视频选集
原理:
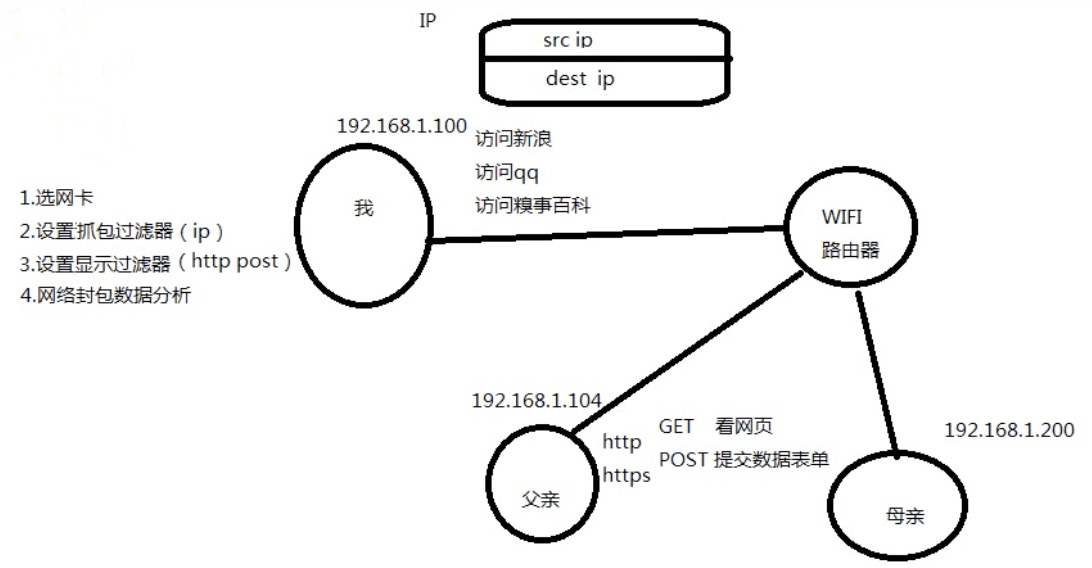
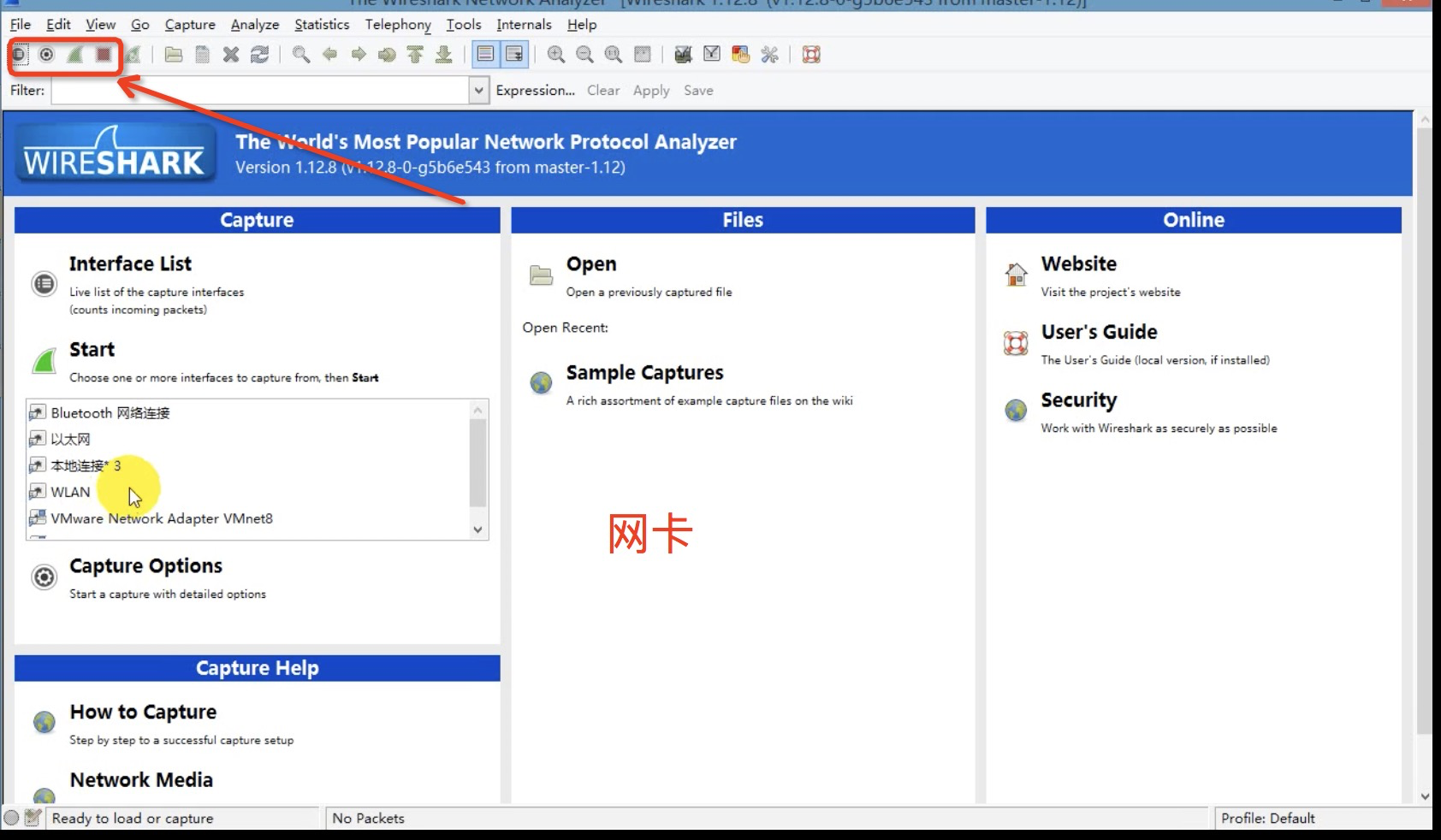
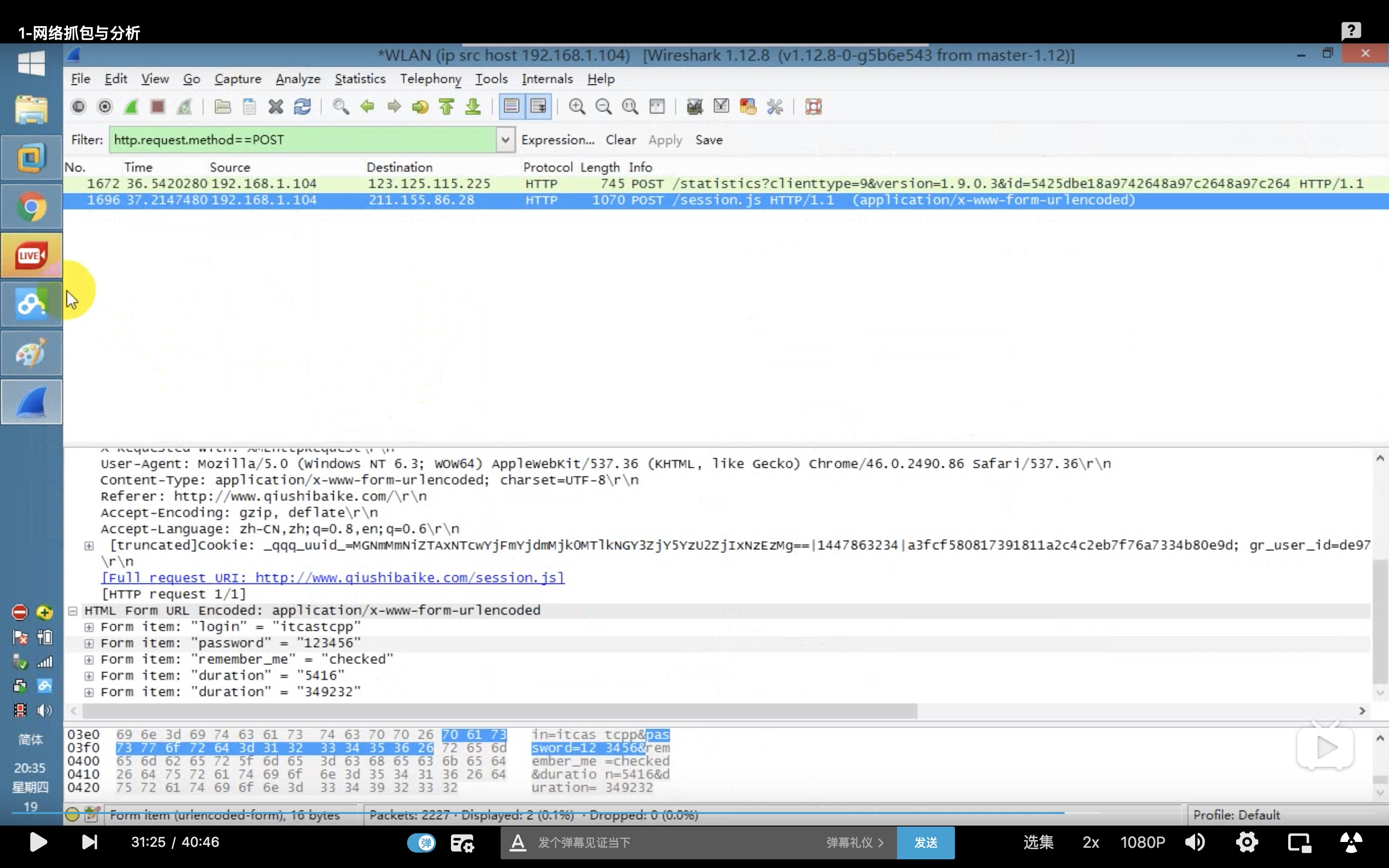
必须是 HTTP协议才抓得到,HTTPS 协议不行
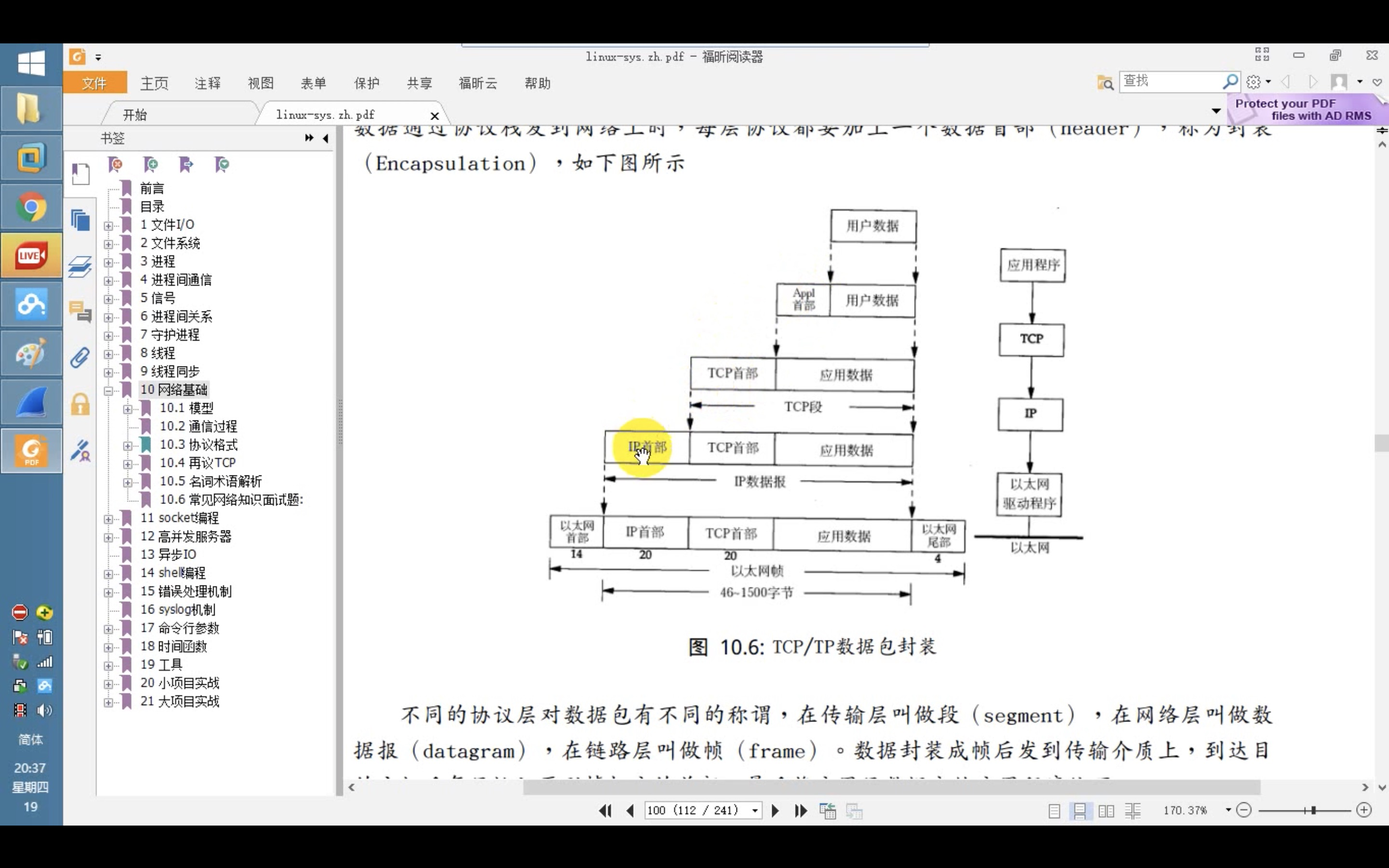
http://read.pudn.com/downloads708/sourcecode/unix_linux/network/2842830/linux-sys.zh.pdf
大并发服务器架构(陈硕muduo库源码解析)
视频选集
- P2大并发服务器架构(陈硕muduo库源码解析) - 2.02大型网站架构演变过程
- P3大并发服务器架构(陈硕muduo库源码解析) - 3.03poll(一)
- P4大并发服务器架构(陈硕muduo库源码解析) - 4.04poll(二)
- P5大并发服务器架构(陈硕muduo库源码解析) - 5.05epoll(一)
