深度需求预测(Deep Demand Forecast)
由于最近工作的关系,在需求预测上有所研究。该篇主要是结合当前学术研究,实际场景和自身工作经验进行一个总结。和以往介绍需求预测的不同,本文侧重实际应用,不侧重技术本身。文章命名为深度需求预测,一方面是会介绍一些深度学习的应用案例,另一方面是希望能够分享现实场景中更深层面的实际挑战。
需求预测场景类型
需求预测通常是供应链的重要一环,它主要是为了供应链下游,如预生产,补货,库存管理,供应链运营等环节服务的。
我自己把需求预测根据场景分为两种:事件驱动型(event-driven)和周期趋势型(periodic or trendy)。这两种类型并不是完全孤立的。现实场景中通常是两种都存在,只是其中一种占据主要因素。
事件驱动型
常见的事件驱动型的场景是电商平台,快消商品等2C产品的需求预测,也包括网页UV,PV等的预测。电商的销量主要通过各种促销活动事件进行驱动,比如618,聚划算,双11,超级品类日等大节和小节。没有活动时的销量会相对较低和稳定。和电商类似的,快消商品在平日的销量趋于稳定,而在部分节假日,促销活动等会有大幅增长,然后回落之前的水平。
在事件驱动型需求预测中,需求本身的表现受活动事件影响,活动前后的需求趋于稳定,主要靠商家广告媒体投放,带来客流和人流,带动销量的迅速增长,但活动结束后又回落。需求在长时间范围内的周期性趋势不明显,主要靠品牌的影响力,口碑等带来的市场份额变化引起的趋势变化,如品牌影响力提高,质量保证,市场占有率逐渐上升,引起在时间范围内的销量稳步上涨。
关于事件驱动型的需求预测,个人认为更偏向于带时间属性的监督学习。通常选择的特征以与事件相关,与市场相关的特征为主。
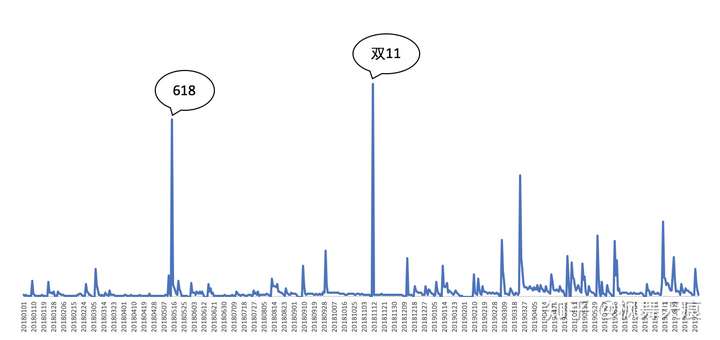 图1 事件驱动型需求示例
图1 事件驱动型需求示例
周期趋势型
常见的周期趋势型的场景在于一些稳定的制造业等2B商品,也会见于一些活动少,不靠活动带来销量的2C商品。这两种产品的例子,如汽车零部件,医药,办公消耗品等。除了一些节假日,特殊活动或者政策的外界因素影响,这些商品的需求表现呈现整体的周期性和规律性。
关于周期趋势型的需求预测,该归属于时间序列预测的范畴。通常选择的特征以时间序列特征为主。
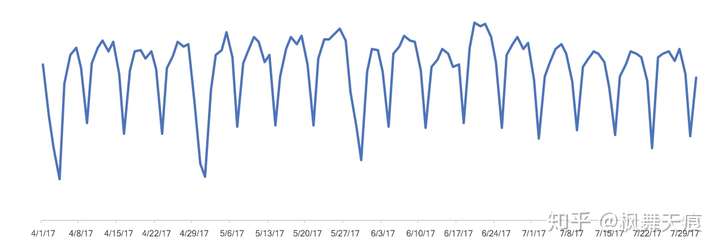 图2 周期趋势型需求示例
图2 周期趋势型需求示例
需求预测维度分类
除了场景分类外,我们也可以把需求预测根据预测维度进行分类。
时间维度需求预测
时间维度的需求预测顾名思义是在时间尺度上进行需求的预测,比如小时预测,日度预测,月度预测,季度预测等。同样的数据,依据下游不同需求会有不同时间尺度的预测,比如工厂生产周期为一个月,那么需要做月度预测。市场部门需要每天的销量预测,用于指导市场投放等。
时间维度预测在需求预测中是非常普遍的。不管是事件驱动型还是周期趋势型,根据不同的业务需求,都需要时间维度的预测。
事件维度需求预测
