《编译原理之美》笔记——前端部分
2020年02月08日简介
编程珠玑番外篇-O 中间语言和虚拟机漫谈编程语言的发展历史,总的来说,是一个从抽象机器操作逐步进化为抽象人的思维的过程。机器操作和人的思维如一枚硬币的两面,而语言编译器就像是个双面胶,将这两面粘在一起,保证编程语言源程序和机器代码在行为上等价。当然,人本身并不是一个完美的编译器,不能无错的将思维表达为高级语言程序,这种偏差,即Bug。因为编译器的帮助,我们可以脱离机器细节,只关心表达思维和程序行为这一面。
宏观
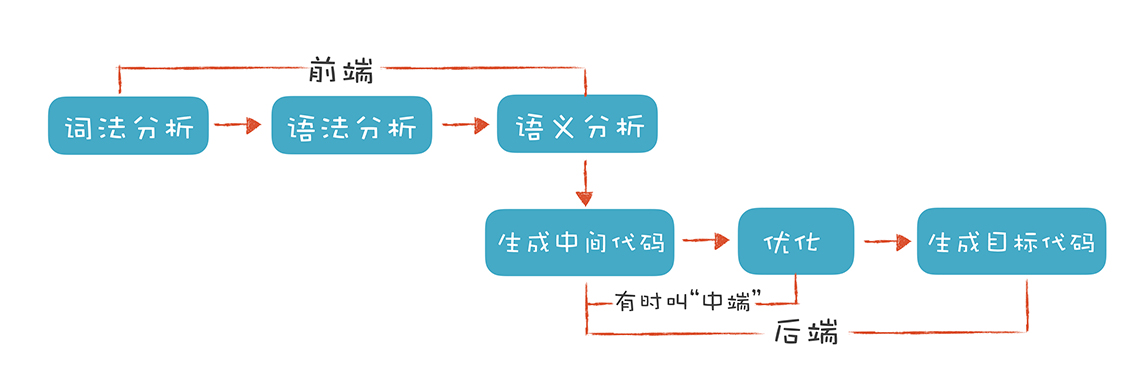
- 前端(Front End)指的是编译器对程序代码的分析和理解过程,它通常只跟语言的语法有关,跟目标机器无关。前端的重点是让编译器能够读懂程序。无结构的代码文本,经过前端的处理以后,就变成了 Token、AST 和语义属性、符号表等结构化的信息。
- 后端(Back End)”则是生成目标代码的过程,跟目标机器有关。
词法分析——将字符串+词法规则转换为Token List
汉语里每个词之间是没有空格的,但我们会下意识地把句子里的词语正确地拆解出来。比如把“我学习编程”这个句子拆解成“我”“学习”“编程”,这个过程叫做“分词”。如果你要研发一款支持中文的全文检索引擎,需要有分词的功能。对于代码来说,需要将代码片段识别为关键字、标识符、操作符、数字字面量等,统称Token,可以通过构造有限自动机来实现。
词法分析器分析整个程序的字符串,当遇到不同的字符时,会驱使它迁移到不同的状态。例如,词法分析程序在扫描 age 的时候,处于“标识符”状态,等它遇到一个 > 符号,就切换到“比较操作符”的状态。词法分析过程,就是这样一个个状态迁移的过程。
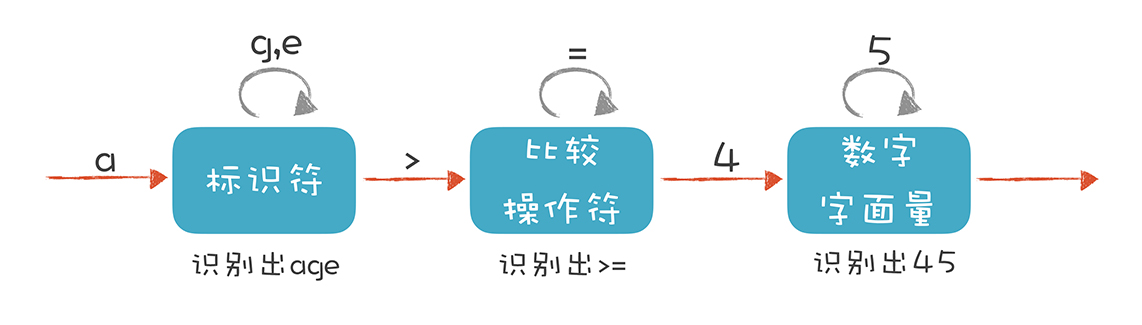
我们可以把所有常用的词法规则都用正则表达式描述出来,用现成工具Lex/Yacc/JavaCC/Antlr生成词法分析器。
Antlr支持的词法规则文件
lexer grammar Hello; //lexer关键字意味着这是一个词法规则文件,名称是Hello,要与文件名相同
