https://blog.csdn.net/wzq6578702/article/month/2017/05
|
2017-05-29 14:48:59 阅读数 583 评论数 0 原 hive原理与源码分析-服务化:LLAP、HiveServer2、MetaStore(七) 2017-05-21 16:43:39 阅读数 1302 评论数 0 2017-05-20 10:04:35 阅读数 1745 评论数 0 原 hive原理与源码分析-UDxF、优化器及执行引擎(五) 2017-05-14 22:45:45 阅读数 1170 评论数 0 原 hive原理与源码分析-算子Operators及查询优化器Optimizers(四) 2017-05-13 14:22:20 阅读数 1083 评论数 0 使用IDE调试一条简单的SQL 画出AST 画出Operator Tree已有表结构:hive> desc src; OK key int value ... 2017-05-07 22:28:49 阅读数 2683 评论数 0 2017-05-07 15:46:58 阅读数 2568 评论数 1 2017-05-06 11:34:35 阅读数 7274 评论数 1 |
|
hive原理与源码分析-hive源码架构与理论(一)
什么是Hive?
数据仓库:存储、查询、分析大规模数据
SQL语言:简单易用的类SQL查询语言
编程模型:允许开发者自定义UDF、Transform、Mapper、Reducer,来更简单地完成复杂MapReduce无法完成的工作
数据格式:处理Hadoop上任意数据格式的数据,或者使用优化的格式存储Hadoop上的数据,RCFile,ORCFile,Parquest
数据服务:HiveServer2,多种API访问Hadoop上的数据,JDBC,ODBC
元数据服务:数据什么样,数据在哪里,Hadoop上的唯一标准
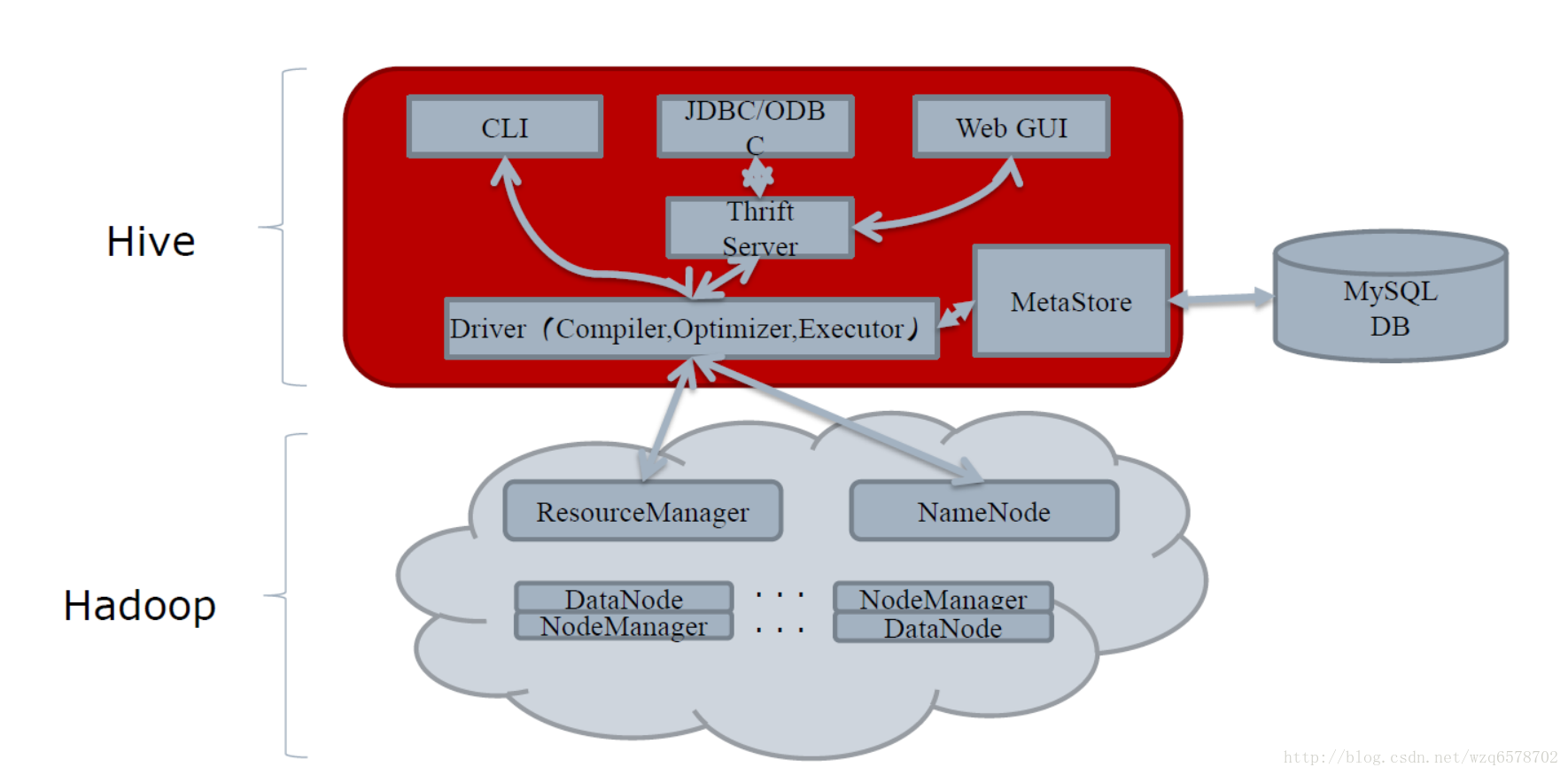
Hive和Hadoop的关系 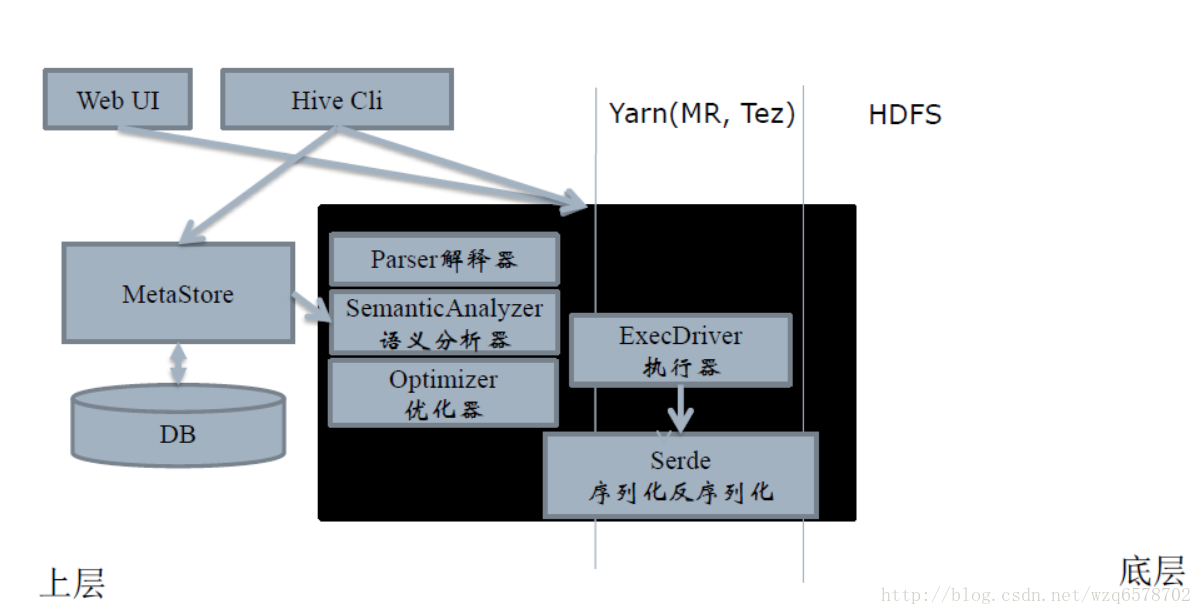
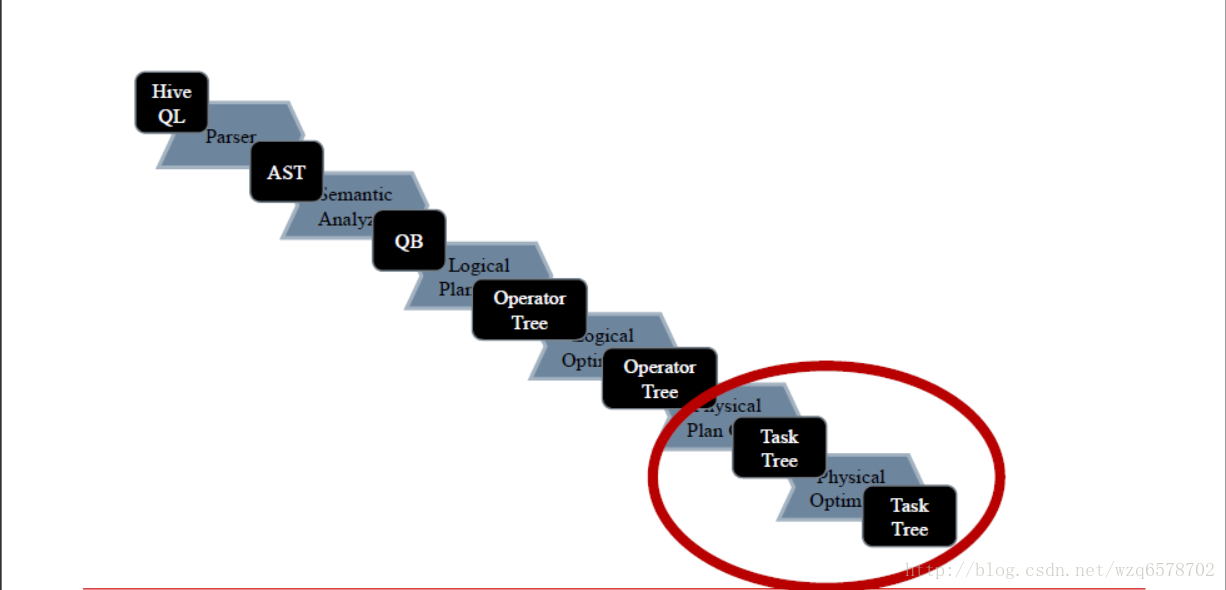
Compiler的流程
hive简单理解的功能就是把一条sql进行解析成mr任务去给hadoop执行,那么hive的核心就是怎么去解释这条sql: 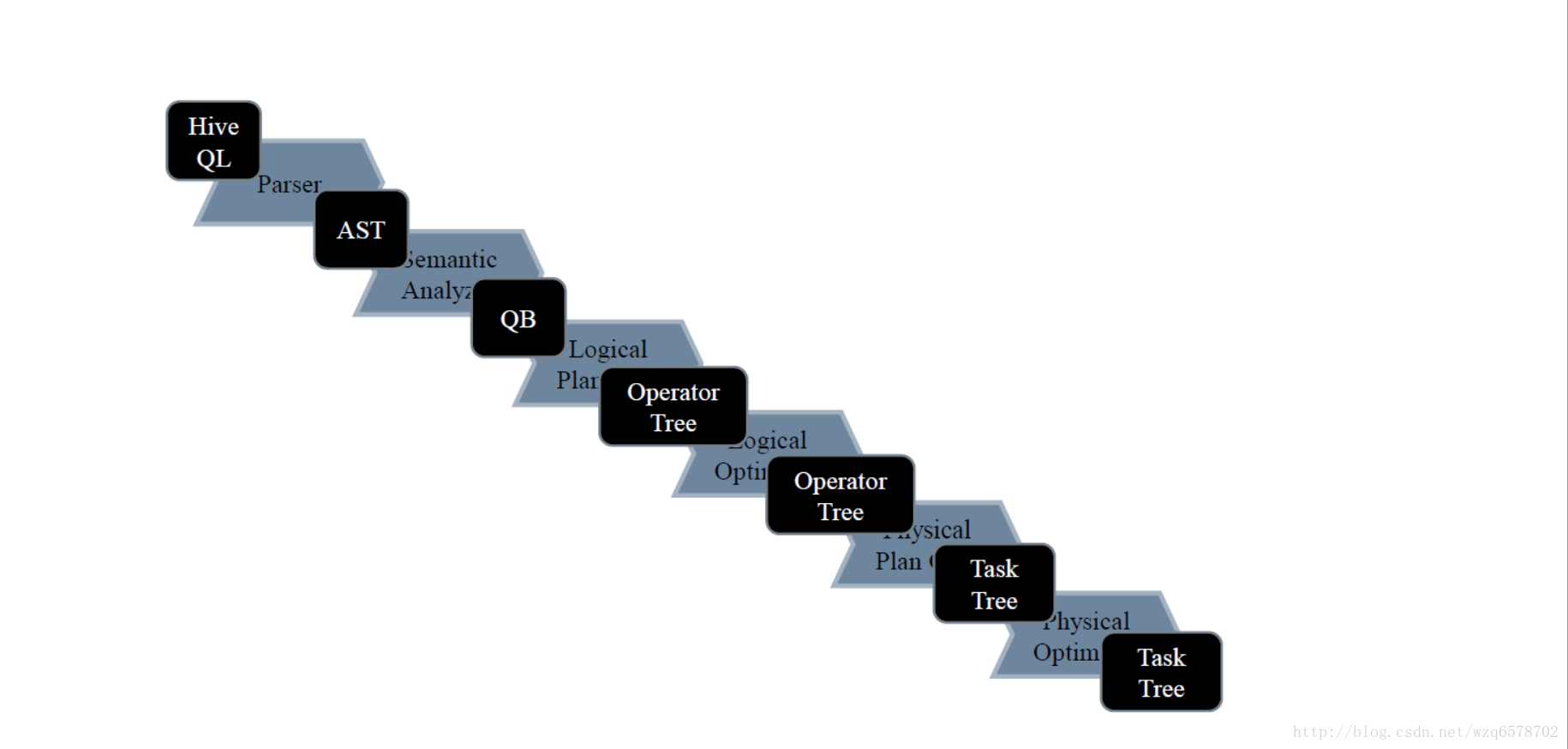
源码在哪里?
三个重要的模块: 
这个类是解析sql的入口
源码位置
入参是一条字符串的sql,输出是一棵树(AST【抽象语法树(abstract syntax tree或者缩写为AST),或者语法树(syntax tree)】),ASTNode 是树的头结点,他有孩子的数组,
public ASTNode parse(String command, Context ctx)
throws ParseException {
return parse(command, ctx, true);
}- 1
- 2
- 3
- 4
ASTNode:
ASTNode获取孩子节点的方法:
/*
* (non-Javadoc)
*
* @see org.apache.hadoop.hive.ql.lib.Node#getChildren()
*/
@Override
public ArrayList<Node> getChildren() {
if (super.getChildCount() == 0) {
return null;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
接下来是一颗抽象语法树变成一个QB(query block)
SemanticAnalyzer.java (语义分析器),之前老的版本大约将近7000行代码,由于Java一个类的代码行数过多时会出现编译上的问题,现在优化分割了。
需要一个树的根节点ast就能对整棵树进行解析(深度优先搜索)。
......略........
@Override
@SuppressWarnings("nls")
public void analyzeInternal(ASTNode ast) throws SemanticException {
reset();
QB qb = new QB(null, null, false);//最终返回结果
this.qb = qb;
this.ast = ast;
ASTNode child = ast;
...........略.....
// continue analyzing from the child ASTNode.
doPhase1(child, qb, initPhase1Ctx());
getMetaData(qb);//元数据
LOG.info("Completed getting MetaData in Semantic Analysis");
Operator sinkOp = genPlan(qb);//将qb生成DAG
......略........
ParseContext pCtx = new ParseContext(conf, qb, child, opToPartPruner,
opToPartList, topOps, topSelOps, opParseCtx, joinContext, topToTable,
loadTableWork, loadFileWork, ctx, idToTableNameMap, destTableId, uCtx,
listMapJoinOpsNoReducer, groupOpToInputTables, prunedPartitions,
opToSamplePruner);
Optimizer optm = new Optimizer();//逻辑优化器
optm.setPctx(pCtx);
optm.initialize(conf);
pCtx = optm.optimize();
init(pCtx);
qb = pCtx.getQB();
............略.......
genMapRedTasks(qb);
............略......- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
最后生成一个QB:
..............................略.........
public class QB {
private static final Log LOG = LogFactory.getLog("hive.ql.parse.QB");
private final int numJoins = 0;
private final int numGbys = 0;
private int numSels = 0;
private int numSelDi = 0;
private HashMap<String, String> aliasToTabs;
private HashMap<String, QBExpr> aliasToSubq;
private List<String> aliases;
**private QBParseInfo qbp;
private QBMetaData qbm;**
private QBJoinTree qbjoin;
private String id;
private boolean isQuery;
private CreateTableDesc tblDesc = null; // table descriptor of the final
..............................略...............- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
QB的两个重要变量是 qbp和qbm他们都有QB的引用,这样组成了一棵树。
在analyzeInternal方法中 Operator sinkOp = genPlan(qb); 我们看一下Operator类的结构:
public abstract class Operator<T extends Serializable> implements Serializable,
Node {
// Bean methods
private static final long serialVersionUID = 1L;
protected List<Operator<? extends Serializable>> childOperators;
protected List<Operator<? extends Serializable>> parentOperators;
protected String operatorId;
......................略.............- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
从代码中可以看到Operator 有很多children和parent,由此这是一个有向无环图(DAG),QB经过genPlan()方法变成了一个DAG,接下来的Optimizer optm = new Optimizer(); 是逻辑优化器,那么hive有多少逻辑优化器呢?进入Optimizer: 
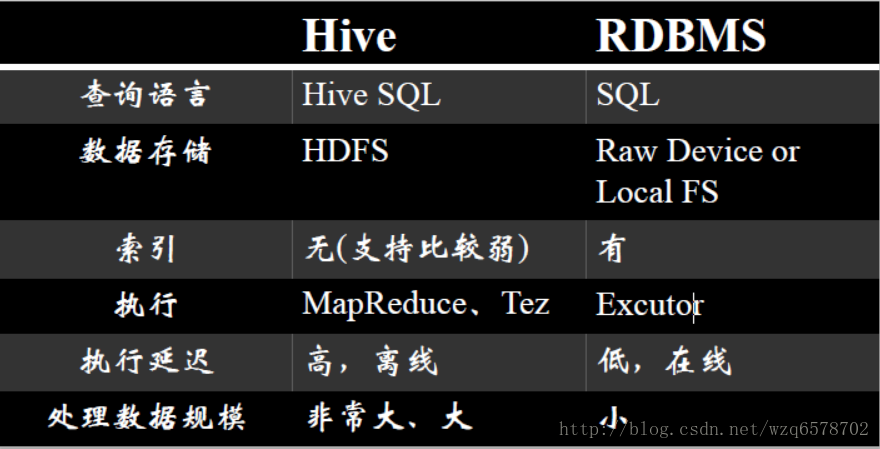
Hive和数据库RDBMS
Hive数据模型
DataBase
和RDBMS中数据库的概念一致
每一个DataBase都对应的一个HDFS目录
例如:
Hive > create database hugo;
对应的HDFS目录是:
/user/hugo/hive/hugo.db
元数据
对hdfs数据的描述与映射,可以理解为数据的数据。关于hive的学习重点是hive query language手册的翻阅
排序与分发的各种By
与传统关系型数据库最大的区别就是处理数据的能力
这种能力最大的体现就是排序与分发的原理
order by 是全局排序,只有一个reduce,数据量多时速度慢
sort by 是随机分发到一个reduce然后reduce内部排序
distribute by 是根据 distribute by 的字段把相应的记录分发到那个reduce
cluster by是distribute by + sort by的简写
查看查询计划
explain 命令,可以用于查看对应查询而产生的查询计划
例如:
Hive > explian select * from src limit 1;
ABSTRACT SYNTAX TREE:
(TOK_QUERY (TOK_FROM (TOK_TABREF (TOK_TABNAME src))) (TOK_INSERT (TOK_DESTINATION (TOK_DIR TOK_TMP_FILE)) (TOK_SELECT (TOK_SELEXPR TOK_ALLCOLREF)) (TOK_LIMIT 1)))
STAGE DEPENDENCIES:
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-0
Fetch Operator
limit: 1
常用优化
扫描相关
谓词下推(Predicate Push Down)
列剪裁(Column Pruning)
分区剪裁(Partition Pruning)
关联JOIN相关
Join操作左边为小表
Join启动的job个数
MapJoin
分组Group By相关
Skew In Data
合并 小文件
列剪裁(Column Pruning)
在读数据的时候,只关心感兴趣的列,而忽略其他列,尽量不要写select * from XXX
例如,对于查询:
select a,b from src where e < 10;
其中,src 包含 5 个列 (a,b,c,d,e),列 c,d 将会被忽略,只会读取a, b, e 列
选项默认为真: hive.optimize.cp = true
分区剪裁(Partition Pruning)
在查询的过程中减少不必要的分区
例如,对于下列查询:
SELECT * FROM T1 JOIN (SELECT * FROM T2) subq ON (T1.c1=subq.c2)
WHERE subq.prtn = 100;
会在子查询中就考虑 subq.prtn = 100 条件,从而减少读入的分区数目。
选项默认为真: hive.optimize.pruner=true
Join操作左边为小表
应该将条目少的表/子查询放在 Join 操作符的左边
原因是在 Join 操作的 Reduce 阶段,位于 Join 操作符左边的表的内容会被加载进内存,将条目少的表放在左边,可以有效减少发生 OOM 错误的几率
Join启动的job个数
如果 Join 的 key 相同,不管有多少个表,都会则会合并为一个 Map-Reduce
一个 Map-Reduce (Tez)任务,而不是 ‘n’ 个
在做 OUTER JOIN 的时候也是一样
INSERT OVERWRITE TABLE pv_users
SELECT pv.pageid, u.age FROM page_view p
JOIN user u ON (pv.userid = u.userid)
JOIN newuser x ON (u.userid = x.userid);
join不支持不等值连接
!= <> 在join的on条件中不支持
select …. from ….
join ….
on (a.key != b.key);
为什么?
