https://www.bilibili.com/video/BV1s4411e7Pz?p=7
2019最新快速玩转SparkGraphx系列【千锋大数据】
https://blog.csdn.net/zcf1002797280/article/details/51075656/

https://endymecy.gitbooks.io/spark-graphx-source-analysis/content/build-graph.html
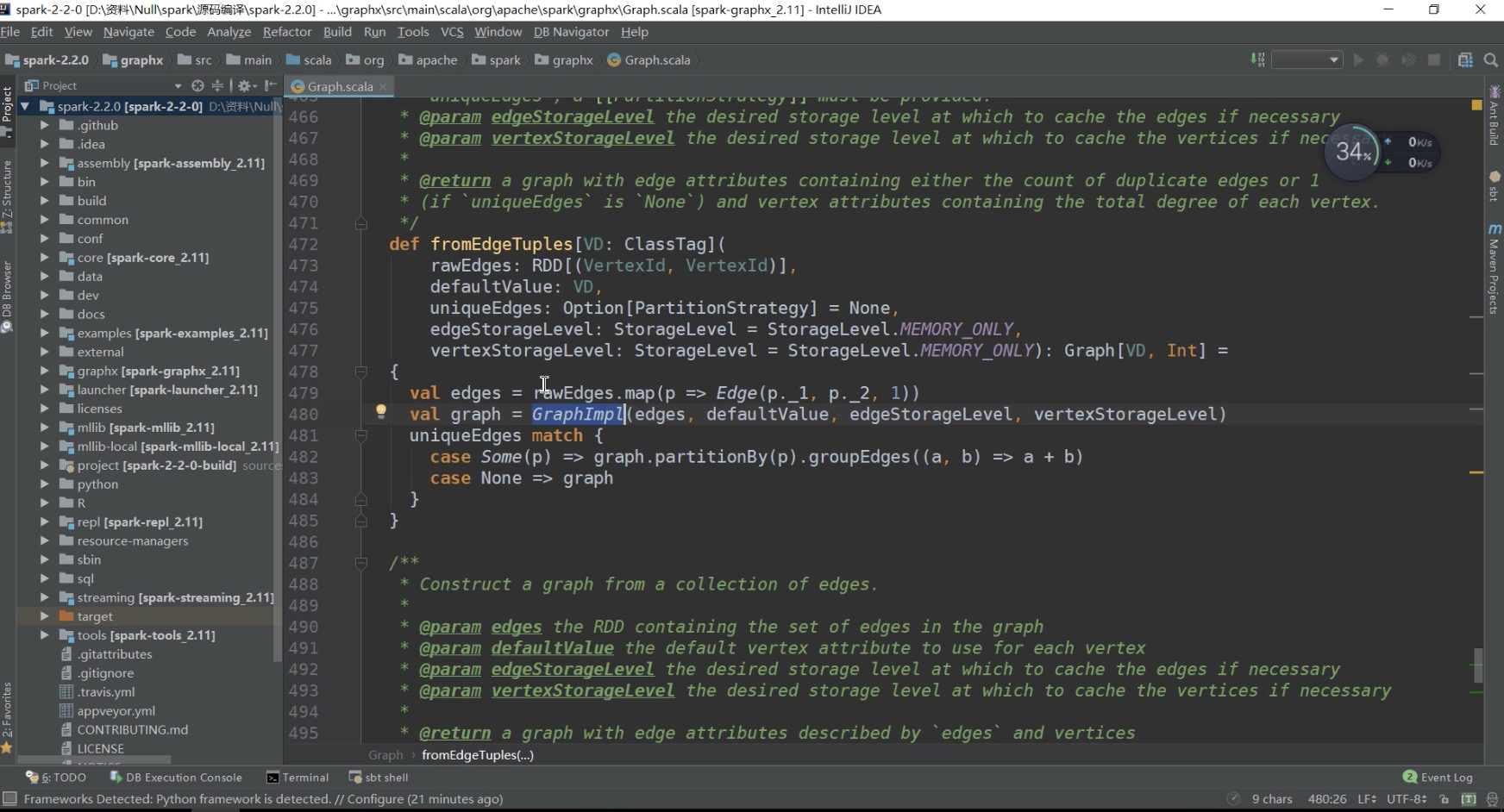
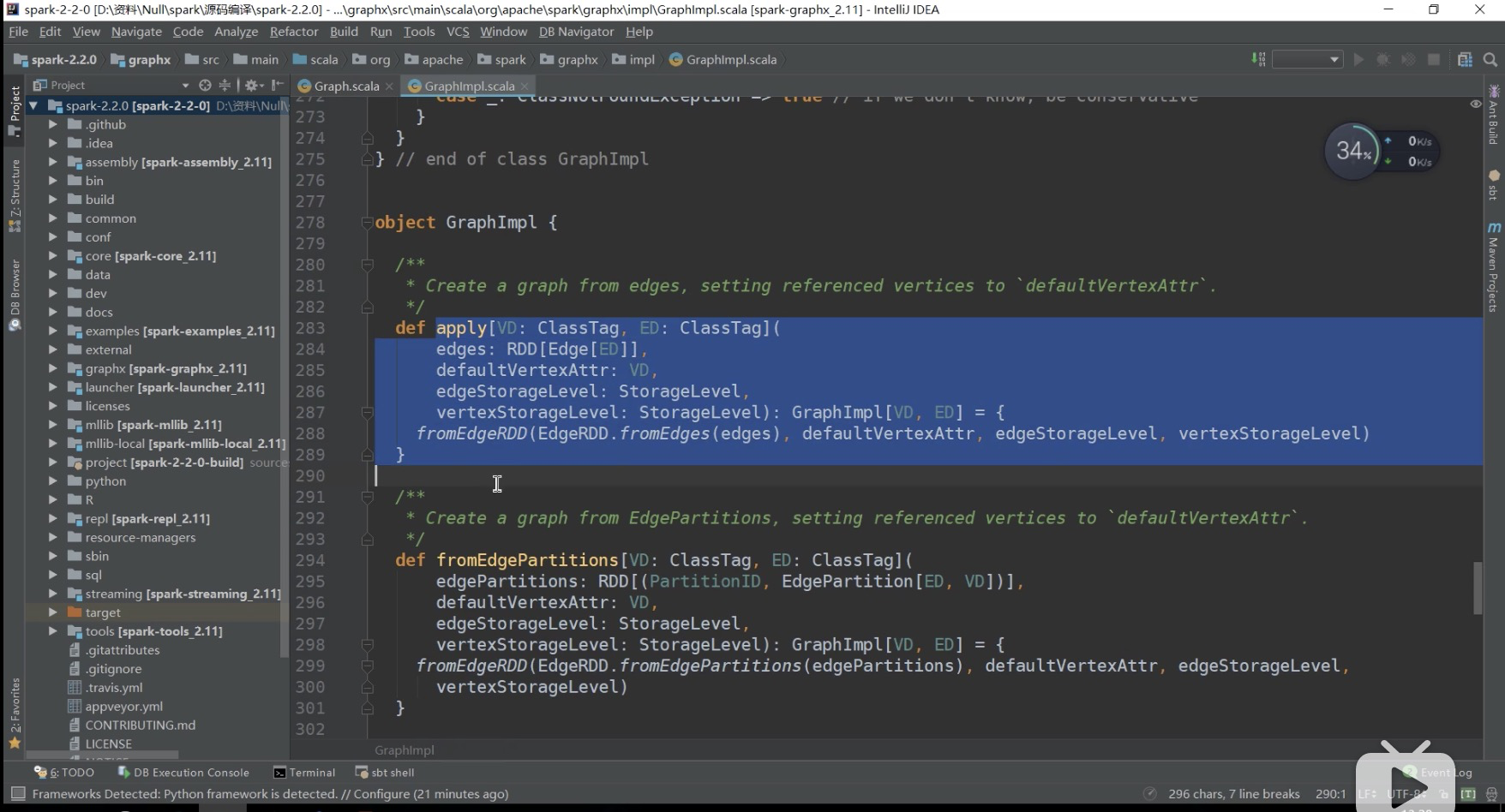
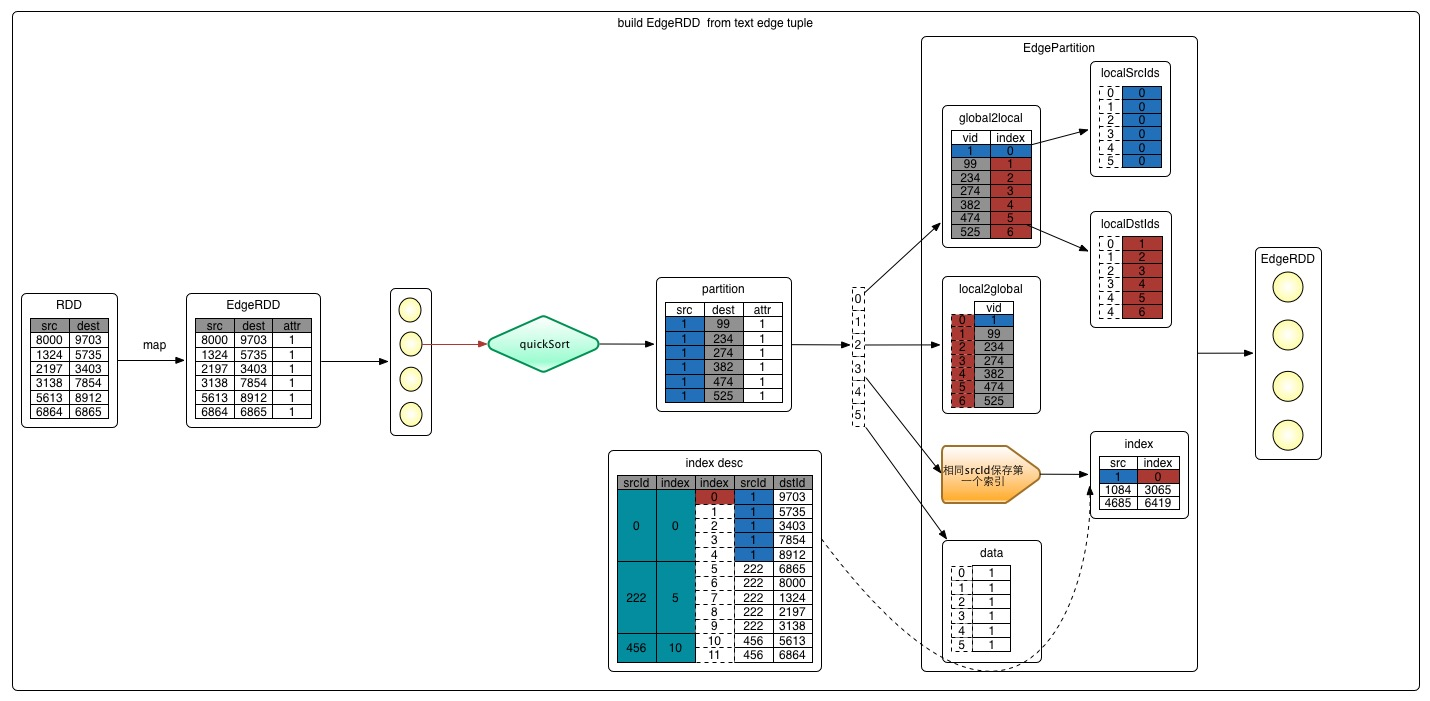
构建图的过程很简单,分为三步,它们分别是构建边EdgeRDD、构建顶点VertexRDD、生成Graph对象。下面分别介绍这三个步骤。
StorageLevel = StorageLevel.MEMORY_ONLY
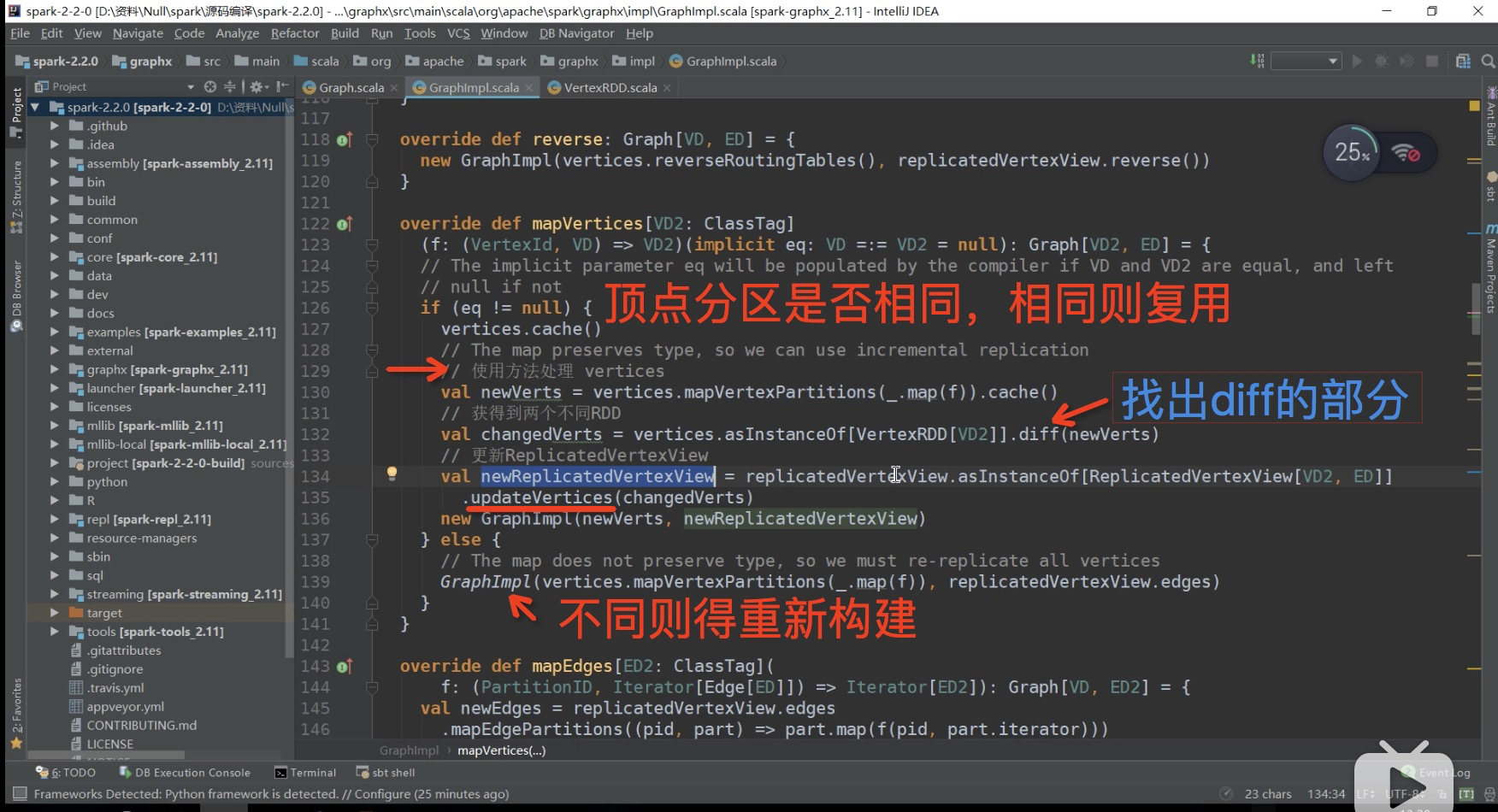
toEdgePartition():对边进行排序(按srcId),排序是为了遍历时顺序访问,加快访问速度;填充localSrcIds, localDstIds, data, index, global2local, local2global, vertexAttrs;可以通过根据本地下标取取VertexId,也可以根据VertexId取本地下标,取相应的属性。