//关键字
If : 'if';
Int : 'int';
//字面量
IntLiteral: [0-9]+;
StringLiteral: '"' .*? '"' ; //字符串字面量
//操作符
AssignmentOP: '=' ;
RelationalOP: '>'|'>='|'<' |'<=' ;
LeftParen: '(';
RightParen: ')';
//标识符
Id : [a-zA-Z_] ([a-zA-Z_] | [0-9])*;语法分析——将Token List+语法规则转换为AST
语法分析就是在词法分析的基础上识别出程序的语法结构。这个结构是一个树状结构,是计算机容易理解和执行的。
一个程序就是一棵树,这棵树叫做抽象语法树(Abstract Syntax Tree,AST)。树的每个节点(子树)是一个语法单元,这个单元的构成规则就叫“语法”。每个节点还可以有下级节点。层层嵌套的树状结构,是我们对计算机程序的直观理解。计算机语言总是一个结构套着另一个结构,大的程序套着子程序,子程序又可以包含子程序。
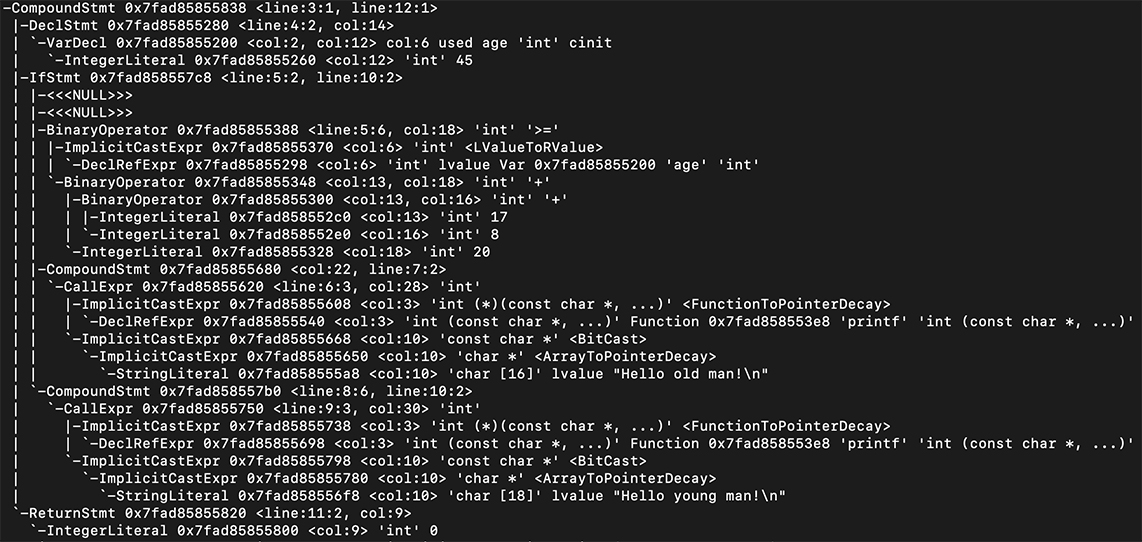
AST 叶子节点,就是词法分析阶段生成的 Token。对这棵 AST 做深度优先的遍历,你就能依次得到原来的 Token。
AST的生成有很多现成的工具,比如 Yacc(或 GNU 的版本,Bison)、Antlr、JavaCC 等。javascript-ast提供javascript 语法树的可视化
语义分析——标注AST的属性
(代码结构化)词法和语法都有很固定的套路,甚至都可以工具化的实现。但语言设计的核心在于语义,特别是要让语义适合所解决的问题。比如 SQL 语言针对的是数据库的操作,那就去充分满足这个目标就好了。
语义分析是要让计算机理解我们的真实意图,把一些模棱两可的地方消除掉。
- 某个表达式的计算结果是什么数据类型?如果有数据类型不匹配的情况,是否要做自动转换?
- 如果在一个代码块的内部和外部有相同名称的变量,我在执行的时候到底用哪个?