想象一下a.key是不均匀的,加入一共1亿条数据,只有一条数据的key是1,其他的都是0,这样会撑爆一个节点。而且回去其他机器找数据是找不到的。
Group By - Skew In Data
主要关注的是数据倾斜
hive.groupby.skewindata = true
当选项设定为 true,生成的查询计划会有两个 MR Job。
第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;
第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作
合并小文件
合并功能会增加任务运行时间。
合并操作的性能很大程度上取决于“单个reduce端输出文件大小”。Reduce端的输出越大,耗时越长。
合并操作会对每个Hive任务增加一次MapReduce任务。
小文件越多,读取metastore的次数就越多,sql的解析变慢,而且小文件对hadoop伤害很大。hadoop不怕文件大,就怕文件小而且多,这样文件的映射在namenode中就多,namenode负载过大,为此hive对小文件进行合并。
SerDe
SerDe 是 Serialize/Deserilize 的简称,目的是用于序列化和反序列化。
序列化(往磁盘上写)的格式包括:
分隔符(tab、逗号、CTRL-A)
Thrift 协议
反序列化(往内存里读):
Java Integer/String/ArrayList/HashMap
Hadoop Writable 类
用户自定义类
何时考虑增加新的SerDe
用户的数据有特殊的序列化格式,当前的 Hive 不支持,而用户又不想在将数据加载至 Hive 前转换数据格式
用户有更有效的序列化磁盘数据的方法
例子-使用RegexSerDe
CREATE TABLE apache_log(
host STRING, identity STRING, user STRING,
time STRING, request STRING, status STRING,
size STRING, referer STRING, agent STRING)
ROW FORMAT SERDE ‘org.apache.hadoop.hive.contrib.serde2.RegexSerDe’
WITH SERDEPROPERTIES
( “input.regex” = “([^ ]) ([^ ]) ([^ ]) (-|^]) ([^ ”]|”[^”]”) (-|[0-9]) (-|[0-9])(?: ([^ ”]|”[^”]”) ([^ ”]|”[^”]”))?”,
“output.format.string” = “%1
s
s %3
s
s %5
s
s %7
s
s %9$s”
) STORED AS TEXTFILE;
hive原理与源码分析-语法分析器和语义分析器(二)
玩个游戏:
执行:find . -name ‘*.java’ | xargs grep –color ‘main(’ | awk ‘{print $1}’ | uniq | grep -v test
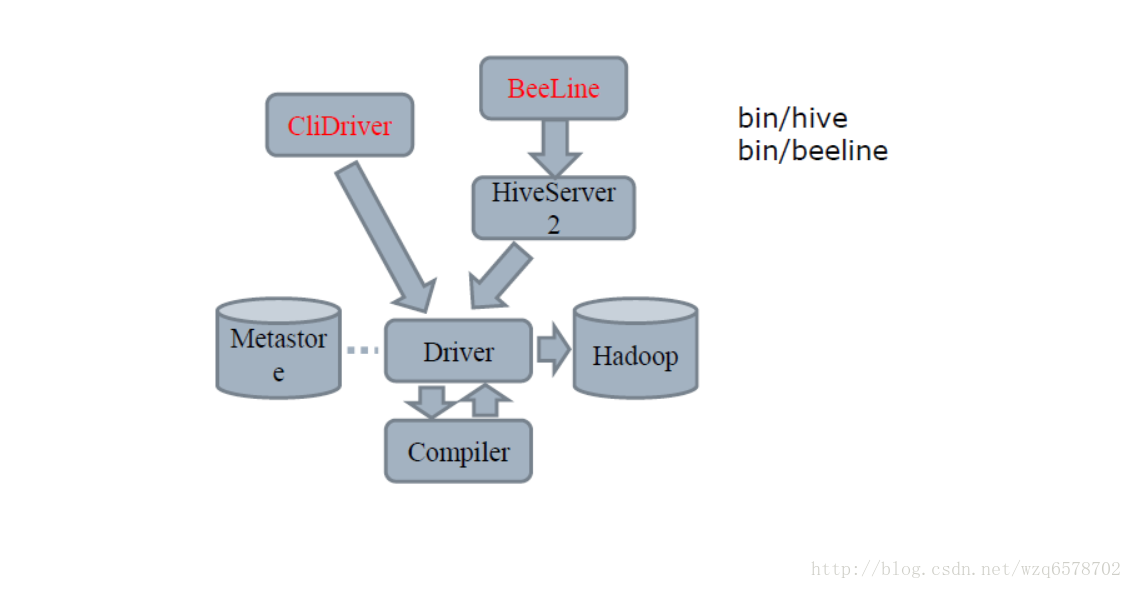
找到cli的执行main方法:
https://insight.io/github.com/apache/hive/blob/master/cli/src/java/org/apache/hadoop/hive/cli/CliDriver.java?line=685
public static void main(String[] args) throws Exception {
int ret = new CliDriver().run(args);
System.exit(ret);
}- 1
- 2
- 3
- 4
main方法调用了CliDriver实体的runmethod:
在run methond中最后返回的是executeDriver方法
public int run(String[] args) throws Exception {
。。。。。。。。。略 。。。
return executeDriver(ss, conf, oproc);
。。。。。。。。。略- 1
- 2
- 3
- 4
继续跟进executeDriver():
private int executeDriver(CliSessionState ss, HiveConf conf, OptionsProcessor oproc)
throws Exception {
。。。。。。。。略
while ((line = reader.readLine(curPrompt + "> ")) != null) {
if (!prefix.equals("")) {
prefix += '
';
}
if (line.trim().startsWith("--")) {
continue;
}
if (line.trim().endsWith(";") && !line.trim().endsWith("\;")) {
line = prefix + line;
ret = cli.processLine(line, true);
prefix = "";
curDB = getFormattedDb(conf, ss);
curPrompt = prompt + curDB;
dbSpaces = dbSpaces.length() == curDB.length() ? dbSpaces : spacesForString(curDB);
} else {
prefix = prefix + line;
curPrompt = prompt2 + dbSpaces;
continue;
}
}
。。。。。。。。。。略- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
executeDriver方法将一条sql用“;”拆分成多条语句,每条语句执行 ret = cli.processLine(line, true);
/**
* Processes a line of semicolon separated commands
* @param line The commands to process
* @param allowInterrupting When true the function will handle SIG_INT (Ctrl+C) by interrupting the processing and
* returning -1
* @return 0 if ok
*/
public int processLine(String line, boolean allowInterrupting) {
。。。。。。。。。略
ret = processCmd(command);
。。。。。。。。。略- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
然后进入processCmd方法:
public int processCmd(String cmd) {
。。。。。。。。。略。。。。。。。
if (cmd_trimmed.toLowerCase().equals("quit") || cmd_trimmed.toLowerCase().equals("exit")) {
。。。。。。。。。略。。。。。。。
} else if (tokens[0].equalsIgnoreCase("source")) {
。。。。。。。。。略。。。。。。。
} else if (cmd_trimmed.startsWith("!")) {
。。。。。。。。。略。。。。。。。
} else { // local mode
try {
CommandProcessor proc = CommandProcessorFactory.get(tokens, (HiveConf) conf);
ret = processLocalCmd(cmd, proc, ss);
} catch (SQLException e) {
console.printError("Failed processing command " + tokens[0] + " " + e.getLocalizedMessage(),
org.apache.hadoop.util.StringUtils.stringifyException(e));
ret = 1;
}
}
ss.resetThreadName();
return ret;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
首先processCmd判断是不是退出命令,然后是source和“!”开始的特殊命令(非SQL)的处理,最后是sql的处理逻辑,
CommandProcessor proc = CommandProcessorFactory.get(tokens, (HiveConf) conf);这句生成了一个CommandProcessor ,那么CommandProcessor 是个什么鬼呢?进入get方法看看:
public static CommandProcessor get(String[] cmd, HiveConf conf)
throws SQLException {
CommandProcessor result = getForHiveCommand(cmd, conf);
if (result != null) {
return result;
}
if (isBlank(cmd[0])) {
return null;
} else {
if (conf == null) {
return new Driver();//此处返回的是一个Driver,即Driver是CommandProcessor 的下属类型。
}
Driver drv = mapDrivers.get(conf);
if (drv == null) {
drv = new Driver();
mapDrivers.put(conf, drv);
} else {
drv.resetQueryState();
}
drv.init();
return drv;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
所以
CommandProcessor proc = CommandProcessorFactory.get(tokens, (HiveConf) conf);
ret = processLocalCmd(cmd, proc, ss);- 1
- 2
这里的proc是一个Driver,进入processLocalCmd:
int processLocalCmd(String cmd, CommandProcessor proc, CliSessionState ss) {
int tryCount = 0;
boolean needRetry;
int ret = 0;
do {
try {
needRetry = false;
if (proc != null) {
if (proc instanceof Driver) {//一定为true
Driver qp = (Driver) proc;
PrintStream out = ss.out;
long start = System.currentTimeMillis();
if (ss.getIsVerbose()) {
out.println(cmd);
}
qp.setTryCount(tryCount);
ret = qp.run(cmd).getResponseCode();//此处调用的是Driver的run
if (ret != 0) {
qp.close();
return ret;
}
。。。。。。。。。。略- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
进入run方法
@Override
public CommandProcessorResponse run(String command)
throws CommandNeedRetryException {
return run(command, false);
}
public CommandProcessorResponse run(String command, boolean alreadyCompiled)
throws CommandNeedRetryException {
CommandProcessorResponse cpr = runInternal(command, alreadyCompiled);
if(cpr.getResponseCode() == 0) {
return cpr;
}
SessionState ss = SessionState.get();
if(ss == null) {
return cpr;
}
MetaDataFormatter mdf = MetaDataFormatUtils.getFormatter(ss.getConf());
if(!(mdf instanceof JsonMetaDataFormatter)) {
return cpr;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
CommandProcessorResponse cpr = runInternal(command, alreadyCompiled);执行sql的编译和返回结果:
private CommandProcessorResponse runInternal(String command, boolean alreadyCompiled)
throws CommandNeedRetryException {
。。。。。略
// compile internal will automatically reset the perf logger
ret = compileInternal(command, true);
。。。。。。。略- 1
- 2
- 3
- 4
- 5
- 6
private int compileInternal(String command, boolean deferClose) {
。。。。。。略。。。。
try {
ret = compile(command, true, deferClose);
} finally {
compileLock.unlock();
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
compile(command, true, deferClose);
就是hive的入口了。
Driver的run方法最终会执行compile()操作,Compiler作语法解析和语义分析。
回顾一下解析步骤:
第一部分:语法分析
语法解析Parser
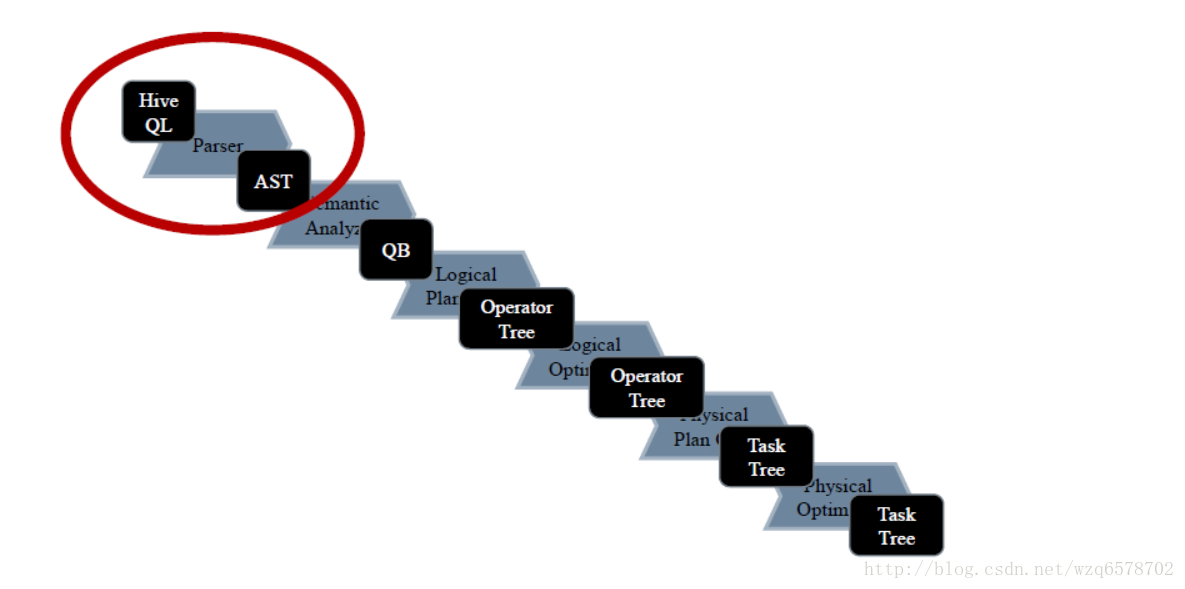
tree = ParseUtils.parse(command, ctx);【源码】ParseUtils封装了ParseDriver 对sql的解析工作,ParseUtils的parse方法:
/** Parses the Hive query. */
public static ASTNode parse(
String command, Context ctx, boolean setTokenRewriteStream) throws ParseException {
ParseDriver pd = new ParseDriver();
ASTNode tree = pd.parse(command, ctx, setTokenRewriteStream);
tree = findRootNonNullToken(tree);
handleSetColRefs(tree);
return tree;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
ParseDriver 对command进行词法分析和语法解析(统称为语法分析),返回一个抽象语法树AST,进入parseDriver的parse方法:
public ASTNode parse(String command, Context ctx, boolean setTokenRewriteStream)
throws ParseException {
if (LOG.isDebugEnabled()) {
LOG.debug("Parsing command: " + command);
}
HiveLexerX lexer = new HiveLexerX(new ANTLRNoCaseStringStream(command));//词法分析
TokenRewriteStream tokens = new TokenRewriteStream(lexer);//根据词法分析的结果得到tokens的,此时不只是单纯的字符串,而是具有特殊意义的字符串的封装,其本身是一个流。
if (ctx != null) {
if ( setTokenRewriteStream) {
ctx.setTokenRewriteStream(tokens);
}
lexer.setHiveConf(ctx.getConf());
}
HiveParser parser = new HiveParser(tokens);
if (ctx != null) {
parser.setHiveConf(ctx.getConf());
}
parser.setTreeAdaptor(adaptor);
HiveParser.statement_return r = null;
try {
r = parser.statement();
} catch (RecognitionException e) {
e.printStackTrace();
throw new ParseException(parser.errors);
}
if (lexer.getErrors().size() == 0 && parser.errors.size() == 0) {
LOG.debug("Parse Completed");
} else if (lexer.getErrors().size() != 0) {
throw new ParseException(lexer.getErrors());
} else {
throw new ParseException(parser.errors);
}
ASTNode tree = (ASTNode) r.getTree();//生成AST返回
tree.setUnknownTokenBoundaries();
return tree;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
Antlr对Hive SQL解析的代码如上述代码逻辑,HiveLexerX,HiveParser分别是Antlr对语法文件HiveLexer.g编译后自动生成的词法解析和语法解析类,在这两个类中进行复杂的解析。
这是解析的第一步,生辰了一个ATS。
看一下之后的词法分析,
词法分析器Lexer - HiveLexerX
输入:一堆字符,这里是HiveSQL
输出:一串Toker,这里是TokenRewriteStream
也称词法分析器 Lexical Analyzer(LA)或者Scanner
建议翻阅《编译原理》
上文提到HiveLexer.g,即文法分析依靠一个文件HiveLexer.g:
文件定义了一些hive的关键字,form、where,数字的定义格式【0–9】,分隔符,比较符之类的etc。每一个关键字都会变成一个token。
例如:规定hive中以数字或者下划线开头:
CharSetName
:
'_' (Letter | Digit | '_' | '-' | '.' | ':' )+
;- 1
- 2
- 3
- 4
如果你对这个规则不满意可以修改它。
语法解析 HiveParser:
如何获得ASTNode
HiveParser.statement().getTree()
https://www.codatlas.com/github.com/apache/hive/master/ql/src/java/org/apache/hadoop/hive/ql/parse/ParseDriver.java?line=197
HiveParser是Antlr根据HiveParser.g生成的文件
进入HiveParser .java看到第一行:
// $ANTLR 3.5.2 org/apache/hadoop/hive/ql/parse/HiveParser.g 2017-05-03 10:08:46- 1
此Java文件在2017-05-03被生成的。但是HiveParser.g我们进去看一下:
用select字句举例:
selectStatement
:
a=atomSelectStatement
set=setOpSelectStatement[$atomSelectStatement.tree]?
o=orderByClause?
c=clusterByClause?
d=distributeByClause?
sort=sortByClause?
l=limitClause?
{
if(set == null){
$a.tree.getFirstChildWithType(TOK_INSERT).addChild($o.tree);
$a.tree.getFirstChildWithType(TOK_INSERT).addChild($c.tree);
$a.tree.getFirstChildWithType(TOK_INSERT).addChild($d.tree);
$a.tree.getFirstChildWithType(TOK_INSERT).addChild($sort.tree);
$a.tree.getFirstChildWithType(TOK_INSERT).addChild($l.tree);
}
}
-> {set == null}?
{$a.tree}
-> {o==null && c==null && d==null && sort==null && l==null}?
{$set.tree}
-> ^(TOK_QUERY
^(TOK_FROM
^(TOK_SUBQUERY
{$set.tree}
{adaptor.create(Identifier, generateUnionAlias())}
)
)
^(TOK_INSERT
^(TOK_DESTINATION ^(TOK_DIR TOK_TMP_FILE))
^(TOK_SELECT ^(TOK_SELEXPR TOK_SETCOLREF))
$o? $c? $d? $sort? $l?