- P6大并发服务器架构(陈硕muduo库源码解析) - 6.06epoll(二)
- P7大并发服务器架构(陈硕muduo库源码解析) - 7.07muduo介绍
- P8大并发服务器架构(陈硕muduo库源码解析) - 8.08面向对象编程风格
- P9大并发服务器架构(陈硕muduo库源码解析) - 9.09基于对象编程风格
- P10大并发服务器架构(陈硕muduo库源码解析) - 10.10muduo_base库源码分析(一)
- P11大并发服务器架构(陈硕muduo库源码解析) - 11.11muduo_base库源码分析(二)
- P12大并发服务器架构(陈硕muduo库源码解析) - 12.12muduo_base库源码分析(三)
- P13大并发服务器架构(陈硕muduo库源码解析) - 13.13muduo_base库源码分析(四)
- P14大并发服务器架构(陈硕muduo库源码解析) - 14.14muduo_base库源码分析(五)
- P15大并发服务器架构(陈硕muduo库源码解析) - 15.15muduo_base库源码分析(六)
- P16大并发服务器架构(陈硕muduo库源码解析) - 16.16muduo_base库源码分析(七)
- P17大并发服务器架构(陈硕muduo库源码解析) - 17.17muduo_base库源码分析(八)
- P18大并发服务器架构(陈硕muduo库源码解析) - 18.18muduo_base库源码分析(九)
- P19大并发服务器架构(陈硕muduo库源码解析) - 19.19muduo_base库源码分析(十)
- P20大并发服务器架构(陈硕muduo库源码解析) - 20.20muduo_base库源码分析(十一)
- P21大并发服务器架构(陈硕muduo库源码解析) - 21.21muduo_base库源码分析(十二)
- P22大并发服务器架构(陈硕muduo库源码解析) - 22.22muduo_base库源码分析(十三)
- P23大并发服务器架构(陈硕muduo库源码解析) - 23.23多线程与并发服务器设计(一)
- P24大并发服务器架构(陈硕muduo库源码解析) - 24.24多线程与并发服务器设计(二)
