论文笔记 —— XLNet
From Google Brain and CMU.
Authors: Zhilin Yang∗, Zihang Dai∗, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le
Title: XLNet: Generalized Autoregressive Pretraining for Language Understanding.
Preprint at 2019.6.20.
Introduction
这篇论文建立在Transformer-XL【作者们ACL2019的工作】的基础之上。看过Transformer-XL的同学应该知道其编码方式其实已经有了挺大的改进,对长文本的编码优于Vanilla Transformer。本文引入了PLM(Permutation Language Model,排列语言模型【Permutation: a way, especially one of several possible variations, in which a set or number of things can be ordered or arranged.】)而抛弃BERT的Mask LM,然后引入Masked Two-Stream Self-Attention解决PLM出现的目标预测问题【见Motivation】,最后用三倍于BERT的语料进行预训练,刷榜SQuAD、GLUE、RACE等。
Motivation
文章从AR(autoregressive,自回归)和AE(autoencoding,自编码)的角度出发,解释论文动机。
AR LM,即自回归语言模型。具体而言,给定一个序列,当前token/时刻只知道前面的信息,而不知道后面的信息,即使分成正向和反向计算当前token时刻的概率分布,也是同样的原则,ELMo、GPT是属于这个范畴。对于一些自然语言理解任务而言,是给定上下文的,即使ELMo把两个的方向计算的信息concat,但也是独立计算,对上下文的编码是有缺陷的。