)
)
;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
用图形表示: 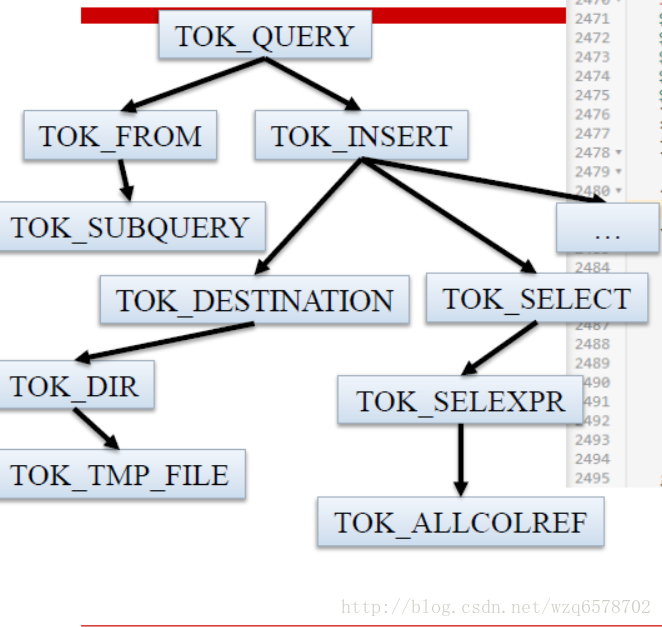
增加一种语法这时候,你知道了……
如果我们想为Hive增加一种新的语法……
第一步……
就是修改HiveParser.g
如果要引入关键字,还需要修改HiveLexer.g
第二部分:语义解析初步 - SemanticAnalyzer 
一个SQL大致分为以下7部分,按顺序执行
(5)SELECT (6)DISTINCT
(1)FROM
(2)WHERE
(3)GROUP BY
(4)HAVING
(7) ORDER BY
Operators对应SQL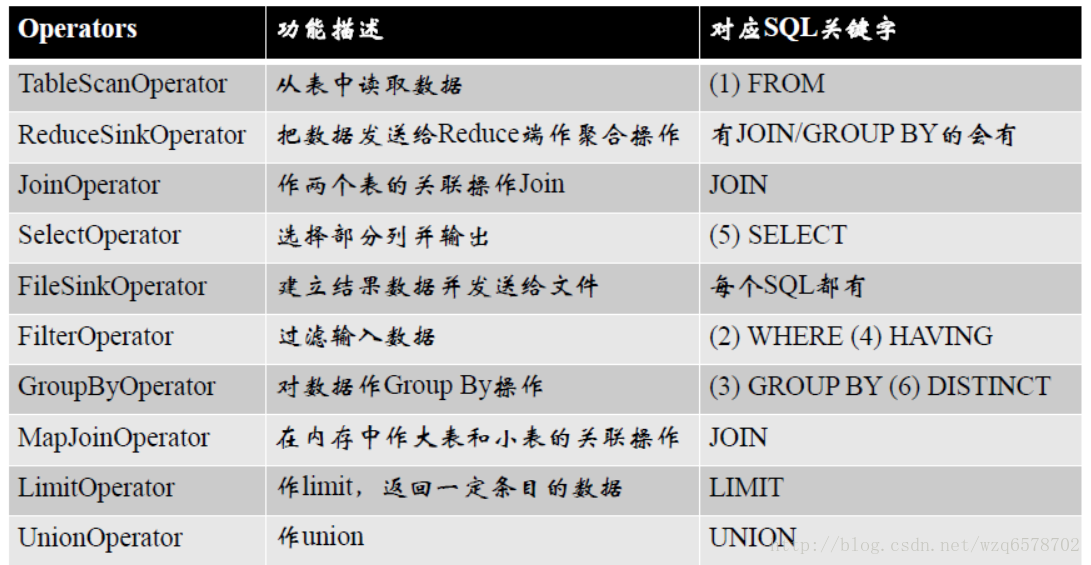
每个步骤对应一个逻辑运算符(Operator)
每个Operator输出一个虚表(VirtualTable) 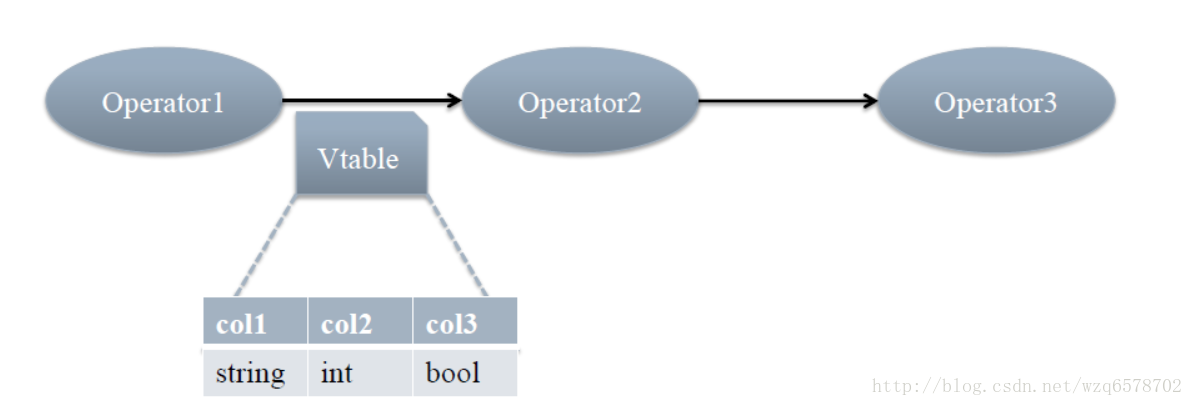
语义解析器:
输入AST树(见3.3.2)
输出Operator图
回到Compiler代码,看入口在哪里
https://www.codatlas.com/github.com/apache/hive/master/ql/src/java/org/apache/hadoop/hive/ql/Driver.java?line=503
SemanticAnalyzer.analyze()
SemanticAnalyzer.analyzeInternal()
在回到Driver.java:
...........ignore
BaseSemanticAnalyzer sem = SemanticAnalyzerFactory.get(queryState, tree);
............ignore
// Do semantic analysis and plan generation
if (saHooks != null && !saHooks.isEmpty()) {
HiveSemanticAnalyzerHookContext hookCtx = new HiveSemanticAnalyzerHookContextImpl();
hookCtx.setConf(conf);
hookCtx.setUserName(userName);
hookCtx.setIpAddress(SessionState.get().getUserIpAddress());
hookCtx.setCommand(command);
for (HiveSemanticAnalyzerHook hook : saHooks) {
tree = hook.preAnalyze(hookCtx, tree);
}
sem.analyze(tree, ctx);
hookCtx.update(sem);
for (HiveSemanticAnalyzerHook hook : saHooks) {
hook.postAnalyze(hookCtx, sem.getAllRootTasks());
}
} else {
sem.analyze(tree, ctx);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
进入sem.analyze(tree,ctx)【https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/parse/BaseSemanticAnalyzer.java?line=255】:
public void analyze(ASTNode ast, Context ctx) throws SemanticException {
initCtx(ctx);//初始化上下文
init(true);
analyzeInternal(ast);//此方法在BaseSemanticAnalyzer中为一个抽象方法【 public abstract void analyzeInternal(ASTNode ast) throws SemanticException;】
}- 1
- 2
- 3
- 4
- 5
analyzeInternal方法有很多实现:

用于查询的 SemanticAnalyzer
继承自BaseSemanticAnalyzer的语义分析器有很多种
其中最重要的是用于查询的SemanticAnalyzer类(很奇怪这种命名,不应该是叫QuerySemanticAnalyzer么?不应该把抽象类的Base一词去掉么?忍吧)
他们有很多是replaction的,有些是ddl的,有些是做查询的,我们在此处关注做查询的。
一万多行语义分析
看到了么?截止2016年11月20日
SemanticAnalyzer有13623行
Hive优化的秘密全在于此
不要急,慢慢来
注意:输入的ASTTree后续的QB的生成,逻辑执行计划、逻辑执行计划的优化、物理执行计划的切分、物理执行计划的优化、以及mr任务的生成全部都在这1万多行的代码里边的逻辑中。
生成QB - genResolvedParseTree()
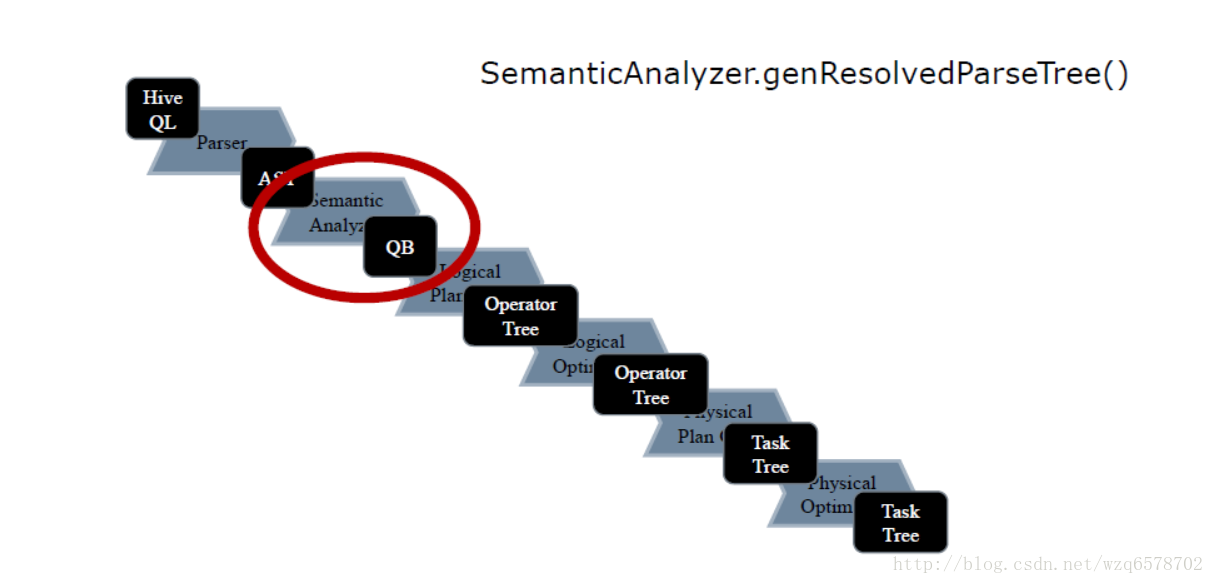
关注SemanticAnalyzer 的 analyzeInterna方法:
public void analyzeInternal(ASTNode ast) throws SemanticException {
analyzeInternal(ast, new PlannerContext());
}- 1
- 2
- 3
进入analyzeInternal(ast, new PlannerContext());
void analyzeInternal(ASTNode ast, PlannerContext plannerCtx) throws SemanticException {
// 1. Generate Resolved Parse tree from syntax tree
LOG.info("Starting Semantic Analysis");
//change the location of position alias process here
processPositionAlias(ast);
if (!genResolvedParseTree(ast, plannerCtx)) {
return;
}
。。。。。。。。。。。略。。。。。。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
进入genResolvedParseTree(ast, plannerCtx)
boolean genResolvedParseTree(ASTNode ast, PlannerContext plannerCtx) throws SemanticException {
。。。。。。。略。。。。。。。。
// 4. continue analyzing from the child ASTNode.
Phase1Ctx ctx_1 = initPhase1Ctx();
preProcessForInsert(child, qb);
if (!doPhase1(child, qb, ctx_1, plannerCtx)) {
// if phase1Result false return
return false;
}
。。。。。。。。。。。。略。。。。。。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
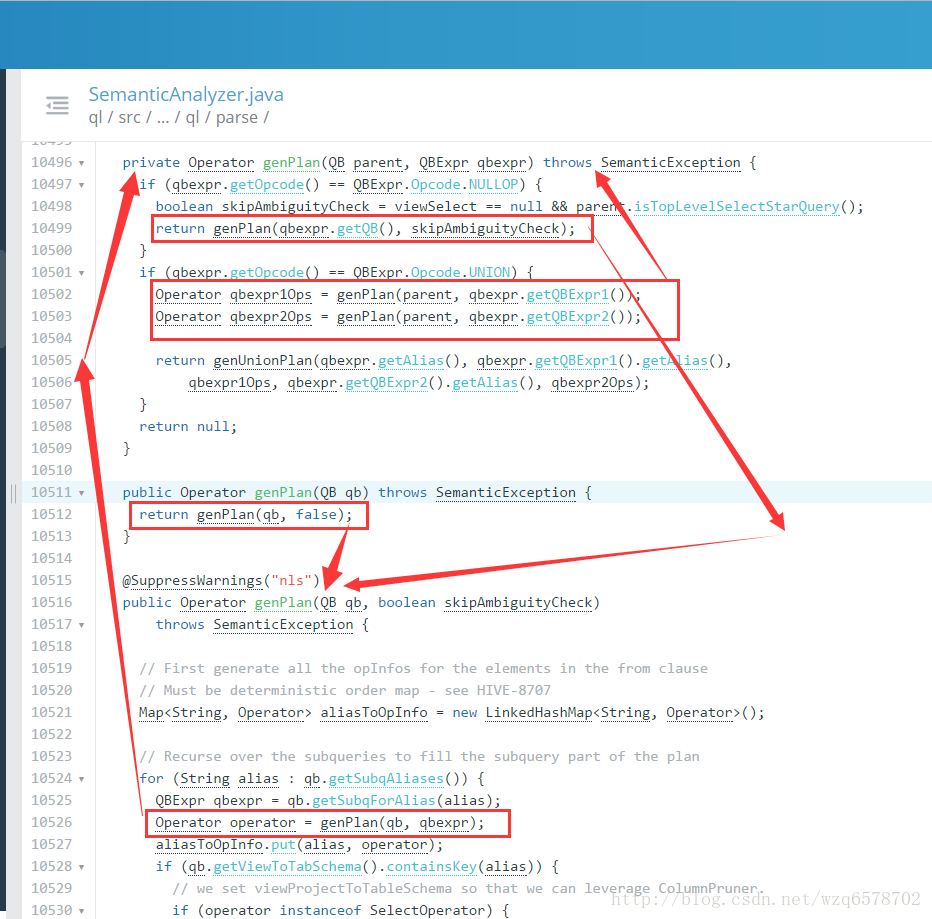
如果doPhase1执行成功那么就会得到一个QB,进入doPhase1方法:
/**
* Phase 1: (including, but not limited to):
* 1. Gets all the aliases for all the tables / subqueries and makes the
* appropriate mapping in aliasToTabs, aliasToSubq 2. Gets the location of the
* destination and names the clause "inclause" + i 3. Creates a map from a
* string representation of an aggregation tree to the actual aggregation AST
* 4. Creates a mapping from the clause name to the select expression AST in
* destToSelExpr 5. Creates a mapping from a table alias to the lateral view
* AST's in aliasToLateralViews
*
* @param ast
* @param qb
* @param ctx_1
* @throws SemanticException
*/
@SuppressWarnings({"fallthrough", "nls"})
public boolean doPhase1(ASTNode ast, QB qb, Phase1Ctx ctx_1, PlannerContext plannerCtx)
throws SemanticException {
。。。。。。。。。。。。。。。。略。。。。。。。。
case HiveParser.TOK_SELECT://select类型的token
qb.countSel();//对qb做标记
qbp.setSelExprForClause(ctx_1.dest, ast);
。。。。。。。。。。。。。。。。。略。。。。。。
case HiveParser.TOK_WHERE://where类型token
//对where的孩子进行处理,为什么是ast.getChild(0)?这个是和之前的HiveParser.g结构相辅相成的。
qbp.setWhrExprForClause(ctx_1.dest, ast);
if (!SubQueryUtils.findSubQueries((ASTNode) ast.getChild(0)).isEmpty())
queryProperties.setFilterWithSubQuery(true);
break;
。。。。。。。。。。。。。。。。略。。。。。。。。
case HiveParser.TOK_GROUPBY:
case HiveParser.TOK_ROLLUP_GROUPBY:
case HiveParser.TOK_CUBE_GROUPBY:
case HiveParser.TOK_GROUPING_SETS:
。。。。。。。。。。。。略。。。。。。。。
if (!skipRecursion) {
// Iterate over the rest of the children
int child_count = ast.getChildCount();
for (int child_pos = 0; child_pos < child_count && phase1Result; ++child_pos) {
// Recurse
phase1Result = phase1Result && doPhase1(
(ASTNode)ast.getChild(child_pos), qb, ctx_1, plannerCtx);
}
}
。。。。。。。。。。。。。。。略。。。。。。。。。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
参数qb是一个空的QB,在不同case类型下对齐进行填满。
doPhase1对ASTTree中的每个元素的TOK类型进行case,针对于不同的case对节点数据进行填充。
for遍历整棵ASTTree,中间对每个元素递归调用doPhase1,这种方式是一种深度优先搜索的算法。
经过一轮深度优先遍历,不带元数据的QB树就生成了。
doPhase1执行完毕之后得到QB,QB里边的只是一些关键字还有一些表的名字,但是和hdfs的文件路径对应不起来,所以需要metaData映射关系,之后在SemanticAnalyzer中调用了 getMetaData :
public void getMetaData(QB qb) throws SemanticException {
getMetaData(qb, false);
}
public void getMetaData(QB qb, boolean enableMaterialization) throws SemanticException {
try {
if (enableMaterialization) {
getMaterializationMetadata(qb);
}
getMetaData(qb, null);
} catch (HiveException e) {
// Has to use full name to make sure it does not conflict with
// org.apache.commons.lang.StringUtils
LOG.error(org.apache.hadoop.util.StringUtils.stringifyException(e));
if (e instanceof SemanticException) {
throw (SemanticException)e;
}
throw new SemanticException(e.getMessage(), e);
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
getMetaData又会递归的去取元数据(从mysql中),经过doPhase1和getMetaData得到一个完整的QB,接下来就是逻辑执行技术的生成。
Logical Plan Generator - SemanticAnalyzer.genPlan() 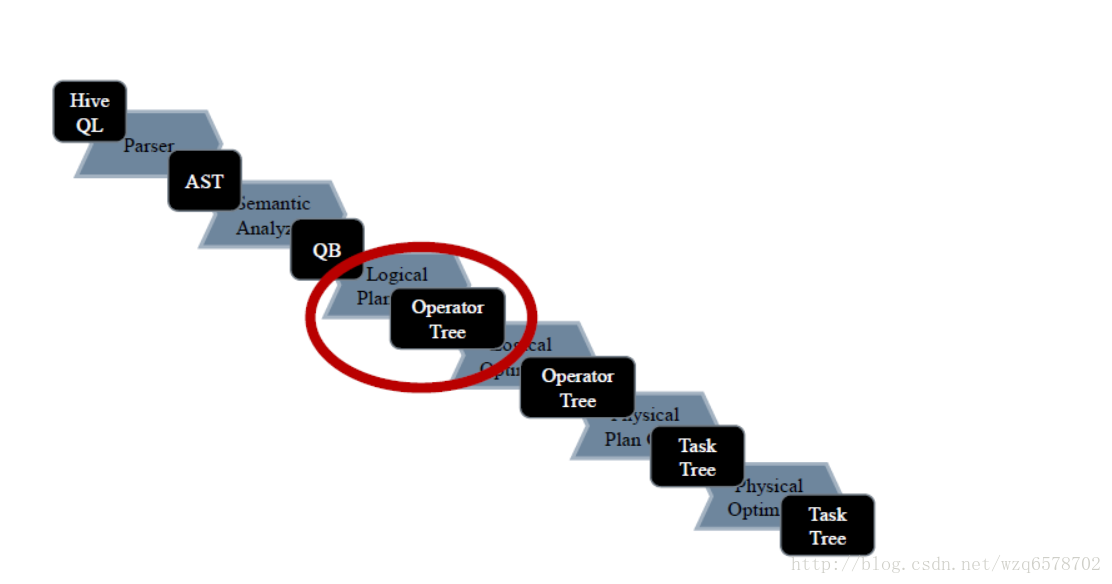
genPlan()实现QB->Operator
genPlan() 也是深度优先的递归
Operator sinkOp = genOPTree(ast, plannerCtx);【https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/parse/SemanticAnalyzer.java?line=11235】生成op:
Operator genOPTree(ASTNode ast, PlannerContext plannerCtx) throws SemanticException {
// fetch all the hints in qb
List<ASTNode> hintsList = new ArrayList<>();
getHintsFromQB(qb, hintsList);
getQB().getParseInfo().setHintList(hintsList);
return genPlan(qb);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
大体的递归过程:
表达式分析
•类型推倒 100 INT 100.1 DOUBLE ‘Hello’ STRING TRUE BOOL
•隐式类型转换 对于fun(DOUBLE, DOUBLE),有输入A—INT, B—DOUBLE fun(double(A), B) 如1+2.5 double(1) + 2.5
NULL值类型转换
•表达式求值 f(g(A), B) A, g(), B, f() 逆波兰表达式
•BOOL表达式分析 合取范式 (C1 and C2) or C3 (C1 or C3) and (C2 or C3) SELECT * FROM T,P WHERE (T.A>10 AND P.B<100) OR T.B>10 SELECT * FROM T,P WHERE (T.A>10 OR T.B>10) AND (P.B<100 OR T.B>10) 当条件变换为合取范式时,可以对AND连接的每一项进行下推优化
UDFToLong
public LongWritable evaluate(Text i) {
//有三种情况为null
//第一Text是null
if (i == null) {
return null;
} else {
//猜测不是数字,返回null
if (!LazyUtils.isNumberMaybe(i.getBytes(), 0, i.getLength())) {
return null;
}
try {
longWritable.set(LazyLong.parseLong(i.getBytes(), 0, i.getLength(), 10));//使用LazyLong装换,没有用jdk的API
return longWritable;
} catch (NumberFormatException e) {
// MySQL returns 0 if the string is not a well-formed numeric value.
// return LongWritable.valueOf(0);
// But we decided to return NULL instead, which is more conservative.
//出错返回null
return null;
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
public IntWritable evaluate(Text i) {
//Text 为null,返回null
if (i == null) {
return null;
} else {
//猜测失败,返回null
if (!LazyUtils.isNumberMaybe(i.getBytes(), 0, i.getLength())) {
return null;
}
try {
intWritable.set(LazyInteger.parseInt(i.getBytes(), 0, i.getLength(), 10));//使用LazyInteger,未使用jdk的API
return intWritable;
} catch (NumberFormatException e) {
// MySQL returns 0 if the string is not a well-formed numeric value.
// return IntWritable.valueOf(0);
// But we decided to return NULL instead, which is more conservative.