- P25大并发服务器架构(陈硕muduo库源码解析) - 25.25muduo_net库源码分析(一)
- P26大并发服务器架构(陈硕muduo库源码解析) - 26.26muduo_net库源码分析(二)
- P27大并发服务器架构(陈硕muduo库源码解析) - 27.27muduo_net库源码分析(三)
- P28大并发服务器架构(陈硕muduo库源码解析) - 28.28muduo_net库源码分析(四)
- P29大并发服务器架构(陈硕muduo库源码解析) - 29.29muduo_net库源码分析(五)
- P30大并发服务器架构(陈硕muduo库源码解析) - 30.30muduo_net库源码分析(六)
- P31大并发服务器架构(陈硕muduo库源码解析) - 31.31muduo_net库源码分析(七)
- P32大并发服务器架构(陈硕muduo库源码解析) - 32.32muduo_net库源码分析(八)
- P33大并发服务器架构(陈硕muduo库源码解析) - 33.33muduo_net库源码分析(九)
- P34大并发服务器架构(陈硕muduo库源码解析) - 34.34muduo_net库源码分析(十)
- P35大并发服务器架构(陈硕muduo库源码解析) - 35.35muduo_net库源码分析(十一)
- P36大并发服务器架构(陈硕muduo库源码解析) - 36.36muduo_net库源码分析(十二)
- P37大并发服务器架构(陈硕muduo库源码解析) - 37.37muduo_net库源码分析(十三)
- P38大并发服务器架构(陈硕muduo库源码解析) - 38.38muduo_net库源码分析(十四)
- P39大并发服务器架构(陈硕muduo库源码解析) - 39.39muduo_net库源码分析(十五)
- P40大并发服务器架构(陈硕muduo库源码解析) - 40.40muduo_http库源码分析
- P41大并发服务器架构(陈硕muduo库源码解析) - 41.41muduo_inspect库源码分析
- P42大并发服务器架构(陈硕muduo库源码解析) - 42.42muduo库使用示例(一)