AE LM,即自编码语言模型。BERT通过预测原始数据里MASK掉的token来预训练语言模型,预测[MASK]使用了上下文信息,弥补了AR LM的缺陷。但是[MASK]只在预训练的时候用到,finetune的时候是不用的,这使得pretrain/train不一致【这点顶一下BERT,我觉得这样更能体现泛化能力】。并且,BERT假定每个[MASK]与其他[MASK]是相互独立的,不能计算序列、长期依赖的联合概率。即使BERT的NSP预训练任务一定程度上给了模型建模句间关系的能力,但是还是对长文本不敏感。
本文结合AR LM和AE LM,在Transformer-XL的基础上提出generalized autoregressive method,XLNet。
- 所有的分解序列作为一个集合,对所有采样序列,XLNet按照AR LM的计算方式求对数似然期望的极大值。通常,当前token的上文包含left和right的tokens:比如原始序列为1-2-3-4,分解序列中采样一个为2-4-1-3,那么如果当前token为3,XLNet的方式就可以看到所有的信息【当然这也是理想情况】,而AR LM只能看到1和2。
- 引入Transformer-XL的segment recurrence mechanism和relative encoding scheme。
- 引入Masked Two-Stream Self-Attention解决PLM出现的目标预测歧义【the ambiguity in target prediction】问题。举个例子,比如分解序列中采样一个为2-4-6-1-3-5的序列,假设要预测位置[1]的token,按照经典的Transformer来计算next-token的概率分布,位置[1]的token的概率就是通过[2,4,6]位置上的tokens来计算。但是如果以这种方式去预测next-token,这对[3,5]的预测就会产生影响,因为如果[1]的预测出现错误会把错误传给后面。对后面每一个token的预测,需要建立在之前token都已知的条件下。因此本文计算了两个self-attention计算方式,一个mask当前词,attention值记为g;一个已知当前词,attention值记为h。最后假设self-attention一共有M层,用第M层、t时刻的g_t,去预测词x_t。