事件维度的需求预测是从影响需求的事件出发的,关注的某个事件发生的需求。比如在电商场景中,我们关注促销活动的销量。同样地,我们可以把普通的日期汇总作为一个普通事件。对于该类预测,我们可以通过时间维度的需求预测进行事件维度的汇总,也可以从事件本身出发预测。
事件维度的预测主要集中在事件驱动型的需求预测中。
极端点预测
极端点预测类比离群点预测,比如节假日的高峰/低估,双11这种超级离群点等。在大多数比赛或者研究中,因为这些极端点预测不准会影响总体的准确率,所以这些极端点都会被各种数据预处理掉(如离群点处理,平滑处理等)。不过,在实际生产业务中,这些极端的离群点是包含有用信息的,不能只是简单的预处理。
通常地,极端点的预测可以通过后处理,带趋势的模型,还有一些外部信息的辅助来实现。举例来说,双11的预测。双11的销量很有可能超越所有历史数据的值。如果只是用树模型去预测双11的量,一般都是低估的。因为树模型不能extrapolate,无法预测历史上没有出现过的销量。我们可考虑基于树模型预测值的后处理方法,比如类比以往双11与双11前预售的比例,类比双11和去年双11等。另一个角度,我们可以基于事件维度的需求预测。我们把历史离群点归为事件数据,用线性模型或者其它模型,进行事件维度的需求预测建模。
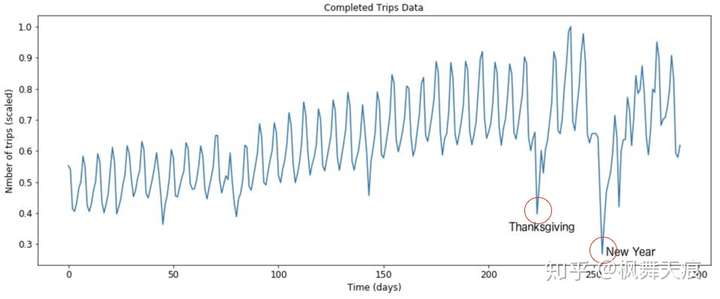 图3 极端点需求示例
图3 极端点需求示例
需求预测方法论
通常来说,需求预测可分为简单方法,传统时间序列预测,转化为监督学习预测,以及深度学习方法。
- 简单方法包括:直接平均法,滑动平均法,加权平均法,指数平滑法,多倍数指数平滑法,线性回归
- 传统时间序列预测包括:ARIMA,Holt-winters
- 转化为监督学习预测包括:XGBoost, LightGBM, CatBoost, Random Forest等树模型
- 深度学习:
- Multi-time series forecast: seq2seq, LSTM及其变种, TPA-LSTM, LSNets等
- Multi-time series quantile regression: DeepAR, MQ-RNN, Deep Factors Model
简单方法本文不再累述,详情可参考相关的文献,参考文献中也由相关网页链接。该章主要讲述一下传统时间序列预测和转化为监督学习预测的方法。深度学习的方法会在后面案例研究中详述。
ARIMA (Autoregressive Integrated Moving Average)
ARIMA侧重于数据自相关的描述。它通过学习历史需求随着时间变化的模式而预测未来。简单ARIMA通常包含三个重要的参数ARIMA(p, d, q)。p是数据的自回归项,d是差分阶数,q是相应的移动平均项数。
如何确定参数呢?首先,我们确定差分阶数d。那么为什么要做差分呢?差分的目的是让数据更加平稳(detrend),以便做自相关和移动平均,如图所示,分别为原数据,一阶差分和二阶差分。二阶差分后我们可以看到数据趋于平稳。类似的情况,我们可以选择d = 2。p和q可以分别通过偏自相关图和自相关图获得。同时,现在R和python都可以支持获取最优ARIMA参数。
