深度学习_21天实战Caffe.pdf
- 原
深度学习21天实战caffe学习笔记《1:深度学习的过往》
- 原
深度学习21天实战实战caffe学习笔记《5 : Mnist手写体识别案例》
- 原
深度学习21天实战caffe学习笔记《6 : Caffe代码梳理》
- 原
深度学习21天实战caffe学习笔记《7 :Caffe数据结构》
- 原
深度学习21天实战caffe学习笔记《8:Caffe I/O模块》
- 原
深度学习21天实战caffe学习笔记《9:Caffe 模型》
- 原
深度学习21天实战实战caffe学习笔记<10:Caffe前向传播>
- 原
深度学习21天实战实战caffe学习笔记<11:Caffe 反向传播>
- 原
深度学习21天实战caffe学习笔记《12:Caffe 最优化求解过程》
- 原
深度学习21天实战caffe学习笔记《2 :深度学习工具》
- 原
深度学习21天实战caffe学习笔记《0 : caffe包解析》
- 原
深度学习21天实战caffe学习笔记《3 :准备Caffe环境》
- 原
深度学习21天实战caffe学习笔记《4 : Caffe依赖包解析》
- 原
Caffe安装过程中相关问题
- 原
caffe中的学习率的衰减机制
- 原
深度学习21天实战caffe学习笔记《13:Caffe 实用工具》
- 原
深度学习21天实战实战caffe学习笔记《14:Caffe可视化方法》
- 原
深度学习21天实战caffe学习笔记《15:Caffe计算加速》
- 原
深度学习21天实战caffe学习笔记《16:Caffe迁移和部署》
- 原
深度学习21天实战caffe学习笔记《17:学习资源》
按书上的进程今天应该就是新生了~全然木有学完tensorflow的激动,不过呢~~应该找个项目虐虐自己了~ 以下是资源哦~从书上扒下来的 ~~#~#**
-
学习:Ubuntu14.04编译caffe问题记录
- 原
Caffe之prototxt
- 原
深度学习21天实战实战caffe学习<查看机器已经安装的环境>
- 转
【Caffe安装】caffe安装系列——史上最详细的安装步骤
第五章









第六章

为什么使用 LMDB、LEVELDB —— 1)统一格式,简化数据读取层的实现;2)提高磁盘IO利用率;

熟悉模型描述文件中的参数;


caffe.bin 参数:
|
usage:caffe<command><args> # 这个是告诉你使用格式, caffe 后接上 一个command命令,后面再接其他参数 commands: #你能选择的命令有一下这么几种 train #训练或者微调一个模型 test #对一个模型打分 device—query #显示GPU诊断信息 time #评估模型执行时间 Flags form tools/caffe.cpp #其他一些参数的总览 -gpu (可选;给定时运行GPU模式,用’ , ’分隔开不同的gpu, ‘-gpu all’表示运行在所有可用的gpu设备上,此时有效训练批量大小就是gpu设备数乘以batch_size) -iterations (循环迭代次数,默认为50) -level (可选;定义网络水平,也是NetState中的一个,但我也还不清楚这个的作用) -model (指定模型定义文本文件名,xxx.prototxt) -phase (可选;网络是处于TEST还是TRAIN阶段,当你使用command中time命令时,再指定phase就可以选择计算TEST或者TRAIN的耗时) -sighup_effect (可选;当收到SIGHUP信号时要采取的动作,可选项:snapshot、stop、none,默认为snapshot,即打印快照) -sigint_effect (可选;当收到当收到SIGINT信号时要采取的动作,可选项同上,默认stop) -snapshot (可选,恢复训练时指定上次中止的快照,就是比如训练到一般按Ctrl+C终止训练(Linux中这个Ctrl+C不是copy,而是终止当前操作),就会得到一个solverstate 文件,下次恢复训练时就可以指定这个) -solver ( 指定sovler.prototxt文件,在train的时候需要这个参数) -stage (可选;也是NetState中的一个,但我也还不清楚这个的作用) -weights ( 指定用于微调的预训练权值,也即 训练后得到的**.caffemodel文件,不可与snapshot同时出现) |
第七章


需要有 LK 个卷积核实现通道数目的转换;


data 指针(只读)
diff 指针(读写)——求导迭代用?
第八章
Caffe 数据结构
|
caffe中数据结构主要包括caffe::Net,caffe::Layer,caffe::Solver三个主要大类。下面就这三个主要的数据结构做一下总结。 1,caffe:Net:这个数据结构用来表示整个网络,这个数据结构里包含了很多重要的变量。 vector< shared_ptr< Layer< Dtype > > > layers_变量存储的是每层layer结构体的指针。 vector< shared_ptr< Blob< Dtype > > > blobs_变量存储每层网络的训练参数,通常有blobs_[0]存储该层网络的weight,blobs_[1]存储该层网络的bias。不管是weight还是bias都是具有blob结构,关于blob结构的数据存储具体是什么样的,以后会有总结。 (1)caffe::BaseConvolutionLayer:这个存储的是convlution层的所需要的参数 int bottom_dim_变量存储的是输入数据的宽度。 int height_,int width_表示pooling层输入的图像的尺寸。 int M_表示一个batch中的样本数目,即input矩阵的行数目。 vector< Blob< Dtype > * > softmax_bottom_vec_表示该层的输入,数据宽度为10。 int outer_num_对应一个batch中的样本数量。 |
|
在某社区看到的回答,觉得不错就转过来了:http://caffecn.cn/?/question/123 Caffe从四个层次来理解:Blob,Layer,Net,Solver。 1、Blob Caffe的基本数据结构,用四维矩阵Batch*Channel*Height*Width表示,存储了包括神经元的 激活值、参数、以及相应的梯度(dW,db)。其中包含有cpu_data、gpu_data、cpu_diff、gpu_diff、 mutable_cpu_data、mutable_gpu_data、mutable_cpu_diff、mutable_gpu_diff这一堆很像的东西, 分别表示存储在CPU和GPU上的数据(印象中二者的值好像是会自动同步成一致的)。其中带data的里面存 储的是激活值和W、b,diff中存储的是残差和dW、db。另外带mutable和不带mutable的一对指针所指 的位置是相同的,只是不带mutable的只读,而带mutable的可写。 2、Layer 代表神经网络的层,由各种各样的层来构成整个网络。一般一个图像或样本会从数据层中读进来, 然后一层一层的往后传。除了数据层比较特殊之外,其余大部分层都包含4个函数:LayerSetUp、Reshape、 Forward、Backward。其中LayerSetup用于初始化层,开辟空间,填充初始值什么的。Reshape是对输入 值进行维度变换,比如pooling接全连接层的时候要先拉成一个向量再计算。Forward是前向传播,Backward是 后向传播。 那么数据是如何在层之间传递的呢?每一层都会有一个(或多个)Bottom和top,分别存储输入和输出, 比如bottom[0]->cpu_data()存输入的神经元激活值,换成top存输出的,换成cpu_diff()存的是激活值的残差, 换成gpu是存在GPU上的数据,再带上mutable就可写了,这些是神经元激活值相关的,如果这个层前后有多个输入输出层, 就会有bottom[1],比如accuracy_layer就有两个输入,fc8和label。而每层的参数会存在this->blobs_里,一般this->blobs_[0] 存W,this->blobs_[1]存b,this->blobs_[0]->cpu_data()存的是W的值,this->blobs_[0]->cpu_diff()存的梯度dW,b和db也 类似,然后换成gpu是存在GPU上的数据,再带上mutable就可写了。 3、Net Net就是把各种层按train_val.prototxt的定义堆叠在一起,首先进行每个层的初始化,然后不断进行Update,每更新一次就 进行一次整体的前向传播和反向传播,然后把每层计算得到的梯度计算进去,完成一次更新,这里注意每层在Backward中只是计 算dW和db,而W和b的更新是在Net的Update里最后一起更新的。而且在caffe里训练模型的时候一般会有两个Net,一个train一 个test。刚开始训练网络时前面的一大堆输出,网络的结构什么的也都是这里输出的。 4、Solver Solver是按solver.prototxt的参数定义对Net进行训练,首先会初始化一个TrainNet和一个TestNet,然后其中的Step函数会 对网络不断进行迭代,主要就是两个步骤反复迭代:①不断利用ComputeUpdateValue计算迭代相关参数,比如计算learning rate, 把weight decay②调用Net的Update函数对整个网络进行更新。迭代中的一大堆输出也是在这里输出的,比如当前的loss 和learning rate。 |