- 在同一个作用域内,不允许有两个名称相同的变量,这是唯一性检查。
- 变量类型的消解。比如当我们声明“Bird bird = Bird(); ”时,需要知道 Bird 对象的定义在哪里,以便正确地访问它的成员。在做语义分析时,会把类型定义会保存在 一个数据结构中
语义分析的结果保存在AST 节点的属性上,比如在 标识符节点和 字面量节点上标识它的数据类型是 int 型的。在AST上还可以标记很多属性,有些属性是在之前的两个阶段就被标注上了,比如所处的源代码行号,这一行的第几个字符。某些部分也可以独立存储(只是在概念上,这些属性还是标注在树节点上的),比如符号表。变量、类和函数的名称,我们都叫做符号,编译过程中的一项重要工作就是建立符号表,它帮助我们进一步地编译或执行程序。在符号表里,我们保存它的名称、类型、作用域等信息。对于类和函数,我们也有相应的地方来保存类变量、方法、参数、返回值等信息。
从属性计算的视角看,各种语义分析问题都可以看做是对 AST 节点的某个属性进行计算。比如,针对变量赋值语句中的“左值”,它需要计算的属性包括:
- 它的变量定义是哪个(这就引用到定义该变量的 Symbol)。
- 它的类型是什么?
- 它的作用域是什么?
- 这个节点求值时,是否该返回左值?能否正确地返回一个左值?
- 它的值是什么?
语义分析获得的一些信息(引用消解信息、类型信息等),会附加到 AST 上,AST 加上这些语义规则,就能完整地反映源代码的含义。可以深度优先地遍历 AST,并且一边遍历,一边执行语法规则。那么这个遍历过程,就是解释执行代码的过程。相当于写了一个基于 AST 的解释器。
从属性计算的角度看,对表达式求值,或运行脚本,只是去计算 AST 节点的 Value 属性。属性计算,可以伴随着语法分析的过程一起进行,也可以在做完语法分析以后再进行。这两个阶段不一定完全切分开。甚至,我们有时候会在语法分析的时候做一些属性计算,然后把计算结果反馈回语法分析的逻辑,帮助语法分析更好地执行。(开阔一下思路,免得把知识学得太固化了)。
在工程上,为了让算法更清晰,还会把语义分析过程拆成了好几个任务,对 AST 做了多次遍历。比如《编译之美》中示例编译器的实现
- 第一遍类型和作用域解析,把自定义类、函数和和作用域的树都分析出来。
- 第二遍类型的消解,把所有出现引用到类型的地方,都消解掉,比如变量声明、函数参数声明、类的继承等等。
- 第三遍引用的消解和 S 属性的类型的推导,对所有的变量、函数调用,都会跟它的定义关联起来,并且完成了所有的类型计算。
- 第四遍做类型检查,比如当赋值语句左右两边的类型不兼容的时候,就可以报错。