//报错返回null
return null;
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
https://blog.csdn.net/wzq6578702/article/details/71375026
hive原理与源码分析-序列化器与反序列化器(三)
2017年05月07日 22:28:49 魔鬼_ 阅读数 2683
版权声明:本文为博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/wzq6578702/article/details/71375026
使用IDE调试一条简单的SQL
画出AST
画出Operator Tree
已有表结构:
- 1
- 2
- 3
- 4
执行计划:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
Stage-4:是小表序列化
Stage-3:mr任务
Stage-0:对mr输出文件的输出
逻辑执行计划Stage-3
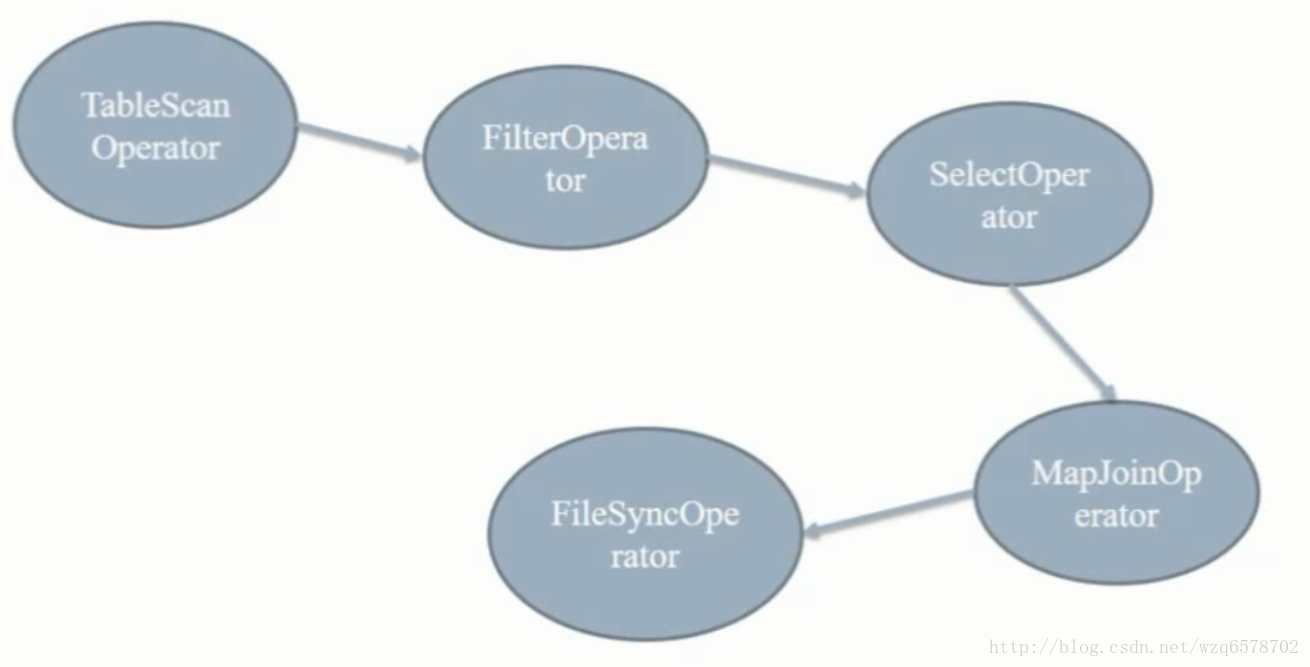
TableScanOperator: from src a /from src b 【a表加载进入内存,b在磁盘上边】
FilterOperator: where a.key<100
SelectOperator : select *
MapJoinOperator : on a.key = b.key
FileSyncOperator:输出
整个流程:从b表加载一条数据 FilterOperator一下,SelectOperator 选择出记录,用MapJoinOperator 和内存中的ajoin一下,然后输出
SerDe简介
SerDe是Serializer和Deserializer的缩写
序列化器与反序列化器
Hive使用SerDe接口去完成IO操作
接口三个主要功能:
序列化(Serialization),从Hive写FS
反序列化(Deserialization),从FS读入Hive
解释读写字段,加起文件到字段结构的桥梁
Hive核心三大组件
Hive有三大核心组件:
Query Processor:查询处理工具,源码ql包
SerDe:序列化与反序列化器,源码serde包
MetaStore:元数据存储及服务,源码metastore包
请注意:
HiveServer2、MR和Tez引擎并不是Hive的三大核心组件,只是周边,后续我们会做分析
关于MR和Tez的性能比较点这:http://www.cnblogs.com/linn/p/5325147.html
SerDe所处的位置
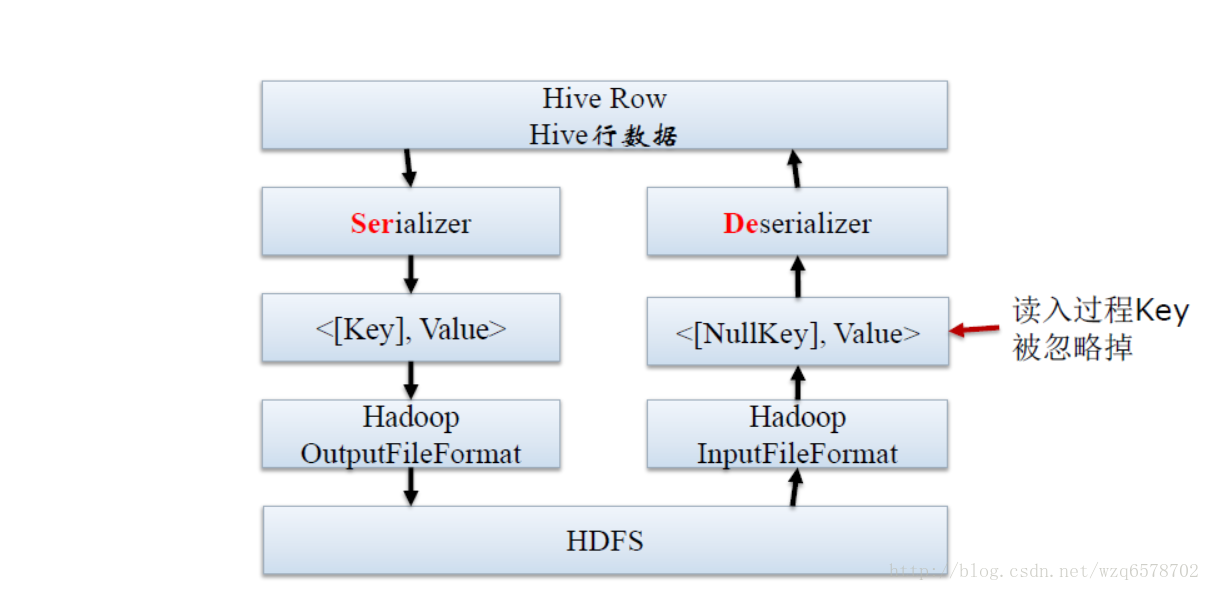
序列化和反序列化的目的
Serde是用于序列化和反序列化。
序列化的目的是Hive格式输出成为特定格式,包括:
分隔符(tab、逗号、CTRL-A)
Thrift 协议
反序列化的目的是HDFS格式读入Hive内存中,包括:
Java Integer/String/ArrayList/HashMap
Hadoop Writable 类
用户自定义类
内置SerDe与外置SerDe
内置SerDe
LazySimpleSerde
ColumnarSerde
AvroSerde
ORC
RegexSerde
Thrift
Parquet
CSV
JSONSerde
自定义Serde,读写自定义格式的数据
例子:使用RegexSerDe
分析http请求日志。
CREATE TABLE apache_log(
host STRING, identity STRING, user STRING,
time STRING, request STRING, status STRING,
size STRING, referer STRING, agent STRING)
ROW FORMAT SERDE ‘org.apache.hadoop.hive.contrib.serde2.RegexSerDe’
WITH SERDEPROPERTIES
( “input.regex” = “([^ ]) ([^ ]) ([^ ]) (-|^]) ([^ ”]|”[^”]”) (-|[0-9]) (-|[0-9])(?: ([^ ”]|”[^”]”) ([^ ”]|”[^”]”))?”,
“output.format.string” = “%1ss %3ss %5ss %7ss %9$s”
) STORED AS TEXTFILE;
( “input.regex” = “([^ ]) ([^ ]) ([^ ]) (-|^]) ([^ ”]|”[^”]”) (-|[0-9]) (-|[0-9])(?: ([^ ”]|”[^”]”) ([^ ”]|”[^”]”))?”
这个正则表达式是Serializer的过程,
( “input.regex” = “([^ ]) ([^ ]) ([^ ]) (-|^]) ([^ ”]|”[^”]”) (-|[0-9]) (-|[0-9])(?: ([^ ”]|”[^”]”) ([^ ”]|”[^”]”))?”
这条正则表达式是DeSerializer的过程。
SerDe的源码分析
相对于SemanticAnalyzer,Serde的编写较为规范,也较为好懂
https://www.codatlas.com/github.com/apache/hive/master/serde/src/java/org/apache/hadoop/hive/serde2/
AbstractSerde
https://www.codatlas.com/github.com/apache/hive/master/serde/src/java/org/apache/hadoop/hive/serde2/AbstractSerDe.java
AbstractSerde
serialize() 接口:Object -> Writable
deserialize()接口:Writable -> Object
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
如果我们想要改变存储在文件上的分隔符在哪个地方改动呢?打开serdeConstants这个类:
- 1
- 2
- 3
ObjectInspector
ObjectInspector作用相当大,它解耦了数据使用和数据格式
ObjectInspector接口使得Hive可以不拘泥于一种特定数据格式
在输入端和输出端切换不同的输入/输出格式
在不同的Operator上使用不同的数据格式
https://insight.io/github.com/apache/hive/blob/master/serde/src/java/org/apache/hadoop/hive/serde2/objectinspector/ObjectInspector.java
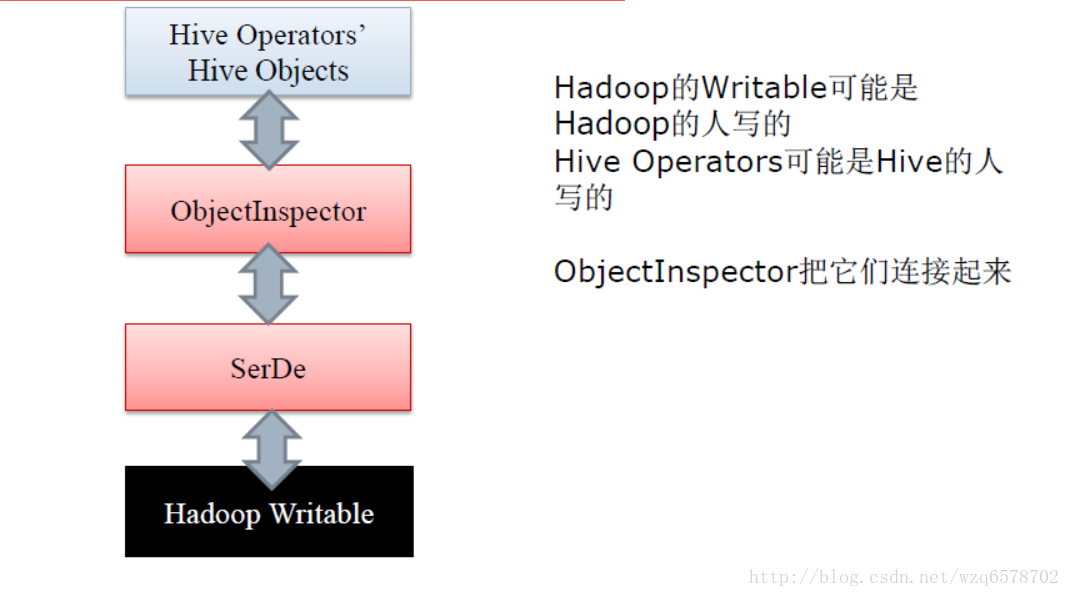
我们在上文的 explain select * from src a join src b on a.key=b.key where a.key<100;执行计划的时候,在stage-3有一个 Map Operator,这个操作是一个读操作,即反序列化Deserializer。
Deserializer是如何工作的
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/exec/MapOperator.java?line=125
value : hadoop中一条数据;context:hadoop的配置
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
Serializer是如何工作的
源码:https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/exec/ReduceSinkOperator.java?line=112
- 1
- 2
- 3
- 4
- 5
- 6
- 7
我们在写数据的时候serialize(Object obj, ObjectInspector objInspector) obj是个什么对象我们是通过objInspector来描述的。
FileSinkOperator:
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/exec/FileSinkOperator.java?line=92
- 1
- 2
- 3
FileSinkDesc:
- 1
- 2
ReduceSinkDesc原理也是如此:
- 1
- 2
在FileSinkDesc的注解@Explain中有个displayName=File Output Operator和我们之前的执行计划中的输出:
由此我们在根据执行bebug的时候就是根据类似于这种注解去判断的。
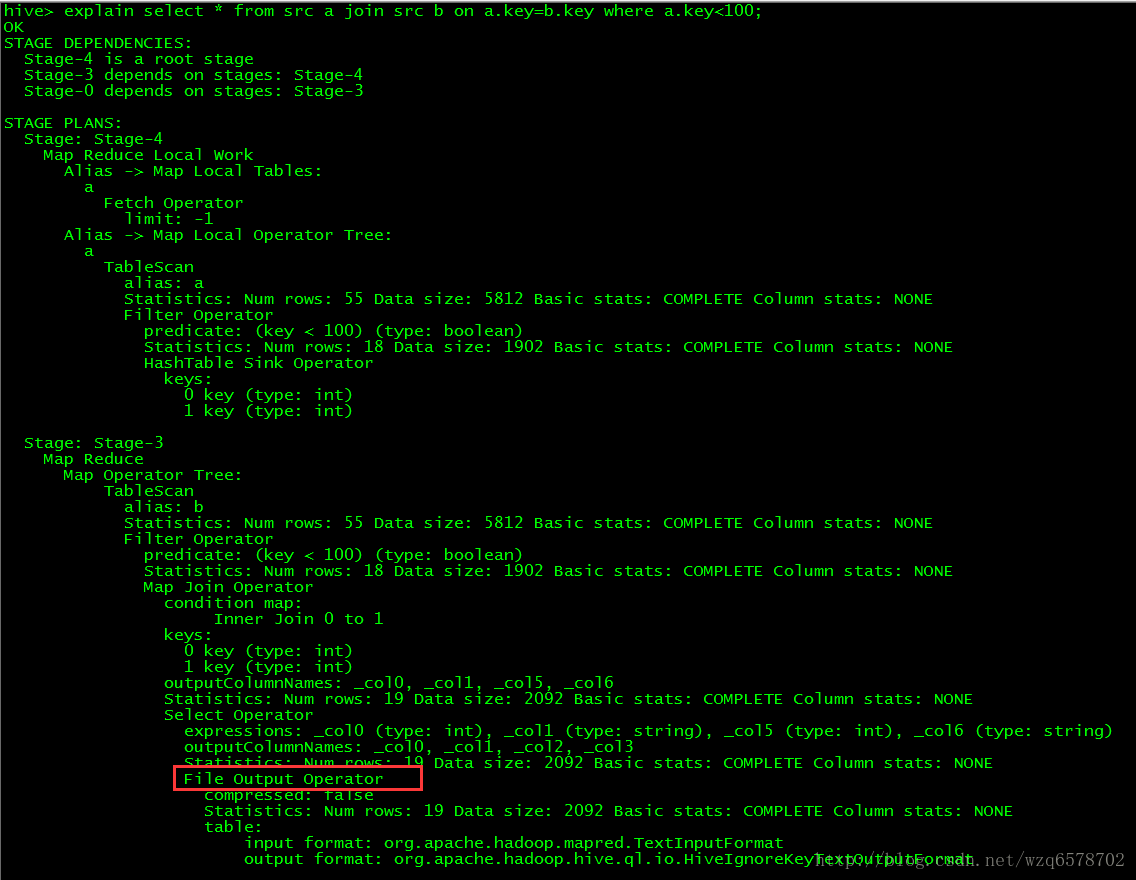
Hive的本质是一条SQL生成的一系列Operators,并执行它们 每个Operators的原理和适应条件,决定查询的性能 这里的代码是ReduceSinkOperator:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
valueSerializer.serialize(cachedValues, valueObjectInspector);将row序列化最终为为BytesWritable【hadoop的数据类型】
ReduceSinkOperator的Sink是下沉的意思,此处是map的输出结果输入到reduce中,row是map的结果,输出是BytesWritable,即用BytesWritable作为reduce的输入。
由此可以看出,hive的主要功能是对一条sql解析生成若干operator,并且执行他们,和关系型数据库还有很大的不同的,关系型数据库还有存储 功能。
创建自定义Serde
参考:https://cwiki.apache.org/confluence/display/Hive/DeveloperGuide
何时添加自定义SerDe
用户有更有效的序列化磁盘数据的方法,添加Ser(不常出现)
用户的数据有特殊的序列化格式,当前的 Hive 不支持,而用户又不想在将数据加载至 Hive 前转换数据格式,添加De(经常出现)
Hive常用可编程用户接口文件格式FileFormats
序列化与反序列化器Serde
Map-Reduce脚本
UDxF(UDF, UDAF, UDTF)
创建自定义SerDe
大多数情况,只需要De而不是SerDe
只需要读取(反序列化)特殊格式的数据,而不是写(序列化)数据
读完之后用Hive内置的数据结构处理会更高效
创建自定义SerDe的过程
1.准备数据
2.使用IDE,继承AbstractSerde接口
3.实现serialize()和deserialize()方法
4.将创建的类打包为serde.jar
5.Add serde.jar 命令添加分布式缓存
6.建表,指定刚才编写的类
7.读写数据
hive原理与源码分析-算子Operators及查询优化器Optimizers(四)
Operator接口
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/exec/Operator.java?line=66
这个接口最重要的一个方法:
/**
* Process the row.
* @param row The object representing the row.
* @param tag
* The tag of the row usually means which parent this row comes from.
* Rows with the same tag should have exactly the same rowInspector
* all the time.