随笔分类 - Caffe摘要:装过很多次caffe了,但这个还是遇到了很多奇葩问题,不过以前都是在ubuntu上,这次是在centos上。 1、import error _caffe.so: undefined symbol: _ZN5boost6python6detail11init_moduleER11PyModuleDef 阅读全文 posted @ 2019-03-28 10:01 牧马人夏峥 阅读 (265) | 评论 (0) 编辑 摘要:http://blog.csdn.net/u010402786/article/details/70141261 https://zhuanlan.zhihu.com/p/22624331 阅读全文 posted @ 2017-11-14 11:26 牧马人夏峥 阅读 (42) | 评论 (0) 编辑 摘要:参考:http://blog.csdn.net/bailufeiyan/article/details/50876728#reply 阅读全文 posted @ 2017-10-11 11:04 牧马人夏峥 阅读 (50) | 评论 (0) 编辑 fatal error: google/protobuf/arena.h:没有那个文件或目录 摘要:安装caffe时make all会出现这个错误,按照https://github.com/BVLC/caffe/issues/4988说法,可能时libprotobuf-dev过时了,需要从源码重新变异protobuf。 首先安装:sudo apt-get install autoconf auto 阅读全文 posted @ 2017-09-30 13:43 牧马人夏峥 阅读 (881) | 评论 (0) 编辑 摘要:python图像标记工具labelTool: http://blog.csdn.net/wuzuyu365/article/details/52523061 可视化工具,支持prototxt可视化:http://ethereon.github.io/netscope/#/editor 阅读全文 posted @ 2016-12-08 09:22 牧马人夏峥 阅读 (163) | 评论 (0) 编辑 摘要:对于blob.h文件。 先看成员变量。定义了6个保护的成员变量,包括前、后向传播的数据,新、旧形状数据(?), 数据个数及容量。 再看成员函数。包括构造函数(4个参数),reshape(改变blob形状),以及很多inline函数。 #ifndef CAFFE_BLOB_HPP_ #define C 阅读全文 posted @ 2016-12-05 08:56 牧马人夏峥 阅读 (1373) | 评论 (0) 编辑 摘要:因为没有GPU,所以在CPU下训练自己的数据,中间遇到了各种各样的坑,还好没有放弃,特以此文记录此过程。 1、在CPU下配置faster r-cnn,参考博客:http://blog.csdn.net/wjx2012yt/article/details/52197698#quote 2、在CPU下训 阅读全文 posted @ 2016-12-03 09:51 牧马人夏峥 阅读 (7340) | 评论 (0) 编辑 摘要:知乎上的讨论:https://www.zhihu.com/question/27982282 从0开始山寨caffe系列:http://www.cnblogs.com/neopenx/archive/2016/02.html caffe源码阅读系列:http://blog.csdn.net/xize 阅读全文 posted @ 2016-11-24 21:43 牧马人夏峥 阅读 (204) | 评论 (0) 编辑 摘要:如何在Caffe中增加一层新的Layer呢?主要分为四步: (1)在./src/caffe/proto/caffe.proto 中增加对应layer的paramter message; (2)在./include/caffe/***layers.hpp中增加该layer的类的声明,***表示有com 阅读全文 posted @ 2016-11-19 21:43 牧马人夏峥 阅读 (7067) | 评论 (0) 编辑 摘要:知乎上这位博主画的caffe的整体结构:https://zhuanlan.zhihu.com/p/21796890?refer=hsmyy Caffe 做train时的流程图,来自http://caffecn.cn/?/question/242 阅读全文 posted @ 2016-11-19 10:06 牧马人夏峥 阅读 (371) | 评论 (0) 编辑 摘要:在某社区看到的回答,觉得不错就转过来了:http://caffecn.cn/?/question/123 Caffe从四个层次来理解:Blob,Layer,Net,Solver。 1、Blob Caffe的基本数据结构,用四维矩阵Batch*Channel*Height*Width表示,存储了包括神 阅读全文 posted @ 2016-11-19 09:49 牧马人夏峥 阅读 (5013) | 评论 (0) 编辑 Caffe学习系列(12):不同格式下计算图片的均值和caffe.proto 摘要:均值是所有训练样本的均值,减去之后再进行训练会提高其速度和精度。 1、caffe下的均值 数据格式是二进制的binaryproto,作者提供了计算均值的文件compute_image_mean, 计算均值时调用: 生成的均值文件保存在mean_binaryproto。 2、python格式下的均值( 阅读全文 posted @ 2016-11-09 22:07 牧马人夏峥 阅读 (1506) | 评论 (0) 编辑 Caffe学习系列(11):数据可视化环境(python接口)配置 摘要:参考:http://www.cnblogs.com/denny402/p/5088399.html 这节配置python接口遇到了不少坑。 1、我是利用anaconda来配置python环境,在将caffe根目录下的python文件夹加入到环境变量这一步时遇到 问题,我用那个命令打开后不知道怎么加入 阅读全文 posted @ 2016-08-31 22:18 牧马人夏峥 阅读 (254) | 评论 (0) 编辑 摘要:训练网络命令: 用预先训练好的权重来fine-tuning模型,需要一个caffemodel,不能和-snapshot同时使用 参考:http://www.cnblogs.com/denny402/p/5076285.html 阅读全文 posted @ 2016-08-30 21:38 牧马人夏峥 阅读 (73) | 评论 (0) 编辑 摘要:介绍了各种优化算法 参考:http://www.cnblogs.com/denny402/p/5074212.html 阅读全文 posted @ 2016-08-30 21:36 牧马人夏峥 阅读 (217) | 评论 (0) 编辑 Caffe学习系列(8):solver,train_val.prototxt,deploy.prototxt及其配置 摘要:solver是caffe的核心。 http://www.cnblogs.com/denny402/p/5074049.html train_val.prototxt,deploy.prototxt的比较:http://blog.csdn.net/fx409494616/article/details 阅读全文 posted @ 2016-08-30 21:33 牧马人夏峥 阅读 (93) | 评论 (0) 编辑 摘要:参考:http://www.cnblogs.com/denny402/p/5073427.html 阅读全文 posted @ 2016-08-24 23:16 牧马人夏峥 阅读 (100) | 评论 (0) 编辑 摘要:主要包括softmax-loss层(与softmax有区别),全连接层(Inner Prouduct),accuracy层,reshape层, Dropout层。 softmax: accuracy reshape Dropout层 参考:http://www.cnblogs.com/denny40 阅读全文 posted @ 2016-08-24 23:07 牧马人夏峥 阅读 (74) | 评论 (0) 编辑 摘要:参考:http://www.cnblogs.com/denny402/p/5072507.html 主要介绍了各个激活函数。 阅读全文 posted @ 2016-08-24 23:02 牧马人夏峥 阅读 (83) | 评论 (0) 编辑 摘要:视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层。 这里介绍下conv层。 输入:n*c0*w0*h0 输出:n*c1*w1*h1 其中,c1就是参数中的num_output,生成的特征图个数 w1=(w0 阅读全文 posted @ 2016-08-24 22:58 牧马人夏峥 阅读 (126) | 评论 (0) 编辑 摘要:一个模型由多个层构成,如Data,conv,pool等。其中数据层是模型的最底层,是模型的入口。 提供数据的输入,也提供数据从Blobs转换成别的格式进行保存输出还包括数据的预处理(如减去 均值, 放大缩小, 裁剪和镜像等)。数据源来自高效的数据库(如LevelDB和LMDB),或者hdf5 文件和 阅读全文 posted @ 2016-08-24 22:40 牧马人夏峥 阅读 (85) | 评论 (0) 编辑 摘要:参考:http://www.cnblogs.com/denny402/p/5083300.html 上述主要介绍的是从自己的原始图片转为lmdb数据,再到训练、测试的整个流程(另外可参考薛开宇的笔记)。 用的是自带的caffenet(看了下结构,典型的CNN),因为没有GPU,整个过程实在是太慢了, 阅读全文 posted @ 2016-08-24 22:22 牧马人夏峥 阅读 (335) | 评论 (0) 编辑 caffe学习系列(1):图像数据转换成db(leveldb/lmdb)文件 摘要:参考:http://www.cnblogs.com/denny402/p/5082341.html 上述博文用caffe自带的两张图片为例,将图片转为db格式。博主对命令参数进行了详细的解释,很赞。 遇到的问题是,因为对linux命令不熟,不知为啥创建.sh文件不成功,于是将其他文件下的.sh文件拷 阅读全文 posted @ 2016-08-24 20:39 牧马人夏峥 阅读 (448) | 评论 (0) 编辑 |
Blob

Blob:Caffe的基本存储单元
blob:
四维数组,维度从低到高(width_,height_,channels_,num_);
用于存储和交换数据;存储数据或者权值(data)和权值增量(diff);
提供统一的存储器接口,持有一批图像或其他数据、权值、权值更新值;
进行网络计算时,每层的输入、输出都需要通过Blob对象缓冲。
|