Model
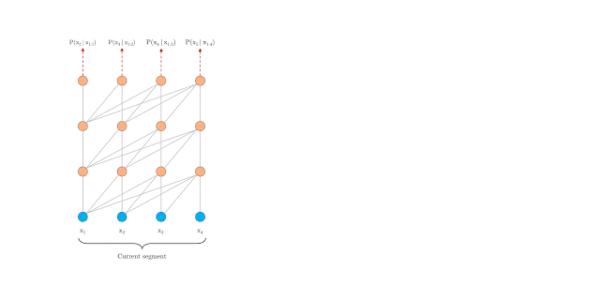
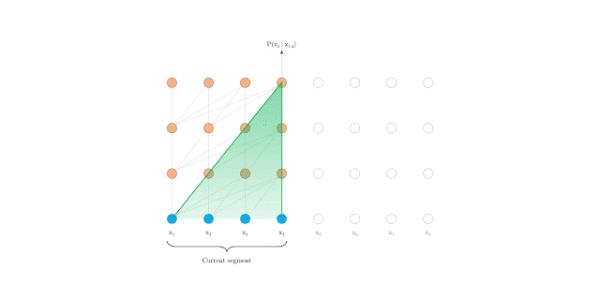
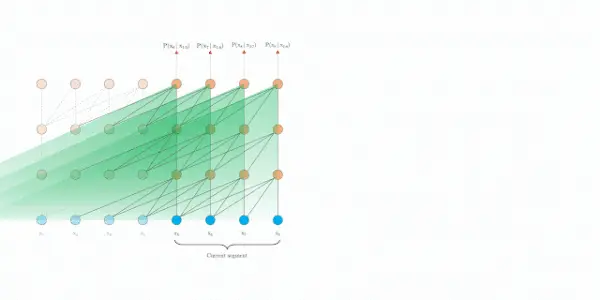
Permutation Language Modeling
首先会根据输入序列的长度采样排列集合,然后用Transformer中attention mask的方式实现每个排列情况,如果原始序列长度为T,那么理论上一共有T的阶乘种情况。PLM的目标函数就是所有排列情况(论文里设定:统共T种,如何采样的并没有说,只是说大概率上下文会出现在被预测词的前面)的期望最大:
这样pretrain和finetune阶段就一样了,输入都是原始序列,通过attention mask实现随机产生的排列。例如排列是2-4-3-1,那么在预测X3的时候就只有2、4作为先验,并且2、4的位置信息是通过Zt来体现的,这样也保留了排列的时序信息。下图是排列语言模型的表现形式:
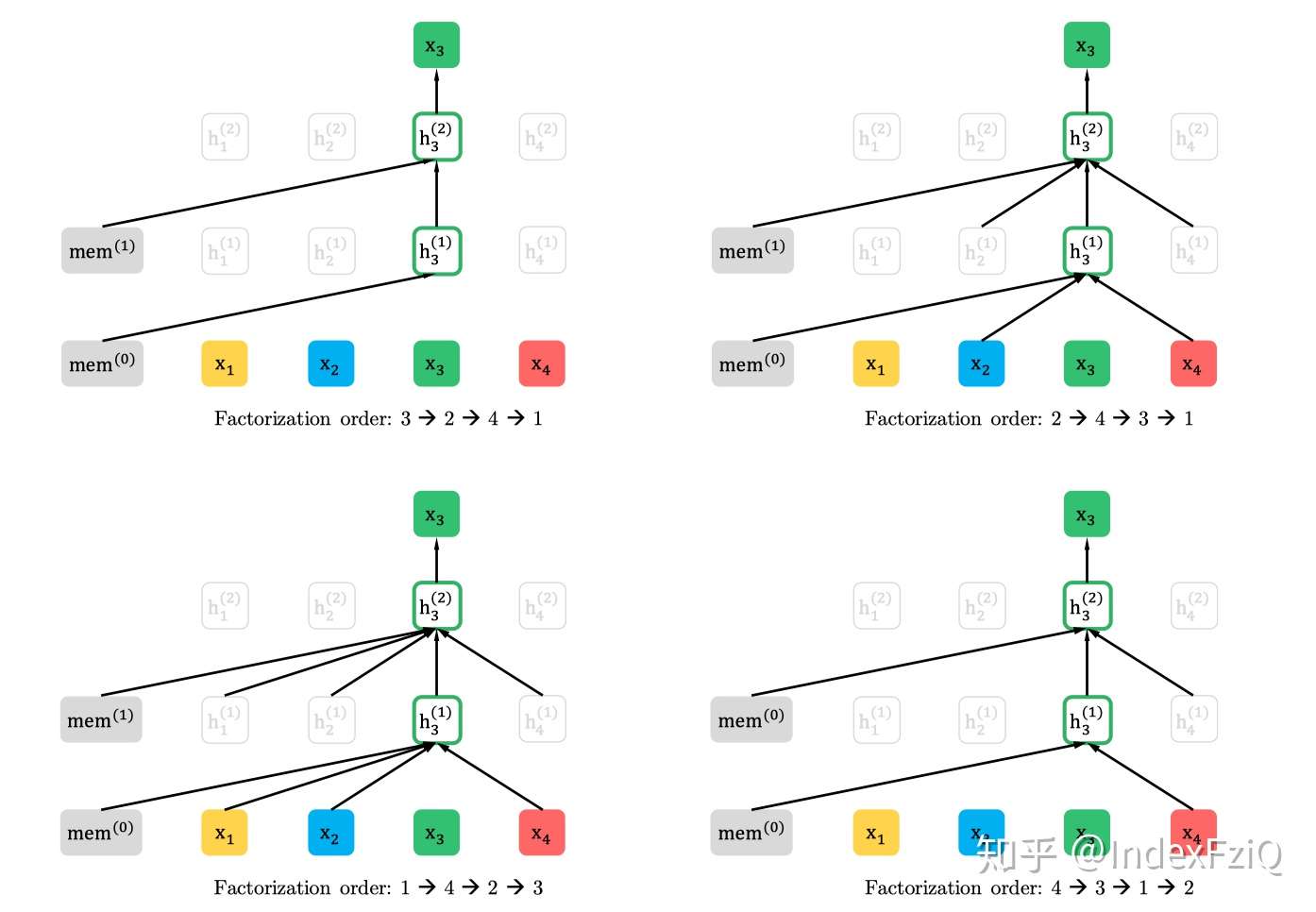
注:假设要预测t=3的词,按照不同的排列顺序,h_3的上文都不一样,用attention-mask的方式得到t=3的上文。
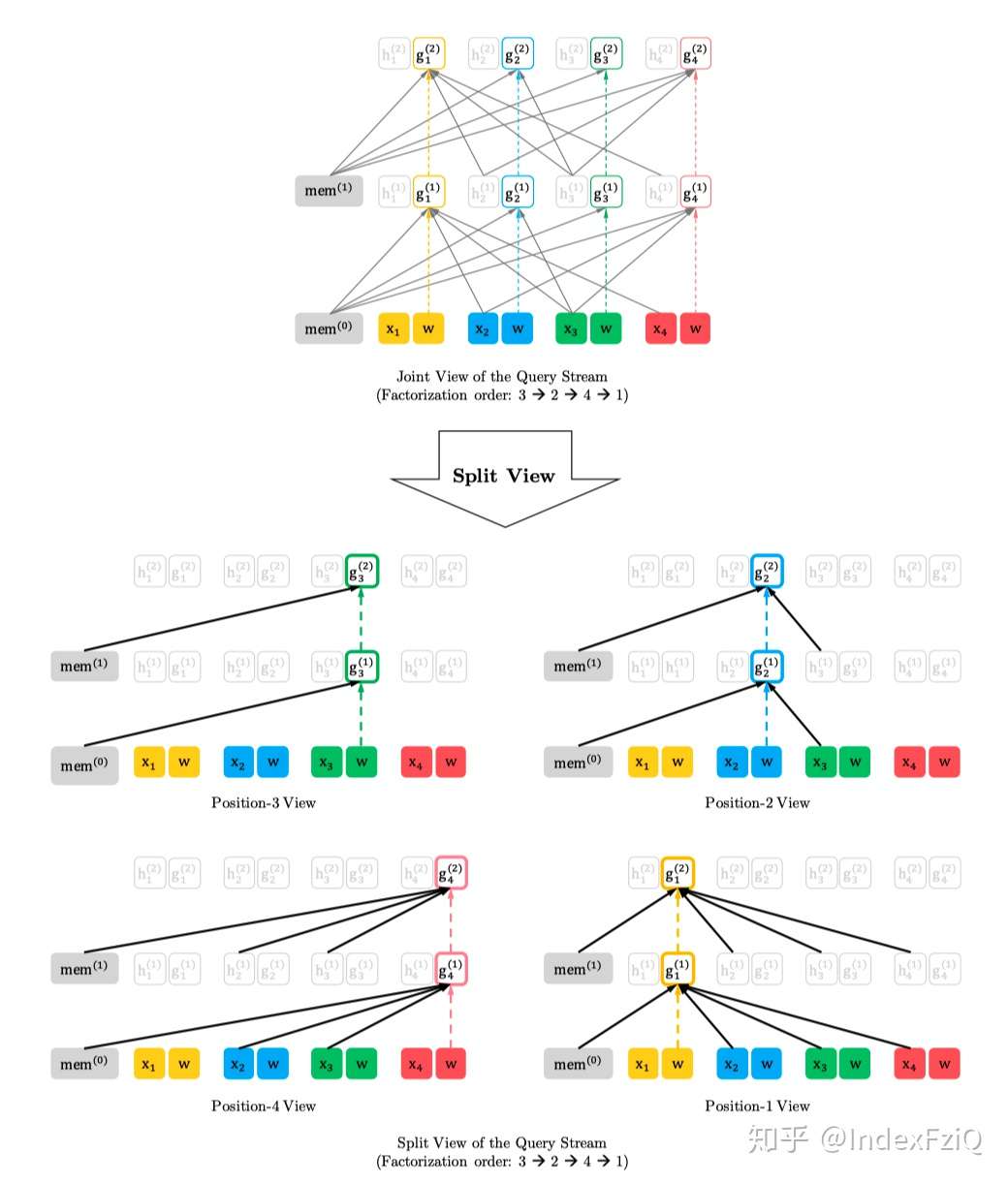
Two-Stream Self-Attention for Target-Aware Representations
上面是构造输入,这里就是自回归地得到每一时刻的概率分布,示意图如下:
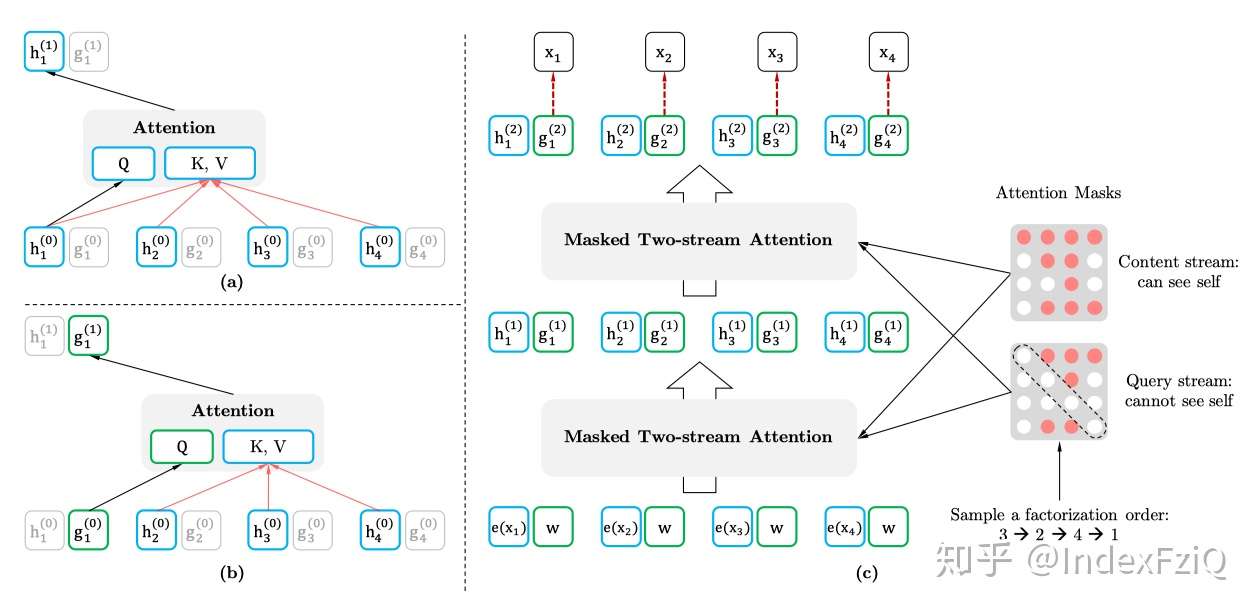
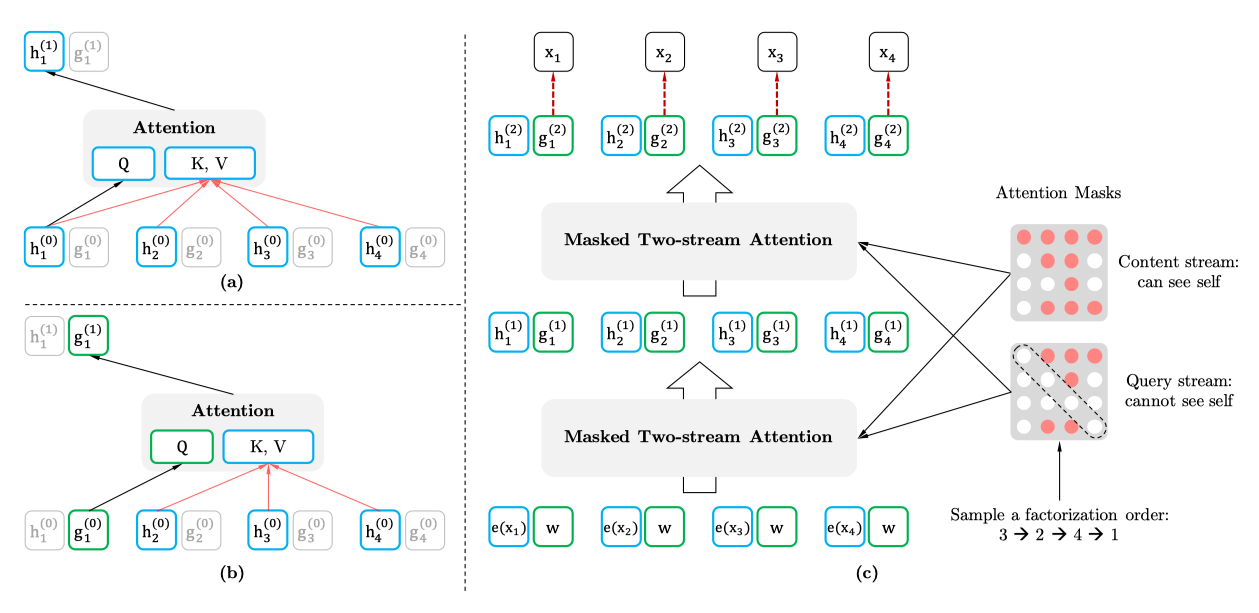
动机部分已经介绍过为什么要计算两个self-attention。
(a)代表context stream self-attention,以[1,t]时刻的词作为K、V,t时刻的词作为Q计算当前词的信息,把排列之后的原始序列信息用h记忆起来。