- P1千锋大数据教程:01. 好程序员_快速玩转SparkGraphx系列之Graphx的优势
- P2千锋大数据教程:02. 好程序员_快速玩转SparkGraphx系列之弹性分布式属性图(图计算的优势)
- P3千锋大数据教程:03. 好程序员_快速玩转SparkGraphx系列之Graphx图存储原理
- P4千锋大数据教程:04. 好程序员_快速玩转SparkGraphx系列之Partition分区策略
- P5千锋大数据教程:05. 好程序员_快速玩转SparkGraphx系列之Graphx中的vertices、edges、triples
- P6千锋大数据教程:06. 好程序员_快速玩转SparkGraphx系列之图构建
- P7千锋大数据教程:07. 好程序员_快速玩转SparkGraphx系列之图构建之方法
- P8千锋大数据教程:08. 好程序员_快速玩转SparkGraphx系列之图构建之过程
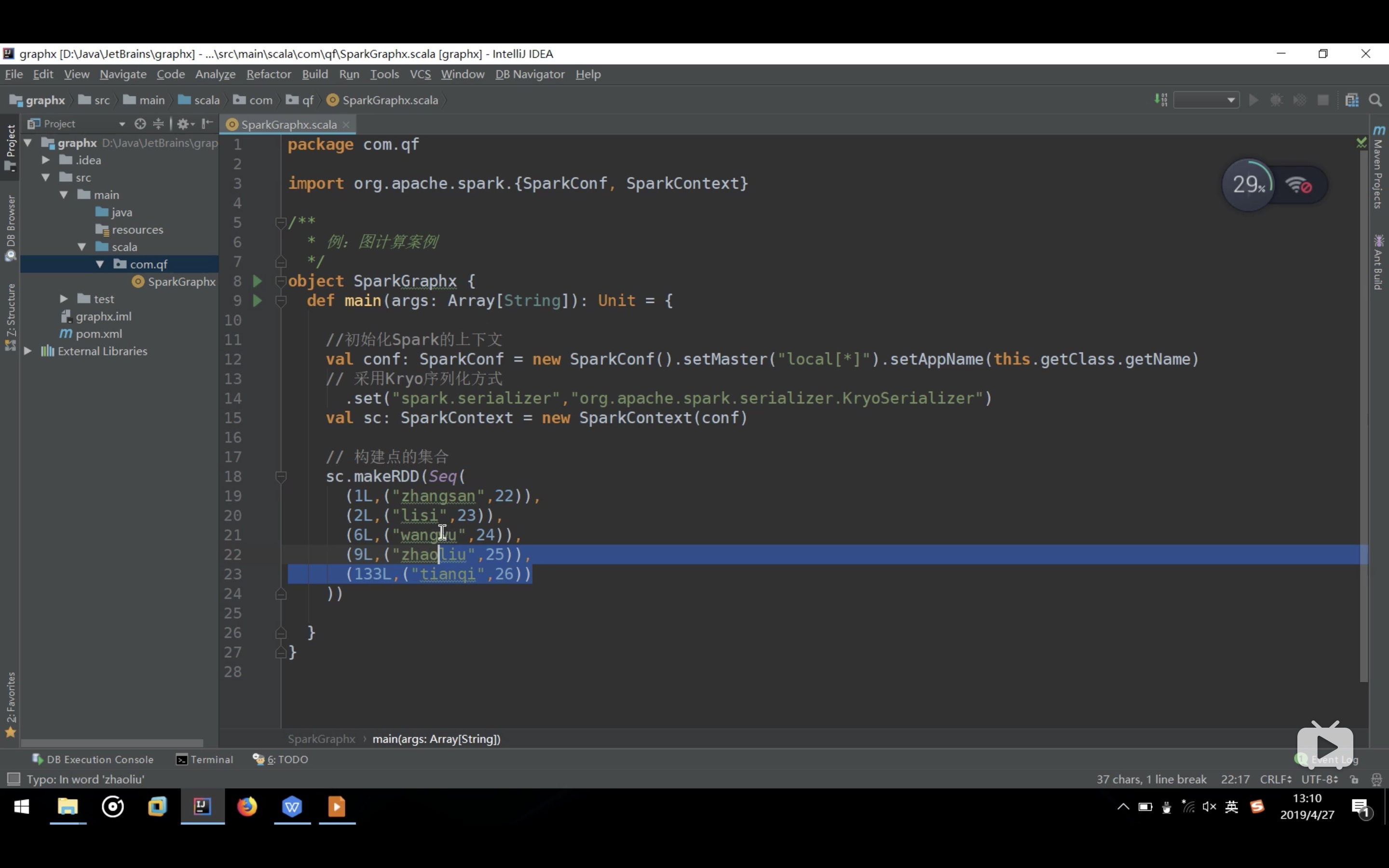
- P9千锋大数据教程:09. 好程序员_快速玩转SparkGraphx系列之构建点集合
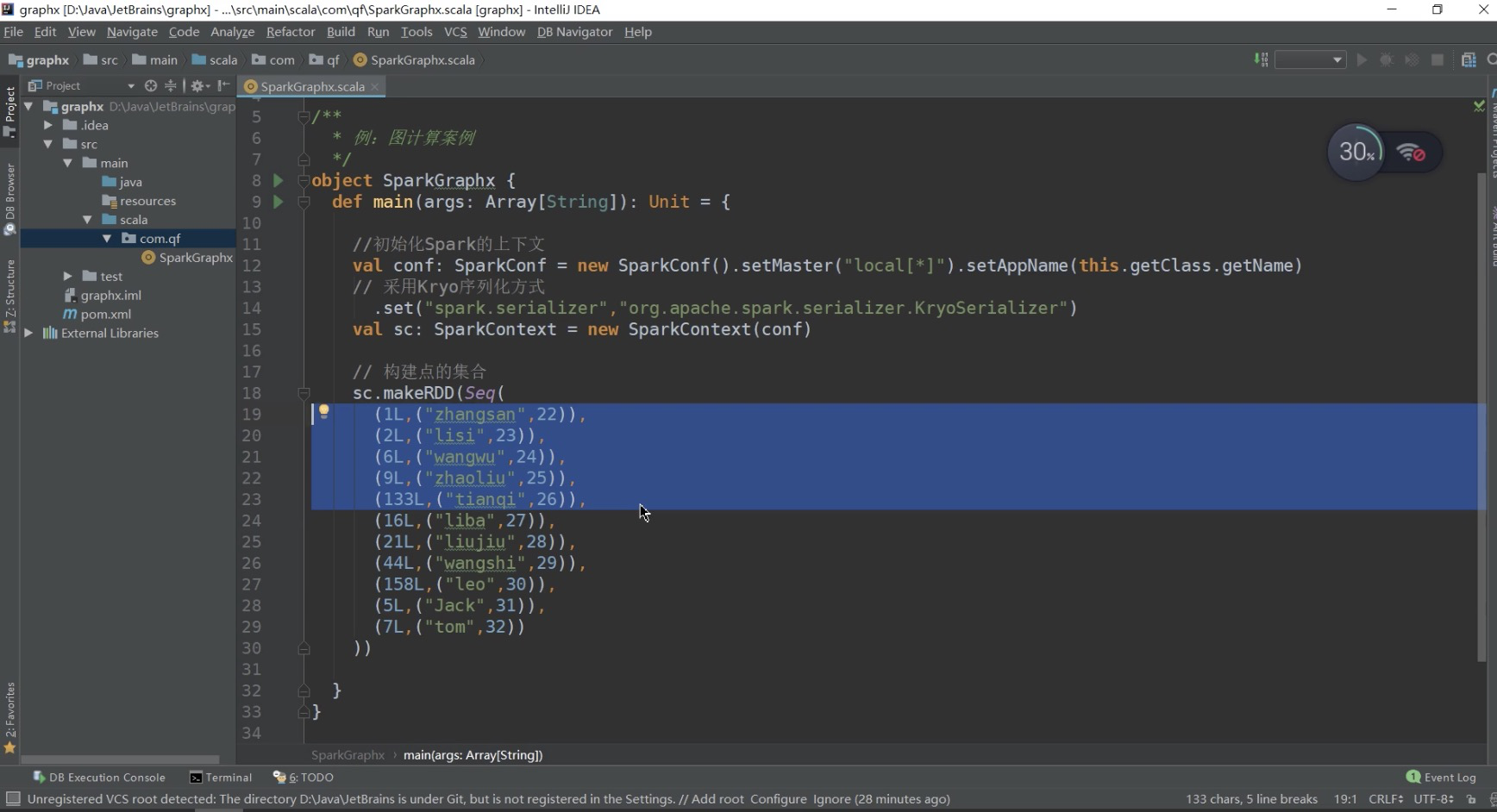