Blob其实从代码的角度看,它是一个模板类。Blob封装了运行时的数据信息(存储、交换和处理网络中正反向传播时的数据和导数信息),并且在CPU和GPU之间具有同步处理的能力。 对于图像处理来说,Blob是一个四维数组,(N, C, H ,W), 其中N表示图片的数量,C表示图片的通道数,H表示图片的高度, W表示图片的宽度。除了图片数据,Blob也可以用于非图片数据。比如传统的多层感知机,就是比较简单的全连接网络,用2D的Blob,调用innerProduct层来计算就可以了。 在模型中设定的参数,也是用Blob来表示和运算。它的维度会根据参数的类型不同而不同。比如:在一个卷积层中,输入一张3通道图片,有96个卷积核,每个核大小为11*11,因此这个Blob是96*3*11*11. 而在一个全连接层中,假设输入1024通道图片,输出1000个数据,则Blob为1000*1024。 |
Caffe.proto中Blob的描述
// Specifies the shape (dimensions) of a Blob.该结构描述Blob的形状信息
message BlobShape {
repeated int64 dim = 1 [packed = true]; // 只包含若干int64类型的值,分别表示Blob每个维度的大小。packed表示这些值紧密排布
}
message BlobProto { //该结构表示Blob载磁盘中序列化后的形态
optional BlobShape shape = 7; //可选,包括一个个BlobShape对象
repeated float data = 5 [packed = true]; //包括若干的(repeated)浮点类型的元素,存储数据,权值;元素数目由shape或者(num,channels,height,width)确定
repeated float diff = 6 [packed = true]; //包括若干的浮点类型的元素,来存储增量信息(diff),维度与上面的data一致
repeated double double_data = 8 [packed = true]; //与data并列,只是类型是double
repeated double double_diff = 9 [packed = true]; //与diff并列,只是类型是double
// 4D dimensions -- deprecated. Use "shape" instead. 可选的维度信息,新版本Caffe推荐使用shape来代替
optional int32 num = 1 [default = 0];
optional int32 channels = 2 [default = 0];
optional int32 height = 3 [default = 0];
optional int32 width = 4 [default = 0];
}
// The BlobProtoVector is simply a way to pass multiple blobproto instances around.存放多个BlobProto实例的对应Index,易于引用
message BlobProtoVector {
repeated BlobProto blobs = 1;
| 说明 | proto |
| 该结构描述了Blob的形状信息 | message BlobShape { |
| 只包括若干int64类型值,分别表示Blob | |
| 每个维度的大小,packed表示这些值在内存 | |
| 中紧密排布,没有空洞 | repeated int64 dim = 1 [packed = true]; |
| } | |
| 说明 | proto |
| 该结构描述Blob在磁盘中序列化后的形态 | message BlobProto { |
| 可选,包括一个BlobShape对象 | optional BlobShape shape = 7; |
| 包括若干护垫元素, | |
| 用于存储增量信息,元素数目由shape或 | |
| (num,channels,height,width)确定 | |
| ,这些元素在内存总紧密排布 | repeated float data = 5 [packed = true]; |
| 包括若干护垫元素, | |
| 用于存储增量信息,维度与data粗细一致 | repeated float diff = 6 [packed = true]; |
| 与data并列,知识类型为double | repeated double double_data = 8 [packed = true]; |
| 与diff并列,只是内心为double | repeated double double_diff = 9 [packed = true]; |
| 可选的维度信息,新版本caffe | |
| 推荐使用shape,而不再后面的值 | // 4D dimensions -- deprecated. Use "shape" instead. |
| optional int32 num = 1 [default = 0]; | |
| optional int32 channels = 2 [default = 0]; | |
| optional int32 height = 3 [default = 0]; | |
| optional int32 width = 4 [default = 0]; | |
| } |

Blob 的强大之处在于可以自动同步 CPU/GPU 上的数据
a.Update();//执行 Update 操作,将 diff 与 data 融合,这也是CNN 权值更新步骤的最终实施者
在Update 函数中,实现了 data=data-diff 操作。这个在CNN权值更新时会用到。

BlogProto 对象实现了磁盘、内存之间的数据通信,这对于保存、载入训练好的模型权值非常实用。

Blobproto对象实现了磁盘、内存之间的数据通信,这对于保存、载入训练好的模型非常实用。
不用BlobShape和BlobProto二实用ProtoBuffer的原因:
1>、结构体的序列化/反序列化操作需要额外的编程思想,难以做到接口标准化;
2>、结构体中包含变长数据时,需要更加细致的工作保证数据完整性。ProtoBuffer将变成最容易出现问题的地方加以隐藏,让机器自动处理,提高了出的健壮性。



https://blog.csdn.net/calvinpaean/article/details/84066848
Caffe 内存管理分析
|
在Caffe的分层结构中,Blob充当了内存管理的角色,屏蔽了上层逻辑代码对于数据的申请释放的感知,同时也屏蔽了底层设备对上层逻辑的影响,本文主要分析Blob的管理机制和实际内存申请单元 SyncedMemory 的机制。 实际上整个Blob的实现就是在SyncedMemory上封装了一层,所以首先需要分析一下SyncedMemory的实现机制。
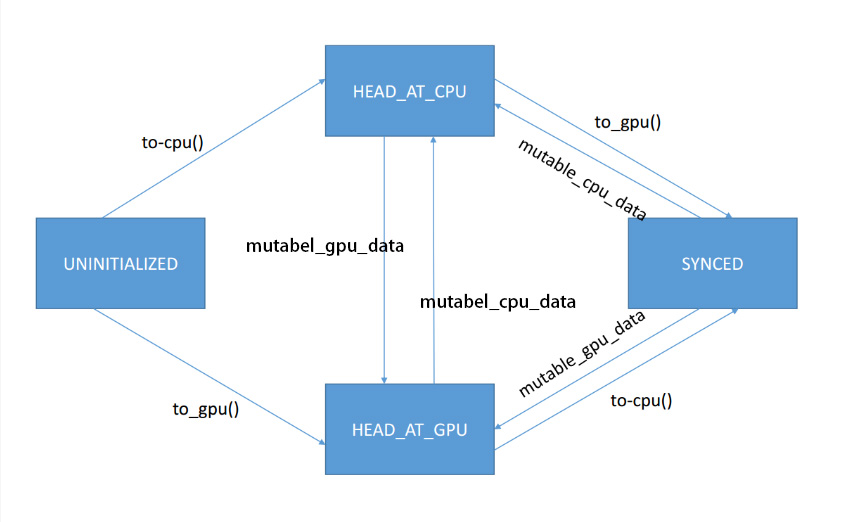
head_ 维护的是 SyncedMemory 当前的状态,分为 UNINITIALIZED,HEAD_AT_GPU,HEAD_AT_CPU ,SYNCED 四中状态。现在介绍一下具体的流程,当第一次调用 to_cpu()时, head_处于UNINITIALIZED状态,那么系统会调用 CPU的申请内存的方式去获得内存区域,之后设置 head_ = HEAD_AT_CPU ,如果中间过程没有GPU设备则不会有状态变动,如果中间有代码调用了 to_gpu() ,则会发现 head_处于 HEAD_AT_CPU 状态,此时会调用同步函数,将数据从CPU同步到GPU, 之后如果又回到CPU上,则同样会发现 head_ 处于HEAD_AT_GPU的状态,那么又会调用相应的同步代码,将数据同步回CPU,通过 head_这样一个状态参数屏蔽了GPU和CPU间的申请和切换的不同。 所以上层业务只需要知道当前自己需要的是CPU还是GPU的数据,然后调用不同的接口,就可以完成数据获取的操作。 |
|
cout_中所存储的就是所有维度的的乘积,也就是当前要reshape到的数据大小 |
GPU 显存 - Caffe 内存优化
https://blog.csdn.net/zziahgf/article/details/80028878
|
该版本 Caffe 中, 内存优化是由网络配置中的 optimize_train - 是否在训练网络中进行优化. 如果设为 True, 可以节省训练时一半的内存. optimize_test - 是否在测试网络中进行优化. 如果设为 True, 可以节省测试时大部分内存. |
|
工作原理 节省内存的原因是, 对于训练的每次 forward 和 backward, 前一 blobs 使用的内存会被后面 blobs 重用. 内存优化模块通过确定网络中 blobs 的依赖关系来工作的. 有时称之为 multiloading. 具体来说, 在网络训练开始前, 运行一次 “dry-run” 来确定重用 blob 内存块的方式. 这是一个静态优化过程. 另一方面, Parrots 深度学习框架是通过动态调度内存使用的, 具有更优的内存节省和更好的灵活性. |
具体如何实现的细节可以看看下面的:
https://blog.csdn.net/lanxueCC/article/details/53009130
Caffe 源码之 CPU 与GPU 数据同步
|
在cuda中调用cudaMallocHost得到的pinned的内存 |
|
接着最重要的就是内存分配和Caffe的底层数据的切换(cpu模式和gpu模式),需要用到内存同步模块。这类个类的代码比较少,但是作用是非常明显的。文件对应着syncedmem.hpp,着syncedmem.cpp首先是两个全局的内联函数。如果机器是支持GPU的并且安装了cuda,通过cudaMallocHost分配的host memory将会被pinned,pinned的意思就是内存不会被paged out,我们知道内存里面是由页作为基本的管理单元。分配的内存可以常驻在内存空间中对效率是有帮助的,空间不会被别的进程所抢占。同样如果内存越大,能被分配的Pinned内存自然也越大。还有一点是,对于单一的GPU而言提升并不会太显著,但是对于多个GPU的并行而言可以显著提高稳定性。这里是两个封装过的函数,内部通过cuda来分配主机和释放内存的接口. |
|