(b)代表query stream self-attention,mask掉当前词,以[1,t-1]时刻的词作为K、V,t时刻的词作为Q预测当前词,得到概率分布。
(c)代表通过多层的masked two-stream attention,最后用t时刻的 来预测
。
t时刻的概率分布如下:
其中, 表示的是位置向量,用以保留采样排列的位置信息,在mask self-attention的时候就知道当前需要预测词的位置。
如果没有,当词的位置不同,但是上文一样时,两个词算出来的概率是一样的。例如2-3-1-4-5和2-3-1-5-4,两个排列中,4和5的上文一样,算概率的时候就会一样【如下公式】,很显然这是错误的,不同位置的概率分布在ground-truth里是不一样的:
的计算公式如下:
其中, ,
,分别是随即初始化的向量和词向量。
引入位置向量之后,最终在预训练的时候也没有每一个token都预测,作者设置了一个超参数K,设定只预测序列最后1/K=的词[c+1, |z|]:
Transformer-XL
确定好目标函数之后,框架确定为Transformer=XL自回归语言模型。特点是relative positional encoding scheme和segment recurrence mechanism,更好地处理长文本,提升计算效率。具体不介绍了,详见参考文献[2]。链接是Transformer-XL的论文笔记。
XLNet的独特之处还有关于每个词的位置信息都会算一个权重,用 表示。其中
是计算标准attention时的query,
和
表示一个序列里的两个位置,
表示
和
在同一个大片段里,
表示
和
在不同大片段里,对比BERT的NSP,这个位置编码方式更加灵活。
Overview
按照3-2-4-1的编码顺序content stream mask self-attention,看到当前词。
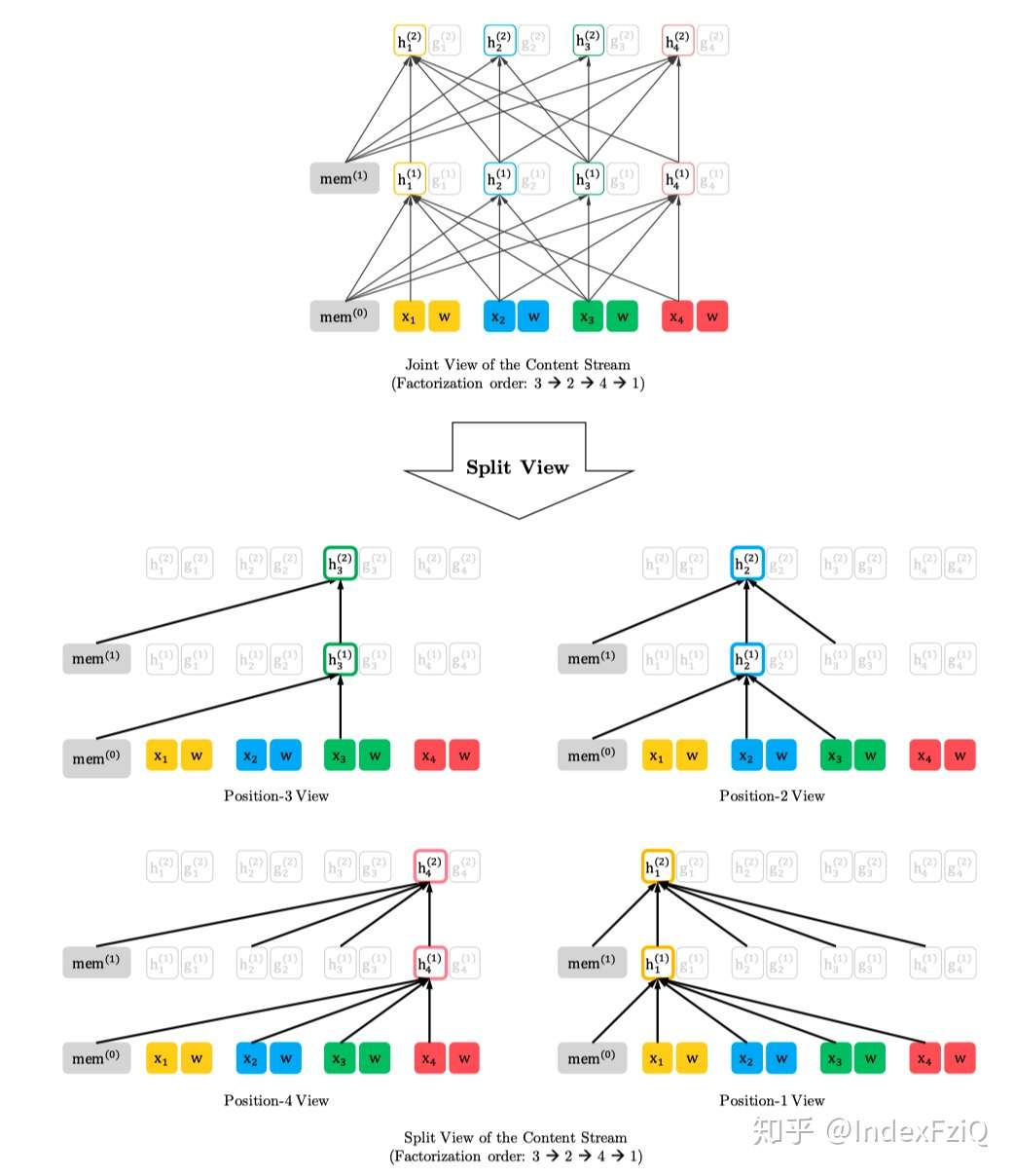
按照3-2-4-1的编码顺序query stream mask self-attention,看不到当前词。
Pretraining and Implementation
