
论文笔记Stacked Hourglass Networks
Stacked Hourglass Networks for Human Pose Estimation这篇论文介绍了一种新的网络结构用于人体姿态检测,作者在论文中展现了不断重复bottom-up、top-down过程以及运用intermediate supervison(中间监督)对于网络性能的提升,下面来介绍Stacked Hourglass Networks.
简介
理解人类的姿态对于一些高级的任务比如行为识别来说特别重要,而且也是一些人机交互任务的基础。作者提出了一种新的网络结构Stacked Hourglass Networks来对人体的姿态进行识别,这个网络结构能够捕获并整合图像所有尺度的信息。之所以称这种网络为Stacked Hourglass Networks,主要是它长得很像堆叠起来的沙漏,如下图所示:
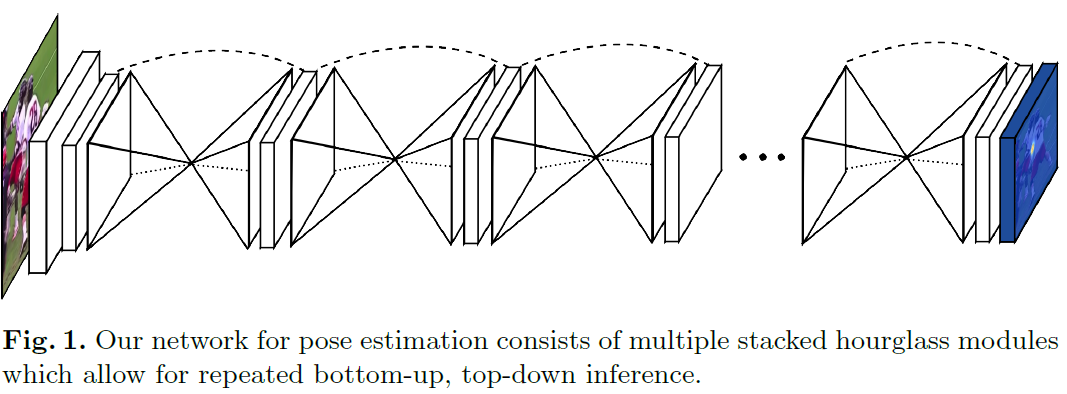
这种堆叠在一起的Hourglass模块结构是对称的,bottom-up过程将图片从高分辨率降到低分辨率,top-down过程将图片从低分辨率升到高分辨率,这种网络结构包含了许多pooling和upsampling的步骤,pooling可以将图片降到一个很低的分辨率,upsampling可以结合多个分辨率的特征。
下面介绍具体的网络结构。
Hourglass Module(Hourglass 模块)
Hourglass模块设计的初衷就是为了捕捉每个尺度下的信息,因为捕捉像脸,手这些部分的时候需要局部的特征,而最后对人体姿态进行预测的时候又需要整体的信息。为了捕获图片在多个尺度下的特征,通常的做法是使用多个pipeline分别单独处理不同尺度下的信息,然后再网络的后面部分再组合这些特征,而作者使用的方法就是用带有skip layers的单个pipeline来保存每个尺度下的空间信息。
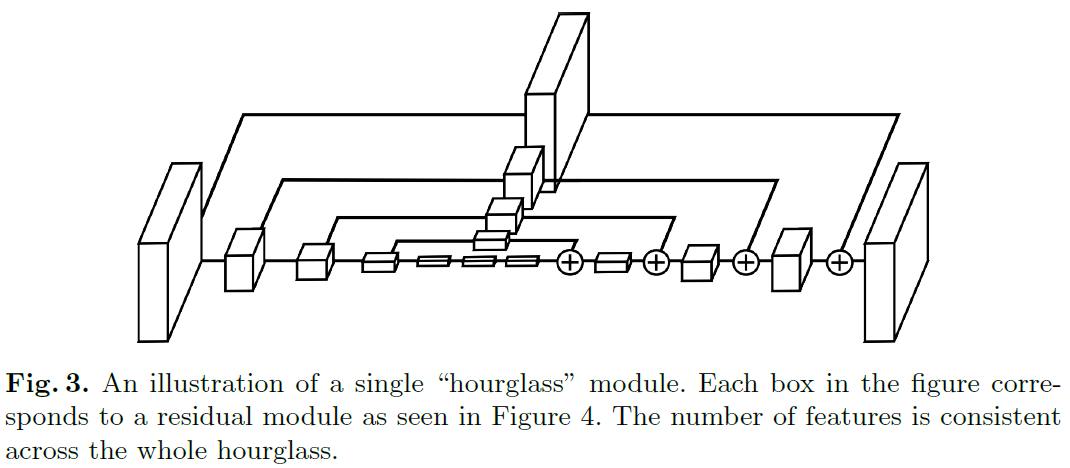
在Hourglass模块中,卷积和max pooling被用来将特征降到一个很低的分辨率,在每一个max pooling步骤中,网络产生分支并在原来提前池化的分辨率下使用更多的卷积,当到达最低的分辨率的时候,网络开始upsample并结合不同尺度下的特征。这里upsample(上采样)采用的方法是最邻近插值,之后再将两个特征集按元素位置相加。
当到达输出分辨率的时候,再接两个1×1的卷积层来进行最后的预测,网络的输出是一组heatmap,对于给定的heatmap,网络预测在每个像素处存在关节的概率。
网络结构
Residual Module
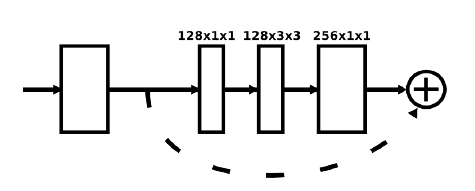
Fig.3中的每个方框都由下面这样的残差块组成:
 Residual Module