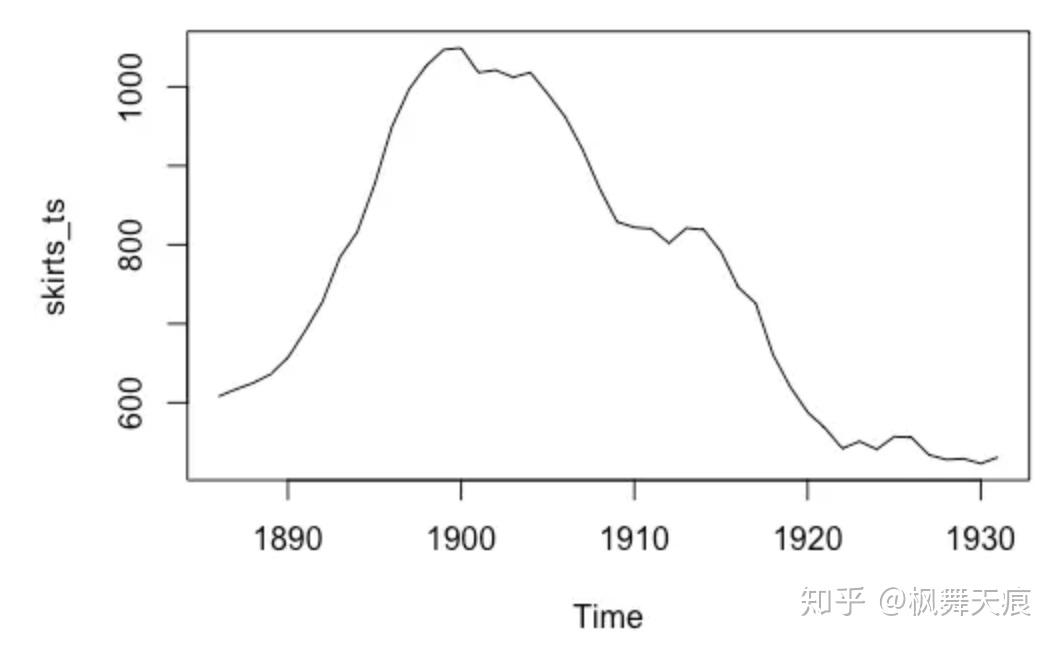 a. 原数据
a. 原数据 b. 一阶差分
b. 一阶差分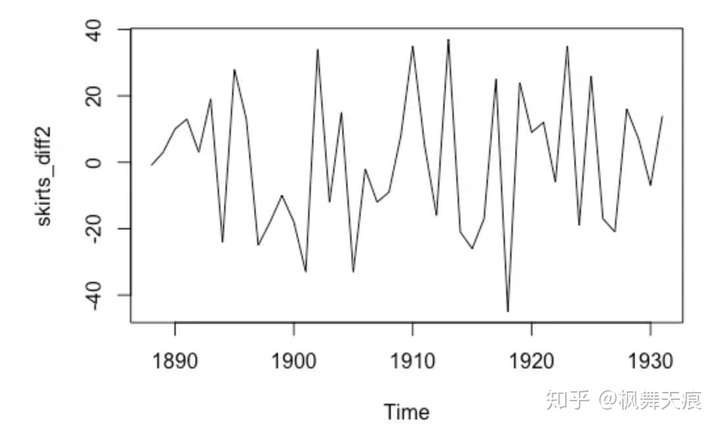 c. 二阶差分
c. 二阶差分
ARIMA适用于预测有明显时间周期规律的数据,不支持极端的需求预测。
Holt-winters
Holt-winters是指数平滑方法中的一种,一般指三次指数平滑,三次分别是针对基准水平(level, ),趋势(trend,
)和季节性因素(seasonal component,
)。基于不同的季节性因素表现,Holt-winters有叠加(additive)和叠乘(multiplicative)两个版本。如果季节性因素在数据上表现稳定,选用叠加的方法。如果季节性因素的表现和序列基准水平成正比,选用叠乘的方法。
叠加的模型:
叠乘的模型:
Holt-winters也是适用于有规律性的时间序列数据。
树模型
采用机器学习方法进行需求预测,树模型现在已经成了大家的首选,比如XGBoost, LightGBM, CatBoost等。在用树模型预测时,我们可以把时间序列的特征加入模型(可以考虑使用python package [tsfresh](https://tsfresh.readthedocs.io/en/latest/)),用于时间序列数据的预测。另外也可以考虑对某些维度进行分别建模,比如周一建个模型,周二建个模型,节假日建个模型等。树模型在各类时间序列预测的比赛上已经大显神通,但是它存在几个缺陷:
- 不能extrapolate,无法预测历史上不存在的数据范围
- fine tuning需要仔细,涉及的参数较多
案例研究
本章主要讲述一些需求预测的案例和研究,比如Amazon的SKU预测,和Uber的打车需求预测。
Amazon Probabilistic Forecast
Amazon在2017, 2018以及2019分别在Probabilistic Forecast的需求预测方向上发表了3篇论文,涉及的模型简称为:DeepAR,MQ-RNN和Deep Factors Model,以及围绕Probabilistic开发了基于AWS和MXNet的Gluon。
与直接去预测未来具体的需求值不同,概率预测(Probablistic Forecast)预测未来需求值的分布或者置信区间。概率预测的出发点是需求预测是为补货服务的。得到具体的预测值后,补货需要在预测值上加安全库存。以往的补货的安全库存基于简单的需求正态分布假设,而概率预测中基于过去的数据拟合了更好的概率分布,更好地服务于补货。以下阐述DeepAR,MQ-RNN和Deep Factors三个模型的一些细节。
DeepAR:Deep Autoregressive Recurrent Neural Networks
