- P1402_利用mykernel实验模拟计算机硬件平台
- P1501_C代码中嵌入汇编代码的写法
- P1602_一个简单的操作系统内核源代码
- P1703_运行这个精简的操作系统内核
- P1801_Linux内核源代码
- P1901_构造一个简单的Linux系统MenuOS
- P2001_使用gdb跟踪调试Linux内核的方法
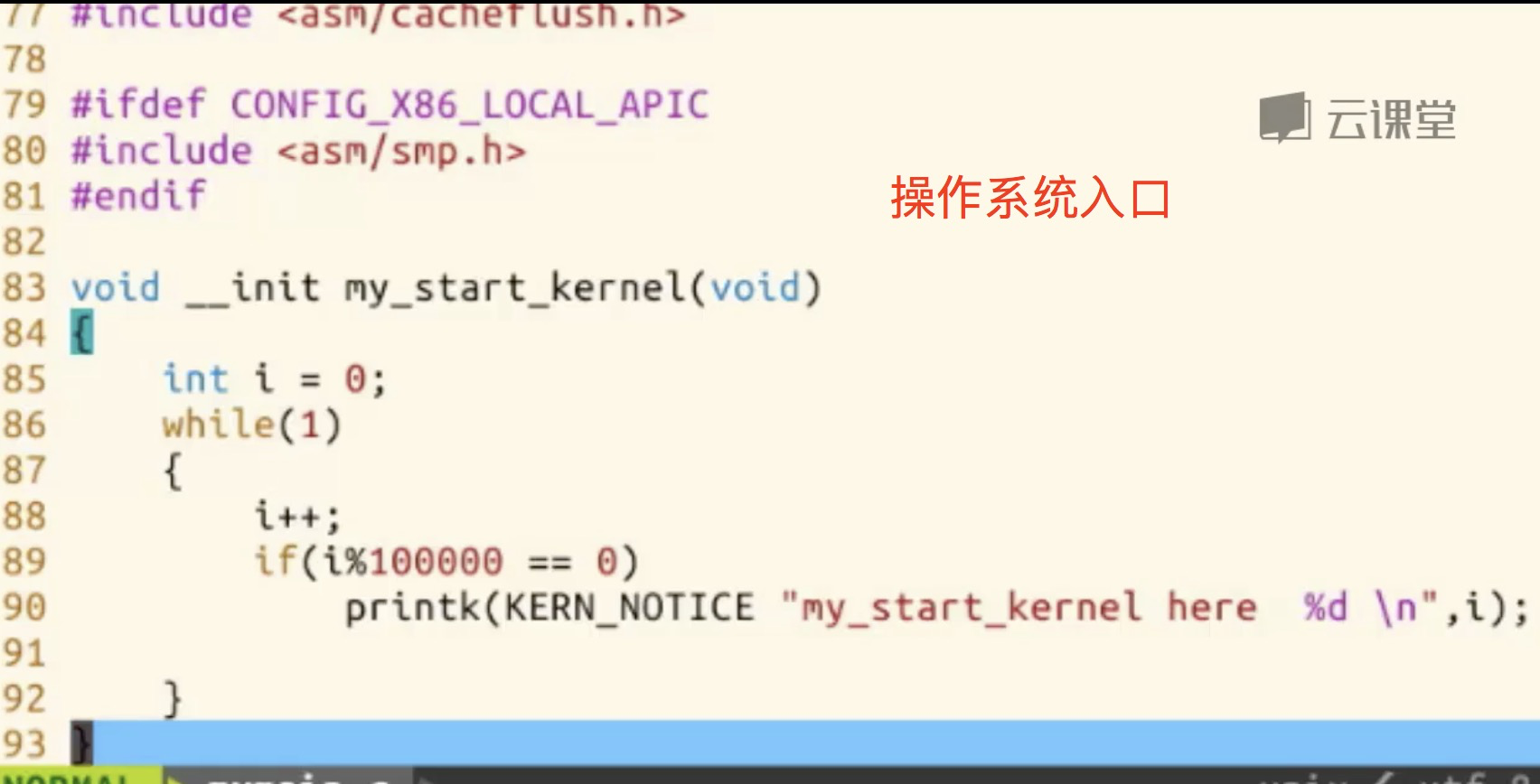
- P2102_简单分析一下start_kernel
- P2201_用户态、内核态和中断处理过程
- P2301_系统调用概述和系统调用的三层皮
- P2401_使用库函数API获取系统当前时间
- P2502_C代码中嵌入汇编代码的写法(复习可跳过)
- P2603_使用C代码中嵌入汇编代码触发系统调用获取系统当前时间
- P2701_给MenuOS增加time和time-asm命令
- P2801_使用gdb跟踪系统调用内核函数sys_time