- P10千锋大数据教程:10. 好程序员_快速玩转SparkGraphx系列之构建点和边的集合例子
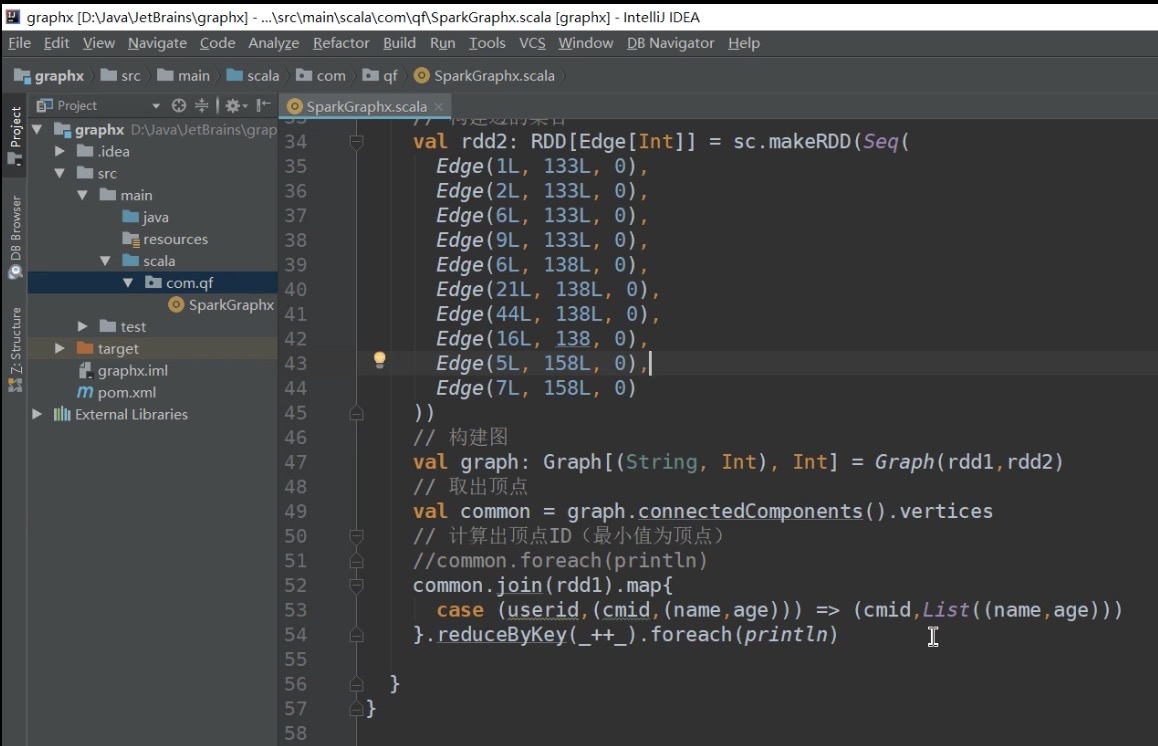
- P11千锋大数据教程:11. 好程序员_快速玩转SparkGraphx系列之构建边集合
- P12千锋大数据教程:12. 好程序员_快速玩转SparkGraphx系列之构建图
- P13千锋大数据教程:13. 好程序员_快速玩转SparkGraphx系列之转换操作(mapVertices)
- P15千锋大数据教程:15. 好程序员_快速玩转SparkGraphx系列之结构操作
- P16千锋大数据教程:16. 好程序员_快速玩转SparkGraphx系列之关联操作
- P17千锋大数据教程:17. 好程序员_快速玩转SparkGraphx系列之聚合操作(map阶段)
- P18千锋大数据教程:18. 好程序员_快速玩转SparkGraphx系列之缓存操作
- P19千锋大数据教程:19. 好程序员_快速玩转SparkGraphx系列之代码操作
- P20千锋大数据教程:20. 好程序员_快速玩转SparkGraphx系列之代码操作(2)
- P21千锋大数据教程:21. 好程序员_快速玩转SparkGraphx系列之代码操作(3)
- P22千锋大数据教程:22. 好程序员_快速玩转SparkGraphx系列之代码操作(4)