/*如果是第一次初始化,就CaffeMallocHost分配CPU内存, /*如果是GPU模式下才处理,如果是单cpu模式下则报错 |
Caffe 源码解析:
https://www.cnblogs.com/yymn/category/762593.html
|
随笔分类 - caffe源码解析(转载) 摘要:Deep Residual Network学习(二) 本文承接上篇对ResNet的分析与复现:Deep Residual Network学习(一) 通过上次在Cifar10上复现ResNet的结果,我们得到了上表,最后一栏是论文中的结果,可以看到已经最好的初始化方法(MSRA)已经和论文中的结果非常 阅读全文 posted @ 2018-04-03 19:02 菜鸡一枚 阅读 (90) | 评论 (0) 编辑 摘要:caffe中batch_norm层代码详细注解 caffe中batch_norm层代码注解 一:BN的解释: 在训练深层神经网络的过程中, 由于输入层的参数在不停的变化, 因此, 导致了当前层的分布在不停的变化, 这就导致了在训练的过程中, 要求 learning rate 要设置的非常小, 另外, 阅读全文 posted @ 2018-03-19 11:23 菜鸡一枚 阅读 (196) | 评论 (0) 编辑 摘要:CAFFE源码学习笔记之batch_norm_layer 一、前言 网络训练的过程中参数不断的变化导致后续的每一层输入的分布也发生变化,而学习的过程使得每一层都需要适应输入的分布。所以就需要谨慎的选择初始化,使用小的学习率,这极大的降低了网络收敛的速度。 为了使每层的输入分布大致都在0均值和单位方差 阅读全文 posted @ 2018-03-19 11:22 菜鸡一枚 阅读 (48) | 评论 (0) 编辑 Batch Normalization Caffe版实现解析 摘要:Batch Normalization Caffe版实现解析 建议先看论文Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift,这样会对本文有更好的理解; 同时使用Ba 阅读全文 posted @ 2018-03-19 11:21 菜鸡一枚 阅读 (67) | 评论 (0) 编辑 摘要:Caffe Batch Normalization推导 首先仔细看过Caffe的BN层实现的话会发现caffe的BN层与论文的是不太一致的。 没有了 γ 和 β 。(因为如果有需要的话可以再加一个scale layer。)我这里将推导出给caffe的backward注释一样的diff公式。那么我们先 阅读全文 posted @ 2018-03-19 11:20 菜鸡一枚 阅读 (48) | 评论 (0) 编辑 摘要:Caffe Batch Normalization推导 Caffe BatchNormalization 推导 总所周知,BatchNormalization通过对数据分布进行归一化处理,从而使得网络的训练能够快速并简单,在一定程度上还能防止网络的过拟合,通过仔细看过Caffe的源码实现后发现,Ca 阅读全文 posted @ 2018-03-19 11:19 菜鸡一枚 阅读 (172) | 评论 (0) 编辑 摘要:caffe的slice和concat实现MultiTask 本篇博客部分转自:http://blog.csdn.net/u013010889/article/details/53098346 http://blog.csdn.net/shuzfan/article/details/54565776 阅读全文 posted @ 2017-10-27 09:50 菜鸡一枚 阅读 (424) | 评论 (0) 编辑 摘要:caffe代码详细注解 Caffe net:init()函数代码详细注解 Caffe 中net的初始化函数init()是整个网络创建的关键函数。在此对此函数做详细的梳理。 一、代码的总体介绍 该init()函数中主要包括以下几个函数: 1. FilterNet(in_param,&filtered_ 阅读全文 posted @ 2017-09-09 16:10 菜鸡一枚 阅读 (225) | 评论 (0) 编辑 CAFFE源码学习笔记之四-device_alternate 摘要:CAFFE源码学习笔记之四-device_alternate 一、前言 common中包含的头文件中有一个device_alternate,里面主要是和cuda有关系的宏: CUDA_CHECK; CUBLAS_CHECK; CURAND_CHECK; CUDA_KERNEL_LOOP; 同时还对b 阅读全文 posted @ 2017-08-21 16:48 菜鸡一枚 阅读 (332) | 评论 (0) 编辑 该文被密码保护。 posted @ 2017-07-30 10:04 菜鸡一枚 阅读 (1) | 评论 (0) 编辑 解析./build/tools/caffe train --solver=examples/mnist/lenet_solver.prototxt 摘要:解析./build/tools/caffe train --solver=examples/mnist/lenet_solver.prototxt 解析./build/tools/caffe train --solver=examples/mnist/lenet_solver.prototxt 第一 阅读全文 posted @ 2017-07-16 09:41 菜鸡一枚 阅读 (135) | 评论 (0) 编辑 摘要:Caffe中Solver解析 1.Solver的初始化 caffe.cpp中的train函数中通过上述的代码定义了一个指向Solver<float>的shared_ptr。其中主要是通过调用SolverRegistry这个类的静态成员函数CreateSolver得到一个指向Solver的指针来构造s 阅读全文 posted @ 2017-07-11 16:10 菜鸡一枚 阅读 (365) | 评论 (0) 编辑 摘要:梳理caffe代码solver(十四) 之前有一篇介绍solver的求解,也可以看官网的介绍:here ,和翻译版的介绍。 solver.hpp头文件的简单解析: [cpp] view plain copy #ifndef CAFFE_SOLVER_HPP_ #define CAFFE_SOLVER 阅读全文 posted @ 2017-07-11 16:00 菜鸡一枚 阅读 (178) | 评论 (0) 编辑 摘要:Caffe中Layer和Net细解 Layer Layer是Caffe的基本计算单元,至少有一个输入Blob(Bottom Blob)和一个输出Blob(Top Blob),部分Layer带有权值(Weight)和偏置(Bias),有两个运算方向:前向传播(Forward)和反向传播(Backwar 阅读全文 posted @ 2017-07-10 22:14 菜鸡一枚 阅读 (203) | 评论 (0) 编辑 摘要:caffe命令及其参数解析 caffe的c++主程序(caffe.cpp)放在根目录下的tools文件夹内, 当然还有一些其它的功能文件,如:convert_imageset.cpp, train_net.cpp, test_net.cpp等也放在这个文件夹内。经过编译后,这些文件都被编译成了可执行 阅读全文 posted @ 2017-07-08 22:06 菜鸡一枚 阅读 (48) | 评论 (0) 编辑 摘要:CAFFE源码学习笔记之初始化Filler 一、前言 为什么CNN中的初始化那么重要呢? 我想总结的话就是因为他更深一点,相比浅层学习,比如logistics或者SVM,最终问题都转换成了凸优化,函数优化的目标唯一,所以参数初始化随便设置为0都不影响,因为跟着梯度走,总归是会走向最小值的附近的。 但 阅读全文 posted @ 2017-06-25 16:03 菜鸡一枚 阅读 (147) | 评论 (0) 编辑 caffe代码阅读6:Filler的实现细节-2016.3.18 摘要:caffe代码阅读6:Filler的实现细节-2016.3.18 一、Filler的作用简介 Filler层的作用实际上就是根据proto中给出的参数对权重进行初始化,初始化的方式有很多种,分别为常量初始化(constant)、高斯分布初始化(gaussian)、positive_unitball初 阅读全文 posted @ 2017-06-25 11:08 菜鸡一枚 阅读 (124) | 评论 (0) 编辑 摘要:caffe中的filler.hpp源码的作用: filler.hpp文件:(它应该没有对应的.cpp文件,一切实现都是在头文件中定义的,可能是因为filler只分在网络初始化时用到那么一次吧) 1,首先定义了基类:Filler,它包括:一个纯虚函数:filler(用于在子类里根据不同的情况具体实现) 阅读全文 posted @ 2017-06-24 22:30 菜鸡一枚 阅读 (51) | 评论 (0) 编辑 摘要:caffe中权值初始化方法 首先说明:在caffe/include/caffe中的 filer.hpp文件中有它的源文件,如果想看,可以看看哦,反正我是不想看,代码细节吧,现在不想知道太多,有个宏观的idea就可以啦,如果想看代码的具体的话,可以看:http://blog.csdn.net/xize 阅读全文 posted @ 2017-06-23 11:24 菜鸡一枚 阅读 (99) | 评论 (0) 编辑 摘要:.prototxt 文件添加注释 利用#字符,在句首。 例如: # this is my annotation. 阅读全文 posted @ 2017-06-21 10:42 菜鸡一枚 阅读 (280) | 评论 (0) 编辑 摘要:(Caffe)编程小技巧 版权声明:未经允许请勿用于商业用途,转载请注明出处:http://blog.csdn.net/mounty_fsc/ 版权声明:未经允许请勿用于商业用途,转载请注明出处:http://blog.csdn.net/mounty_fsc/ 1. Cuda中要处理单位数据N大于可 阅读全文 posted @ 2017-06-13 11:00 菜鸡一枚 阅读 (67) | 评论 (0) 编辑 【caffe源码研究】第四章:完整案例源码篇(5) :LeNet反向过程 摘要:【caffe源码研究】第四章:完整案例源码篇(5) :LeNet反向过程 本部分剖析Caffe中Net::Backward()函数,即反向传播计算过程。