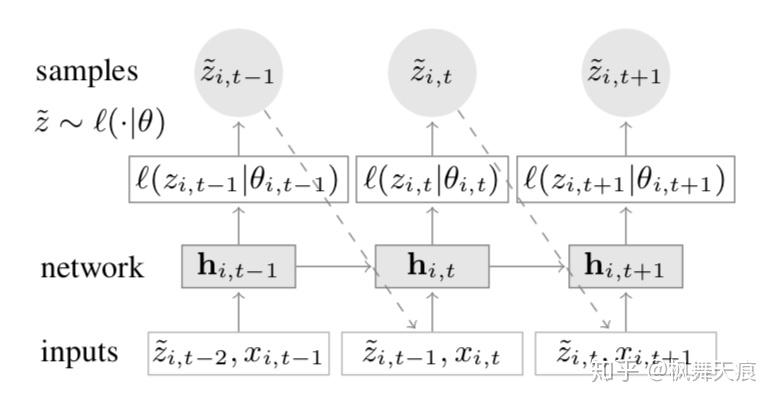 图 4 DeepAR模型图解
图 4 DeepAR模型图解
DeepAR的基础是RNN(大多数情况下,我们使用LSTM)。如图所示,在时间步 时,我们输入
时间步第
个时间序列对应的特征
,以及前一时间步
,第
个时间序列的需求值
。在训练时,输入的是真实的
的需求值。在预测的时候,
通过极大似然函数进行估计
。特征和需求值构成组合向量输入到RNN里面,得到隐向量(
)。通过隐向量计算分布的平均值和方差,计算极大似然估计。那么如何计算极大似然估计呢?通常来说,如果是连续型数值的需求量的话,我们假设为高斯分布。
这里对方差的处理采用soft-plus activation,主要也是避免方差为0的情况。对于一些计数型的需求预测,我们可以假设为负二项分布。
负二项分布的参数都通过soft-plus激活函数保证是正数。与高斯分布计算方差不同,负二项分布计算 。
是形状参数(shape parameter),对方差进行scale。作者发现这个形状参数的加入能够加速模型的收敛。
既然是预测未来需求的分布,且采用的极大似然估计,那么我们的目标函数变为最大化我们的似然函数,相应的模型训练的损失函数可以确定为 :
如果用DeepAR预测Multi-Horizon的数据,由于后面的预测值依赖于前面的预测值,所以有时很难保证可以得到很好的效果。因此,通常需要多次预测取平均和不同分位数的结果。
和大多数预测有所不同的是,DeepAR在模型训练的损失函数和最终结果评价的函数是不同的。模型的目标是拟合需求的分布,结果评价是需要量化数值的准确性。对于不同模型在同一数据集上结果对比,文中主要提到了RMSE和Quantile Loss。对Quantile Loss进行说明,给定输入的分位数,和跨度(Span)[L, L+S) 其中L是预测起点后的某个时间点,S是跨度。Quantile Loss就是在给定分位数和跨度范围的情况下,计算损失。公式如下:
最终的quantile loss是归一化后的结果。比如给定 ,跨度[0, 8),计算在给定跨度范围内不同模型的预测值和真实值quantile loss的比较。
MQ-RNN: Multi-Horizon Quantile Recurrent Neural Network
这篇的主要思想是近期数据预测接下来某段时间的数据,模型训练和选择的训练时窗和预测时窗有关。如,输入 的数据,输出t1到
,其中
。比如,用3月的数据训练,预测4月的需求。
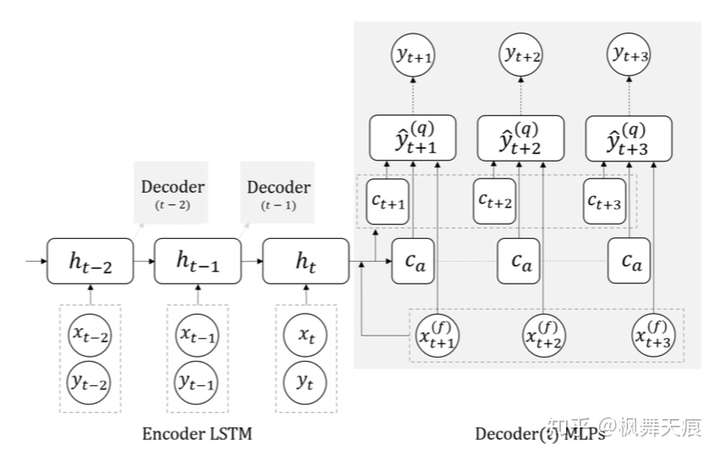 图 5 MQ-RNN模型图解
图 5 MQ-RNN模型图解
MQ-RNN的模型结果类似Sequence-to-Sequence,分成Encoder和Decoder,只是Decoder不是一个LSTM的模型。整体的流程如下:
输入: 的实际需求值y进行embedding,然后和特征向量x构成组合向量作为encoder LSTM的输入。文中还提了不同的encoder方法,并进行了比较。