- P23千锋大数据教程:23. 好程序员_快速玩转SparkGraphx系列之代码操作(5)
- P24千锋大数据教程:24. 好程序员_快速玩转SparkGraphx系列之代码操作(6)
- P25千锋大数据教程:25. 好程序员_快速玩转SparkGraphx系列之深度优先算法(上)
- P26千锋大数据教程:26. 深度优先算法(中)
- P27千锋大数据教程:27. 深度优先算法(下)
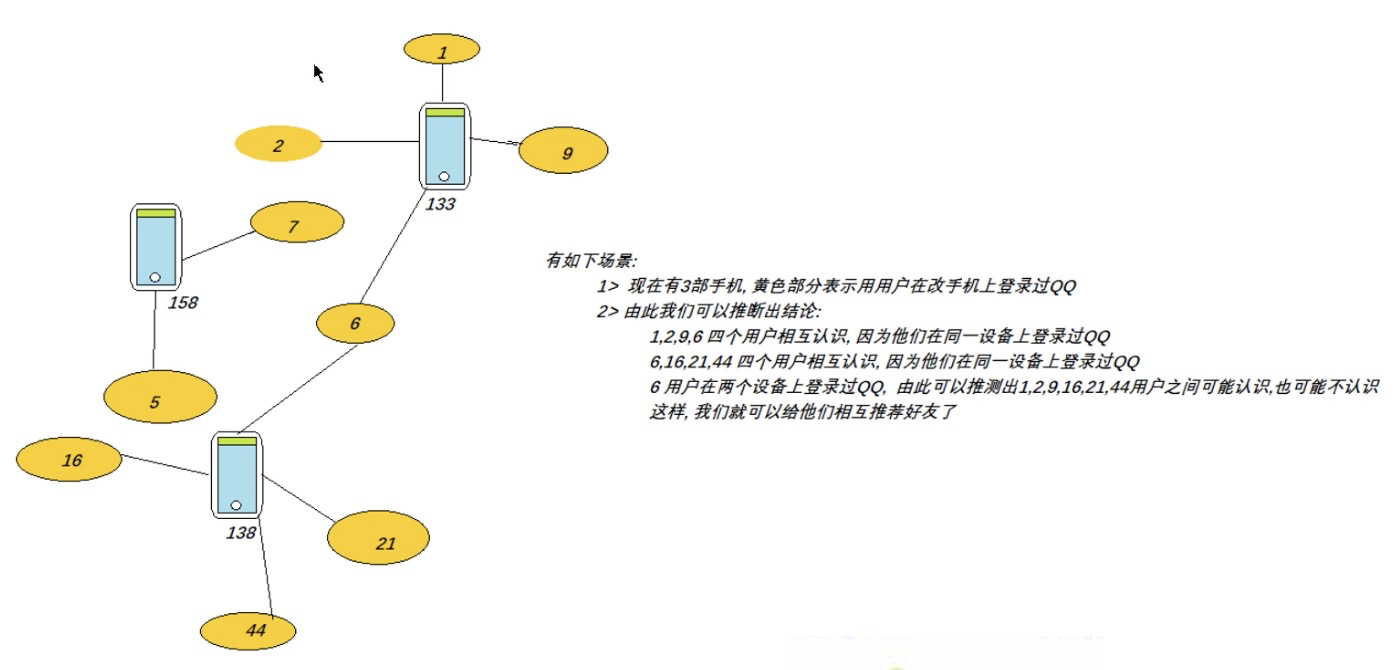
- P28千锋大数据教程:28. 联通分量
- P29千锋大数据教程:29. 广度优先算法
- P30千锋大数据教程:30. PageRank算法(动态和静态)
- P31千锋大数据教程:31. PageRank(源码解析)
- P32千锋大数据教程:32. PageRank(案例实现)
- P33千锋大数据教程:33. PageRank(测试总结)

上面是转换操作
下面是结构操作:
https://www.bookstack.cn/read/spark-graphx-source-analysis/operators-structure.md
https://github.com/endymecy/spark-graphx-source-analysis