从LeNet网络角度出发,且调试网络为训练网络,共9层网络。 入口信息 Net::Backward()函数中调用BackwardFromTo函数,从 阅读全文 posted @ 2017-06-05 15:39 菜鸡一枚 阅读 (175) | 评论 (0) 编辑 【caffe源码研究】第四章:完整案例源码篇(4) :LeNet前向过程 摘要:【caffe源码研究】第四章:完整案例源码篇(4) :LeNet前向过程 入口信息 通过如下的调用堆栈信息可以定位到函数ForwardFromTo(其他函数中无重要信息) caffe::Net<float>::ForwardFromTo() at net.cpp:574 caffe::Net<flo 阅读全文 posted @ 2017-06-05 15:34 菜鸡一枚 阅读 (136) | 评论 (0) 编辑 【caffe源码研究】第四章:完整案例源码篇(3) :LeNet初始化测试网络 摘要:【caffe源码研究】第四章:完整案例源码篇(3) :LeNet初始化测试网络 一、 测试网络结构 注:Top Blob Shape格式为:BatchSize,ChannelSize,Height,Width(Total Count) 二、 与训练网络对比 训练网络9层,测试网络12层 训练网络没有 阅读全文 posted @ 2017-06-05 15:12 菜鸡一枚 阅读 (64) | 评论 (0) 编辑 【caffe源码研究】第四章:完整案例源码篇(2) :LeNet初始化训练网络 摘要:【caffe源码研究】第四章:完整案例源码篇(2) :LeNet初始化训练网络 一、Solver到Net SGDSolver的构造函数中主要执行了其父类Solver的构造函数,接着执行Solver::Init()函数,在Init()中,有两个函数值得注意:InitTrainNet()和InitTes 阅读全文 posted @ 2017-06-05 15:07 菜鸡一枚 阅读 (106) | 评论 (0) 编辑 【caffe源码研究】第四章:完整案例源码篇(1) :LeNetSolver初始化 摘要:【caffe源码研究】第四章:完整案例源码篇(1) :LeNetSolver初始化 在训练lenet的train_lenet.sh中内容为: 由此可知,训练网咯模型是由tools/caffe.cpp生成的工具caffe在模式train下完成的。 初始化过程总的来说,从main()、train()中创 阅读全文 posted @ 2017-06-05 09:38 菜鸡一枚 阅读 (134) | 评论 (0) 编辑 【caffe源码研究】第三章:源码篇(6) :caffe.proto 摘要:【caffe源码研究】第三章:源码篇(6) :caffe.proto caffe使用protobuf来定义网络结构、参数等。这里介绍一下caffe.proto里面核心的部分。 Blob 先看Blob相关的protobuf message BlobShape { //数据块形状定义为Num×Chann 阅读全文 posted @ 2017-06-01 22:30 菜鸡一枚 阅读 (203) | 评论 (0) 编辑 摘要:caffe源码解析-solver_factory 声明:内容整理自 Caffe代码解析(4) Caffe Source Code Analysis BUPTLdy/Caffe_Code_Analysis (带注释源码) 感谢Ldy和各位博主的无私分享。各位博主已经写的很好,个人做了一些梳理和补充,方 阅读全文 posted @ 2017-05-31 08:50 菜鸡一枚 阅读 (205) | 评论 (0) 编辑 摘要:caffe 学c++ 编程 技巧 1、 使用模板,泛型编程 [cpp] view plain copy template <typename Dtype> Net<Dtype>::Net(const NetParameter& param) { Init(param); } [cpp] view p 阅读全文 posted @ 2017-05-23 10:14 菜鸡一枚 阅读 (173) | 评论 (0) 编辑 摘要:Caffe代码解析(4) 在上文对Command Line Interfaces进行了简单的介绍之后,本文将对caffe的Solver相关的代码进行分析。 本文将主要分为四部分的内容: Solver的初始化(Register宏和构造函数) SIGINT和SIGHUP信号的处理 Solver::Sol 阅读全文 posted @ 2017-05-13 10:47 菜鸡一枚 阅读 (98) | 评论 (0) 编辑 摘要:Caffe代码解析(3) 在上文对Google Protocol Buffer进行了简单的介绍之后,本文将对caffe的Command Line Interfaces进行分析。 本文将从一个比较宏观的层面上去了解caffe怎么去完成一些初始化的工作和使用Solver的接口函数,本文将主要分为四部分的 阅读全文 posted @ 2017-05-11 22:19 菜鸡一枚 阅读 (128) | 评论 (0) 编辑 摘要:caffe caffe.cpp 程序入口分析 caffe.cpp 程序入口分析, (1)main()函数中,输入的train,test,device_query,time。 通过下面两行进入程序。 if (argc == 2) { return GetBrewFunction(caffe::stri 阅读全文 posted @ 2017-05-11 22:13 菜鸡一枚 阅读 (170) | 评论 (0) 编辑 摘要:一种根据输入动态执行函数 匿名命名空间,使得文件外无法访问这些变量,定义一个类,以数组方式往map中添加一个函数指针。‘#’表示将一个变量变成字符串。‘##’表示拼接一个字符串和一个变量。 使用的方法: 示例: ./main name1 ./main name2 程序的整个思路是: 开始程序,执行宏 阅读全文 posted @ 2017-05-11 21:22 菜鸡一枚 阅读 (70) | 评论 (0) 编辑 摘要:Caffe代码解析(2) 在Caffe中定义一个网络是通过编辑一个prototxt文件来完成的,一个简单的网络定义文件如下: 1 name: "ExampleNet" 2 layer { 3 name: "data" 4 type: "Data" 5 top: "data" 6 top: "labe 阅读全文 posted @ 2017-05-11 10:25 菜鸡一枚 阅读 (80) | 评论 (0) 编辑 摘要:Caffe代码解析(1) Caffe是一个基于C++和cuda开发的深度学习框架。其使用和开发的便捷特性使其成为近年来机器学习和计算机视觉领域最广为使用的框架。 笔者使用Caffe做各种实验也有一段时间了,除了Caffe支持的各种计算方式(卷积/pooling/全连接等)之外,在自己的使用中开始遇到 阅读全文 posted @ 2017-05-10 20:59 菜鸡一枚 阅读 (111) | 评论 (0) 编辑 摘要:Caffe Source Code Analysis Caffe简介 Caffe作为一个优秀的深度学习框架网上已经有很多内容介绍了,这里就不在多说。作为一个C++新手,断断续续看Caffe源码一个月以来发现越看不懂的东西越多,因此在博客里记录和分享一下学习的过程。其中我把自己看源码的一些注释结合了网 阅读全文 posted @ 2017-05-10 10:38 菜鸡一枚 阅读 (215) | 评论 (0) 编辑 Caffe源码学习笔记2:include/caffe/solver_factory.hpp 摘要:Caffe源码学习笔记2:include/caffe/solver_factory.hpp 简要说明:slover是什么?solver是caffe中实现训练模型参数更新的优化算法,solver类派生出的类可以对整个网络进行训练。在caffe中有很多solver子类,即不同的优化算法,如随机梯度下降( 阅读全文 posted @ 2017-05-06 11:08 菜鸡一枚 阅读 (97) | 评论 (0) 编辑 摘要:Caffe源码学习笔记1:tools/caffe.cpp caffe-master/Tools文件夹下提供了caffe框架的主要工具(经编译后为可执行文件,在build/tools/下)。tools/caffe.cpp是caffe程序的入口(即main函数),一条标准的训练指令为: ./build/ 阅读全文 posted @ 2017-05-05 19:48 菜鸡一枚 阅读 (274) | 评论 (0) 编辑 摘要:梳理caffe代码net(四) net定义网络, 整个网络中含有很多layers, net.cpp负责计算整个网络在训练中的forward, backward过程, 即计算forward/backward 时各layer的gradient。 看一下官网的英文描述: The forward and b 阅读全文 posted @ 2017-05-02 10:03 菜鸡一枚 阅读 (237) | 评论 (0) 编辑 摘要:梳理caffe代码io(十三) io包含了创建临时文件临时目录操作,以及从txt文件以及bin文件读取proto数据或者写入proto的数据到txt或者bin文件。io其实就是提供如何读取如何写入的一些读取图像或者文件,以及它们之间的一些转化的函数。 hpp文件: [cpp] view plain 阅读全文 posted @ 2016-04-12 10:31 菜鸡一枚 阅读 (575) | 评论 (0) 编辑 摘要:梳理caffe代码data_transformer(十二) data_transformer详细注释看头文件和实现部分: 头文件: [cpp] view plain copy /////////////////TransformationParameter的caffe消息定义 /* // Messa 阅读全文 posted @ 2016-04-12 09:55 菜鸡一枚 阅读 (8102) | 评论 (0) 编辑 摘要:梳理caffe代码data_reader(十一) 上一篇的blocking_queue到底干了一件什么事情呢?刚刚看完就有点忘记了,再过一会估计忘光了。。。 