Decoder涉及两个MLP (Multi-layer Perceptron)。 第一个MLP,称为global MLP,整合encoder输出的隐向量,外加未来的features。
,
是horizon-specific contexts,
是horizon-agnostic contexts。horizon-specific contexts包含未来时间点的信息,horizon-agnostic contexts抓住的是共有信息。
第二个MLP,称为local MLP,参数在horizon上是共享的。Local MLP输出对应Quantiles的预测值。比如t+k时间点对应的各个quantiles值
由上可知,模型训练的损失函数为Quantile Loss。
其中, 是 quantile为q的计算公式,和前面DeepAR的雷同。
MQ-RNN对于DeepAR有较大的改进,直接输出不同的quantile的预测值,目标函数改为quantile loss,文中举例说明可以解决一下冷启动和大促的离群点的预测。但是MQ-RNN需要确定时间窗口。比如通常我们要预测下个月每一天的,我们会采用历史所有数据进行训练和验证。MQ-RNN的训练数据可能固定使用一个月的,一个季度的或者一年的,这样的方式可以缩减训练时间,但是需要通过其它方式确定选取较优的训练时间窗口大小。
Deep Factors Model
Deep Factors Model的思想是把导致结果的因素分为随机因素(random effect)和固定因素(fixed effect)。两种因素分别由不同的模型估计,然后耦合在一起得到最终的预测值。
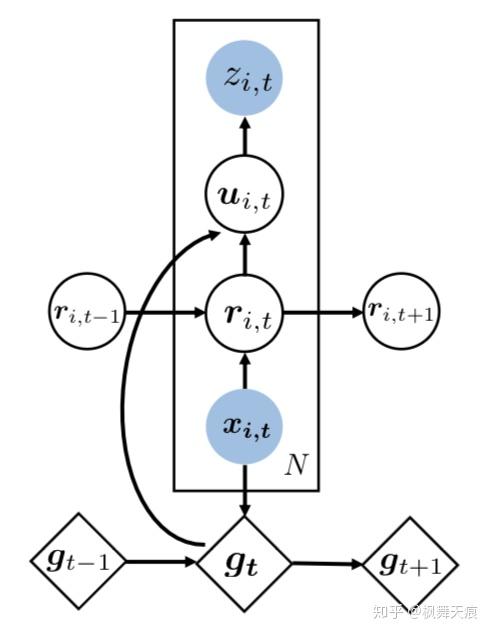 图6 Deep Factors
图6 Deep Factors
Global Effects类似于MQ-RNN的horizon-agnostic contexts部分,想要抓住数据中共有属性的部分。比如,global factors抓住整体数据的增长/下降趋势。它是K个RNN输出latent global deep factors的线性组合。
这里说明一下,大多数LSTM,包括DeepAR和MQ-RNN,我们的做法是先把输入进行embedding后导入LSTM中,但在deep factors中embedding放在了RNN的结果输出后。文中指出这样可以减少方差且提高数据的使用效率。
Random Effect随机因素,类似于MQ-RNN的horizon-specific contexts的部分,想要抓住local的部分。比如,数据在某小段时间内的波动和起伏:
对于随机因素的建模,文中建立了不同Local模型,如DF-RNN,DF-LDS和DF-GP
最终,如何得到我们的预测值呢?我们假设可以叠加global factors和random factors的输出。
其中,p可以是不同的需求分布假设,如高斯分布,负二项分布,泊松分布等。模型的损失函数,与DeepAR一致,评价标准为Quantile Loss。