- P2901_系统调用在内核代码中的工作机制和初始化
- P3002_简化后便于理解的system_call伪代码
- P3103_简单浏览system_call到iret之间的主要代码
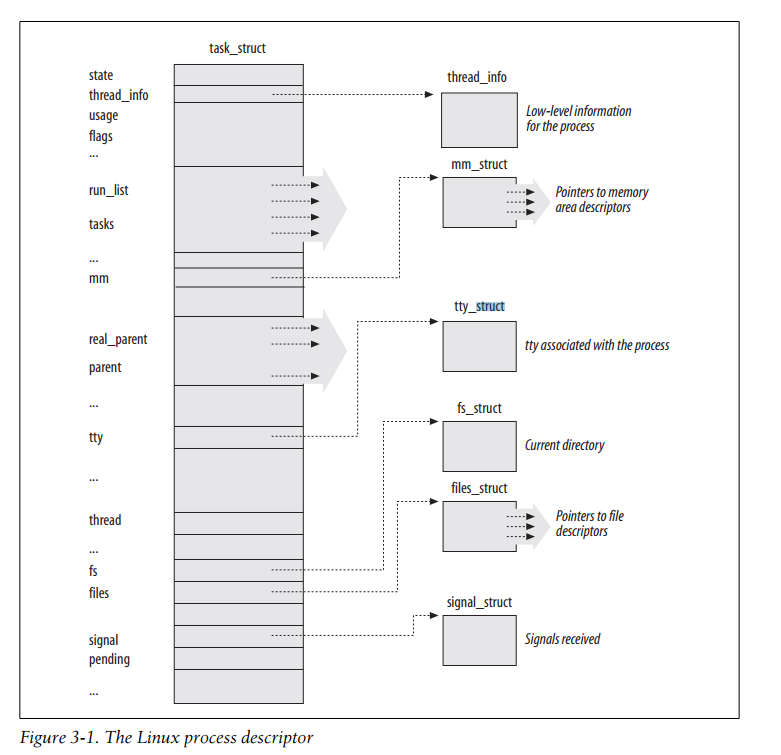
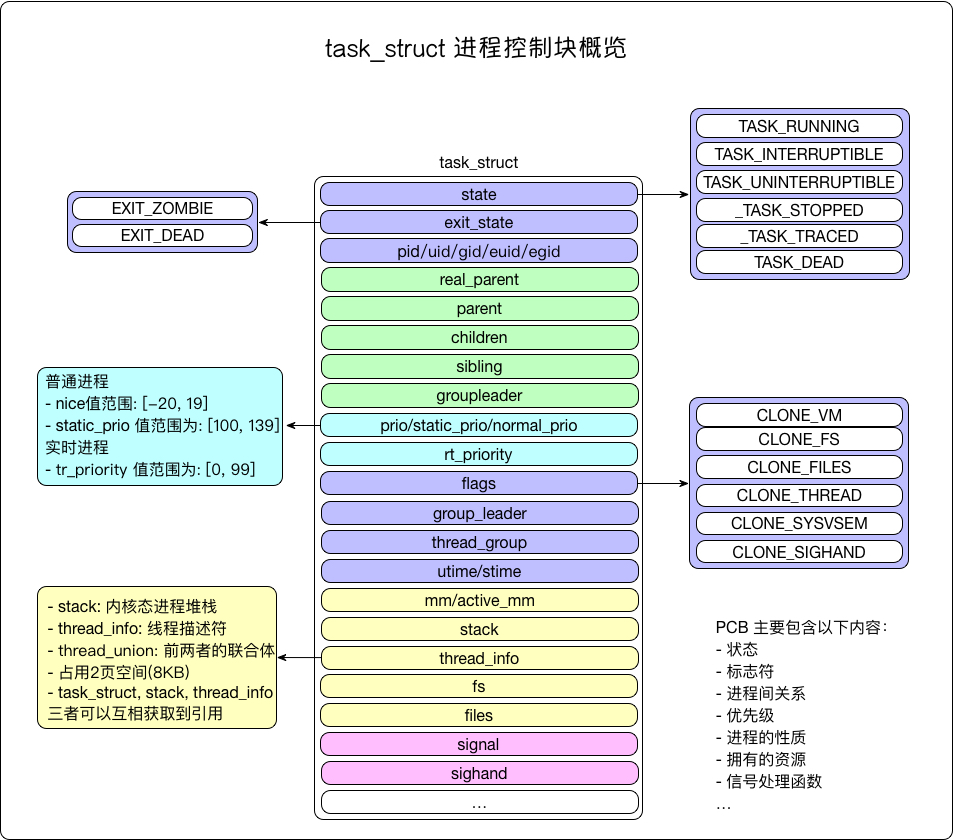
- P3201_进程描述符task_struct数据结构(一)
- P3302_进程描述符task_struct数据结构(二)
- P3401_进程的创建概览及fork一个进程的用户态代码
- P3502_理解进程创建过程复杂代码的方法
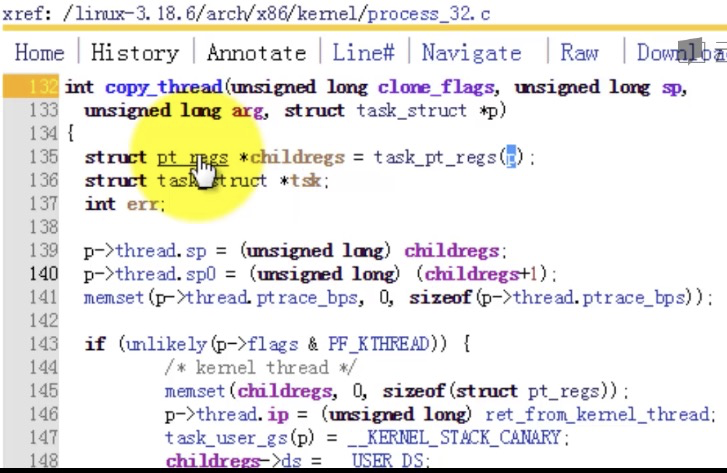
- P3603_浏览进程创建过程相关的关键代码
- P3704_创建的新进程是从哪里开始执行的?
- P3805_使用gdb跟踪创建新进程的过程
- P3901_可执行程序是怎么得来的?
- P4002_目标文件的格式ELF
- P4103_静态链接的ELF可执行文件和进程的地址空间
- P4201_装载可执行程序之前的工作
- P4302_装载时动态链接和运行时动态链接应用举例
- P4401_可执行程序的装载相关关键问题分析
- P4502_sys_execve的内部处理过程
- P4603_使用gdb跟踪sys_execve内核函数的处理过程
- P4704_可执行程序的装载与庄生梦蝶的故事
- P4805_浅析动态链接的可执行程序的装载
- P4901_进程调度与进程调度的时机分析
- P5002_进程上下文切换相关代码分析
- P5101_Linux系统的一般执行过程分析
- P5202_Linux系统执行过程中的几个特殊情况
- P5303_内核与舞女
- P5401_Linux操作系统架构概览
- P5502_最简单也是最复杂的操作——执行ls命令
- P5603_从CPU和内存的角度看Linux系统的执行