顾名思义,阻塞队列,就是一个正在排队的打饭队列,先到窗口的先打饭,为什么会高效安全呢?一是像交通有秩序,二是有了秩序是不是交通运行起来就快了。 阅读全文 posted @ 2016-04-11 16:58 菜鸡一枚 阅读 (1057) | 评论 (0) 编辑 摘要:梳理caffe代码blocking_queue(十) 这一个文件基本是我们最头疼的黑色地带,关于XXXX锁,XXXX解锁的问题,遇到的了学习学习,记不住多温习几次就可以。 首先抛开那些官方的条条框框,我们为了不让多个线程同时访问共享的资源是至关重要的。假如一个线程试图改变共享数据的值,而另外一个线程 阅读全文 posted @ 2016-04-11 16:49 菜鸡一枚 阅读 (345) | 评论 (0) 编辑 摘要:梳理caffe代码internal_thread(九) 经过common的学习之后,然后这个InternalThread类实际上就是boost库的thread的封装,然后对线程进行控制和使用。废话不多啰嗦 看看头文件: [cpp] view plain copy class InternalThre 阅读全文 posted @ 2016-04-11 15:30 菜鸡一枚 阅读 (621) | 评论 (0) 编辑 摘要:梳理caffe代码common(八) 由于想梳理data_layer的过程,整理一半发现有几个非常重要的头文件就是题目列出的这几个: 追本溯源,先从根基开始学起。这里面都是些什么鬼呢? common类 命名空间的使用:google、cv、caffe{boost、std}。然后在项目中就可以随意使用g 阅读全文 posted @ 2016-04-11 15:21 菜鸡一枚 阅读 (4417) | 评论 (0) 编辑 摘要:梳理caffe代码layer_factory(六) 因为前一篇描述的是layer层,其实应该先学习工厂模式,最早我也学习过了23中模式设计,不熟悉这个模式的可以看一下下面这段代码。 这个是最简单的工厂模式。 Layer_factory的主要作用是负责Layer的注册,已经注册完事的Layer在运行时 阅读全文 posted @ 2016-04-11 10:56 菜鸡一枚 阅读 (694) | 评论 (0) 编辑 摘要:Caffe源码解析7:Pooling_Layer 转载请注明出处,楼燚(yì)航的blog,http://home.cnblogs.com/louyihang-loves-baiyan/ Pooling 层一般在网络中是跟在Conv卷积层之后,做采样操作,其实是为了进一步缩小feature map, 阅读全文 posted @ 2016-04-10 17:00 菜鸡一枚 阅读 (364) | 评论 (0) 编辑 摘要:Caffe源码解析6:Neuron_Layer 转载请注明出处,楼燚(yì)航的blog,http://home.cnblogs.com/louyihang-loves-baiyan/ NeuronLayer,顾名思义这里就是神经元,激活函数的相应层。我们知道在blob进入激活函数之前和之后他的si 阅读全文 posted @ 2016-04-10 16:13 菜鸡一枚 阅读 (319) | 评论 (0) 编辑 摘要:Caffe源码解析4: Data_layer 转载请注明出处,楼燚(yì)航的blog,http://home.cnblogs.com/louyihang-loves-baiyan/ data_layer应该是网络的最底层,主要是将数据送给blob进入到net中,在data_layer中存在多个跟d 阅读全文 posted @ 2016-04-10 11:25 菜鸡一枚 阅读 (216) | 评论 (0) 编辑 摘要:梳理caffe代码layer(五) Layer(层)是Caffe中最庞大最繁杂的模块。由于Caffe强调模块化设计,因此只允许每个layer完成一类特定的计算,例如convolution操作、pooling、非线性变换、内积运算,以及数据加载、归一化和损失计算等。layer这个类可以说是里面最终的一 阅读全文 posted @ 2016-04-08 21:02 菜鸡一枚 阅读 (1783) | 评论 (0) 编辑 caffe代码阅读5:Layer的实现细节-2016.3.17 摘要:caffe代码阅读5:Layer的实现细节-2016.3.17 一、Layer的作用简介 Layer实际上定义了Layer的基本操作,即初始化层、前向传播和反向传播。在前向传播中根据bottom blob得到top blob,反向传播则根据top反传到bottom。而且在前传的时候还可以计算loss 阅读全文 posted @ 2016-04-07 10:57 菜鸡一枚 阅读 (696) | 评论 (0) 编辑 caffe代码阅读1:blob的实现细节-2016.3.14 摘要:caffe代码阅读1:blob的实现细节-2016.3.14 caffe 中 BLOB的实现 一、前言 等着caffe没有膨胀到很大的程度把caffe的代码理一理 (1)第一次阅读Caffe的源码,给人的印象就是里面大量使用了gtest,确实也简化了不少代码,看起来很清晰。 (2)caffe的文档是 阅读全文 posted @ 2016-04-06 16:30 菜鸡一枚 阅读 (379) | 评论 (0) 编辑 摘要:Caffe源码解析3:Layer 转载请注明出处,楼燚(yì)航的blog,http://home.cnblogs.com/louyihang-loves-baiyan/ layer这个类可以说是里面最终的一个基本类了,深度网络呢就是一层一层的layer,相互之间通过blob传输数据连接起来。首先l 阅读全文 posted @ 2016-03-31 17:03 菜鸡一枚 阅读 (1149) | 评论 (0) 编辑 摘要:Caffe源码解析1:Blob 转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/ 首先看到的是Blob这个类,Blob是作为Caffe中数据流通的一个基本类,网络各层之间的数据是通过Blob来传递的。这里整个代码是 阅读全文 posted @ 2016-03-31 16:17 菜鸡一枚 阅读 (211) | 评论 (0) 编辑 摘要:梳理caffe代码blob(三) 贯穿整个caffe的就是数据blob: [cpp] view plain copy #ifndef CAFFE_BLOB_HPP_ #define CAFFE_BLOB_HPP_ #include <algorithm> #include <string> #inc 阅读全文 posted @ 2016-03-31 15:26 菜鸡一枚 阅读 (4787) | 评论 (0) 编辑 摘要:【Caffe代码解析】SyncedMemory 功能: Caffe的底层数据的切换(cpu模式和gpu模式),需要用到内存同步模块。 源码:头文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 2 阅读全文 posted @ 2016-03-31 10:37 菜鸡一枚 阅读 (1522) | 评论 (0) 编辑 摘要:Caffe源码解析2:SycedMem 转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang loves baiyan/ 看到SyncedMem就知道,这是在做内存同步的操作。这类个类的代码比较少,但是作用是非常明显的。文件对应着syncedme 阅读全文 posted @ 2016-03-31 10:22 菜鸡一枚 阅读 (292) | 评论 (0) 编辑 摘要:梳理caffe代码syncedmem(二) 接着最重要的就是内存分配和Caffe的底层数据的切换(cpu模式和gpu模式),需要用到内存同步模块。这类个类的代码比较少,但是作用是非常明显的。文件对应着syncedmem.hpp,着syncedmem.cpp首先是两个全局的内联函数。如果机器是支持GP 阅读全文 posted @ 2016-03-31 10:21 菜鸡一枚 阅读 (569) | 评论 (0) 编辑 摘要:Caffe源码(一):math_functions 分析 目录 目录 主要函数 caffe_cpu_gemm 函数 caffe_cpu_gemv 函数 caffe_axpy 函数 caffe_set 函数 caffe_add_scalar 函数 caffe_copy 函数 caffe_scal 函数 阅读全文 posted @ 2016-03-30 15:25 菜鸡一枚 阅读 (655) | 评论 (0) 编辑 摘要:梳理caffe代码math_functions(一) 先从caffe中使用的函数入手看看: #include <boost/math/special_functions/next.hpp> #include <boost/random.hpp> #include <limits> #include 阅读全文 posted @ 2016-03-30 13:35 菜鸡一枚 阅读 (473) | 评论 (0) 编辑 摘要:caffe proto文件,和配置文件 要看caffe源码,我认为首先应该看的就是caffe.proto。 它位于…srccaffeproto目录下,在这个文件夹下还有一个.pb.cc和一个.pb.h文件,这两个文件都是由caffe.proto编译而来的。 在caffe.proto中定义了很多 阅读全文 posted @ 2016-03-28 15:37 菜鸡一枚 阅读 (2194) | 评论 (0) 编辑 摘要:caffe的caffe.proto 经过前面“caffe的protocol buffer使用例子”的学习,对caffe.proto熟悉了。 看caffe源码先从这里开始吧。它位于…srccaffeproto目录下,在这个文件夹下还有一个.pb.cc和一个.pb.h文件,这两个文件都是由caff 阅读全文 posted @ 2016-03-28 15:36 菜鸡一枚 阅读 (485) | 评论 (0) 编辑 摘要:caffe源码解析 — caffe.proto 引言 要看caffe源码,我认为首先应该看的就是caffe.proto。 它位于…srccaffeproto目录下,在这个文件夹下还有一个.pb.cc和一个.pb.h文件,这两个文件都是由caffe.proto编译而来的。 