*/
public abstract void process(Object row, int tag) throws HiveException;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
row是一行数据,tag代表是那张表。用一个整数代表是那张表。
hadoop在执行任务的时候会在每个节点创建一个进程。
每个进程一个实例
每个实例开始执行一次initialize()方法
每个实例执行多次process()方法,每行执行一次,这个进程有几行就执行几次
每个实例最后执行一次close()方法
对于Operator比较正要的有group by Operator和join Operator
前文章节SemanticAnalyzer生成一个QB,之后递归genplan(),然后是genBodyPlan(),genBodyPlan会对group by进行处理: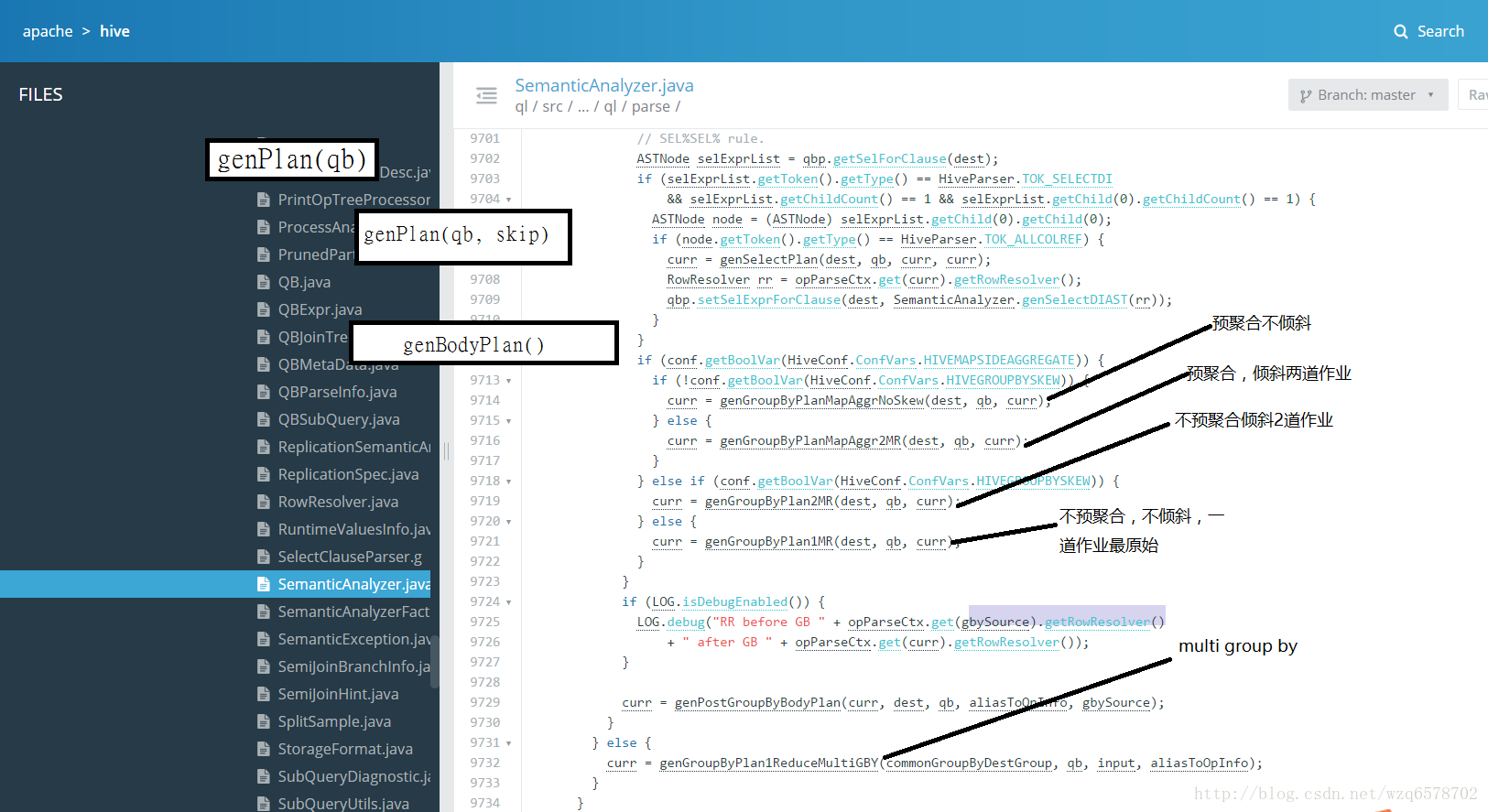
HiveConf.ConfVars.HIVEGROUPBYSKEW:将一个group by拆成2个group by减少数据量
Hive Group By
HiveConf.ConfVars.HIVEMAPSIDEAGGREGATE:hive.map.aggr,使用Map端预聚合
HiveConf.ConfVars.HIVEGROUPBYSKEW:hive.groupby.skewindata,是否优化倾斜的查询为两道作业
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/parse/SemanticAnalyzer.java?line=9713
一共四中情况
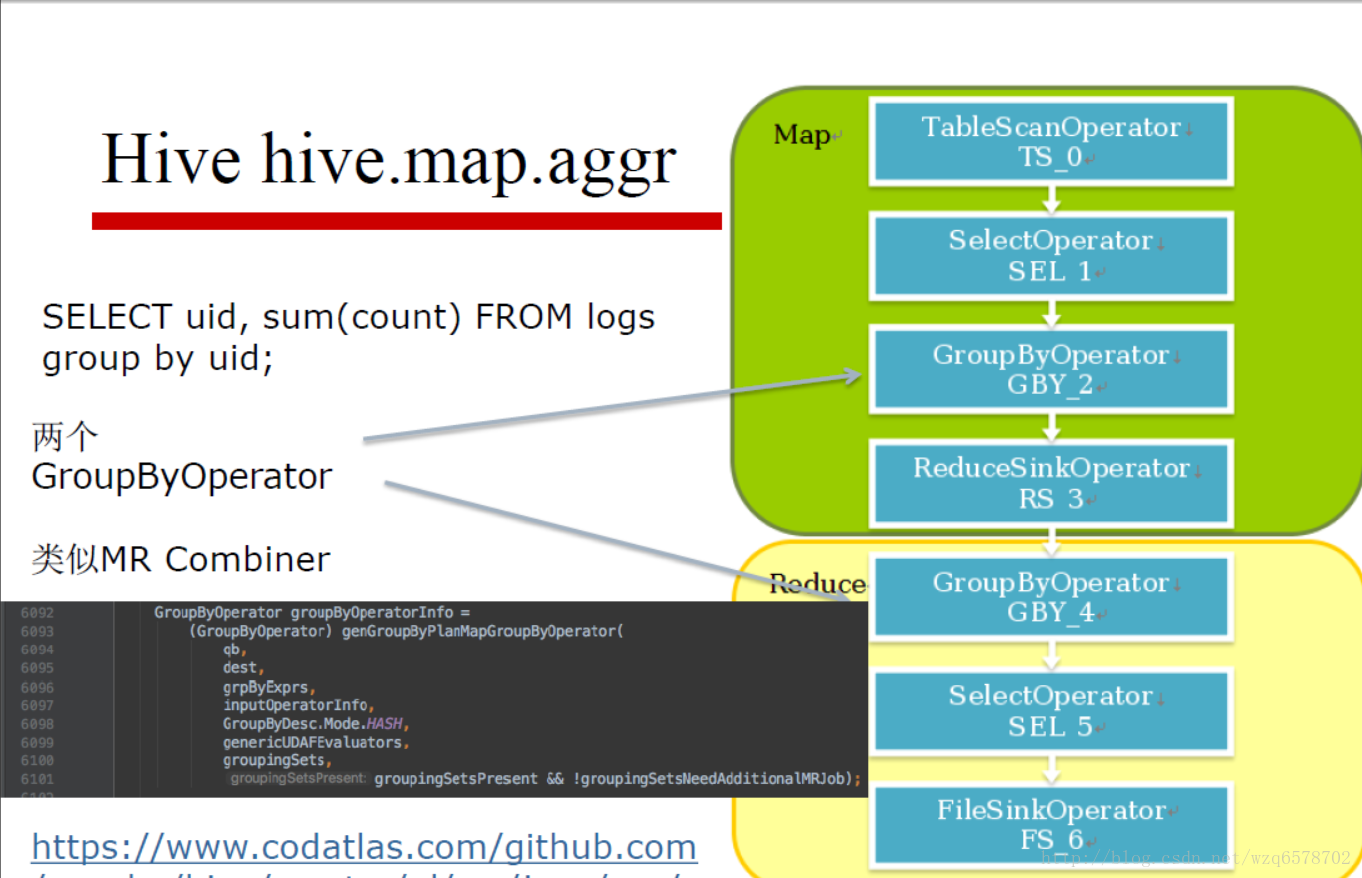
Hive GroupBy hive.groupby.skewindata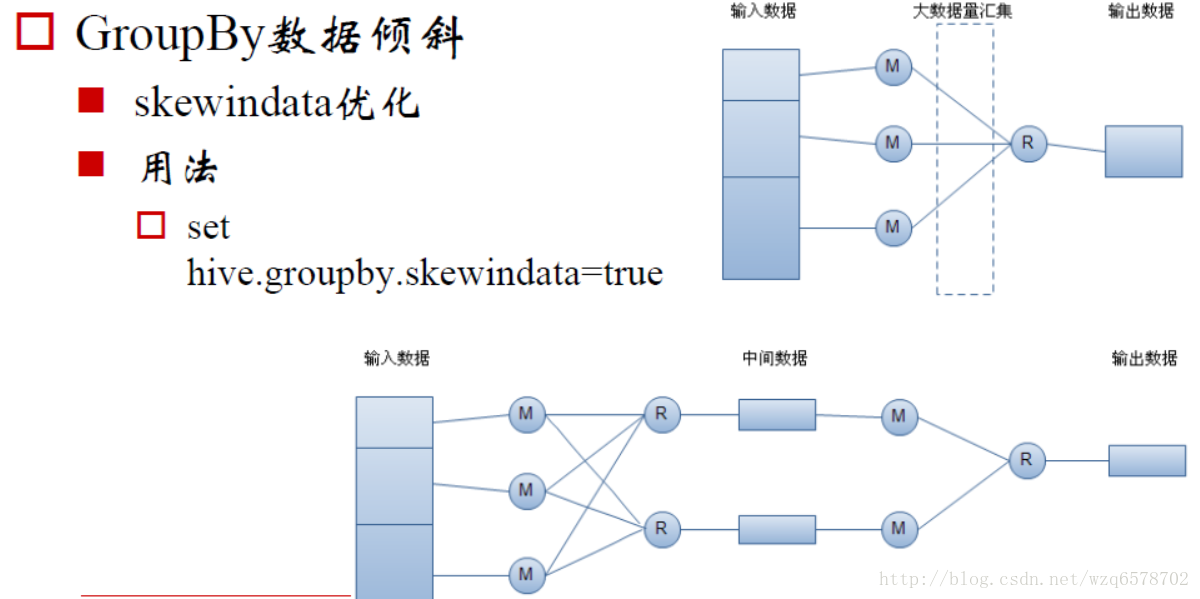
hive.groupby.skewindata源码
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/parse/SemanticAnalyzer.java?line=6114
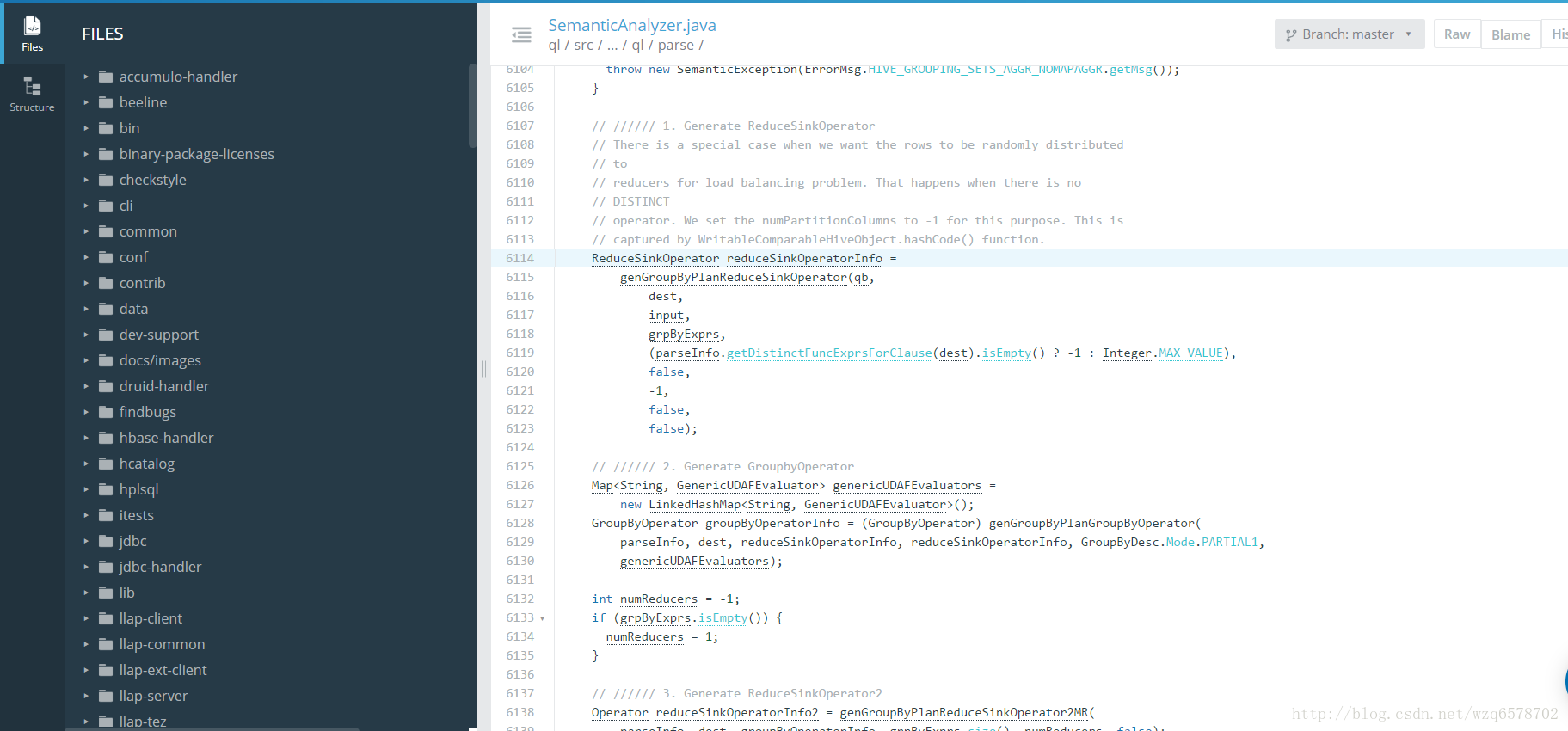
这样我们就能完美了吗,我们的group by就不会倾斜了吗?大部分的group by是不会倾斜的,但是有一种是特殊的。
代数型聚合与非代数聚合
代数型聚合:可以通过部分结果计算出最终结果的聚合方法,如count、sum
非代数型聚合:无法通过部分结果计算出最终结果的聚合方法,如percentile,median
Group By优化只适用于代数型聚合,代数型UDAF,思考为什么?
group by聚合:
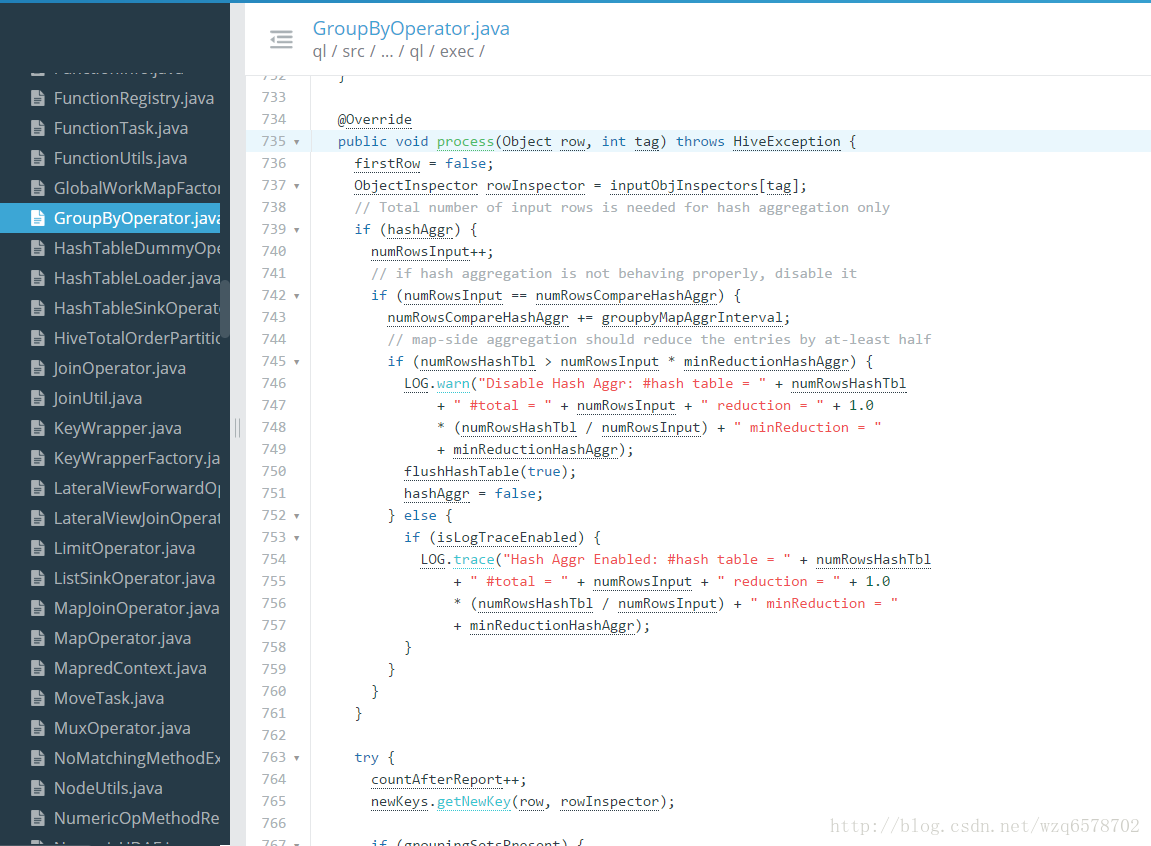
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/exec/GroupByOperator.java?line=735
group by的聚合逻辑就是这个process方法, process方法会调用 processHashAggr和 processAggr方法,即hash聚合和普通 聚合的方法。
Join关联
Join是Hive是最难的部分,也是最需要优化的部分
常用Join方法
普通(Reduce端)Join, Common (Reduce-Side) Join
广播(Map端)Join,Broadcast(Map-Side)Join
Bucket Map Join
Sort Merge Bucket Map Join
倾斜Join,Skew Join
先从最简单的Common Join开始,此join是所有join的基础。
Common Join
也叫做Reduce端Join
背景知识:Hive只支持等值Join,不支持非等值Join
扫描N张表
Join Key相同的放在一起(相同Reduce) -> 结果
流程:
Mapper: 扫描,并处理N张表,生成发给Reduce的<Key, Value> Key = {JoinKey, TableAlias}, Value = {row}
Shuffle阶段
JoinKey相同的Reduce放到相同的
TableAlias 是排序的标识,就是表的编号,相同表的数据在一起是排序的。
Reducer: 处理Join Key并输出结果
最坏的情况
所有的数据都被发送到相同的结点,同一个Reduce
JoinOperator:
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/exec/JoinOperator.java?line=78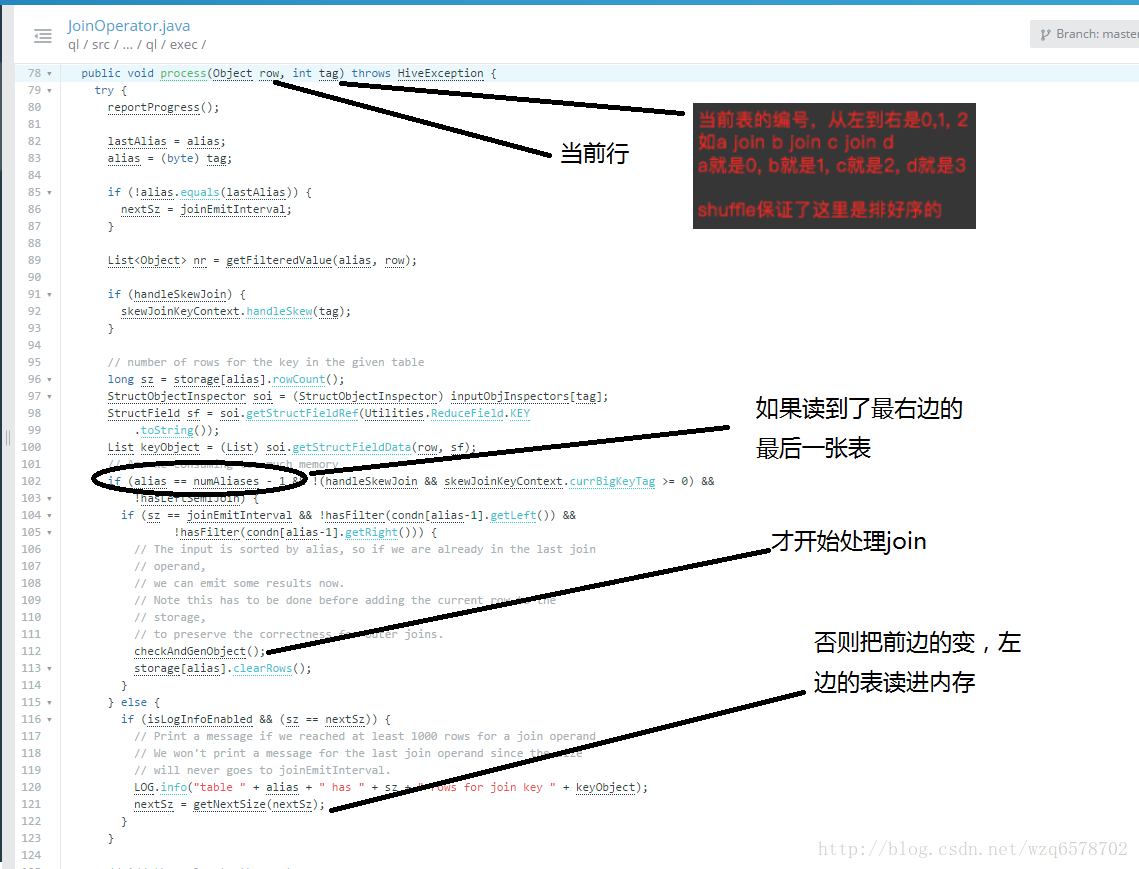
commonJoinOperation下边还有一些特化的Operator:
先说最简单的commonJoinOperator
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/exec/CommonJoinOperator.java?line=569
// creates objects in recursive manner
private void genObject(int aliasNum, boolean allLeftFirst, boolean allLeftNull)
throws HiveException {
JoinCondDesc joinCond = condn[aliasNum - 1];
int type = joinCond.getType();
int left = joinCond.getLeft();
int right = joinCond.getRight();
if (needsPostEvaluation && aliasNum == numAliases - 2) {
int nextType = condn[aliasNum].getType();
if (nextType == JoinDesc.RIGHT_OUTER_JOIN || nextType == JoinDesc.FULL_OUTER_JOIN) {
// Initialize container to use for storing tuples before emitting them
rowContainerPostFilteredOuterJoin = new HashMap<>();
}
}
boolean[] skip = skipVectors[aliasNum];
boolean[] prevSkip = skipVectors[aliasNum - 1];
// search for match in the rhs table
//内存里边的小表
AbstractRowContainer<List<Object>> aliasRes = storage[order[aliasNum]];
。。。。。。略。。。。
根据判断,执行inner join或者left join
if (type == JoinDesc.INNER_JOIN) {
innerJoin(skip, left, right);
} else if (type == JoinDesc.LEFT_SEMI_JOIN) {
if (innerJoin(skip, left, right)) {
// if left-semi-join found a match, skipping the rest of the rows in the
// rhs table of the semijoin
done = true;
}
} else if (type == JoinDesc.LEFT_OUTER_JOIN ||
(type == JoinDesc.FULL_OUTER_JOIN && rightNull)) {
int result = leftOuterJoin(skip, left, right);
if (result < 0) {
continue;
}
done = result > 0;
} else if (type == JoinDesc.RIGHT_OUTER_JOIN ||
(type == JoinDesc.FULL_OUTER_JOIN && allLeftNull)) {
if (allLeftFirst && !rightOuterJoin(skip, left, right) ||
!allLeftFirst && !innerJoin(skip, left, right)) {
continue;
}
} else if (type == JoinDesc.FULL_OUTER_JOIN) {
if (tryLOForFO && leftOuterJoin(skip, left, right) > 0) {
loopAgain = allLeftFirst;
done = !loopAgain;
tryLOForFO = false;
} else if (allLeftFirst && !rightOuterJoin(skip, left, right) ||
!allLeftFirst && !innerJoin(skip, left, right)) {
continue;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
每来一条数据就会读取一下小表的内容,如果小表比较小,过程会比较快
MapJoin
也叫广播Join,Broadcast Join
从 (n-1)张小表创建Hashtable,Hashtable的键是 Joinkey, 把这张Hashtable广播到每一个结点的map上,只处理大表.