- 第五遍做一些语义合法性的检查,比如 break 只能出现在循环语句中,如果某个函数声明了返回值,就一定要有 return 语句等等。
实例分析——一个简单的解释器
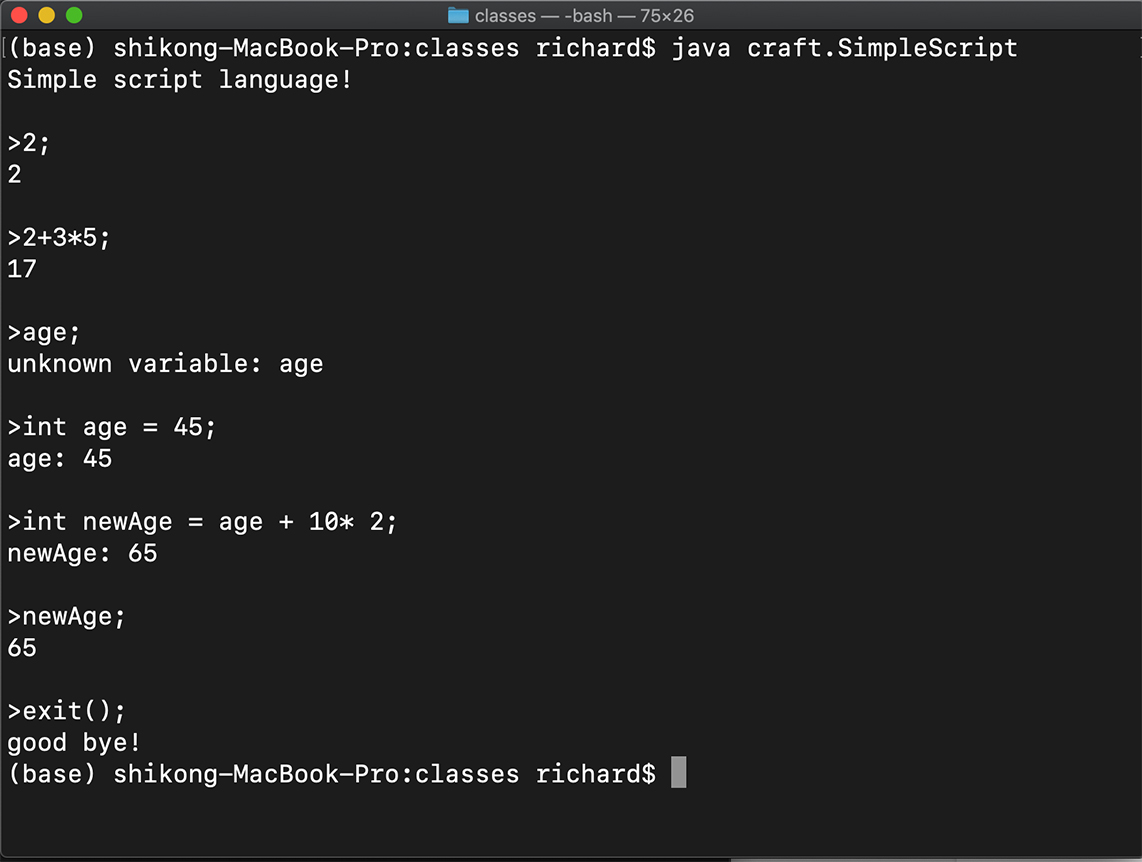
- 支持变量声明和初始化语句
- 支持赋值语句“age = 45”;
- 在表达式中可以使用变量,例如“age + 10 *2”;
java类实现
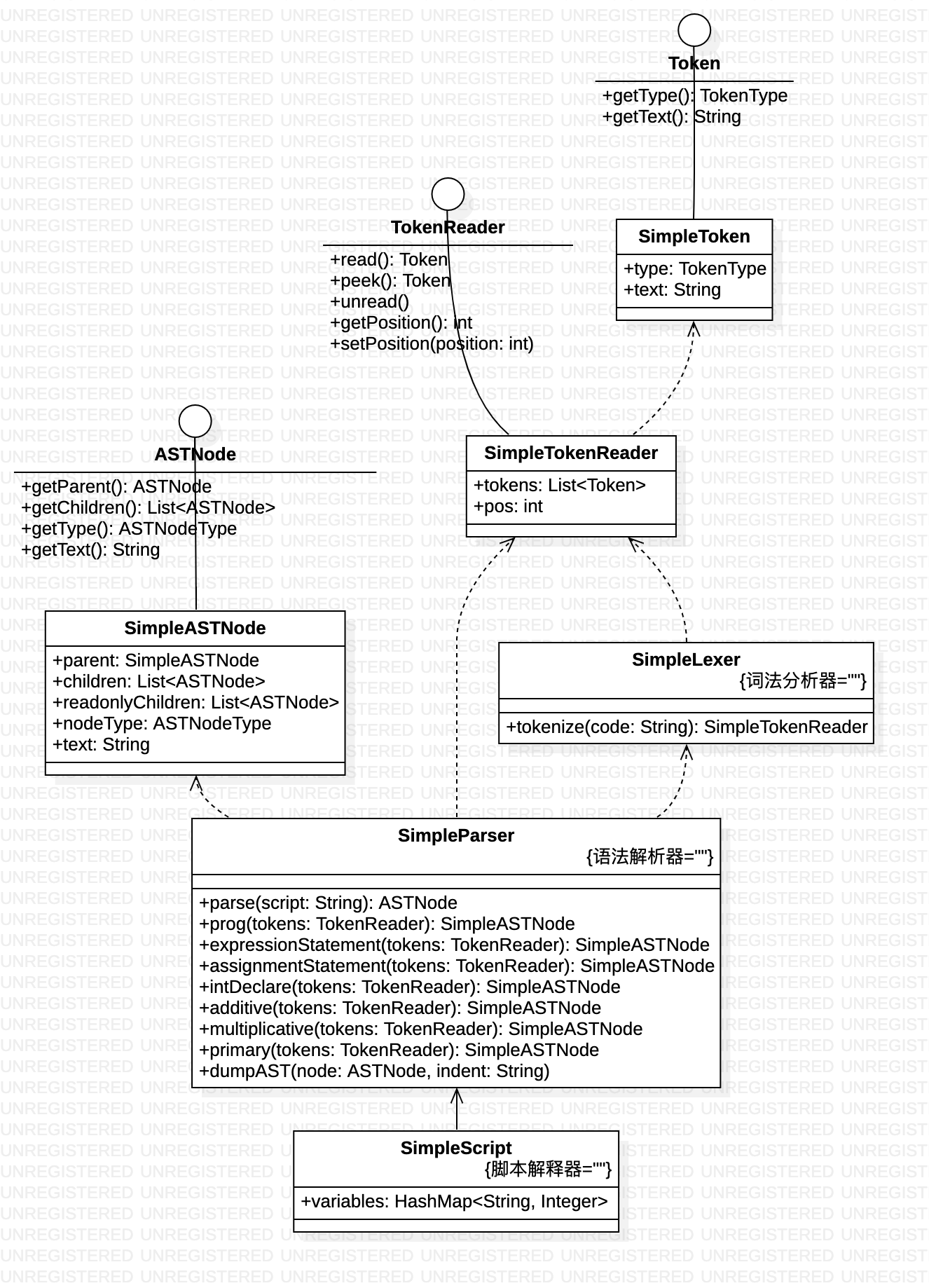
一个最简单版 脚本解释器实现
public class SimpleScript {
// 简单地用了一个 HashMap 作为变量存储区。在变量声明语句和赋值语句里,都可以修改这个变量存储区中的数据
private HashMap<String, Integer> variables = new HashMap<String, Integer>();
public static void main(String[] args) {
SimpleScript script = new SimpleScript();
SimpleParser parser = new SimpleParser();
...
// 读取输入的一行
String line = reader.readLine().trim();
// 将输入经过词法分析器转为Token数组,再转换为AST
ASTNode tree = parser.parse(scriptText);
// 所谓解释执行,其实是对AST进行遍历计算
script.evaluate(tree, "");
...
}
}语法分析
public class SimpleParser {
// 解析脚本 生成AST
public ASTNode parse(String script) throws Exception {
SimpleLexer lexer = new SimpleLexer();
TokenReader tokens = lexer.tokenize(script);
ASTNode rootNode = prog(tokens);
return rootNode;
}
private SimpleASTNode prog(TokenReader tokens) throws Exception{
SimpleASTNode node = new SimpleASTNode(ASTNodeType.Programm, "pwc");
// 穷举词法分析得到的tokens 是什么语句,作为AST 根节点的子节点
while (tokens.peek() != null) {