Amazon的三个模型属于Probablistic Forecast,支持多个时间序列一起预测,可以解决一些SKU的冷启动问题(多个SKU时间序列一起学习,并加入了产品属性特征),更适用于一些有周期性的数据。
Uber Extreme Event Forecaster
Uber的应用是极端事件预测的一种方法。文中主要阐述特殊事件引起的需求巨变,如感恩节,圣诞节,存在大型欺诈事件等。主要的思想是把Uncertainty,分为model uncertainty和forecast uncertainty。模型结构如图7。模型的不确定性通过LSTM autoencoder来学习估计,同时autoencoder起到feature extraction的重要作用。选取模型的中间层输出作为forecaster的部分输入。forecaster用于估计预测的不确定型。整体的模型结构进行分离异步学习。文中指出去掉autoencoder部分,直接把feature extraction加入forecaster也是可以的,但是作者的经验是分离的结构有更好的效果。
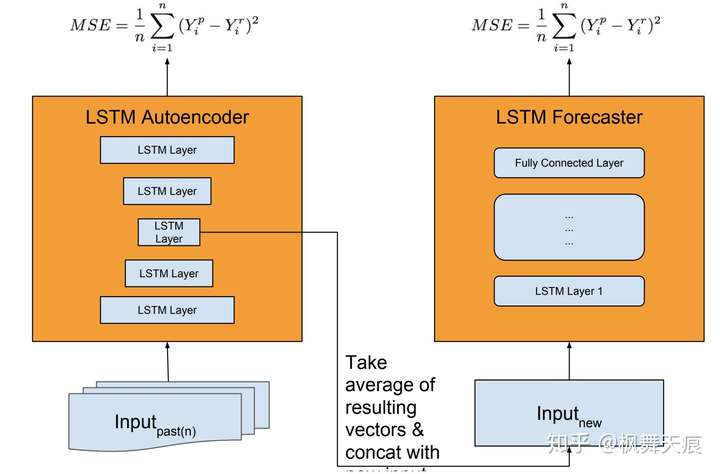 图7 Uber Extreme Event Forecaster模型结构
图7 Uber Extreme Event Forecaster模型结构
模型评价标准是SMAPE,损失函数如图7,为MSE。
Uber经验
预处理:
- 训练数据和测试数据要用相同的预处理方式
- 对处理可以先做去趋势处理(detrending, de-seasonaling)
- 对输入特征进行归一化(Standard/MinMax Scaler)以及对y值进行log scale后会加速训练
模型结构:
- 时间序列越长,dropout的效果越明显
- dropout作用在激活函数上,别用在权重参数上。而正则项用在权重参数上,而不要用在激活函数上。
简单模型/深度学习:
- 短期且不相关的时间序列数据,数据量不大
- 已知已经可以实现很好效果的传统模型
- 解释性强
深度学习更适用于:
- 有很多时间序列,且时间序列够长
- 有潜在的相关关系
- 解释性不重要
- 前沿技术探索和研究
什么是可预测性(forecastability)?
通常业务人员或者一些做模型算法的工程师,在拿到需求数据后就直接上各种模型尝试,调参,优化。花大量的时间在提升一些实际上无法预测的SKU的预测准确性,而且不能帮助下游控制风险。比如,一些SKU量级小,且自身原因需求波动大,预测无法达到很精确。针对于不同的SKU有时候要甄别可预测性。
可预测性即某种SKU/产品可以通过数据建模进行预测,且能够达到一定的准确性。那么不同的SKU存在不同的可预测性。比如某个SKU预测准确性最多达到30%,那么可不可以说这30%是好的呢?怎么证明这30%也是好的呢?