每一个大表的mapper在小表的hashtable中查找join key -> Join Result
Ex: Join by “CityId”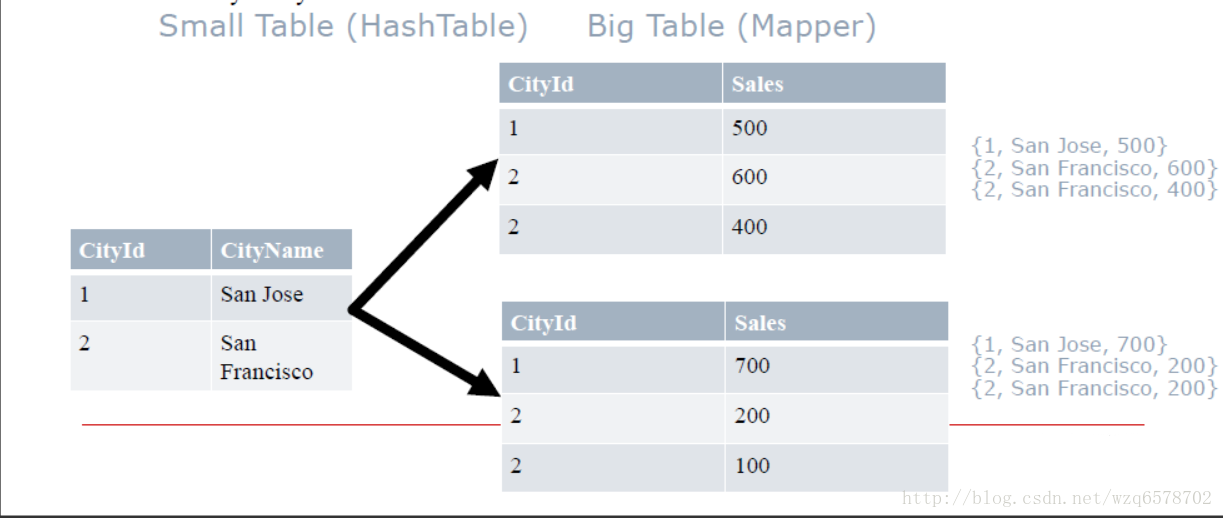
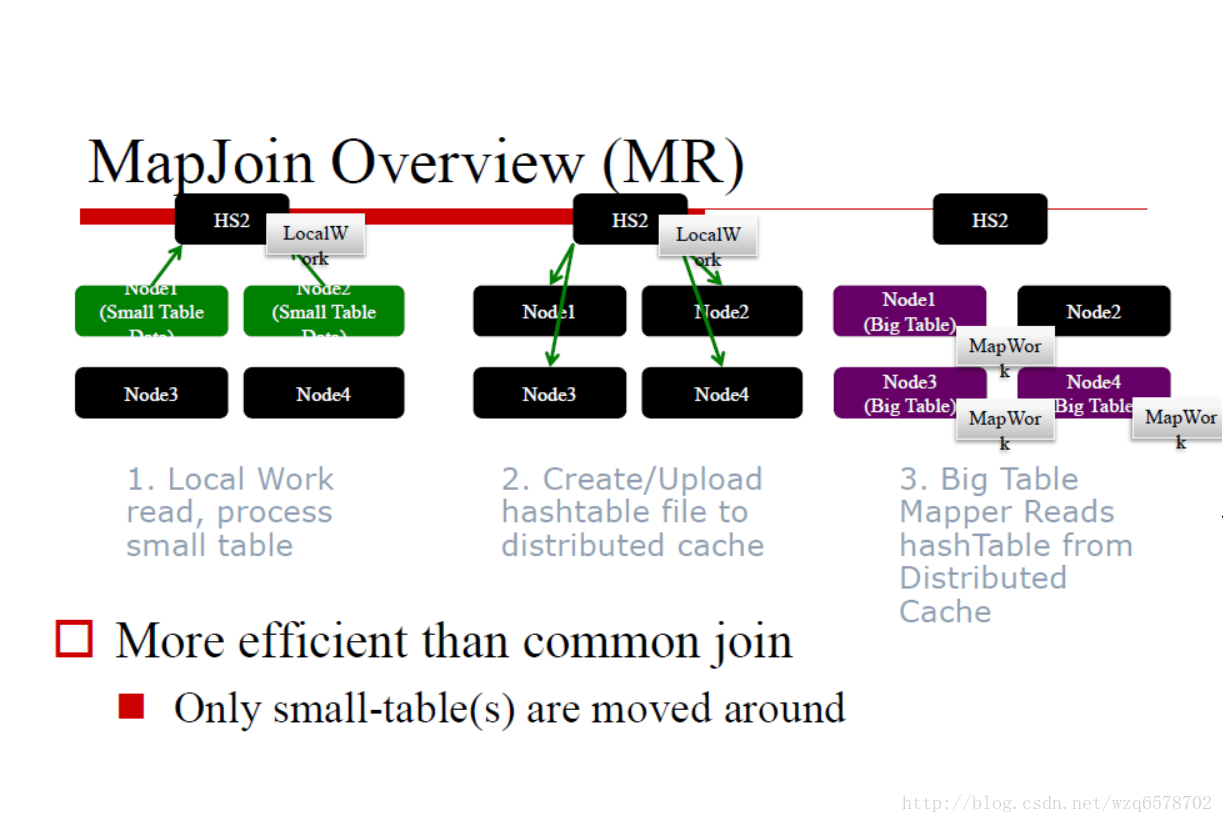
如何决定MapJoin
内存要求: N-1 张小表必须能够完全读入内存
Hive决定MapJoin的两种方式(手动/自动)
手动,通过Query Hints(不再推荐):
SELECT /*+ MAPJOIN(cities) / * FROM cities JOIN sales on cities.cityId=sales.cityId;
/+ MAPJOIN(cities) */ *会决定把cities读入内存,放在hashTable里边,分发到每一个节点。
自动,打开(“hive.auto.convert.join”)
如果N-1张小表小于: “hive.mapjoin.smalltable.filesize”这个值
MapJoin Optimizers
构造查询计划Query Plan时,决定MapJoin优化
“逻辑优化器Logical (Compile-time) optimizers” :修改逻辑执行计划,把JoinOperator修改成MapJoinOperator
“物理优化器Physical (Runtime) optimizers” 修改物理执行计划(MapRedWork, TezWork, SparkWork), 引入条件判断等机制
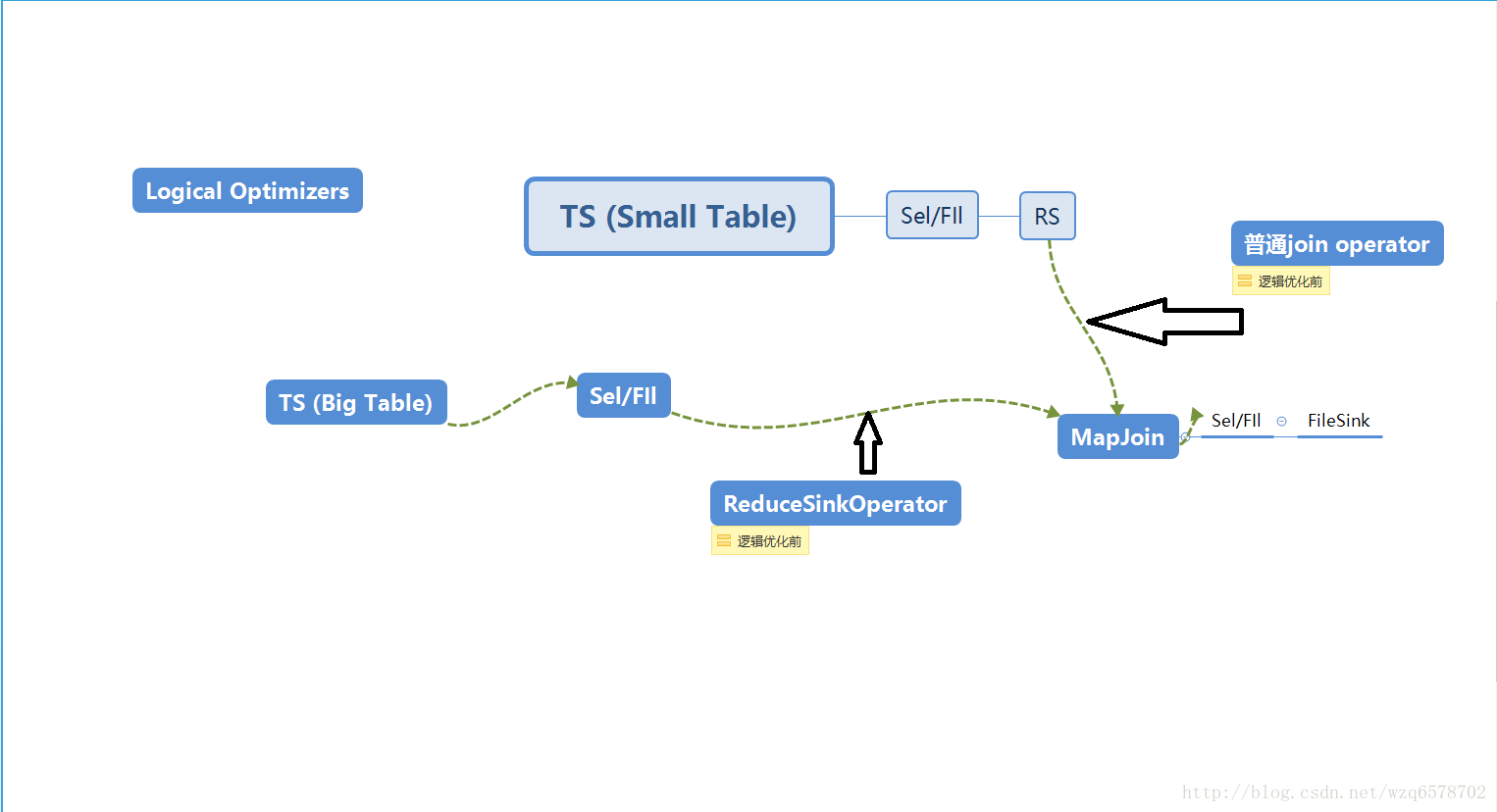
逻辑优化之后ReduceSinkOperator.和普通的join operator被摘掉,换成mapjoin。
物理执行计划会被关联到具体的执行引擎,逻辑执行计划的小表部分会在本地执行,即左边小表在本地执行,逻辑执行计划的大表部分会被在远端执行。
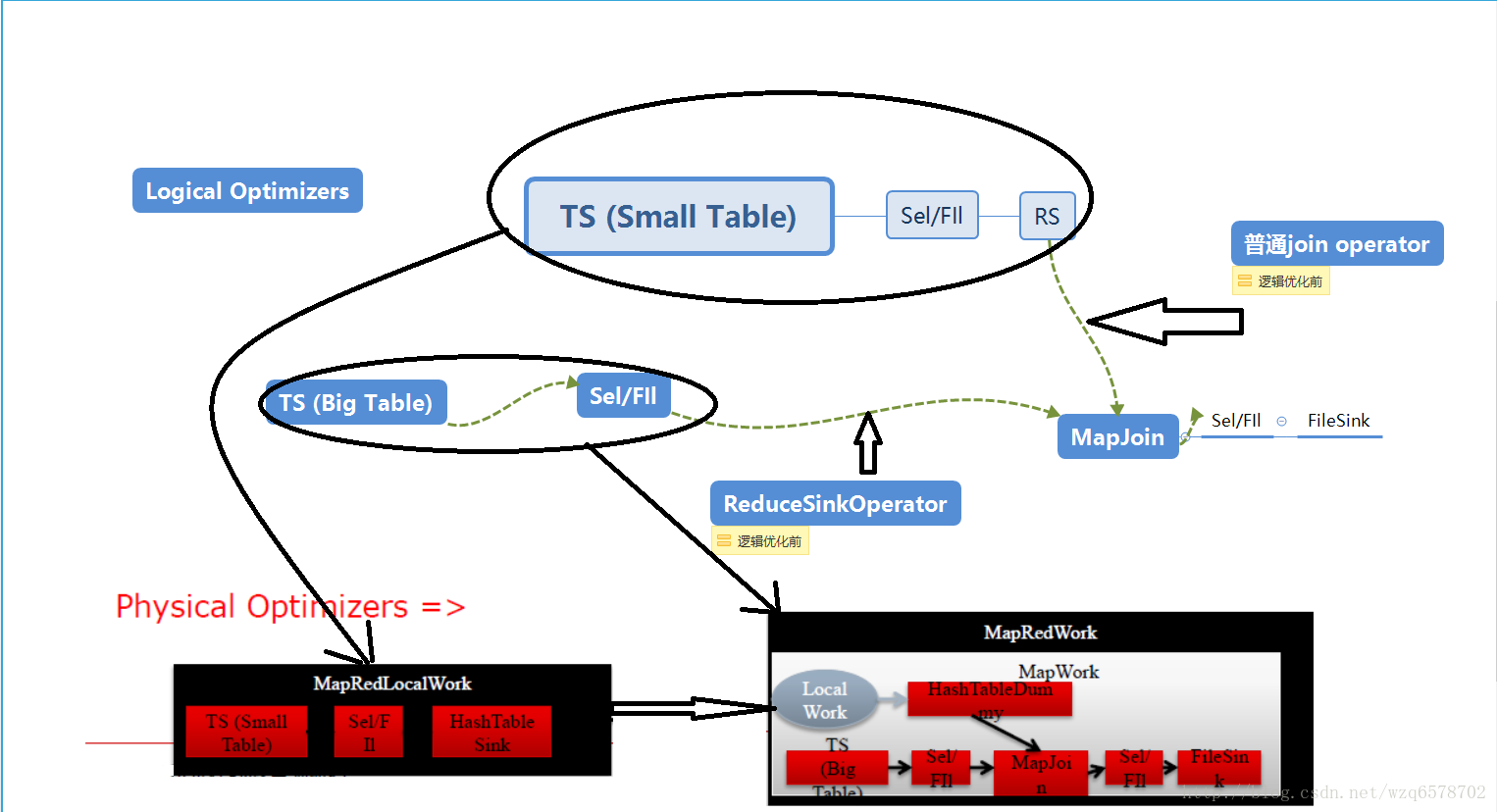
MapJoin Optimizers (MR)
Query Hint: 编译时知道哪个表是小表的情况.(手动模式,加一个/*+ MAPJOIN(cities) */ *注释)
Logical Optimizer逻辑优化器: MapJoinProcessor
Auto-conversion: 编译时不知道哪个表是小表的情况(自动模式)
Physical Optimizer物理优化器: CommonJoinResolver, MapJoinResolver.
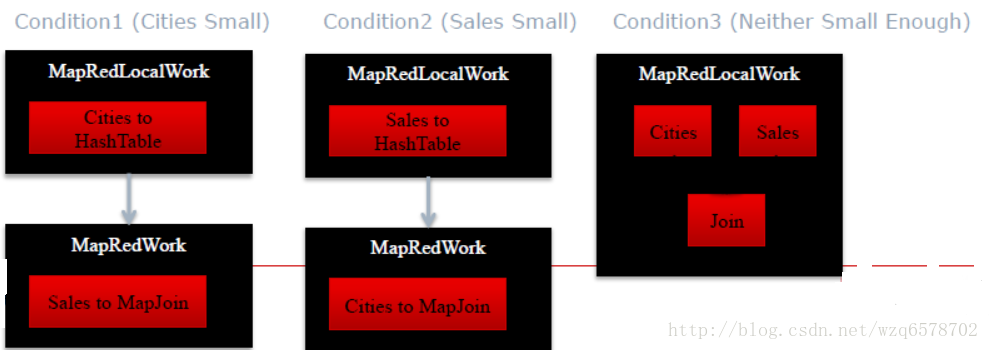
创建Conditional Tasks 把每个表是小表的情况考虑进去
Noconditional mode: 如果没有子查询的话,表的大小是在编译时可以知道的,否则是不知道的(join of intermediate results…)
自动模式模式分了三种情况,其中一个属于小表,这是前两种情况,第三种是都不是小表。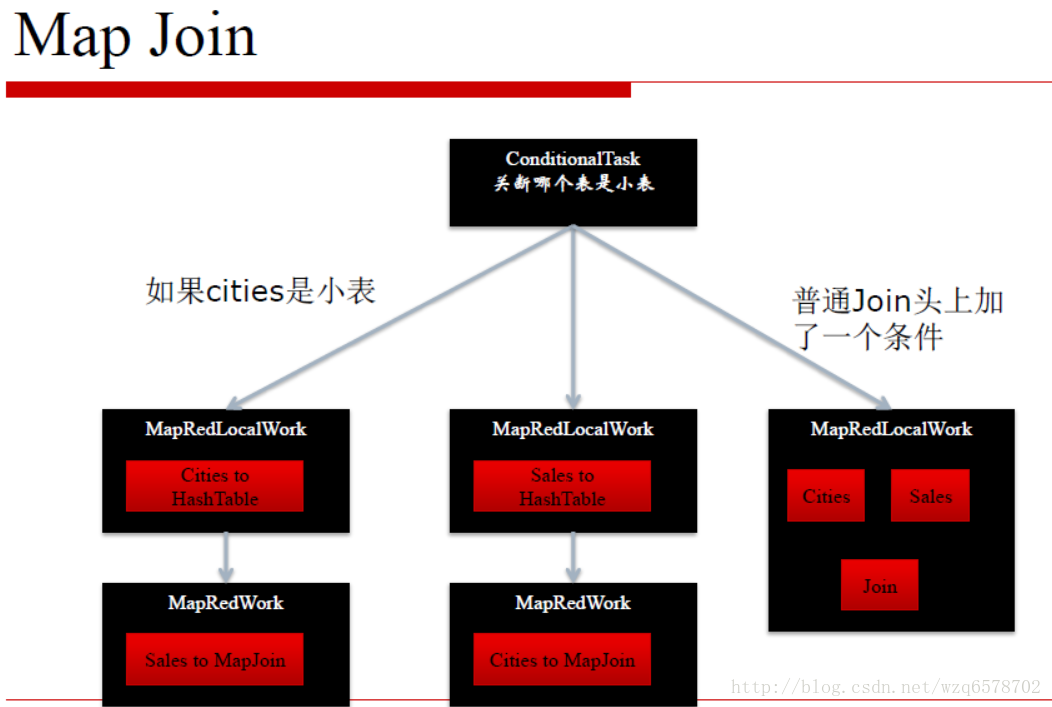
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/optimizer/physical/CommonJoinResolver.java?line=71
实现细节是:
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/optimizer/physical/CommonJoinTaskDispatcher.java?line=191
BucketMapJoin
Bucketed 表: 根据不同的值分成不同的桶
CREATE TABLE cities (cityid int, value string) CLUSTERED BY (cityId) INTO 2 BUCKETS;即建表的时候指定桶。
如果把分桶键(Bucket Key)作为关联键(Join Key): For each bucket of table, rows with matching joinKey values will be in corresponding bucket of other table
像Mapjoin, but big-table mappers load to memory only relevant small-table bucket‟s hashmap
Ex: Bucketed by “CityId”, Join by “CityId”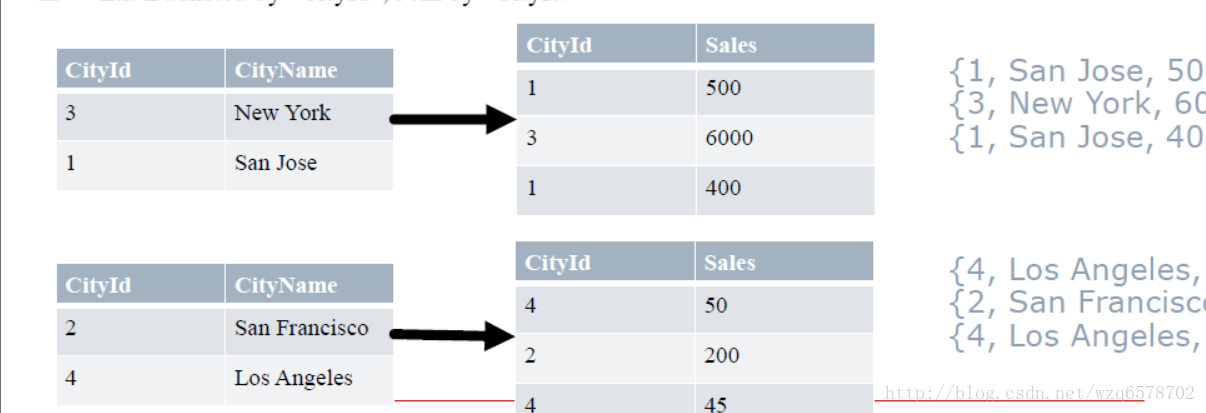
Bucket MapJoin 执行过程
与MapJoin非常类似
HashTableSink (小表) 写Hashtable是每个桶写一个Hashtable,而不是每张表写一个
HashTableLoader (大表Mapper mapper) 也是每个桶读取一次HashTable
SMB Join
CREATE TABLE cities (cityid int, cityName string) CLUSTERED BY (cityId) SORTED BY (cityId) INTO 2 BUCKETS;
Join tables are bucketed and sorted (per bucket)
This allows sort-merge join per bucket.