- P43大并发服务器架构(陈硕muduo库源码解析) - 43.43muduo库使用示例(二)
- P44大并发服务器架构(陈硕muduo库源码解析) - 44.44muduo库使用示例(三)
- P45大并发服务器架构(陈硕muduo库源码解析) - 45.45muduo库使用示例(四)
- P46大并发服务器架构(陈硕muduo库源码解析) - 46.46muduo库使用示例(五)
- P47大并发服务器架构(陈硕muduo库源码解析) - 47.47muduo库使用示例(六)
- P48大并发服务器架构(陈硕muduo库源码解析) - 48.48muduo库使用示例(七)
- P49大并发服务器架构(陈硕muduo库源码解析) - 4

https://search.bilibili.com/all?keyword=webbench
| (2 条消息)Webbench 实现与详解_刘斐浩的博客 - CSDN 博客_webbench
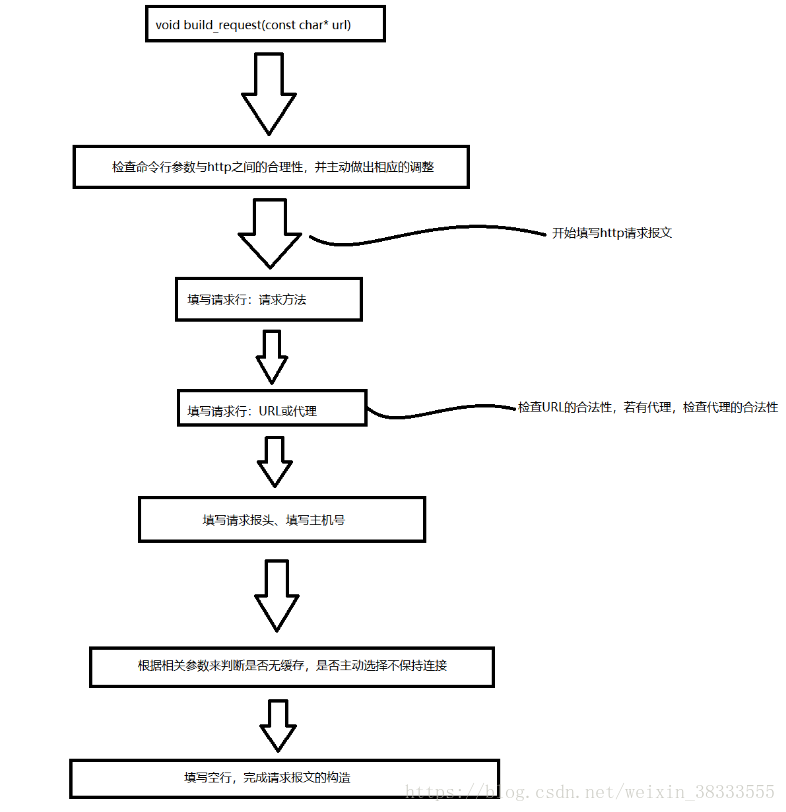