其实,如果我们能够在提供SKU准确性的同时,提供变异系数(CoV,Coefficients of Variation),那么会对需求预测的下游部门控制风险有很大帮助。变异系数是衡量模型预测稳定性的指标。公式如下,同一时窗大小不同时间范围,准确率的方差/准确率的平均值:
通常不存在预测准确性低,变异系数也低的情况。如果出现了,那么准确率应该是在上下波动,导致方差偏大。准确率低,但是有稳定的变异系数,可以帮助下游管控风险,满足供应率。
Amazon代码实践
针对Amazon的三篇论文,结合自己的理解,进行了编码实践。如果有误,欢迎大家指正。也希望和大家有所交流。
jingw2/demand_forecastgithub.com
参考文献
- 简单预测方法总结:https://skubrain.com/docs/demand-forecasting/forecasting-algorithms/
- 时间序列方法总结:https://zhuanlan.zhihu.com/p/67832773
- ARIMA介绍:https://www.jianshu.com/p/f547bb4b50c3
- Holt-winters介绍:https://otexts.com/fpp2/holt-winters.html
- Gradient Boosting Regression Tree:https://orbi.uliege.be/bitstream/2268/163521/1/slides.pdf
- DeepAR: https://arxiv.org/abs/1704.04110
- MQ-RNN:https://arxiv.org/abs/1711.11053
- Deep Factors Model: https://arxiv.org/pdf/1905.12417.pdf
- Amazon Demand Forecast Tutorial KDD 2019: https://lovvge.github.io/Forecasting-Tutorial-KDD-2019/
- JD Tutorial KDD 2018: http://www.aigsic.com/kdd_2018_raas.html
- Uber Extreme Event Paper ICML 2017: http://roseyu.com/time-series-workshop/submissions/TSW2017_paper_3.pdf
- Time-Series Modeling with Neural Networks at Uber: https://forecasters.org/wp-content/uploads/gravity_forms/7-c6dd08fee7f0065037affb5b74fec20a/2017/07/Laptev_Nikolay_ISF2017.pdf
- How to gause forecastability?: https://demand-planning.com/2018/03/20/how-to-gauge-forecastability/