Residual Module
上图的残差块是论文中的原图,描述的不够详细,自己看了下源代码之后,画出了如下图所示的Residual Module:
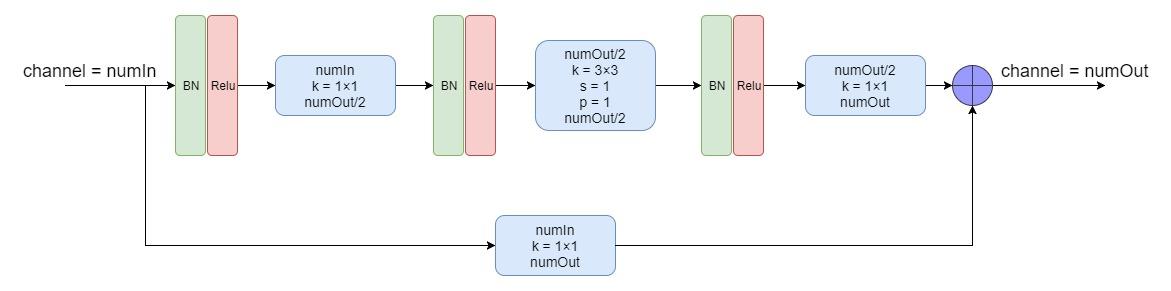
贴出一段作者提供的关于Residual Module的源代码:
local conv = nnlib.SpatialConvolution
local batchnorm = nn.SpatialBatchNormalization
local relu = nnlib.ReLU
-- Main convolutional block
local function convBlock(numIn,numOut)
return nn.Sequential()
:add(batchnorm(numIn))
:add(relu(true))
:add(conv(numIn,numOut/2,1,1))
:add(batchnorm(numOut/2))
:add(relu(true))
:add(conv(numOut/2,numOut/2,3,3,1,1,1,1))
:add(batchnorm(numOut/2))
:add(relu(true))
:add(conv(numOut/2,numOut,1,1))
end
-- Skip layer
local function skipLayer(numIn,numOut)
if numIn == numOut then
return nn.Identity()
else
return nn.Sequential()
:add(conv(numIn,numOut,1,1))
end
end
-- Residual block
function Residual(numIn,numOut)
return nn.Sequential()
:add(nn.ConcatTable()
:add(convBlock(numIn,numOut))
:add(skipLayer(numIn,numOut)))
:add(nn.CAddTable(true))
endHourglass Module
Hourglass Module由上面的Residual Module组成,由于它是一个递归的结构,所以可以定义一个阶数来表示递归的层数,首先来看一下一阶的Hourglass Module:
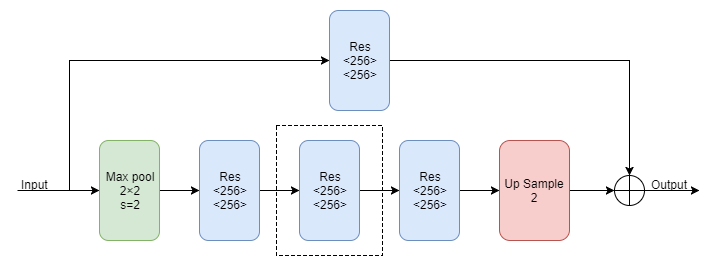
上图中的Max pool代表下采样,Res代表上面介绍的Residual Module,Up Sample代表上采样。多阶的Hourglass Module就是将上图虚线框中的块递归地替换为一阶Hourglass Module,由于作者在实验中使用的是4阶的Hourglass Moudle,所以我们画出了4阶的Hourglass Module的示意图:
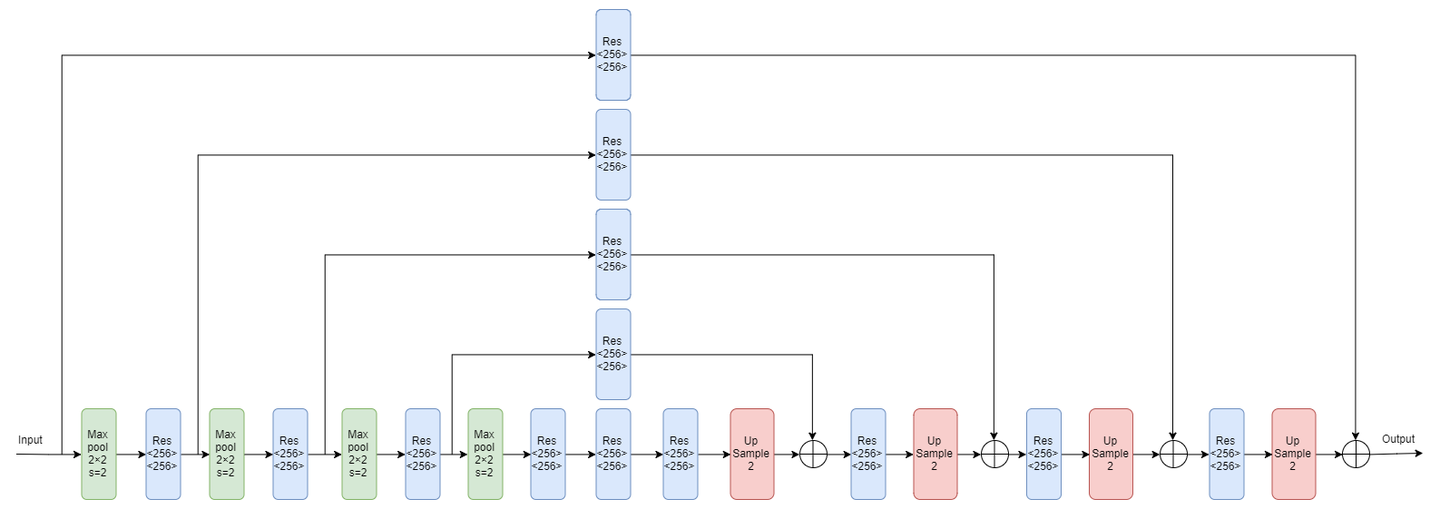
整体结构
网络输入的图片分辨率为256×256,在hourglass模块中的最大分辨率为64×64,整个网络最开始要经过一个7×7的步长为2的卷积层,之后再经过一个残差块和Max pooling层使得分辨率从256降到64。下面贴出作者提供的整个网络结构的源代码:
paths.dofile('layers/Residual.lua')
local function hourglass(n, f, inp)
-- Upper branch
local up1 = inp
for i = 1,opt.nModules do up1 = Residual(f,f)(up1) end
-- Lower branch
local low1 = nnlib.SpatialMaxPooling(2,2,2,2)(inp)
for i = 1,opt.nModules do low1 = Residual(f,f)(low1) end
local low2
if n > 1 then low2 = hourglass(n-1,f,low1)
else
low2 = low1
for i = 1,opt.nModules do low2 = Residual(f,f)(low2) end
end
local low3 = low2
for i = 1,opt.nModules do low3 = Residual(f,f)(low3) end
local up2 = nn.SpatialUpSamplingNearest(2)(low3)
-- Bring two branches together
return nn.CAddTable()({up1,up2})
end
local function lin(numIn,numOut,inp)
-- Apply 1x1 convolution, stride 1, no padding
local l = nnlib.SpatialConvolution(numIn,numOut,1,1,1,1,0,0)(inp)
return nnlib.ReLU(true)(nn.SpatialBatchNormalization(numOut)(l))
end
function createModel()
local inp = nn.Identity()()
-- Initial processing of the image
local cnv1_ = nnlib.SpatialConvolution(3,64,7,7,2,2,3,3)(inp) -- 128
local cnv1 = nnlib.ReLU(true)(nn.SpatialBatchNormalization(64