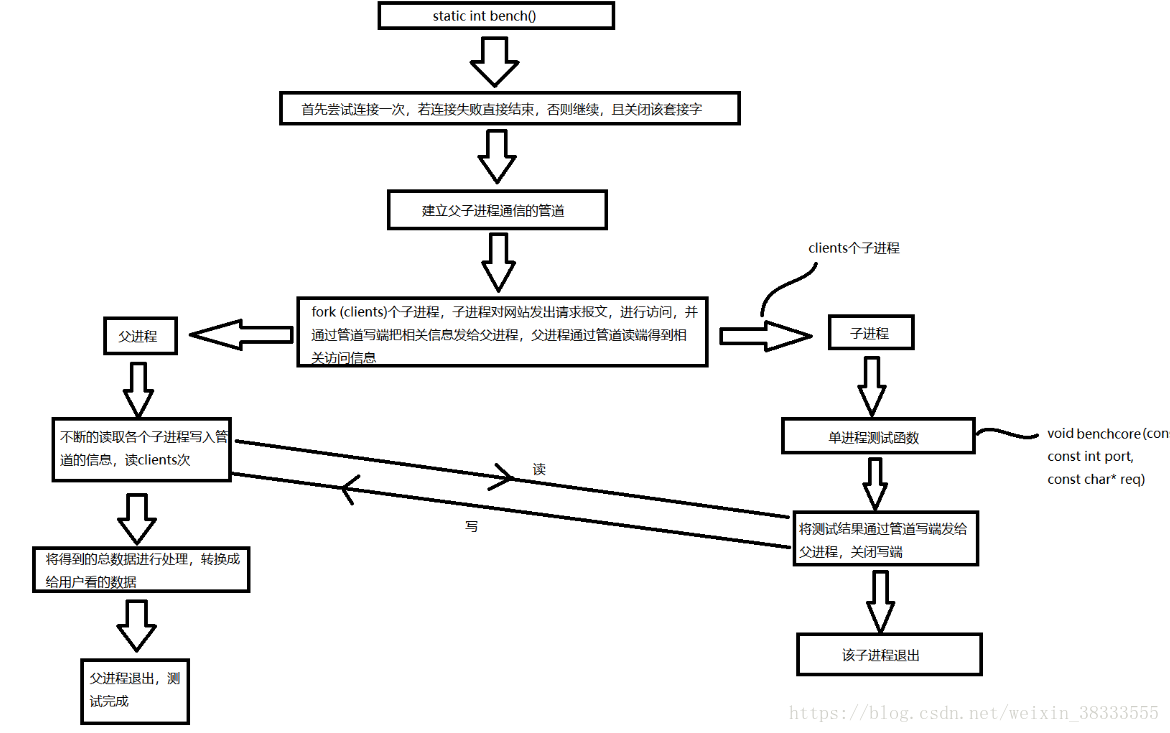
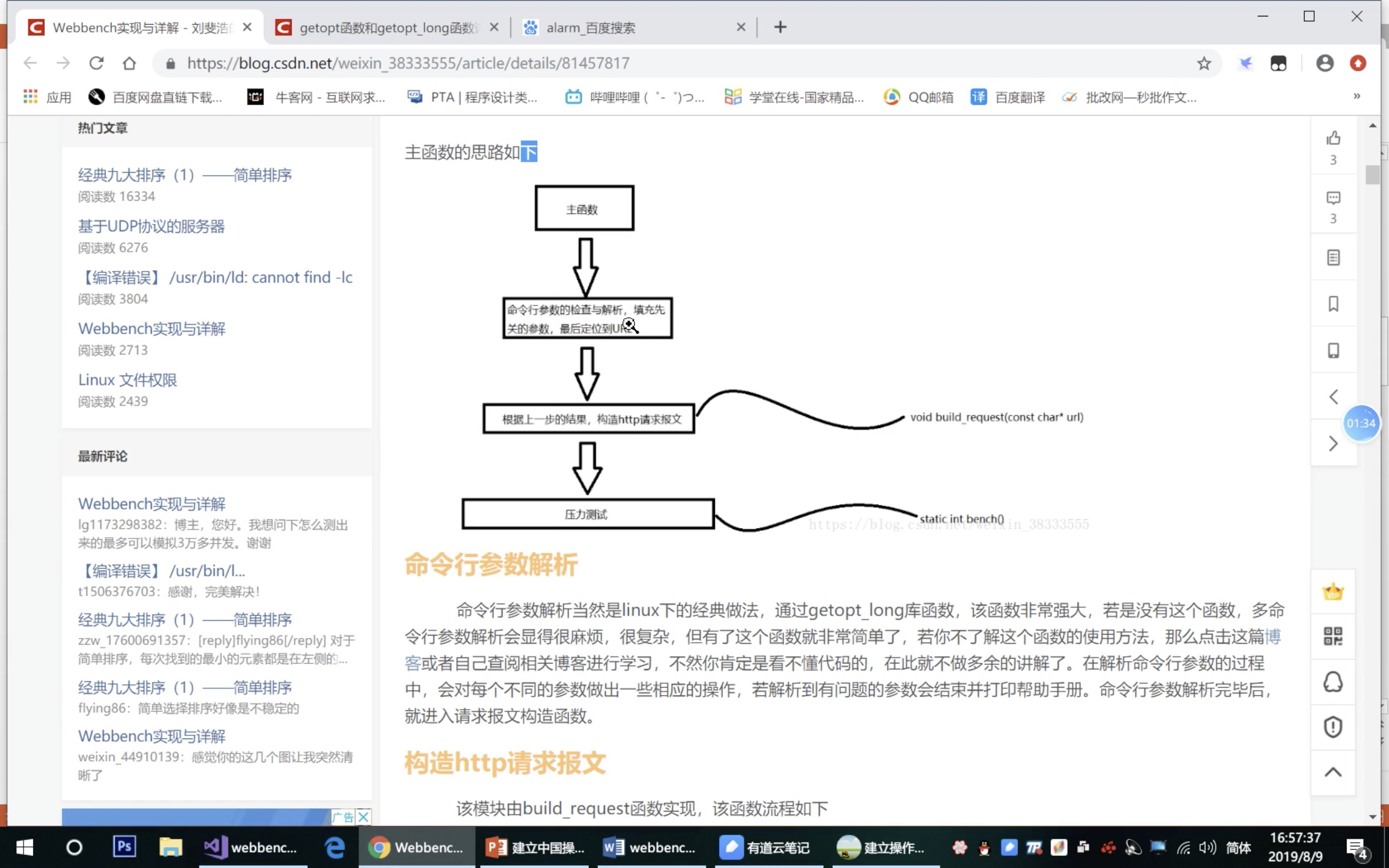
本博客已弃用,当时存在一些小细节错误后期也不再修改了 欢迎来我的新博客 Webench 是一款轻量级的网站测压工具,最多可以对网站模拟 3w 左右的并发请求,可以控制时间、是否使用缓存、是否等待服务器回复等等,且对中小型网站有明显的效果,基本上可以测出中小型网站的承受能力,对于大型的网站,如百度、淘宝这些巨型网站没有意义,因为其承受能力非常大。同时测试结果也受自身网速、以及自身主机的性能与内存的限制,性能好、内存大的主机可以模拟的并发就明显要多。 Webbench 用 C 语言编写,运行于 linux 平台,下载源码后直接编译即可使用,非常迅速快捷,对于中小型网站的制作者,在上线前用 webbench 进行系列并发测试不失为一个好的测试方法。 