XLNet-Large和BERT-Large的参数量是差不多的,24层的Transformer-XL。经过处理,最终得到Wikipedia-2.78B,BooksCorpus-1.09B,Giga5-4.75B,ClueWeb-4.30B和Common Crawl respectively-19.97B,一共32.89B,近3倍于BERT的语料作为模型输入。序列长度512,memory维度384,batch-size为2048,用512块TPU v3跑了500K step用了2.5天。一般我种子才会设置成2048。
XLNet-Base和BERT-Base用的语料一样。但是貌似没说参数量一样。更详细的参数设置见论文补充材料[1]A.3。
Experiment
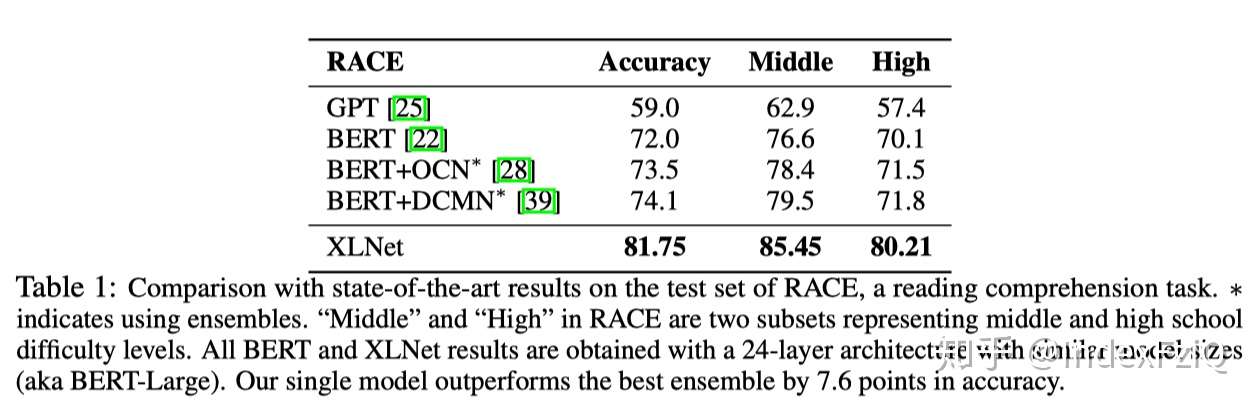
第一个实验是在RACE多选型阅读理解数据集上,单模型比第二名准确率提高了7.6%。
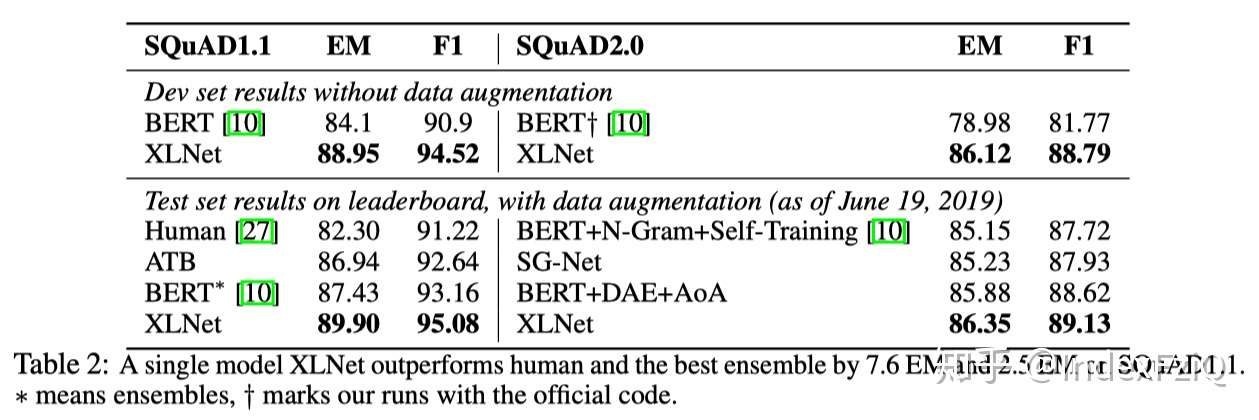
第二个实验是在SQuAD抽取式阅读理解数据集上,单模型效果相对于BERT,v1的F1值提高3.6,v2的F1值提高7.0。
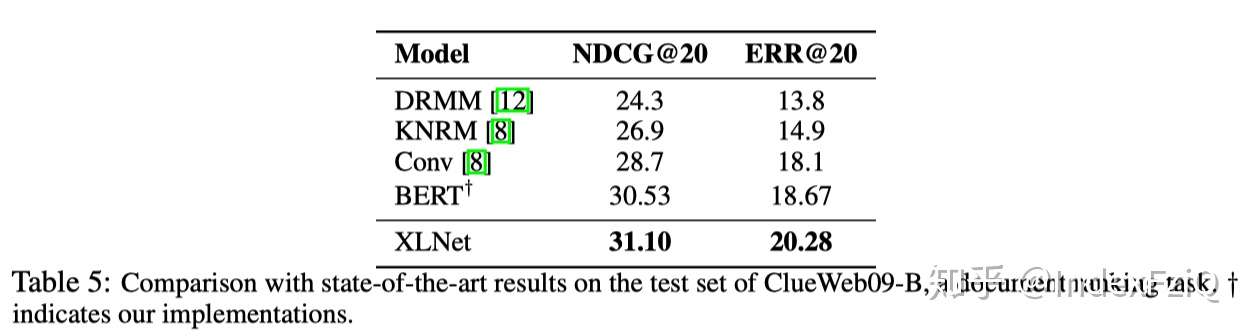
第三个实验是在文本分类数据集上,评价指标是错误率。单模型已经达到SOTA。
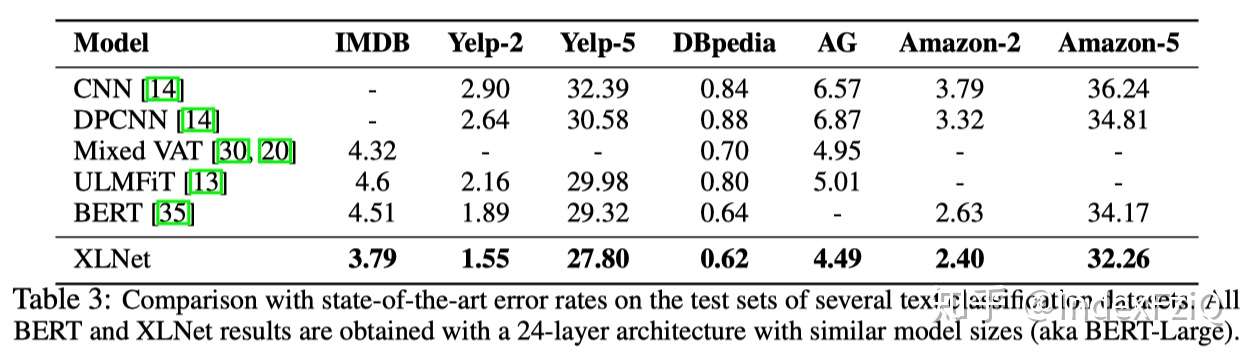
第四个实验是在GLUE,包括9个自然语言理解任务,评价指标是准确率。单模型比BERT在每个任务上都有提升,并且在NLI类任务、MRPC、RTE、STS-B提升显著,只有QQP、CoLA上没有ALICE好。
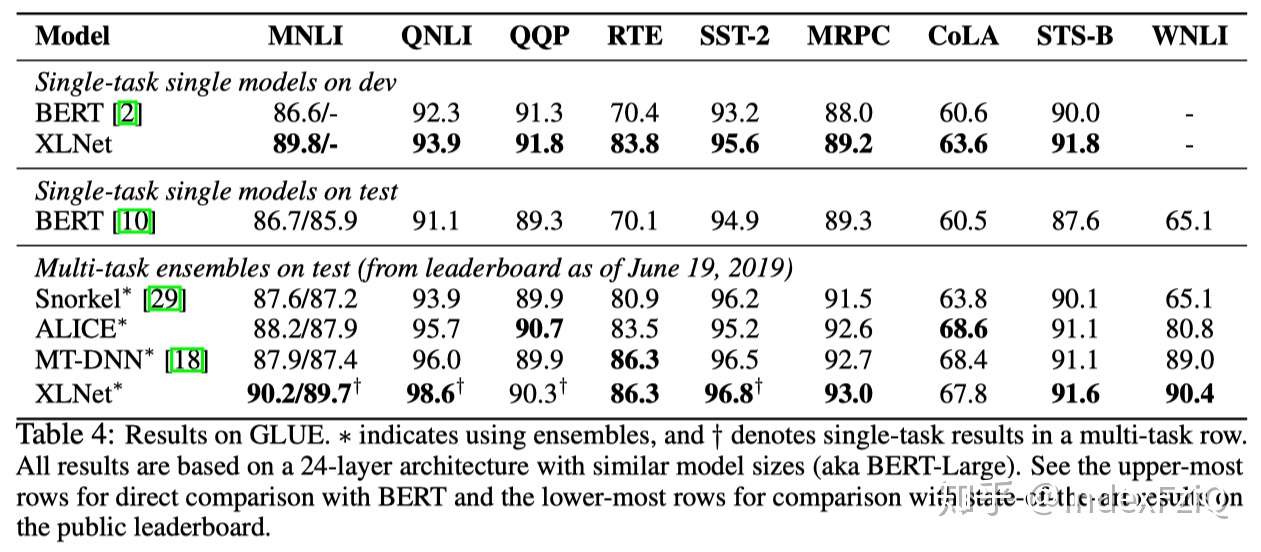
第五个实验是文档排序任务,根据query重排序出Top-100的文档,效果比BERT好一些。
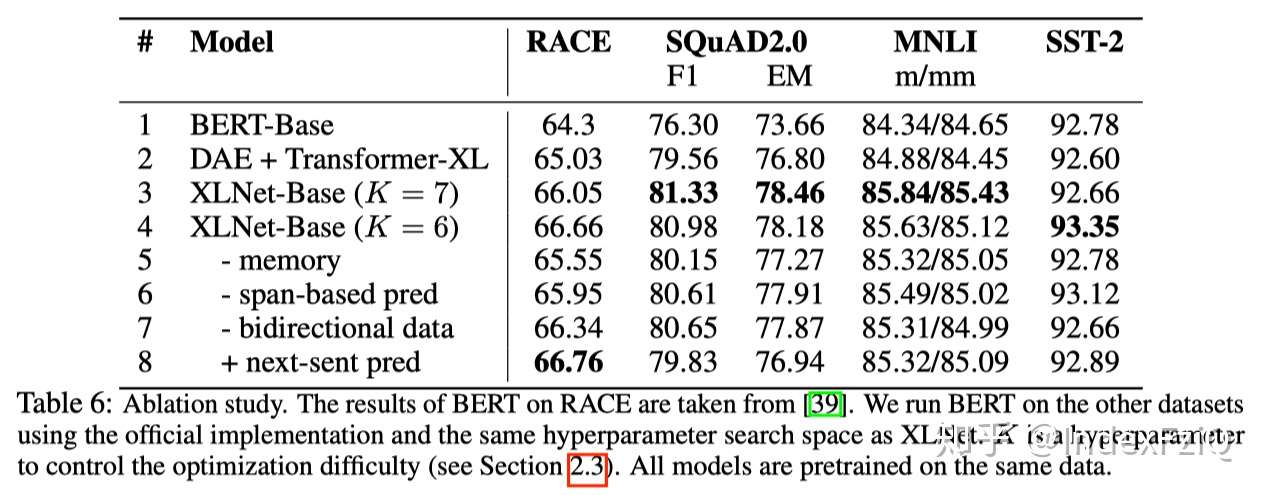