把当前栈的寄存器内容等,压到另外一个叫“内核栈”的栈里面去
把EIP指向一个叫做中断处理程序的入口,做保护现场的工作;然后执行中断处理程序;
mykernel:模拟了时钟中断——只有一个程序,隔一段时间就中断一次
在此基础上实现了一个极小的 基于时间片轮转的多进程调度 内核







系统调用是一种特殊的中断,存在保护现场和恢复现场的问题
SAVE_ALL
sys_call_table:系统调用表


操作系统内核三大功能:
进程管理
内存管理
文件系统

task_struct 400多行代码。。。


|
1、R 暂停与跟踪状态还是有区别的,被跟踪状态相当于在暂停状态之上多了一层保护,处于被跟踪状态的进程不能响应SIGCONT信号而被唤醒,只能等到调试进程通过ptrace系统调用执行ptrace_cont、ptrace_detach等操作(通过ptrace系统调用的参数指定操作),或调试进程退出,被调试的进程才能恢复到R状态。 |
|

所有的进程用 list_head *tasks 链表保存

mm:物理地址、逻辑地址转换 ... MMU 内存管理单元 ...
每个进程有自己独立的进程地址空间, x86 32位,4G
进程地址空间 -> 分段 -> 分页,转换为物理地址 ...
struct mm_struct *mm, *active_mm;
vm_area_struct *vmacache ...


thread_struct:


该系统调用所需要的参数pt_regs在include/asm-i386/ptrace.h文件中定义:
struct pt_regs {
long ebx; //可执行文件路径的指针(regs.ebx中
long ecx; //命令行参数的指针(regs.ecx中)
long edx; //环境变量的指针(regs.edx中)。
long esi;
long edi;
long ebp;
long eax;
int xds;
int xes;
long orig_eax;
long eip;
int xcs;
long eflags;
long esp;
int xss;
};
该 参数描述了在执行该系统调用时,用户态下的CPU寄存器在核心态的栈中的保存情况( SAVE_ALL )。通过这个参数,sys_execve能获得保存在用户空间的以下信息: 可执行文件路径的指针(regs.ebx中)、命令行参数的指针(regs.ecx中)和环境变量的指针(regs.edx中)。





syscall_exit 后,用户态已经是返回的子进程了 ( )
动手调试:

make rootfs
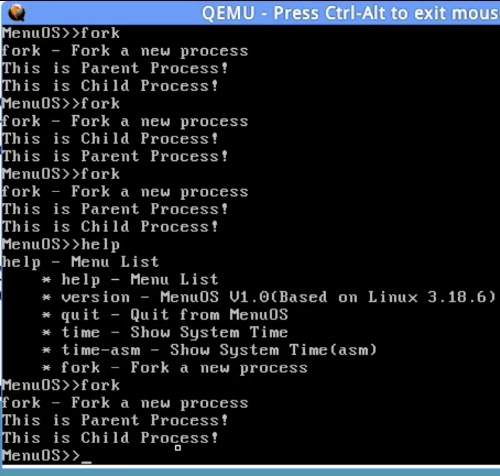
输入fork,子进程已经创建了
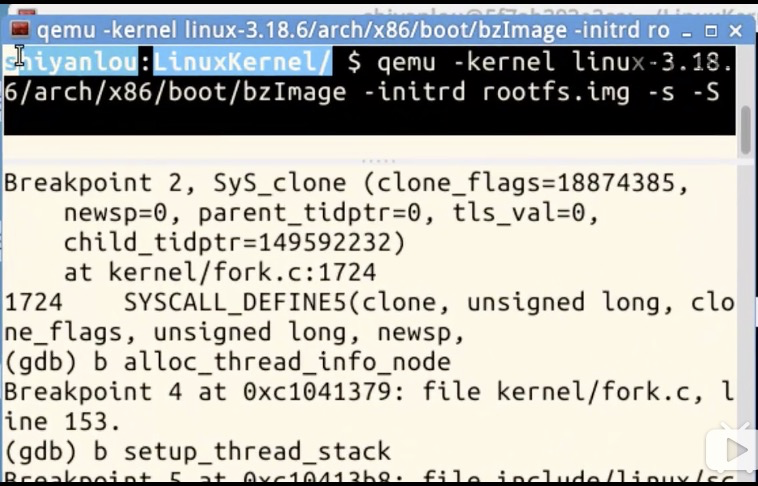