Advance table until find a match
建表的时候对桶内的指定字段进行排序,这样的安排可以直接使用common join operator,不需要使用map join operator,直接把表读出来交给common join operator
SMB Join
MR和Spark执行方式相同
用mapper处理大表,处理过程中直接读取对应的小表
Map直接读取小表中相应的文件,相应的部分,避免了广播的开销
小表没有大小的限制
前提是,要知道经常使用哪个键做Join
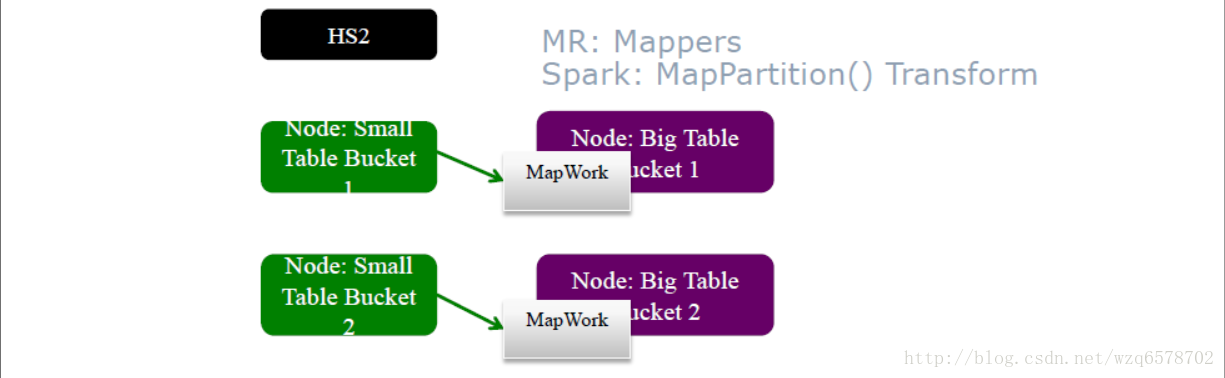
SMB Join Optimizers: MR
SMB 需要识别„大表‟,以便在大表上运行mapper,执行过程中读取„小表‟. 通常来说,在编译时决定
手动方法,用户可以手动提供hints
Triggered by “hive.optimize.bucketmapjoin.sortedmerge”
Logical Optimizer逻辑优化器: SortedMergeBucketMapJoinProc
自动触发: “hive.auto.convert.sortmerge.join.bigtable.selection.policy” 一个处理类
Triggered by “hive.auto.convert.sortmerge.join”
Logical Optimizer: SortedBucketMapJoinProc
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/optimizer/SortedMergeBucketMapjoinProc.java?line=42
public Object process(Node nd, Stack<Node> stack, NodeProcessorCtx procCtx,
Object... nodeOutputs) throws SemanticException {
if (nd instanceof SMBMapJoinOperator) {
return null;
}
MapJoinOperator mapJoinOp = (MapJoinOperator) nd;
SortBucketJoinProcCtx smbJoinContext = (SortBucketJoinProcCtx) procCtx;
boolean convert =
canConvertBucketMapJoinToSMBJoin(mapJoinOp, stack, smbJoinContext, nodeOutputs);
// Throw an error if the user asked for sort merge bucketed mapjoin to be enforced
// and sort merge bucketed mapjoin cannot be performed
if (!convert &&
pGraphContext.getConf().getBoolVar(
HiveConf.ConfVars.HIVEENFORCESORTMERGEBUCKETMAPJOIN)) {
throw new SemanticException(ErrorMsg.SORTMERGE_MAPJOIN_FAILED.getMsg());
}
if (convert) {
convertBucketMapJoinToSMBJoin(mapJoinOp, smbJoinContext);
}
return null;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
回到原来的那个汇总:
倾斜关联Skew Join
倾斜键Skew keys = 高频出现的键, 非常多的键,多到一个reduce处理不了
使用Common Join处理非倾斜键,使用Map Join处理倾斜键.
A join B on A.id=B.id, 如果A 表中id=1倾斜, 那么查询会变成
A join B on A.id=B.id and A.id!=1 union
A join B on A.id=B.id and A.id=1
判断是否是倾斜的,主要是判断建是不是倾斜的,那么怎么判断一个建是不是倾斜的呢?
Skew Join Optimizers (Compile Time, MR)
建表时指定倾斜键: create table … skewed by (key) on (key_value);
开关“hive.optimize.skewjoin.compiletime”
Logical Optimizer逻辑优化器: SkewJoinOptimizer查看元数据
直接指定倾斜建,是最好的一种,他会直接给出union的方式处理倾斜: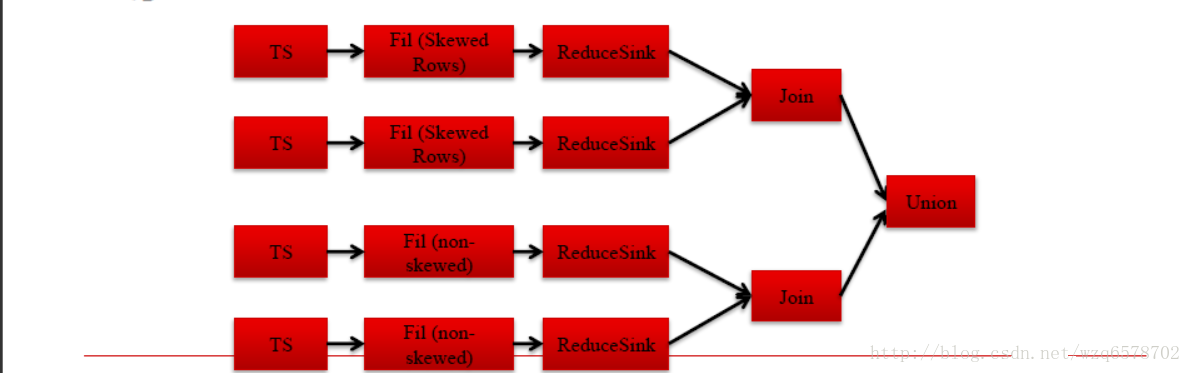
Skew Join Optimizers (Runtime, MR)
开关“hive.optimize.skewjoin”
Physical Optimizer: SkewJoinResolver
JoinOperator处理时候计数,如果某个可以被某个节点处理次数超过 “hive.skewjoin.key” 域值
倾斜键Skew key被跳过并且把值拷到单独的目录
ConditionalTask会单独针对倾斜的键作处理,并将结果作Union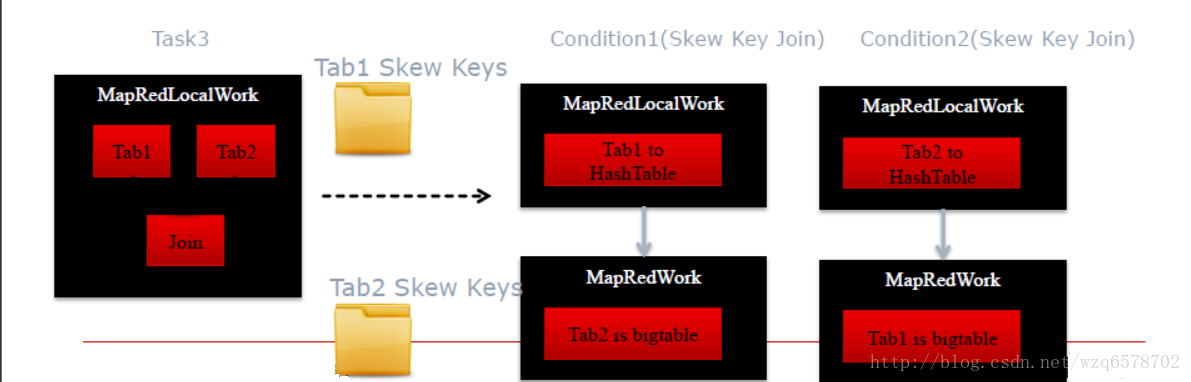
hive原理与源码分析-UDxF、优化器及执行引擎(五)
什么是UDF?
UDF的全称是User-Defined-Functions
Hive中一共有三种UDF
UDF(User-Defined Function):输入一行,输入一行,1->1
UDAF(User-Defined Aggregation Function):输入N行,输出一行,N->1
UDTF(User-Defined Table-generating Function):输入一行,输出N行,1->N
一切都是UDxF
内置操作符(本质上是一个UDF)
加、减、乘、除、等号、大于、小于……
内置UDF
常用数学操作,常用内符串操作……
常用日期操作……
内置UDAF
Count, sum , avg …
内置UDTF
Explode
自定义UDxF
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
UDF源码举例
一个简单的加号 1+2.5
https://www.codatlas.com/github.com/apache/hive/master/ql/src/java/org/apache/hadoop/hive/ql/udf/generic/GenericUDFOPPlus.java
类型转换 cast(1.5 as string)
https://www.codatlas.com/github.com/apache/hive/master/ql/src/java/org/apache/hadoop/hive/ql/udf/UDFToString.java?line=120
返回字符串长度 length(s)
https://www.codatlas.com/github.com/apache/hive/master/ql/src/java/org/apache/hadoop/hive/ql/udf/UDFLength.java
PTF是一种特殊的UDF
https://www.codatlas.com/github.com/apache/hive/master/ql/src/java/org/apache/hadoop/hive/ql/udf/generic/GenericUDFLead.java
https://www.codatlas.com/github.com/apache/hive/master/ql/src/java/org/apache/hadoop/hive/ql/udf/generic/GenericUDFLeadLag.java?line=35
用于窗口函数的计算
UDF存在下列Operator中
演示
https://cwiki.apache.org/confluence/display/Hive/HivePlugins#HivePlugins-CreatingCustomUDFs
UDAF
UDAF用于聚合
存在于GroupByOperator -> GenericUDAFEvaluator
思考:为什么Group By Operator即有ExprNodeEvaluator又月GenericUDAFEvaluator?
https://www.codatlas.com/github.com/apache/hive/master/ql/src/java/org/apache/hadoop/hive/ql/exec/GroupByOperator.java
UDAF源码举例
通用接口
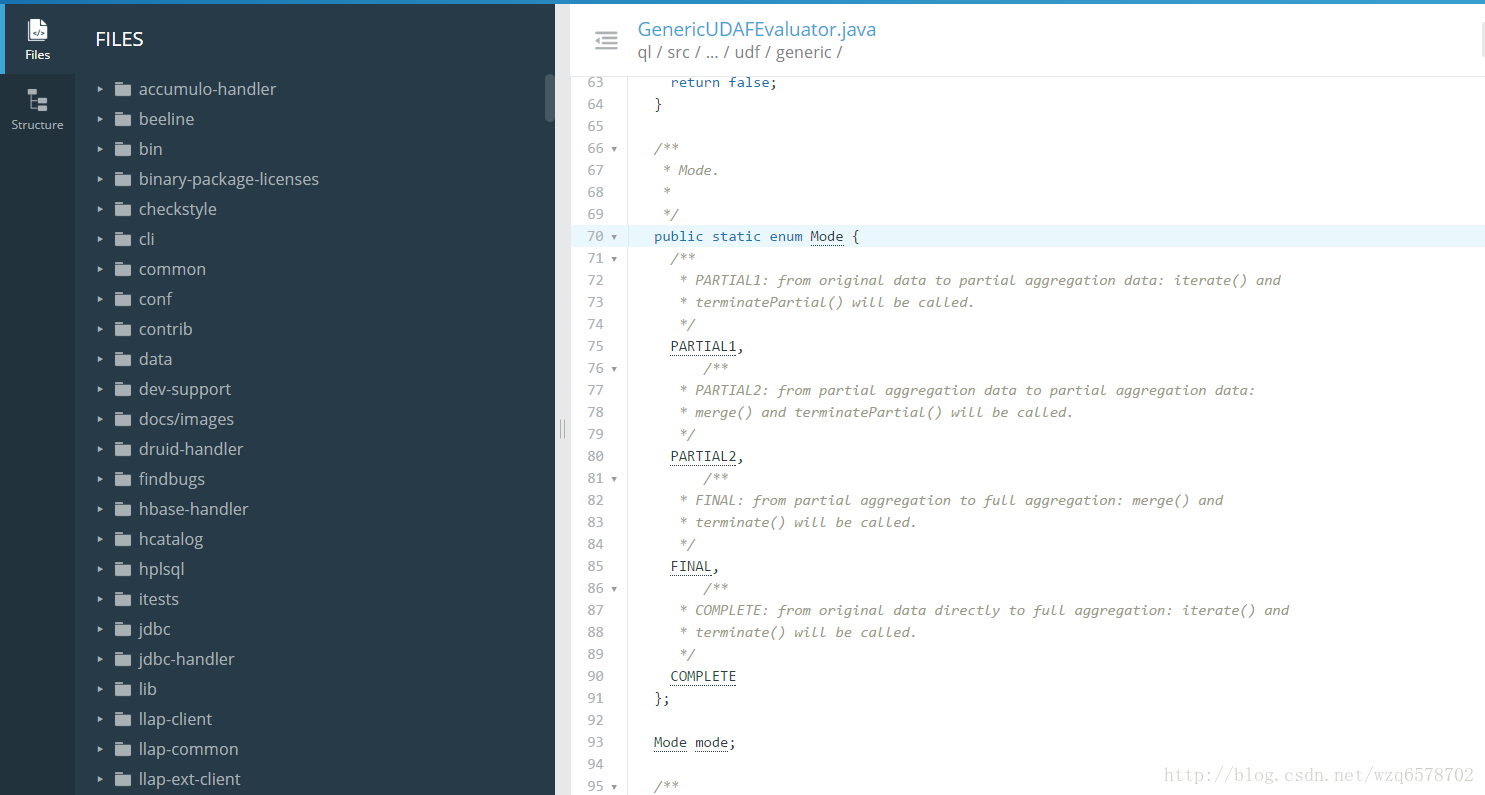
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/udf/generic/GenericUDAFEvaluator.java?line=70
当中有四种模式:
/**
* Mode.
*
*/
public static enum Mode {
/**
* PARTIAL1: from original data to partial aggregation data: iterate() and
* terminatePartial() will be called.
*/
PARTIAL1,
/**
* PARTIAL2: from partial aggregation data to partial aggregation data:
* merge() and terminatePartial() will be called.
*/
PARTIAL2,
/**
* FINAL: from partial aggregation to full aggregation: merge() and
* terminate() will be called.
*/
FINAL,
/**
* COMPLETE: from original data directly to full aggregation: iterate() and
* terminate() will be called.
*/
COMPLETE
};- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
回忆一下Group By执行的四种模式
对应一下UDAF四种模式
自定义UDAF
https://cwiki.apache.org/confluence/display/Hive/GenericUDAFCaseStudy
写Resolver
写Evaluator
getNewAggregationBuffer()
iterate()
terminatePartial()
merge()
terminate()
UDTF
UDTF用于行转列、拆分行、生成小表
存在于UDTFOperator
https://www.codatlas.com/github.com/apache/hive/master/ql/src/java/org/apache/hadoop/hive/ql/exec/UDTFOperator.java
@Override
public void process(Object row, int tag) throws HiveException {
//输入一行数据
// The UDTF expects arguments in an object[]
StructObjectInspector soi = (StructObjectInspector) inputObjInspectors[tag];
List<? extends StructField> fields = soi.getAllStructFieldRefs();
for (int i = 0; i < fields.size(); i++) {
objToSendToUDTF[i] = soi.getStructFieldData(row, fields.get(i));
}
//对输出的多个数据处理
genericUDTF.process(objToSendToUDTF);
if (conf.isOuterLV() && collector.getCounter() == 0) {
collector.collect(outerObj);
}
collector.reset();
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
/**
* Give a set of arguments for the UDTF to process.
*
* @param args
* object array of arguments
*/
public abstract void process(Object[] args) throws HiveException;- 1
- 2
- 3
- 4
- 5
- 6
- 7
经常会与LateralView一起使用
为什么?单独生成小表是无意义的
会将生成的小表和原来的表进行join
Lateral View
把某一列拆分成一个小表
把拆出来的小表作为一个视图
用这个视图和原表作Join (Map Join)
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+LateralView
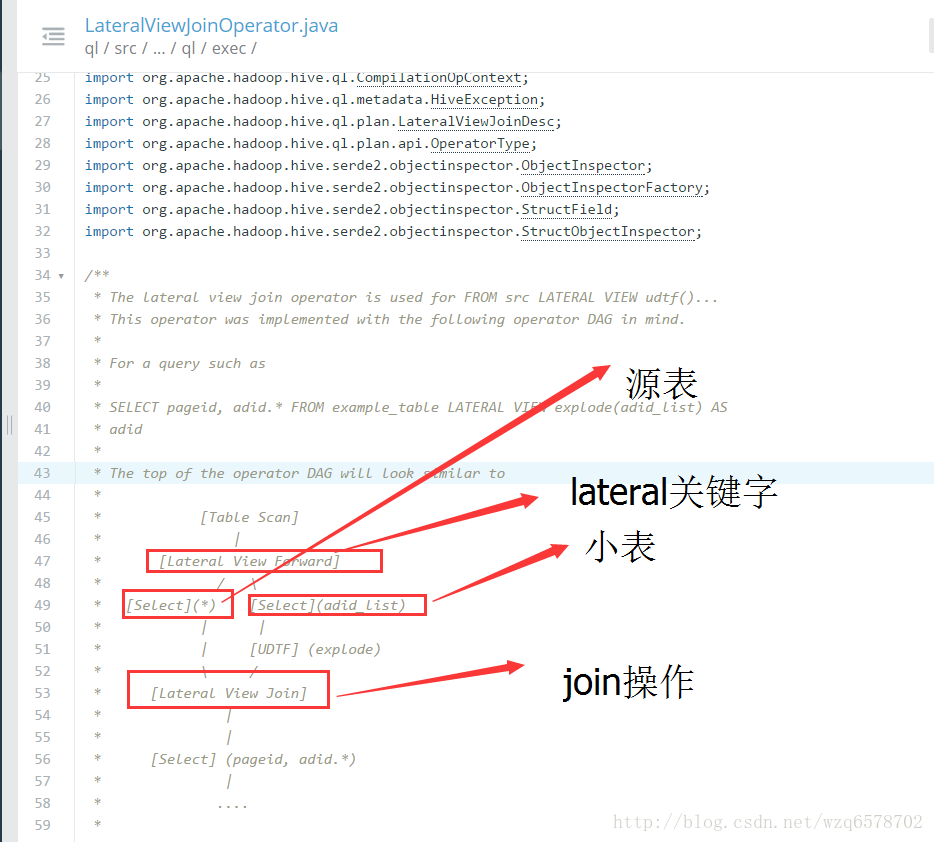
Lateral View源码和执行计划
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/exec/LateralViewJoinOperator.java?line=43
逻辑执行计划:
@Override
public void process(Object[] o) throws HiveException {
//输入一行数据
switch (inputOI.getCategory()) {
case LIST:
ListObjectInspector listOI = (ListObjectInspector)inputOI;
List<?> list = listOI.getList(o[0]);
if (list == null) {
return;
}
for (Object r : list) {
forwardListObj[0] = r;
//处理
forward(forwardListObj);
}
break;
case MAP:
MapObjectInspector mapOI = (MapObjectInspector)inputOI;
Map<?,?> map = mapOI.getMap(o[0]);
if (map == null) {
return;
}
for (Entry<?,?> r : map.entrySet()) {
forwardMapObj[0] = r.getKey();
forwardMapObj[1] = r.getValue();
forward(forwardMapObj);
}
break;
default:
throw new TaskExecutionException("explode() can only operate on an array or a map");
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
如,一些价格,以逗号分隔,存储在一个字段中
自定义UDTF
https://cwiki.apache.org/confluence/display/Hive/DeveloperGuide+UDTF
比UDAF要简单很多
Transform
与UDTF类似,只是以自定义脚本的形式,编写
适合语言控,比如我特别喜欢Python或者特别喜欢Ruby,但并不推荐
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Transform
为什么不推荐呢看源码
Transform源码分析
https://www.codatlas.com/github.com/apache/hive/master/ql/src/java/org/apache/hadoop/hive/ql/exec/ScriptOperator.java
hive默认的分隔符是”ctra+a”,倘若每行数据里边有tab分隔符,那么数据就会错乱,线程也会错乱。所以我们要在数据之中没有类似tab这样的分隔符的时候才能使用Transform不会出错。
。。。。。。。。。。。略
public void process(Object row, int tag) throws HiveException {
。。。。。。。。。。略
//启动2个线程,
outThread.start();
errThread.start();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
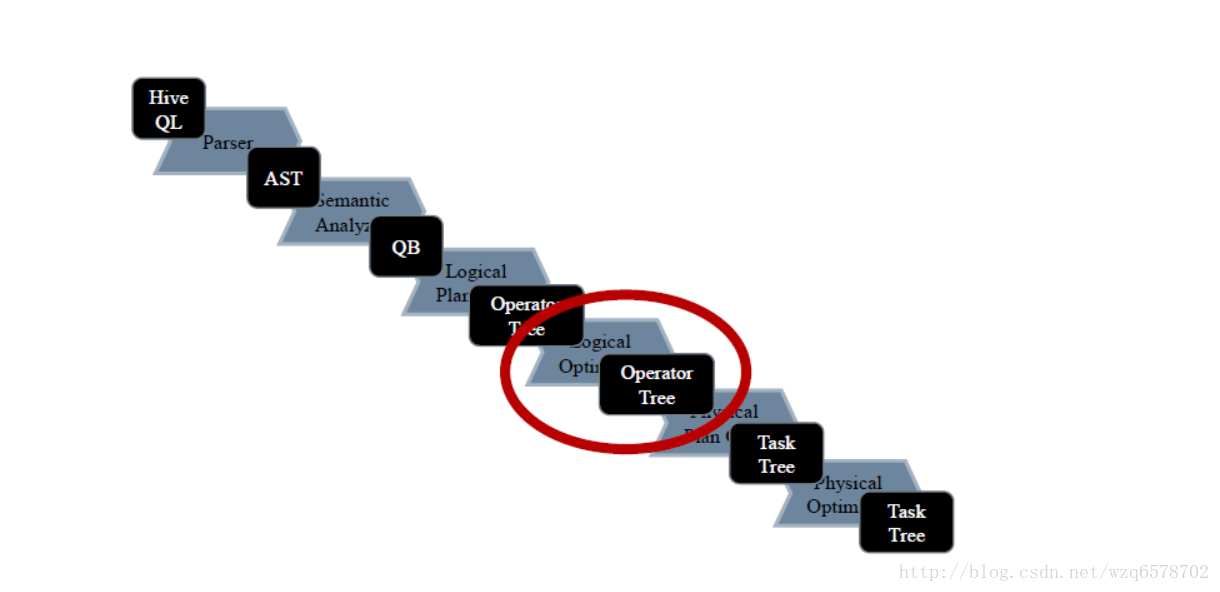
Hive流程 – 回顾
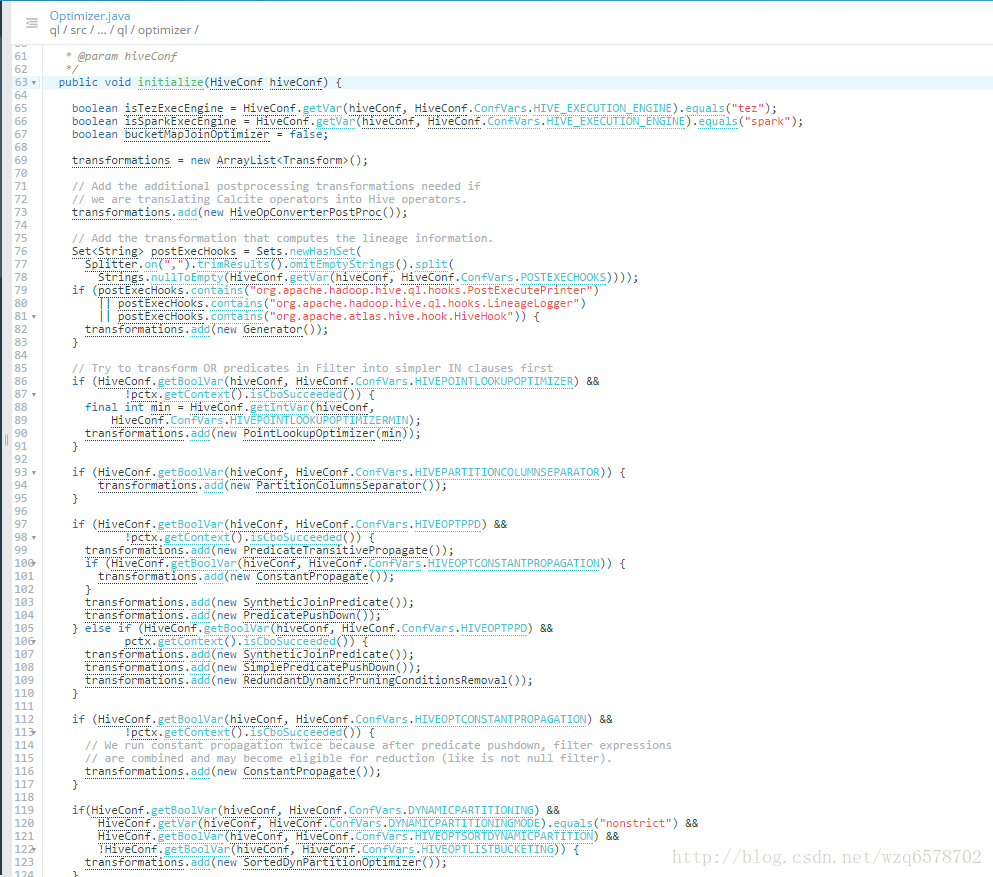
Optimizer其实优化器的调用者:
基于规则的优化的执行
根据配置初始化一个规则列表,然后一条规则一条规则地执行
把根据QB生成的逻辑执行计划改写成新的逻辑执行计划
https://www.codatlas.com/github.com/apache/hive/master/ql/src/java/org/apache/hadoop/hive/ql/optimizer/Optimizer.java?line=240
/**
* Invoke all the transformations one-by-one, and alter the query plan.