第六个实验是去除实验:2.只用Transformer-XL+DAE效果比BERT(Transformer+DAE)好,说明了Transformer-XL的有效性。3和4说明了PLM的有效性,但是K这个超参数是经验值,也没有与K=1的情况相比。5-8应该是在4的基础上,重要性逐渐减小:5说明了Transformer-XL里memory机制的有效性,6说明了片段预测的有效性,7说明正反向输入数据对结果影响不大,8说明了BERT的NSP任务对XLNet并不是很奏效,影响也不大。
Conclusion
首先文章动机很明确,指出了当前AR LM和AE LM的优缺点,在Transformer-XL的基础上结合AE捕获上下文的优点。
1. 提出了PLM预训练,用mask attention的方法实现factorization order的输入,大概率得到上下文信息。
2. 用two-stream self-attention,弥补自回归语言模型中目标预测歧义的缺陷。
本文实现factorization order的方式就很巧妙,保证了pretrain/finetune的一致性。但是这样以来,其实弱化了自然语言本身的时序信息,实验结果表明:更好地编码上下文更重要。不过XLNet刷榜各大自然语言理解数据集,特别是RACE和SQuAD提升很大,但是用的计算资源真是令人叹为观止。
最后抛出几个问题:
- 去除实验中,NSP为什么在XLNet-BASE模型中不起作用?NSP在BERT中每个任务上均有提升。难道是相对位置编码的原因?
- RTE任务上,XLNet单模型(多了2倍语料+PLM+相对位置编码+Transformer-XL)提升了13.4的准确率,原因为何?是数据还是模型?RTE就是标准的文本蕴含任务。
- XLNet的large model提升更大,base model一般般,原因为何?
都是个人的理解,如有错误,评论区或者E-mail展开讨论。
Reference
[1]. Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov and Quoc V. Le. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv preprint arXiv:1906.08237, 2019.