使用方法也是非常的简单,例如对百度进行测试 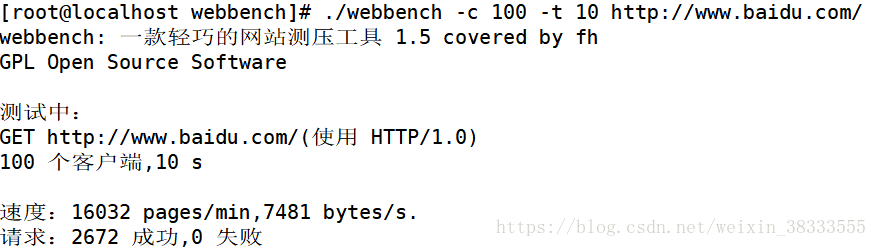 Webbench 实现的核心原理是:父进程 fork 若干个子进程,每个子进程在用户要求时间或默认的时间内对目标 web 循环发出实际访问请求,父子进程通过管道进行通信,子进程通过管道写端向父进程传递在若干次请求访问完毕后记录到的总信息,父进程通过管道读端读取子进程发来的相关信息,子进程在时间到后结束,父进程在所有子进程退出后统计并给用户显示最后的测试结果,然后退出。 下面我从我实现的思路来详细说一下每个过程,非常显然的地方就略过了,有不明白的地方提问后会尽快回复。 源代码主要有三个源文件:Socket.cSocket.hwebbench.c 其中 Sokcet.c 与 Socket.h 封装了对于目标网站的 TCP 套接字的构造,其中 Socket 函数用于获取连接目标网站 TCP 套接字,这一部分后面就不做说明了,重点讲解 webbench.c,其中有些对于各种错误的处理就不在此加以说明了,详见末尾的源码。 详细实现过程主函数的思路如下 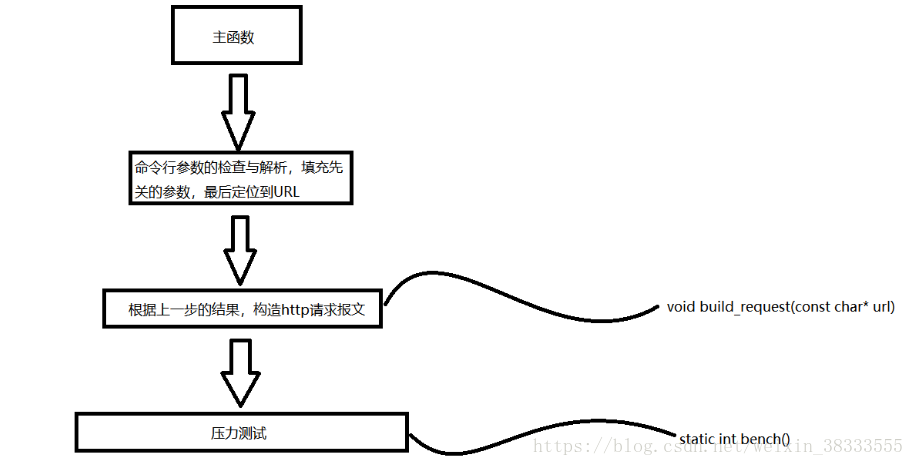
|