reverse操作返回一个新的图,这个图的边的方向都是反转的。例如,这个操作可以用来计算反转的PageRank。因为反转操作没有修改顶点或者边的属性或者改变边的数量,所以我们可以
在不移动或者复制数据的情况下有效地实现它。
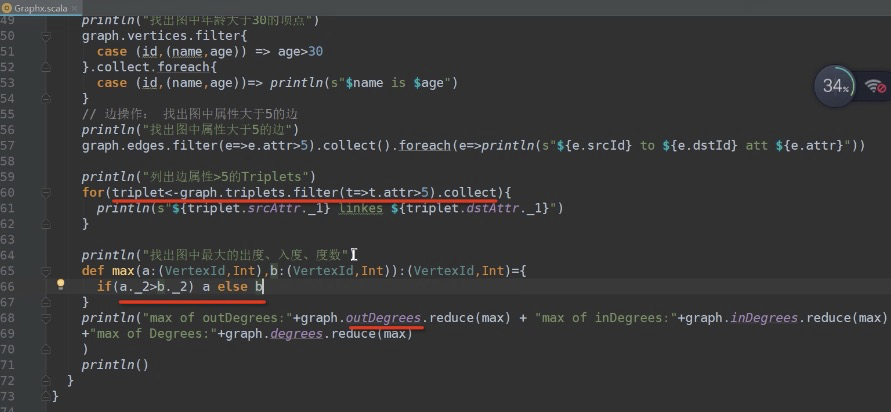
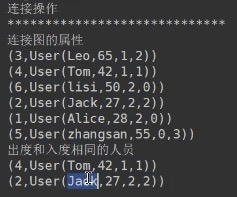
subgraph操作利用顶点和边的判断式(predicates),返回的图仅仅包含满足顶点判断式的顶点、满足边判断式的边以及满足顶点判断式的triple。subgraph操作可以用于很多场景,如获取感兴趣的顶点和边组成的图或者获取清除断开连接后的图。该代码显示,subgraph方法的实现分两步:先过滤VertexRDD,然后再过滤EdgeRDD。如上,过滤VertexRDD比较简单,我们重点看过滤EdgeRDD的过程。
mask操作构造一个子图,这个子图包含输入图中包含的顶点和边。它的实现很简单,顶点和边均做inner join操作即可。这个操作可以和subgraph操作相结合,基于另外一个相关图的特征去约束一个图。
groupEdges操作合并多重图中的并行边(如顶点对之间重复的边)。在大量的应用程序中,并行的边可以合并(它们的权重合并)为一条边从而降低图的大小。
graph.display() 可视化
https://www.cnblogs.com/tonglin0325/p/8338312.html
