从语言编译器源码入手,编译原理该这么学
视频选集


标志符 & 关键字:
Java 是先一起识别出来,再挑出保留关键字;
Python 不区分,在后面语法处理阶段再区分

Java:同时使用自顶向下(总体)和自底向上(部分,比如二元表达式:加减乘除)—— Go语言也是这么实现的



并发:
- coroutine
- goroutine
虚拟机在栈、寄存器上的安排,和 线程 有什么不同?

教科书里面,大多数是 TAC 三地址代码
真实的编译器四种示例:LLVM IR、Julia、Java(图)——JIT编译器、V8
sea of nodes (节点之海)这种数据结构,为什么?
SSA

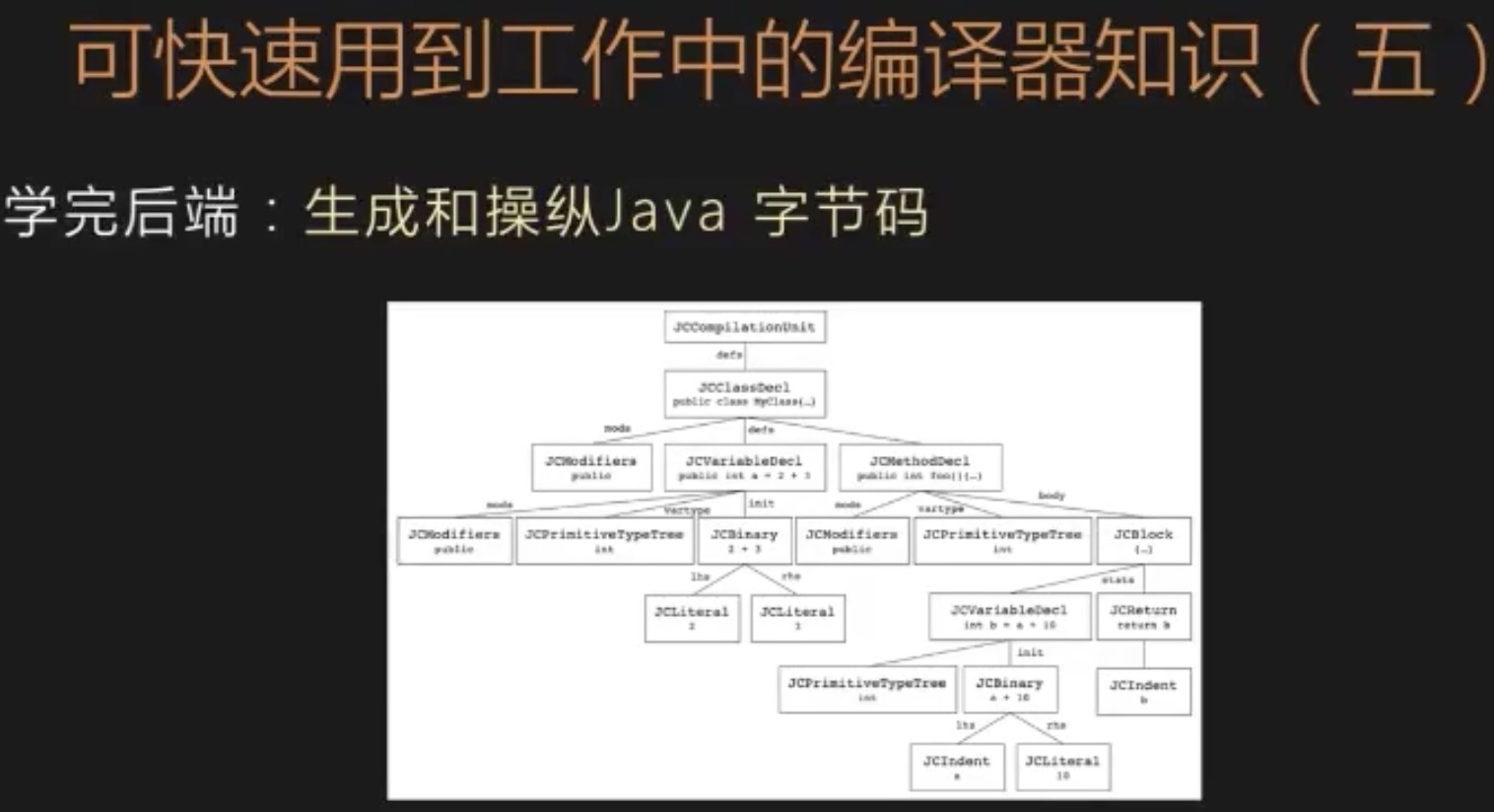
上图是 Java
机器码是怎么生成的?
AST -> IR(高、中、低) --> 指令选择、寄存器分配、指定的排序 --> 机器码