*
* @return ParseContext
* @throws SemanticException
*/
public ParseContext optimize() throws SemanticException {
for (Transform t : transformations) {
t.beginPerfLogging();
pctx = t.transform(pctx);
t.endPerfLogging(t.toString());
}
return pctx;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
基于规则的优化的执行

demo 1: 简单谓词下推优化器
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/ppd/SimplePredicatePushDown.java?line=55

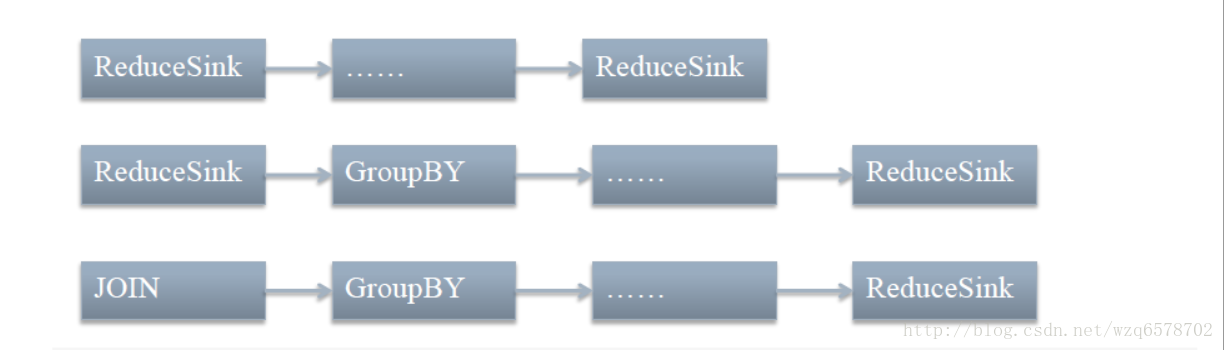
demo 2: ReduceSinkDeDuplication
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/optimizer/correlation/ReduceSinkDeDuplication.java?line=94
去重优化器,减少map作业数
// If multiple rules can be matched with same cost, last rule will be choosen as a processor
// see DefaultRuleDispatcher#dispatch()
Map<Rule, NodeProcessor> opRules = new LinkedHashMap<Rule, NodeProcessor>();
//reduce sink后边有reduce sink 执行ReduceSinkDeduplicateProcFactory.getReducerReducerProc()优化
opRules.put(new RuleRegExp("R1", RS + "%.*%" + RS + "%"),
ReduceSinkDeduplicateProcFactory.getReducerReducerProc());
//reduce sink后边有group by + reduce sink执行ReduceSinkDeduplicateProcFactory.getGroupbyReducerProc()优化
opRules.put(new RuleRegExp("R2", RS + "%" + GBY + "%.*%" + RS + "%"),
ReduceSinkDeduplicateProcFactory.getGroupbyReducerProc());
if (mergeJoins) {
//jion 后边有reduce sink执行ReduceSinkDeduplicateProcFactory.getJoinReducerProc()优化
opRules.put(new RuleRegExp("R3", JOIN + "%.*%" + RS + "%"),
ReduceSinkDeduplicateProcFactory.getJoinReducerProc());
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
demo 3: JoinReorder
我们建议小表放在左边,大表放在右边,但是没有这种情况下,
虽然大表要放右边,有了JoinReorder,大表就可以放左边了JoinReorder可以改写成这样的形式来优化。这种优化需要打开开关。
为什么?看代码
https://www.codatlas.com/github.com/apache/hive/master/ql/src/java/org/apache/hadoop/hive/ql/optimizer/JoinReorder.java?line=40
只能是大表,不能是大的子查询
思考:为什么?
所以,打开这个开关时,简单查询是不需要小表放左边的 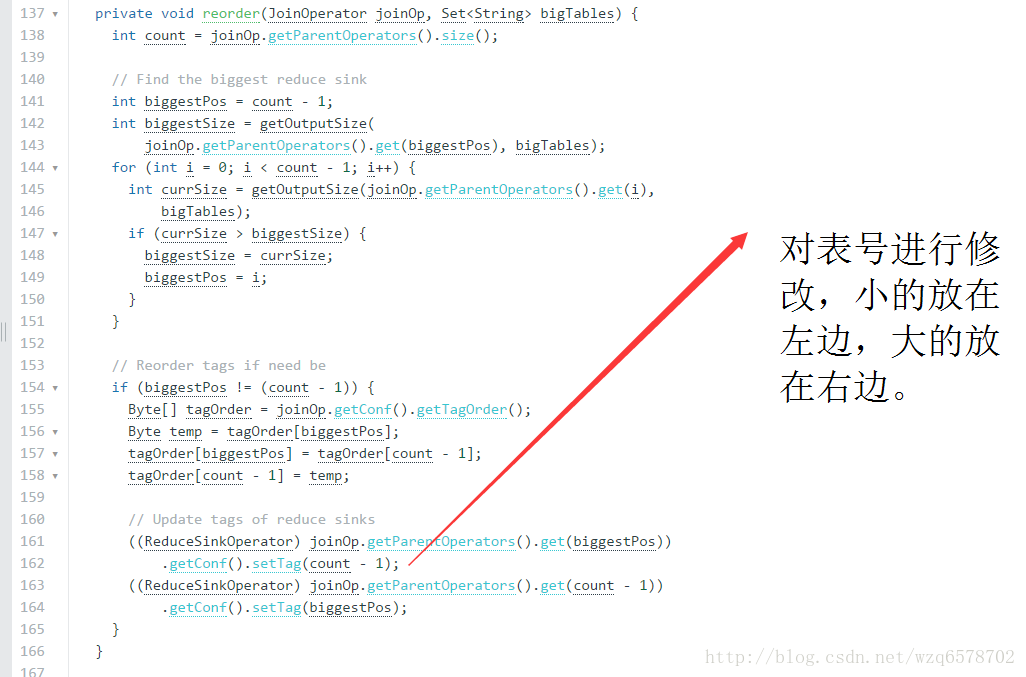
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/optimizer/Optimizer.java?line=186
if (HiveConf.getBoolVar(hiveConf, HiveConf.ConfVars.NWAYJOINREORDER)) {
transformations.add(new JoinReorder());
}- 1
- 2
- 3
https://insight.io/github.com/apache/hive/blob/master/common/src/java/org/apache/hadoop/hive/conf/HiveConf.java?line=3353 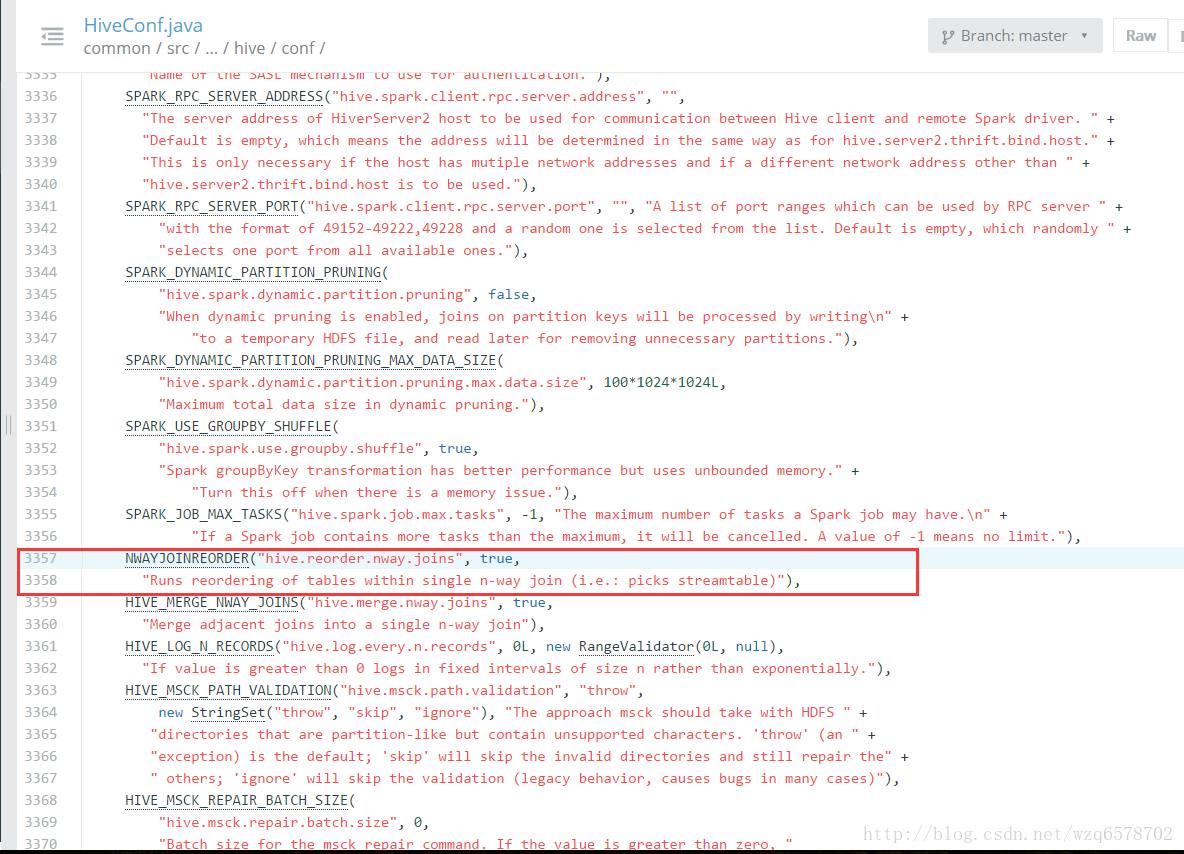
更多优化器
更多优化器请根据Optimizer的代码自行阅读
如果作为一个用户,只需要知道优化器的作用即可
如果是源码程序员,可尝试手动写一个优化器
Hive流程 – 回顾
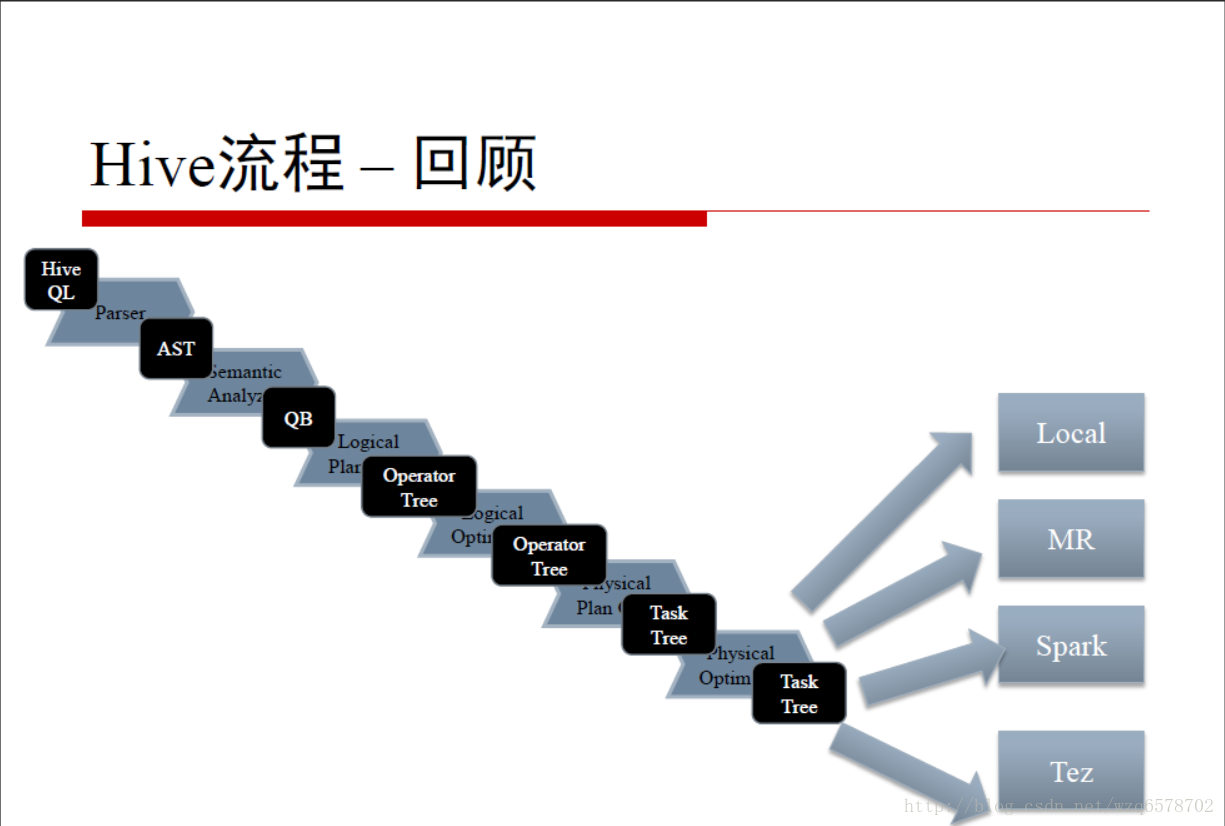
Hive执行引擎
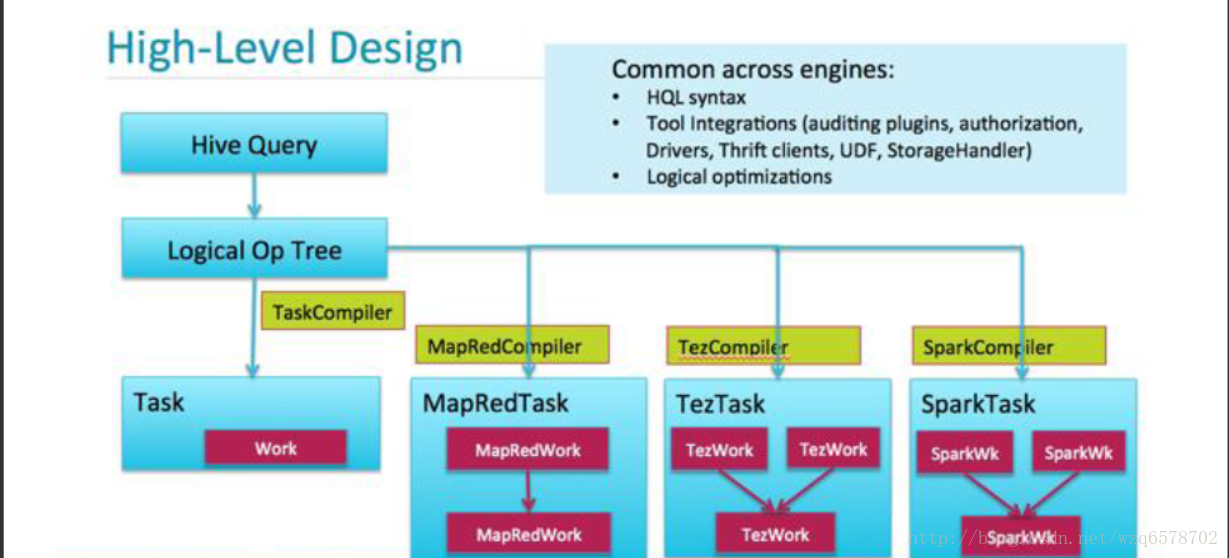
执行引擎
四种执行引擎
Local
MapReduce
Spark
https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started
Tez
https://cwiki.apache.org/confluence/display/Hive/Hive+on+Tez
Tez + LLAP
代码部分 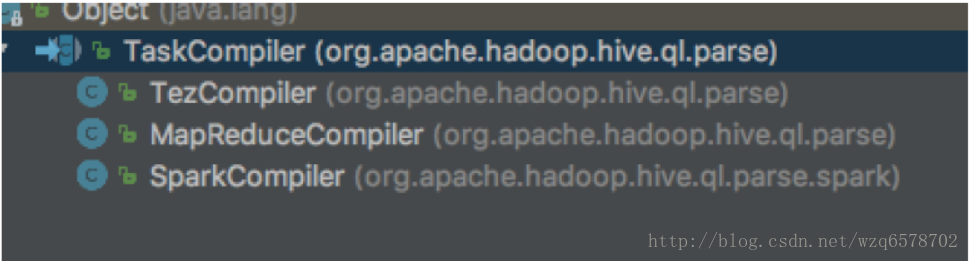
https://www.codatlas.com/github.com/apache/hive/master/ql/src/java/org/apache/hadoop/hive/ql/parse/TaskCompiler.java?line=87
Hive流程 – 我们还没介绍的