在caffe.prot 阅读全文 posted @ 2016-01-27 16:16 菜鸡一枚 阅读 (517) | 评论 (0) 编辑 摘要:caffe源码解析 — blob.cpp 主要参考:linger Reshape(const int num, const int channels, const int height, const int width) 功能:改变一个blob的大小 步骤:1.读入num_,channels_,he 阅读全文 posted @ 2016-01-27 15:36 菜鸡一枚 阅读 (1313) | 评论 (0) 编辑 摘要:Caffe源码(二):blob 分析 目录 目录 简单介绍 源代码分析 Reshape 函数 Blob 构造函数 data_数据操作函数 反向传播导数diff_ 操作函数 ShareData 函数 Updata 函数 asum_data 函数 asum_diff 函数 sumsq_data 函数 s 阅读全文 posted @ 2016-01-27 15:15 菜鸡一枚 阅读 (796) | 评论 (0) 编辑 摘要:【Caffe代码解析】Blob 主要功能: Blob 是Caffe作为数据传输的媒介,无论是网络权重参数,还是输入数据,都是转化为Blob数据结构来存储,网络,求解器等都是直接与此结构打交道的。 其直观的可以把它看成一个有4纬的结构体(包含数据和梯度),而实际上,它们只是一维的指针而已,其4维结构通 阅读全文 posted @ 2016-01-25 15:37 菜鸡一枚 阅读 (1585) | 评论 (0) 编辑 摘要:caffestudy(1)-数据结构(1)以下主要是对于Caffe主页文档的总结1. 结构的生成:caffe的基本结构是采用google的proto库自动生成的,基本流程就是定义一个配置文件,扩展名为proto,调用proto库的编译器编译这个文件可以生成相应的类的c++的代码。具体的可以参见pro... 阅读全文 posted @ 2016-01-21 09:22 菜鸡一枚 阅读 (229) | 评论 (0) 编辑 摘要:Caffe学习笔记1-安装以及代码结构安装按照官网教程安装,我在 OS X 10.9 和 Ubuntu 14.04 上面都安装成功了。主要麻烦在于 glog gflags gtest 这几个依赖项是google上面的需要翻墙。由于我用Mac没有CUDA,所以安装时需要设置 CPU_ONLY := 1... 阅读全文 posted @ 2016-01-20 15:48 菜鸡一枚 阅读 (1213) | 评论 (0) 编辑 摘要:Caffe源码导读(6):LRN层的实现LRN全称为Local Response Normalization,即局部响应归一化层,具体实现在CAFFE_ROOT/src/caffe/layers/lrn_layer.cpp和同一目录下lrn_layer.cu中。该层需要参数有:norm_region... 阅读全文 posted @ 2015-12-02 11:20 菜鸡一枚 阅读 (575) | 评论 (0) 编辑 摘要:Caffe代码导读(5):对数据集进行Testing上一篇介绍了如何准备数据集,做好准备之后我们先看怎样对训练好的模型进行Testing。先用手写体识别例子,MNIST是数据集(包括训练数据和测试数据),深度学习模型采用LeNet(具体介绍见http://yann.lecun.com/exdb/le... 阅读全文 posted @ 2015-12-02 11:18 菜鸡一枚 阅读 (437) | 评论 (0) 编辑 摘要:Caffe代码导读(4):数据集准备Caffe上面有两个比较简单的例子:MNIST和CIFAR-10,前者是用于手写数字识别的,后者用于小图片分类。这两个数据集可以在Caffe源码框架中用脚本(CAFFE_ROOT/data/mnist/get_mnist.sh和CAFFE_ROOT/data/ci... 阅读全文 posted @ 2015-12-02 11:18 菜鸡一枚 阅读 (440) | 评论 (0) 编辑 摘要:Caffe代码导读(3):LevelDB例程Caffe自带例子Cifar10中使用leveldb存储输入数据,为此我们研究一下怎样使用它。安装步骤可以参考http://blog.csdn.net/kangqing2003/article/details/6658345Leveldb库提供了一种持续的... 阅读全文 posted @ 2015-12-02 11:16 菜鸡一枚 阅读 (215) | 评论 (0) 编辑 摘要:Caffe代码导读(2):LMDB简介闪电般的内存映射型数据库管理(LMDB)简介LMDB是基于二叉树的数据库管理库,建模基于伯克利数据库的应用程序接口,但做了大幅精简。整个数据库都是内存映射型的,所有数据获取返回数据都是直接从映射的内存中返回,所以获取数据时没有malloc或memcpy发生。因此... 阅读全文 posted @ 2015-12-02 11:16 菜鸡一枚 阅读 (207) | 评论 (0) 编辑 摘要:Caffe代码导读(1):Protobuf例子Protobuf是一种可以实现内存与外存交换的协议接口。这是由谷歌开发的开源工具,目前研究Caffe源码时用到。一个软件项目 = 数据结构 + 算法 + 参数,对于数据结构和算法我们都已经有较多研究,但不同开发者对参数管理却各有千秋。有人喜欢TXT格式化... 阅读全文 posted @ 2015-12-02 11:15 菜鸡一枚 阅读 (759) | 评论 (0) 编辑 摘要:Caffe代码导读(0):路线图【Caffe是什么?】Caffe是一个深度学习框架,以代码整洁、可读性强、运行速度快著称。代码地址为:https://github.com/BVLC/caffe【博客目的】从接触Caffe、编译运行、阅读代码、修改代码一路走来,学习到不少内容,包括深度学习理论,卷积神... 阅读全文 posted @ 2015-12-02 11:12 菜鸡一枚 阅读 (384) | 评论 (0) 编辑 摘要:Caffe_Manual/get_features.cpp根据反馈,专门写了个cpp文件,可以一次前向,同时完成多层的特征提取、最后的概率输出以及Top标签输出,见get_features.cpp文件:/*** usage: get_features.exe feat.prototxt H:Mod... 阅读全文 posted @ 2015-08-11 19:03 菜鸡一枚 阅读 (648) | 评论 (0) 编辑 摘要:Caffe C++使用教程Caffe使用教程by Shicai Yang(@星空下的巫师)on 2015/08/06初始化网络#include "caffe/caffe.hpp"#include #include using namespace caffe;char *proto = "H:\Mo... 阅读全文 posted @ 2015-08-09 19:24 菜鸡一枚 阅读 (5718) | 评论 (0) 编辑 摘要:caffe源码分析--softmax_layer.cpp文件位置为caffe-master/src/caffe/layers/softmax_layer.cpp这个是一个以前版本的程序,现在的代码有些不同了,不过可以参考caffe源码分析--softmax_layer.cpp[cpp]view pl... 阅读全文 posted @ 2015-05-14 15:20 菜鸡一枚 阅读 (2412) | 评论 (0) 编辑 摘要:Caffe4——计算图像均值均值削减是数据预处理中常见的处理方式,按照之前在学习ufldl教程PCA的一章时,对于图像介绍了两种:第一种常用的方式叫做dimension_mean(个人命名),是依据输入数据的维度,每个维度内进行削减,这个也是常见的做法;第二种叫做per_image_mean,ufl... 阅读全文 posted @ 2015-05-14 15:13 菜鸡一枚 阅读 (2564) | 评论 (0) 编辑 Caffe3——ImageNet数据集创建lmdb类型的数据 摘要:Caffe3——ImageNet数据集创建lmdb类型的数据ImageNet数据集和cifar,mnist数据集最大的不同,就是数据量特别大;单张图片尺寸大,训练样本个数多;面对如此大的数据集,在转换成lmdb文件时;使用了很多新的类型对象。1,动态扩容的数组“vector”,动态地添加新元素2,p... 阅读全文 posted @ 2015-05-05 15:15 菜鸡一枚 阅读 (1908) | 评论 (0) 编辑 Caffe2——cifar10数据集创建lmdb或leveldb类型的数据 摘要:Caffe2——cifar10数据集创建lmdb或leveldb类型的数据cifar10数据集和mnist数据集存储方式不同,cifar10数据集把标签和图像数据以bin文件的方式存放在同一个文件内,这种存放方式使得每个子cifar数据bin文件的结构相同,所以cifar转换数据代码比mnist的代... 阅读全文 posted @ 2015-05-05 15:14 菜鸡一枚 阅读 (2326) | 评论 (0) 编辑 Caffe1——Mnist数据集创建lmdb或leveldb类型的数据 摘要:Caffe1——Mnist数据集创建lmdb或leveldb类型的数据Leveldb和lmdb简单介绍Caffe生成的数据分为2种格式:Lmdb和Leveldb。它们都是键/值对(Key/Value Pair)嵌入式数据库管理系统编程库。虽然lmdb的内存消耗是leveldb的1.1倍,但是lmdb... 阅读全文 posted @ 2015-05-05 15:13 菜鸡一枚 阅读 (4733) | 评论 (0) 编辑 友情链接: 昵称: 菜鸡一枚 关注成功
搜索积分与排名
随笔分类
Copyright © 2019 菜鸡一枚 Powered by .NET Core 3.0 Preview 8 on Linux |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
.proto 文件要会读、读熟
数据结构:https://blog.csdn.net/Teeyohuang/article/details/76619125
Caffe (2) SyncedMemory内存管理机制
讲得比较体贴入微!