图计算框架乱斗
Flink: https://ci.apache.org/projects/flink/flink-docs-master/apis/batch/libs/gelly.html
GraphX: http://spark.apache.org/docs/latest/graphx-programming-guide.html
GraphLab: https://dato.com/learn/userguide/
前面的都是废话,直接看写代码。。。
https://www.bilibili.com/video/BV1s4411e7Pz?p=20



- P1千锋大数据教程:01. 好程序员_快速玩转SparkGraphx系列之Graphx的优势
- P2千锋大数据教程:02. 好程序员_快速玩转SparkGraphx系列之弹性分布式属性图(图计算的优势)
- P3千锋大数据教程:03. 好程序员_快速玩转SparkGraphx系列之Graphx图存储原理
- P4千锋大数据教程:04. 好程序员_快速玩转SparkGraphx系列之Partition分区策略
- P5千锋大数据教程:05. 好程序员_快速玩转SparkGraphx系列之Graphx中的vertices、edges、triples
- P6千锋大数据教程:06. 好程序员_快速玩转SparkGraphx系列之图构建
- P7千锋大数据教程:07. 好程序员_快速玩转SparkGraphx系列之图构建之方法
- P8千锋大数据教程:08. 好程序员_快速玩转SparkGraphx系列之图构建之过程
- P9千锋大数据教程:09. 好程序员_快速玩转SparkGraphx系列之构建点集合
- P10千锋大数据教程:10. 好程序员_快速玩转SparkGraphx系列之构建点和边的集合例子
- P11千锋大数据教程:11. 好程序员_快速玩转SparkGraphx系列之构建边集合
- P12千锋大数据教程:12. 好程序员_快速玩转SparkGraphx系列之构建图
- P13千锋大数据教程:13. 好程序员_快速玩转SparkGraphx系列之转换操作(mapVertices)
- P14千锋大数据教程:14. 好程序员_快速玩转SparkGraphx系列之转换操作(mapEdges、mapTriplets)
- P15千锋大数据教程:15. 好程序员_快速玩转SparkGraphx系列之结构操作
- P16千锋大数据教程:16. 好程序员_快速玩转SparkGraphx系列之关联操作
- P17千锋大数据教程:17. 好程序员_快速玩转SparkGraphx系列之聚合操作(map阶段)
- P18千锋大数据教程:18. 好程序员_快速玩转SparkGraphx系列之缓存操作