SimpleASTNode child = intDeclare(tokens);
if (child == null) {
child = expressionStatement(tokens);
}
if (child == null) {
child = assignmentStatement(tokens);
}
if (child != null) {
node.addChild(child);
} else {
throw new Exception("unknown statement");
}
}
return node;
}
}脚本解释器
AST 是语法解析的成果,解释器所谓“解释”就是对AST 的运算
public class SimpleScript {
// 遍历AST,计算值
private Integer evaluate(ASTNode node, String indent) throws Exception {
switch (node.getType()) {
case Programm://程序入口,根节点
case Additive://加法表达式
ASTNode child1 = node.getChildren().get(0);
Integer value1 = evaluate(child1, indent + " ");
ASTNode child2 = node.getChildren().get(1);
Integer value2 = evaluate(child2, indent + " ");
// 取出左右节点,递归求职,然后根据加法符号进行计算
if (node.getText().equals("+")) {
result = value1 + value2;
} else {
result = value1 - value2;
}
break;
case Multiplicative://乘法表达式
case IntLiteral://整型字面量
case Identifier://标识符
case AssignmentStmt://赋值语句
case IntDeclaration://整型变量声明
}
}
}从某个视角看,脚本解释跟md/OpenAPI渲染 是一样一样的,只是代码的词法规则、语法规则更多
| 源文件 | 内部处理 | 效果呈现 | |
|---|---|---|---|
| markdown引擎 | md文本 | java对象 | html |
| OpenAPI渲染 | OpenAPI规范文本 | java对象 | html |
| 代码解释器 | 代码文本 | AST | 代码执行 |
其它
为什么是AST?