[2]. Zihang Dai, Zhilin Yang, Yiming Yang, William W Cohen, Jaime Carbonell, Quoc V Le, and Ruslan Salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860, 2019.
文章被以下专栏收录
推荐阅读
从2017年顶会论文看 Attention Model
前言:2017年KDD,Sigir以及Recsys会议被接收的论文早已公示,本文对这些会议中Attention Model相关的10篇论文进行了整理,主要包括Attention Model的变型与应用。其中,本文所使用的图片除…
论文笔记:ENCODER-AGNOSTIC ADAPTATION
这篇论文(ENCODER-AGNOSTIC ADAPTATION FOR CONDITIONAL LANGUAGE GENERATION,文章名里太长写不下了)是哈佛大学今年八月份发布的论文,探究了改造预训练语言模型使得它能够接收任意encod…

论文笔记 - Memory Networks 系列

Bert 源码笔记
论文笔记 —— Transformer-XL
From Google Brain and CMU.
Authors: Zihang Dai∗, Zhilin Yang∗, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov
Title: TransformerXL: Attentive Language Models Beyond a Fixed-Length Context.
In: ACL, 2019
Introduction
为了帮助理解XLNet,本文对其核心框架Transformer-XL作一个解读。本文发表在ACL2019上,论文想要解决的问题:如何赋予编码器捕获长距离依赖的能力。目前在自然语言处理领域,Transformer的编码能力超越了RNN,但是对长距离依赖的建模能力仍然不足。在基于LSTM的模型中,为了建模长距离依赖,提出了门控机制和梯度裁剪,目前可以编码的最长距离在200左右。在基于Transformer的模型中,允许词之间直接建立联系【self-attention】,能够更好地捕获长期依赖关系,但是还是有限制。
Motivation
Transformer编码固定长度的上下文,即将一个长的文本序列截断为几百个字符的固定长度片段(segment),然后分别编码每个片段[1],片段之间没有任何的信息交互。比如BERT,序列长度的极限一般在512。动机总结如下:
- Transformer无法建模超过固定长度的依赖关系,对长文本编码效果差。
- Transformer把要处理的文本分割成等长的片段,通常不考虑句子(语义)边界,导致上下文碎片化(context fragmentation)。通俗来讲,一个完整的句子在分割后,一半在前面的片段,一半在后面的片段。
文章围绕如何建模长距离依赖,提出Transformer-XL【XL是extra long的意思】:
- 提出片段级递归机制(segment-level recurrence mechanism),引入一个记忆(memory)模块(类似于cache或cell),循环用来建模片段之间的联系。
- 使得长距离依赖的建模成为可能;
- 使得片段之间产生交互,解决上下文碎片化问题。
- 提出相对位置编码机制(relative position embedding scheme),代替绝对位置编码。
- 在memory的循环计算过程中,避免时序混淆【见model部分】,位置编码可重用。
小结一下,片段级递归机制为了解决编码长距离依赖和上下文碎片化,相对位置编码机制为了实现片段级递归机制而提出,解决可能出现的时序混淆问题。
Model
Vanilla Transformer
普通的Transformer是如何编码的?[2]给了动图,很形象,每个segment分别编码,相互之间不产生任何交互。

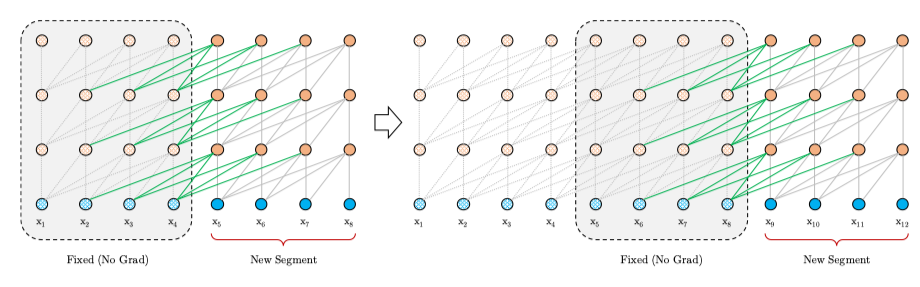
segment-level recurrence mechanism
为了解决长距离依赖,文章引入一个memory状态。
在训练过程中,每个片段的表示为最后的隐层状态,表示片段的序号,表示片段的长度,表示隐层维度。
在计算片段的表示时,用memory缓存片段层的隐层状态,用来更新,这样就给下一个片段同了上文,长距离依赖也通过memory保存了下来。并且,最大可能的依赖长度线性增长,达到 。
relative position embedding scheme
在实现片段级递归时遇到一个问题:如果采用绝对位置编码,不同片段的位置编码是一样的,这很显然是不对的。公式如下:
表示片段
的词向量,
表示绝对位置向量,可以看出,两个片段之间所用的位置向量是一样的。如果一个词出现在两个片段中
、
,按照绝对位置编码方式,它们的表示向量是一样的,难以区分。
因此,本文引入相对位置编码机制,计算self-attention公式如下:
