https://www-file.huawei.com/-/media/corporate/pdf/cyber-security/ai-security-white-paper-cn.pdf
HW AI安全白皮书
谷歌可解释人工智能白皮书,27页pdf,Google AI Explainability Whitepaper
【导读】近几年,随着人工智能的迅速发展,人工智能对各行各业也产生了深远的影响。围绕人工智能建立的系统已经对医疗、交通、刑事司法、金融风险管理和社会的许多其他领域产生了巨大的价值。然而,人工智能系统仍然具有很多问题,为了保证人工智能系统的有效性和公平性,需要我们对人工智能具有深刻的理解和控制能力。所以,今天专知小编给大家带来的是Google可解释人工智能白皮书《AI Explainability Whitepaper》,总共27页pdf,主要介绍谷歌的AI平台上的AI的可解释性。
机器学习发展
人工智能的迅速发展导致现在我们现在所研究和使用的AI模型越来越复杂化,从手工规则和启发法到线性模型和决策树再到集成和深度模型,最后再到最近的元学习模型。
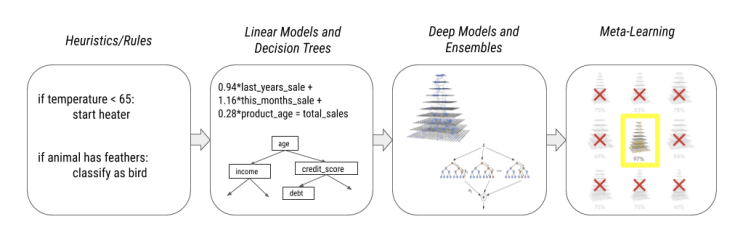
这些变化已经导致了多个维度上规范的变化:
-
可表达性(Expressiveness),使我们能够在越来越多的领域(如预测、排名、自主驾驶、粒子物理、药物发现等)拟合各种各样的功能。
-
通用性(Versatility),解锁数据模式(图像,音频,语音,文本,表格,时间序列等),并启用联合/多模式应用。
-
适应性(Adaptability ),通过迁移学习和多任务学习来适应小数据状态。
-
效率(Efficiency ),通过自定义优化硬件,如gpu和TPUs,使研究人员可以更快地训练更大更复杂更强大的模型。
然而,这些更复杂更强大的模型也变得越来越不透明,再加上这些模型基本上仍然是围绕相关性和关联建立的,这导致了以下几个挑战和问题:
-
虚假的关联性(Spurious correlations),这往往会妨碍模型的泛化能力,导致模型在现实场景下效果很差。
-
模型的调试性和透明性的缺失(Loss of debuggability and transparency),这会导致模型难以调试和改进,同时这种透明度的缺乏阻碍了这些模型的应用,尤其是在受到监管的行业,如银行和金融或医疗保健行业。
-
代理目标(Proxy objectives),这会导致模型在线下的效果与实际场景下的效果存在很大的出入。
-
模型的不可控(Loss of control)
-
不受欢迎的数据放大(Undesirable data amplification)
AI方法有:
-
简单(基于规则且可解释)