编译的第一步是构建一个叫抽象语法树(AST)的数据结构 (脚注: 语法树这个概念来源于 LISP)。有了这样的数据结构后,解释器和编译器在此分野。
抽象语法树(AST),是源代码的结构的一种抽象表示,它用树状的方式表示编程语言的语法结构,抽象语法树抹去了源代码中不重要的一些字符 - 空格、分号或者括号等等。
| 程序代码的树形表示 | html/DOM | 编程语言/AST |
|---|---|---|
| 基本组成 | 标签 | 代码 |
| 内部表示 | DOM | AST |
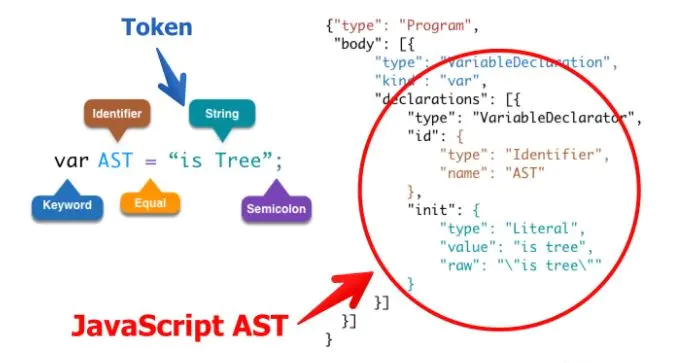
中文总是倾向于将重要的事情放在最后说,所以抽象语法树 容易重点关注“树”。抽象语法树 拆开来理解
- 语法,编程语言之间的差异直接体现在 语法和语义上,比如java 和go 的方法定义就不同。 具体的说,语法可以认为是 一个语言包含多少中语句(比如赋值语句、函数定义),每个语句有哪些组成。然后因为语句之间 包含关系,进而构成一棵树。
-
树,计算机语言总是一个结构套着另一个结构,大的程序套着子程序,子程序又可以包含子程序。 就像一个树状结构一样。从 可视化的角度看,只要能够表达 层次关系,也可以不按树形输出,以java 对象的语法规则为例
classDeclaration // classDeclaration 几个组成(包括两个可选) : CLASS IDENTIFIER (EXTENDS typeType)? (IMPLEMENTS typeList)? classBody // classBody的详细组成另行描述 ; classBody : '{' classBodyDeclaration* '}' ; classBodyDeclaration : ';' | memberDeclaration ; memberDeclaration : functionDeclaration | fieldDeclaration ; functionDeclaration : typeTypeOrVoid IDENTIFIER formalParameters ('[' ']')* (THROWS qualifiedNameList)? functionBody ; - 语法树 只是代码另一种形态的文字表示。代码中看到 “=” 知道是赋值语句,在语法树中则是一个明确的 VariableDeclaration。但语法树只是 代码的另一种表示,就好像水有固态、液态和气态,但都是H2O一样。至于一个赋值语句涉及到的 给变量申请空间,将内存某个地址设置为某个值的动作,是语义的事情,针对每个语句定义解释器的行为。PS:在k8s中,我们编写yaml 文件,k8s 负责操作集群 使其符合yaml 定义的状态。再往前推,有java sdk 用来封装 k8s api,
Deloyment deployment = new Deployment这个赋值语句可以解释为 内存中新建了一个Deployment 对象,也可以解释为 集群中新出现了一个 Deployment
抽象语法树的使用场景
- 语法检查、代码错误提示、代码自动补全
- 代码高亮、代码格式化、代码风格检查
- 关键字匹配
- 作用域判断
- 代码压缩
但从AST 的学习来说,js 相关文章比较多,语法树格式也比较易懂。
类型系统
《编译原理之美》:类型系统是一门语言所有的类型的集合,操作这些类型的规则,以及类型之间怎么相互作用的(比如一个类型能否转换成另一个类型)。
类型到底是什么?我们说一个类型的时候,究竟在说什么?要知道,在机器代码这个层面,其实是分不出什么数据类型的。在机器指令眼里,那就是 0101,它并不对类型做任何要求,不需要知道哪儿是一个整数,哪儿代表着一个字符,哪儿又是内存地址。你让它做什么操作都可以,即使这个操作没有意义,比如把一个指针值跟一个字符相加。
那么高级语言为什么要增加类型这种机制呢?对类型做定义很难,但大家公认的有一个说法:类型是针对一组数值,以及在这组数值之上的一组操作。比如,对于数字类型,你可以对它进行加减乘除算术运算,对于字符串就不行。所以,类型是高级语言赋予的一种语义,有了类型这种机制,就相当于定了规矩,可以检查施加在数据上的操作是否合法。因此类型系统最大的好处,就是可以通过类型检查降低计算出错的概率。所以,现代计算机语言都会精心设计一个类型系统,而不是像汇编语言那样完全不区分类型。