LLVM学什么?:一个学它的优化,一个学它的后端代码生成

非结构化的数据转化为结构化的数据:


阿里一个手写的SQL解析器 —— 快、分布式导到对应的数据库服务器?
——有最佳实践,有固定的套路

SaaS:Salesforce 和 SAP 都是用自己的语言、编程平台做的
模块化

JS:V8 会根据参数类型做推断,再做优化;一旦改了类型,则前面的优化就全无效了;建议用不同的函数名字
要会调试跟踪是不是进行了内联;——内联不仅减少了函数的调用,还有其它的优化;
大量的循环,不要去访问对象的成员变量——因为要写内存;
Skia:重性能,官网强烈推荐用 clang 编译
基于Java 的DSL,这件事一定要会做;
Protobuf 的例子:内部有编译器把网络协议的内容编译后落地

两种不同的汇编架构:
- x86
- ARM:load-store 架构?
什么样的功能,应该用什么样的指令最高效实现,心里有数~
内存计算:一定要知道 SIMD指令
AI:支持 SIMD、支持 GPU,效果是不一样的!!
——AI框架发布的时候,要看它是否支持了相应的指令集
学会了编译原理后,会对高性能这块敏感

看得更加的本质化;

GraalVM:实现了基于语言的虚拟化(如C/C++)
...


左递归在哪出现?
一个产生式会生成 epsilon(空字符串),在哪里会产生?:{} block statements;parameter;
什么地方需要预读好几个 token?
内置函数:要速度比较快,难点是如何去支持那么多的后端?

https://zh.wikipedia.org/wiki/%E9%9D%99%E6%80%81%E5%8D%95%E8%B5%8B%E5%80%BC%E5%BD%A2%E5%BC%8F
编译器最佳化的算法,可以借由SSA的使用,达到以下的改进:
- 常数传播 (constant propagation)
- 值域传播(value range propagation)
- 稀疏有条件的常数传播 (sparse conditional constant propagation)
- 消除无用的程式码 (dead code elimination)
- 全域数值编号 (global value numbering)
- 消除部分的冗余 (partial redundancy elimination)
- 强度折减 (strength reduction)
- 暂存器配置 (register allocation)
Sea of nodes 中译文
https://blog.csdn.net/raojun/article/details/103605349 (好文!)
抽象语法树是使用 esprima工具生成
AST树,因此从顶部到底部遍历访问它很自然,当我们访问AST节点时就生成对应的机器码。 这种方法的问题在于,有关变量的信息非常稀疏,并且分布在不同的树节点上。
同样,为了安全地将长度查找移出循环,我们需要知道数组长度在循环的迭代之间不会改变。 人们只要看一下源代码就可以轻松地做到这一点,但是编译器需要做大量工作才能从AST中提取到这些信息。
像许多其他编译器问题一样,通常可以通过将数据提升到更合适的抽象层(即中间表示)中来解决此问题。 在这个特例里,IR的选择称为数据流图(DFG)。 与其关注语法实体(例如用于循环,表达式等),不如关注数据本身(读取,变量值)以及它们如何在程序中变化。
我为sea-of-nodes实践编写了一个JavaScript工具集,其中包括:
- json-pipeline -图的生成器和标准库。 提供创建节点,向节点添加输入,更改其控制依赖性以及向/从可打印数据导出/导入图的方法!
- json-pipeline-reducer – 简化(reductions)引擎。 只需创建一个reducer实例,为它提供几个reduce函数,然后在现有的json-pipeline图上执行这个reducer。
- json-pipeline-scheduler – 这是一个库,用于将无序图放回由控制边(虚线)连接在一起的有限数量的块中
这些工具结合在一起,可以解决许多用数据流方式表示的问题。
强加范式:——比如 JVM的对象模式;
scala 支持 actor 模式,Erlang 也支持 actor 模式;
Erlang 的作者在讨论这件事的时候,提了一个问题:scala 不支持抢断式的并发——因为JVM不支持;
如果一个携程运行时间太长的话,它可以影响其它的携程的
Golang 的并发与 Erlang、Scala、Node.js 和 Python 的并发模型相比有何特点? - 蔡磊的回答 - 知乎 https://www.zhihu.com/question/21461752/answer/27746958