https://blog.csdn.net/hnshahao/article/details/81218713
|
在Caffe中,blob是对于上层空间的数据管理存储对象,对于上层来说的话,大部分时候是直接取blob对象的指针来用,如果不考虑GPU的情况下,实际上很简单,就是返回指针就行,但是问题是通常的数据是在GPU和CPU上同时存在,需要两个数据在不同的设备上进行同步,那么SyncedMemory的作用是实际上在管理实际数据。对于Blob中,封装的3个SyncedMemory对象的智能指针: 【大的逻辑】 SyncedMemory对象实际管理着数据空间,一个blob可以包含多个SyncedMemory对象的智能指针。SyncedMemory中主要完成数据空间的创建,GPU数据和CPU数据,数据空间的释放,以及GPU和CPU数据的同步。 |
|
【细节逻辑】 SyncedMemory对象管理着一个数据对象,数据对象是一个tensor. 这个数据对象可能只存在CPU上,或者只存在GPU上,或者同时存在两个位置上。对于一个数据对象,按道理来说,存储情况会存在几种可能, (1)只存在CPU上,这时候通过*cpu_ptr_就能访问 (2)只存在CPU上,这时候通过*cpu_ptr_就能访问 (3)需要同时存在CPU和GPU上,那么需要在两个设备上,数据需要同步。希望的效果是两个不同位置的数据是一致的。所谓的同步是指,当一方的数据发生变化时,另外一方的数据需要更新。比如CPU上的数据发生变化,那么需要同步把GPU上的数据更新。这样就涉及到一个何时更新的问题,更新太频繁,比如一方发生变化,就去更新另外一方,这样会导致额外的开销。 那么这时候就会涉及到一个同步管理的问题,实际上对于每个SyncedMemory对象都包含了一个head_变量,标志着目前被管理的数据对象的同步情况 1:head_ 状态机变量介绍,功能 取值是4种可能,UNINITIALIZED, HEAD_AT_CPU, HEAD_AT_GPU, SYNCED, (1) UNINITIALIZED -- 表示这个数据对象的存储空间没有被初始化,对于这样的情况,需要alloc memory, 分配内存可能会分配在CPU或者GPU上 (2)HEAD_AT_CPU -- 表示的是目前在CPU空间上的数据对象的备份是最新的,或者说,目前CPU上的数据是能够反映当前SyncedMemory所管理数据对象的最新状态,那么对于GPU上的数据备份就不是最新的 (3)HEAD_AT_GPU -- 表示的是目前在GPU空间上的数据对象的备份是最新的,或者说目前GPU上数据是能够反映当前SyncedMemory所管理数据对象的最新状态,那么对于GPU上的数据备份就不是最新的 (4)SYNCED -- 表示的是目前GPU和CPU空间上的数据是同步的,两个位置都能反映当前SyncedMemory所管理数据对象的最新状态 2:下面的问题是这个状态变量是如何改变的状态机变量的值 在SyncedMemory.cpp文件中,改变状态机变量,主要有两个函数,这里的改变是指状态机变量的值发生变化,从一个值变化到另外一个值。 (1) to_cpu() 函数 - //函数作用是让现在数据最新备份至少出现在cpu上 |
| 在每次Blob对象调用函数,cpu_data()或者gpu_data()返回数据指针的时候,都是希望被返回的数据指针是能够反映当前tensor的最新状态,访问CPU指针,那么希望CPU上具有tensor数据的最新备份,访问GPU指针,那么希望GPU上有tensor数据的最新备份。而内部的管理是通过SyncedMemory对象的内部状态机来管理。 ———————————————— 版权声明:本文为CSDN博主「hnshahao」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/hnshahao/article/details/81218713 |
| 这里的new SyncedMemory(并没有开始申请空间),只是设置了head_(UNINITIALIZED)这个标志,在实际访问指针的时候,创建内容空间 |
| 在每次Blob对象调用函数,cpu_data()或者gpu_data()返回数据指针的时候,都是希望被返回的数据指针是能够反映当前tensor的最新状态,访问CPU指针,那么希望CPU上具有tensor数据的最新备份,访问GPU指针,那么希望GPU上有tensor数据的最新备份。而内部的管理是通过SyncedMemory对象的内部状态机来管理。 |
 |
https://blog.csdn.net/xizero00/article/details/51001206
caffe代码阅读9:SyncedMemory的实现细节-2016.3.28
https://blog.csdn.net/hangdianabc/article/details/72902322
caffe1源码解析从入门到放弃1):内存管理syncedmem.hpp / syncedmem.cpp
caffe源码分析-Blob
讲得相当之好
https://cloud.tencent.com/developer/article/1394880
Blob主要函数,核心在于Blob的使用实例以及其与opencv Mat的操作的相互转化(附带运行结果基于CLion) |
|
其直观的可以把它看成一个有4维的结构体(包含数据和梯度),而实际上,它们只是一维的指针而已,其4维结构通过shape属性得以计算出来(根据C语言的数据顺序)。
|
|
Blob中的主要数据成员如下,实际是在SyncedMemory上做了一层包装(SyncedMemory介绍见上一篇blog): |
|
主要函数 主要分析如下几类函数:
|
|
|
知乎上的讨论:https://www.zhihu.com/question/27982282 从0开始山寨caffe系列:http://www.cnblogs.com/neopenx/archive/2016/02.html caffe源码阅读系列:http://blog.csdn.net/xizero00?viewmode=contents http://blog.csdn.net/langb2014/article/category/5998589/1 Google Protocol Buffer 的使用和原理:http://www.ibm.com/developerworks/cn/linux/l-cn-gpb/ |
|
caffe系列源码分析介绍 本系列深度学习框架caffe 源码分析主要内容如下: 1. caffe源码分析-cmake 工程构建: caffe源码分析-cmake 工程构建主要内容: 自己从头构建一遍工程,这样能让我更好的了解大型的项目的构建。当然原始的caffe的构建感觉还是比较复杂(主要是cmake),我这里仅仅使用cmake构建,而且简化点,当然最重要的是支持CLion直接运行调试(如果需要这个工程可以评论留下你的邮箱,我给你发送过去)。
主要内容: 3. caffe layer的源码分析,包括从整体上说明了layer类别以及其proto定义与核心函数. 内容如下: 首先分析了最简单的layer Relu,然后在是inner_product_layer全连接层, 最后是layer_factorycaffe中 以此工厂模式create各种Layer. 4. 数据输入层,主要是多线程+BlockingQueue的方式读取数据训练: 内容如下: 5. IO处理例如读取proto文件转化为网络,以及网络参数的序列化 内容如下: 6. 最后给出了使用纯C++结合多层感知机网络训练mnist的示例 内容如下: caffe c++示例(mnist 多层感知机c++训练,测试) 类似与caffe一样按照layer、solver、loss、net等模块构建的神经网络实现可以见下面这篇blog,相信看懂了这个python的代码理解caffe框架会更简单点. 神经网络python实现 |
Caffe 源码解析之 Blob
https://imbinwang.github.io/research/inside-caffe-code-blob
| https://imbinwang.github.io/research/inside-caffe-code-blob |
|
Blob作为Caffe的四大模块之一,负责完成CPU/GPU存储申请、同步和数据持久化映射。Caffe内部数据存储和通讯都是通过Blob来完成,Blob提供统一的存储操作接口,可用来保存训练数据、模型参数等。 模块说明 Blob是一个N维连续数组。批处理图像数据时通常使用4维Blob,Blob的维度可以表示为(N, K, H, W),每个维度的意思分别是:
Blob中数据是row-major存储的,W是变化最快的维度,例如在(n, k, h, w)处的数据,其物理偏移量计算方式为 ((n∗K+k)∗H+h)∗W+w Caffe中通常只使用4维Blob完成图像应用,但是Blob完全可以合理地被用来存储任何数据,例如,
对于自定义数据,通常需要我们自己准备数据处理工具,编写自定义的data layer。一旦数据准备完毕,剩下的工作交给layers模块来完成。 实现细节Blob内部其实包含两个存储对象 |
|
核心操作: |
https://blog.shinelee.me/2018/11-23-Caffe源码理解1:Blob存储结构与设计.html
Layer
|
三、Layer:Caffe的基本计算单元 Layer至少有一个输入Blob(Bottom Blob)和一个输出Blob(Top Blob),部分Layer带有权值和偏置项;
Layer头文件位于include/caffe/layer.hpp中; |
|
注意:caffe类中成员变量名都带有后缀“_”,这样再返俗世相中容易区分临时变量和类变量。 Layer至少有一个输入Blob(Bottom Blob)和一个输出Blob(Top Blob),部分Layer带有权值和偏置项;
Layer头文件位于include/caffe/layer.hpp中; 四、Net:Caffe中网站的CNN模型,包含若干Layer实例 (1)基本用法 描述文件 *.prototxt (models/bvlc_reference_caffenet/deploy.prototxt ); (3)Net绘成法 下面有两类Blob:
Blob提供数据容器的机制; |

https://blog.shinelee.me/2018/11-23-Caffe源码理解1:Blob存储结构与设计.html

Nd=4,Blob表示卷积层kernel参数时,N为当前层输出特征图的数量,其与卷积核数量相同,C为当前层输入特征图的数量,其与一个卷积核的层数相同,H和W为卷积核的高和宽,每个卷积是三维的即$CHW$。
理解上述这段的基础见:https://blog.csdn.net/chenxuanhanhao/article/details/99709517