根据类型检查是在编译期还是在运行期进行的,我们可以把计算机语言分为两类:
- 静态类型语言(全部或者几乎全部的类型检查是在编译期进行的)。因为编译期做了类型检查,运行期不用再检查类型,性能更高。像 C、Java 和 Go 语言,在编译时就对类型做很多处理,包括检查类型是否匹配,以及进行缺省的类型转换
- 动态类型语言(类型的检查是在运行期进行的)。
跟静态类型和动态类型概念相关联的,还有强类型和弱类型。强类型语言中,变量的类型一旦声明就不能改变,弱类型语言中,变量类型在运行期时可以改变。二者的本质区别是,强类型语言不允许违法操作,因为能够被检查出来,弱类型语言则从机制上就无法禁止违法操作,所以是不安全的。
类型检查主要出现在几个场景中:
- 赋值语句(检查赋值操作左边和右边的类型是否匹配)。
- 变量声明语句(因为变量声明语句中也会有初始化部分,所以也需要类型匹配)。
- 函数传参(调用函数的时候,传入的参数要符合形参的要求)。
- 函数返回值(从函数中返回一个值的时候,要符合函数返回值的规定)。
a = b + 10 类型推导的代码实现。我们在编译期实现了这段代码,就不用放在运行期了。
case PlayScriptParser.ADD:
if (type1 == PrimitiveType.String ||
type2 == PrimitiveType.String){
type = PrimitiveType.String;
}
else if (type1 instanceof PrimitiveType &&
type2 instanceof PrimitiveType){
//类型“向上”对齐,比如一个int和一个float,取float
type = PrimitiveType.getUpperType(type1,type2);
}else{
at.log("operand should be PrimitiveType for additive operation", ctx);
}
break;闭包的实现
闭包就是把函数在静态作用域中所访问的变量的生存期拉长,形成一份可以由这个函数单独访问的数据。正因为这些数据只能被闭包函数访问,所以也就具备了对信息进行封装、隐藏内部细节的特性。
function int() fun1(){ //函数的返回值是一个函数
int b = 0; //函数内的局部变量
int inner(){ //内部的一个函数
a = a+1;
b = b+1;
return b; //返回内部的成员
}
return inner; //返回一个函数
}
function int() fun2 = fun1();原理是:给 fun2 赋值时,先执行 fun1() 函数,创建一个 FunctionObject 对象(包含变量b),作为 fun1() 的返回值,给到调用者。
从类型体系的角度理解继承和多态
面向对象主要的特点:封装、继承、多态。 语义分析的事情汇总一下就是:类型系统和处理上下文。所以说,面向对象对 编译系统(主要是对语法和语义分析)的影响 主要说的是 语法分析要支持封装,继承多态对语义分析(类型系统和处理上下文)的影响。
//将子类的实例赋给父类的变量
Mammal a = Cow();
Mammal b = Sheep();
// 对象a 的类型在运行时可能发生更改,编译期只确定a的父类型Mammal
a = b;继承和多态对类型系统提出的新概念,就是子类型。我们之前接触的类型往往是并列关系,你是整型,我是字符串型,都是平等的。而现在,一个类型可以是另一个类型的子类型。对某个类型所做的所有操作都可以用子类型替代。这会导致我们在编译期无法准确计算出a/b的类型,从而无法对方法和属性的调用做完全正确的消解(或者说绑定):指向 Cow 或 Sheep 的 speak 方法。这部分工作要留到运行期去做,在运行期对象里是保存了真实类型信息的,我们能知道 a 和 b 这两个变量具体指向的是哪个对象。也因此,面向对象编程会具备非常好的优势,因为它会导致多态性。这个特性会让面向对象语言在处理某些类型的问题时,更加优雅。