设置断点 b sys_clone
关于Linux中fork、vfork、clone的一些个人见解我在网上看到很多博客上面说: 关于这三个函数的调用过程是这样的: fork->sys_fork->do_fork vfork->sys_vfork->do_fork clone->sys_clone->do_fork 但是我很久之前在陈莉君老师写的Linux内核设计与实现 看到过这么一句话: Linux通过clone系统调用实现fork.调用通过一系列的参数标志来指明父、子进程需要共享的资源。fork、vfork、和__clone的库函数都根据各自需要的参数标志去调用clone,然后由clone()去调用do_fork()。 然后我一直也是这么认为的,但是网上的博客看多了,有时候会去怀疑一下书本上的知识。于是我先是写了连个测试用例,分别调用了fork和 pthread_create,然后利用strace跟踪两者的调用过程,发现果然都是调用的clone。 而后,我还是不满足,便去查阅了一番glibc的源码。 最终的结论是:在Linux操作系统下, arch(X86)架构的是:fork、vfork、和__clone的库函数最终调用的都是clone系统调用。 至于其它的架构的,可能是通过fork和vfork系统调用。这和本身的实现有关。当然在现在的大多数Linux内核中,就算调用的是fork,在底层基本上传递给do_fork的参数都带有能实现写时复制的一些标志。 最后提一点,写博客的人能不能不要那么浮躁,大家都抄来抄去,一点都不负责任。 发布于 2019-03-12
|
|
浅谈Linux进程模型写在前面
进程基础基础概念进程是操作系统的基本概念之一,它是操作系统分配资源的基本单位,也是程序执行过程的实体。程序是代码和数据的集合,本身是一个静态的概念,而进程是程序的一次执行的实体,是一个动态的概念。 那在Linux操作系统中,是如何描述一个进程的呢? 进程描述符为了管理进程,内核需要对每个进程的属性和所需要做的事情,进行清楚的描述,这个就是进程描述符的作用,Linux中的进程描述符由
总结一下,进程描述符完整的保存了一个进程的属性和生命周期内的数据、状态和行为,由一个复杂的数据结构 进程创建Linux创建一个进程,大致经历的过程如下:
为了完整的描述一个进程,操作系统设计了非常复杂的数据结构、也申请了大量的内存空间。但是得益于写时复制技术,这些初始化操作,并没有明显的降低进程的创建速度。 写时复制技术:当新进程(子进程)被创建时,Linux内核并不会立马将父进程的内容复制给子进程,而仅仅当进程空间的内容发生变化时,才执行复制操作。写时复制技术允许父子进程读取相同的物理页,只要两者有一个试图更改页内容,内核就会把这个页的内容拷贝到新的物理页,并把这块页分给正在写的进程。 Linux中有三种系统调用可以创建进程 clone()、fork()、vfork()
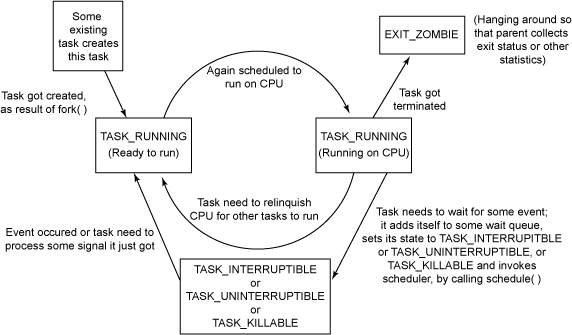
上下文切换概念:进程创建好之后,内核必须有能力挂起正在CPU运行的进程,并切换其他进程到CPU上执行。这种过程被称作为进程切换、任务切换或者上下文切换。 这个过程包括硬件上下文切换和软件上下文切换。 硬件上下文切换:主要通过汇编指令far jmp操作,将一个进程的描述符指针,替换为另一个进程描述符指针,并改变 eip、cs、esp等寄存器,从而改变程序的执行流。 软件上下文切换:
进程切换发生在 执行系统调用时,会经历用户态与内核态的切换以及中断返回。也就是说,每一次执行系统调用,比如fork、read、write等,都可能触发内核调度新进程。 init进程Linux进程是以树形的结构组织的,每一个进程都有唯一的进程标识,简称PID。PID为1的常常是init进程,它相对于普通进程来说,有三个特殊之处:
与孤儿进程类似的是僵尸进程,清理僵尸进程的方法,是杀掉不断产生僵尸进程的父进程,然后这些僵尸进程会称为孤儿进程,由init进程接管、回收。 进程应用进程间通信谈到通信我们都知道,通信的双方必须存在一种可以承载信息的介质,对于计算机之间的通信来说,这种介质可以是双绞线、光纤、电磁波。那对于进程间的通信呢?这种介质有哪些呢?在Linux中,满足这种条件的介质,可以是:
对于操作系统提供的介质来说,常用的有
命名管道(FIFO) 优缺点介绍:
它们的用法相对较为简单,在需要使用时查阅相关文档即可,共享内存是比较常用的做法。 信号处理信号最早是在Unix系统被引入,它主要用于进程间的通信,同时进程可以主动注册信号处理函数,来检测或者应对系统发生的事件。比如当进程访问非法地址空间时,进程会收到操作系统发送SIGSEGV信号,默认情况下的处理方式是:该进程会退出并且把堆栈dump出来,简称出core。 总的来说信号的主要目的:
目前Linux支持的信号,已经默认的处理函数,可以在man手册中查到,截图如下: 
比较常见的信号,解释如下:
其实在项目开发中,常常会和信号处理打交道。比如在处理程序优雅退出时,一般需要捕获SIGINT、SIGPIPE、SIGTERM等信号,以合理的释放资源、处理剩余链接等,防止程序意外crash,导致的一些问题。 后台进程与守护进程在接触Linux系统时,常常会遇到后台进程与守护进程,这里简单的介绍一下这两种进程。
那么这两者有啥区别呢?
举个例子,通过 在进一步了解守护进程之前,还需要了解一些会话和进程组的概念。
那如何实现一个守护进程呢?
总结来说,守护进程是一种长期运行于后台的进程,它脱离了控制终端,不受用户终端退出的影响。可以通过 浅谈nginx多进程模型nginx是一款高性能的Web服务器,由于它优秀的性能、成熟的社区、完善的文档,受到广大开发者的喜爱和支持。它的高性能与其架构是分不开的,nginx的框架如下图所示: 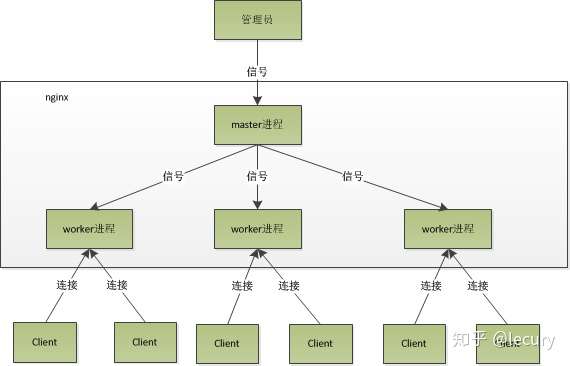 nginx架构图-来源于网上 nginx架构图-来源于网上
Nginx是经典的多进程模型,它启动以后以守护进程的方式在后台运行,后台进程包含一个master进程,和多个worker进程。其中master进程相当于控制进程,有以下作用:
其中 master 进程支持的信号处理如下:
单个worker进程也支持信号处理,包括:
worker进程基于异步非阻塞的模式处理每个请求,这种非阻塞的模式,大大提高了worker进程处理请求的速度。为了尽可能的提高性能,nginx对每个worker进程设置了CPU的亲和性,尽量把worker进程绑定在指定的CPU上执行,以减少上下文切换带来的开销。由于这种绑核的模式,一般推荐worker进程的数目,为CPU的核数。 nginx使用了master<->worker这种多进程的模型,有哪些好处呢?
更多内容来源于:如何理解和应用Linux进程模型? 常用工具介绍Linux内置了许多工具,用于排查系统问题和查看资源使用情况,这里简单介绍和进程有关的几个工具。 ps: 查看进程的基本属性lsof: 查看进程打开的文件情况有两个场景:
对于这些场景,我们可以借助lsof命令,
lsof的常见用法如下:
netstat: 查看网络连接情况strace: 查看系统调用情况发布于 2019-03-27
|