- P19千锋大数据教程:19. 好程序员_快速玩转SparkGraphx系列之代码操作
- P20千锋大数据教程:20. 好程序员_快速玩转SparkGraphx系列之代码操作(2)
- P21千锋大数据教程:21. 好程序员_快速玩转SparkGraphx系列之代码操作(3)
- P22千锋大数据教程:22. 好程序员_快速玩转SparkGraphx系列之代码操作(4)
- P23千锋大数据教程:23. 好程序员_快速玩转SparkGraphx系列之代码操作(5)
- P24千锋大数据教程:24. 好程序员_快速玩转SparkGraphx系列之代码操作(6)
- P26千锋大数据教程:26. 深度优先算法(中)
- P27千锋大数据教程:27. 深度优先算法(下)
- P28千锋大数据教程:28. 联通分量
- P29千锋大数据教程:29. 广度优先算法
- P30千锋大数据教程:30. PageRank算法(动态和静态)
- P31千锋大数据教程:31. PageRank(源码解析)
- P32千锋大数据教程:32. PageRank(案例实现)
- P33千锋大数据教程:33. PageRank(测试总结)

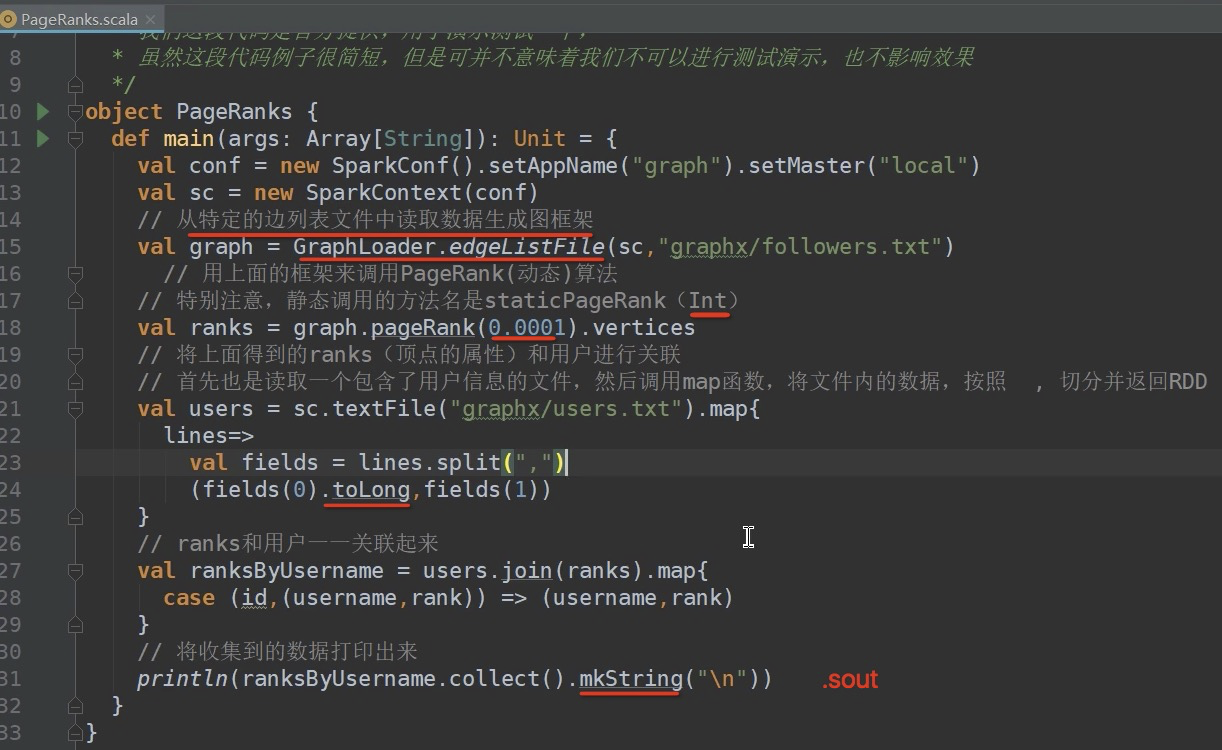

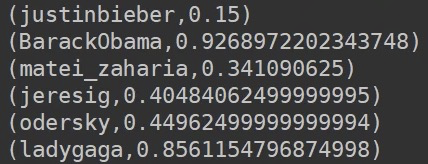
加到100 也不行
用静态的方法很难得到准确的值