- 引入相对位置编码,用的是Transformer里用的sinusoid encoding matrix,不需要学。
-
和
是需要学习的参数,这是这部分的关键。在计算self-attention时,由于query所有位置对应的query向量是一样的,因此不管的query位置如何,对不同单词的attention偏差应保持相同。
-
、
也是需要学习的参数,分别产生基于内容的key向量和基于位置的key向量。
最后再经过Masked-Softmax、Layer Normalization、Positionwise-Feed-Forward得到最终预测用的,详细的过程看论文[1]提供的补充材料B。
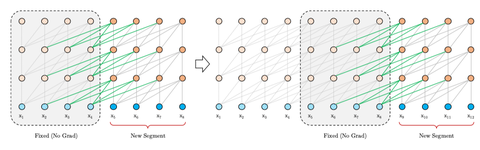
faster evaluation
在评估时, Transformer-XL比Vanilla Transformer具有更长的有效上下文,并且Transformer-XL能够在不需要重新计算的情况下处理新段中的所有元素,显著提高了速度。下图是评估阶段的对比图:
Vanilla Transformer
Transformer-XL
Experiment
实验部分是对基于Transformer-XL的语言模型进行评估,分为字符级和词级。评价指标分别是bpc(每字符位数)和PPL(困惑度),越小越好。enwiki8和text8用的是bpc。Transformer-XL在多个语言模型基准测试中实现了最先进的结果。 Transformer-XL第一个在char级语言模型基准enwiki8上突破1.0。

去除实验:
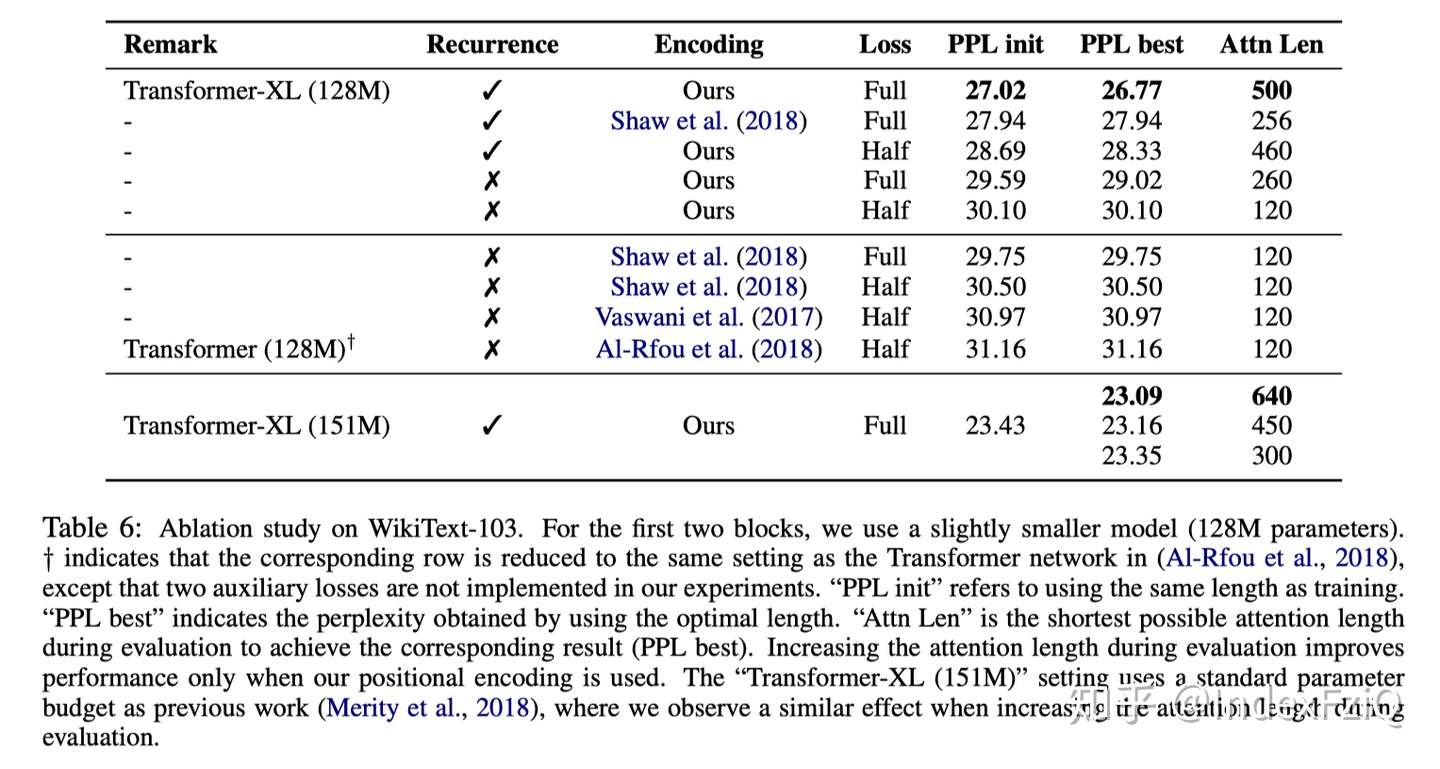
重点是本文设计的相对位置编码优于其他工作,memory的设计也有很大的提升。
补充材料中Transformer-XL生成的文本也比较有意思,感兴趣可以去跳转page 17 in [1]。
最后,Transformer-XL在评估阶段的速度也明显快于 vanilla Transformer,特别是对于较长的上下文。例如,对于 800 个字符的上下文长度,Transformer-XL 比Vanilla Transformer 快 363 倍;而对于 3800 字符的上下文,Transformer-XL 快了 1874 倍。
Conclusion
Transformer-XL从提高语言模型的长距离依赖建模能力出发,提出了片段级递归机制,设计了更好的相对位置编码机制,对长文本的编码更有效。不仅如此,在评估阶段速度更快,很巧妙。在此基础上,XLNet[4]从无监督预训练方法出发,对比自回归语言模型和自编码语言模型的优缺点,设计出了排队语言模型,在自然语言处理下游任务中大放异彩。预训练语言模型属于自监督学习的范畴,这两篇论文从语言模型的根本问题出发(建模长距离依赖/更好地编码上下文),提出一个主要方法(片段级递归机制/排列语言模型),在实现过程中发现需要重新设计子模块(相对位置编码/双流注意力机制),最后完成significant work,使得设计的任务很有说服力,理论性强。
Reference
[1]. Zihang Dai, Zhilin Yang, Yiming Yang, William W Cohen, Jaime Carbonell, Quoc V Le, and Ruslan Salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860, 2019.
[2]. 机器之心报道. https://zhuanlan.zhihu.com/p/56027916.
[3]. 官方代码. https://github.com/kimiyoung/transformer-xl.
[4]. Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov and Quoc V. Le. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv preprint arXiv:1906.08237, 2019.
文章被以下专栏收录
推荐阅读
基于GCN的文本分类
本文主要介绍发表在AAAI 2019上的文章Graph Convolutional Networks for Text Classification这篇文章主要是用图卷积神经网络(GCN)来做文本分类。文本分类是NLP中的一个很基础的问题,目前…
Transform详解(超详细) Attention is all you need论文
这篇文章需要熟悉attention,参考上一篇文章:Atention模型一、背景自从Attention机制在提出之后,加入Attention的Seq2Seq模型在各个任务上都有了提升,所以现在的seq2seq模型指的都是结合r…
Transformer结构及其应用详解--GPT、BERT、MT-DNN、GPT-2
【NLP】BERT中文实战踩坑
终于用上了bert,踩了一些坑,和大家分享一下。 我主要参考了奇点机智的文章,用bert做了两个中文任务:文本分类和相似度计算。这两个任务都是直接用封装好的run_classifer,py,另外两个没…
2 条评论