-
复杂的(不是可解释的)
根据应用不同,我们有明确的伦理、法律和商业理由来确保我们能够解释人工智能算法和模型如何工作。不幸的是,普通人可以解释的简单人工智能方法缺乏优化人工智能决策的准确性。许多提供最佳精度的方法,如ANN(人工神经网络),都是复杂的模型,其设计并不是为了便于解释。
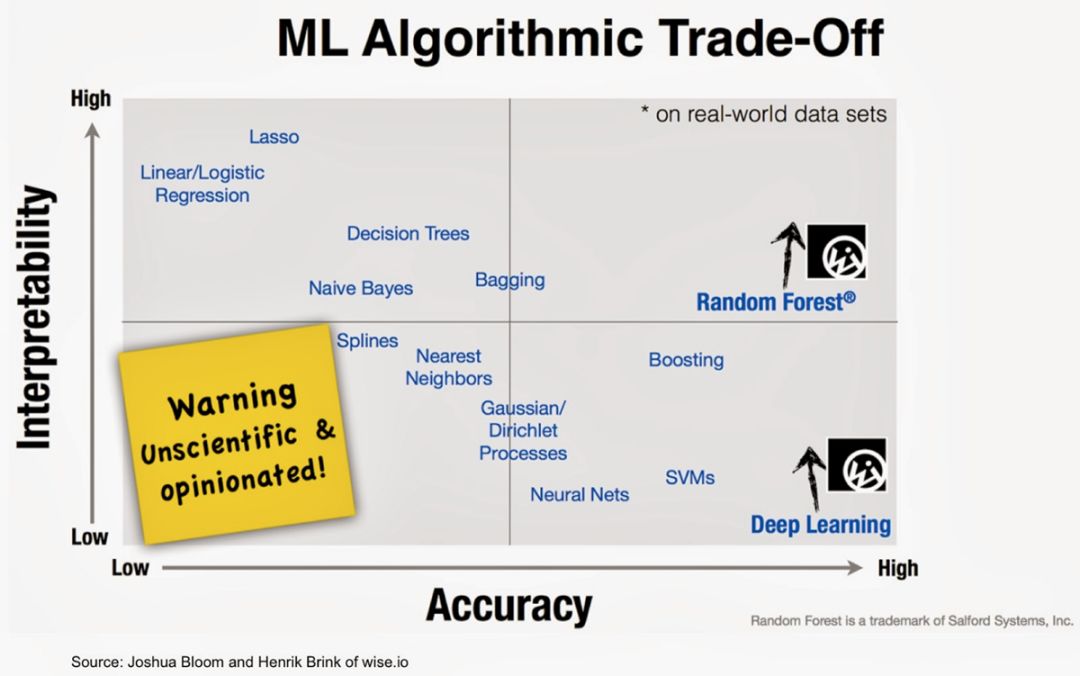
如图所示,人工智能方法的准确性和可解释性之间存在着一种相反的关系。两者之间的负相关关系如下: 解释性越大,准确性越低,反之亦然。
一些不太精确的模型仍然很受欢迎,因为它们具有可模拟性(因此人类可以重复它们)、完全可解释的计算过程(算法透明性)以及模型的每个部分都有一个直观的解释(可分解性)。
随着深度学习和强化学习的普及,对复杂神经网络的解释需求激增,推动了XAI工具的发展。最终目标: 实现负责任的、可追溯的、可理解的AIs。
可解释人工智能 XAI
这些挑战突出了对人工智能的可解释性的需求,以使人们可控的发展人工智能。
围绕人工智能建立的系统将影响并在许多情况下重新定义医疗干预、自动交通、刑事司法、金融风险管理和社会的许多其他领域。然而,考虑到上一节所强调的挑战,这些人工智能系统的有效性和公平性将取决于我们理解、解释和控制它们的能力。
自从几十年前专家系统出现以来,XAI(可解释的AI)领域已经复苏。本文对一种严谨的科学解释的机器学习,Doshi-Velez和Kim定义为“解释性或呈现在人类可以理解的术语的能力“利用韦氏字典的定义“解释”,它适应人类和智能代理之间的交互。
谷歌的人工智能可解释白皮书(AI Explainability Whitepaper)是谷歌云的人工智能解释产品的技术参考。它的目标用户是负责设计和交付ML模型的模型开发人员和数据科学家。谷歌云的可解释产品的目标是让他们利用对AI解释性来简化模型开发,并解释模型的行为。

白皮书的目录:
-
特征归因(Feature Attributions)
-
特征归因的限制和使用注意事项(Attribution Limitations and Usage Considerations)
-
解释模型元数据(Explanation Model Metadata)
-
使用What-if工具的可视化(Visualizations with the What-If Tool)
-
使用范例(Usage Examples)
参考链接:
https://cloud.google.com/ml-engine/docs/ai-explanations/overview
人工智能的下一个挑战 —— 可解释性和可诠释性?
作者: Sashi Obilisetty, 新思科技 R&D 总监
“It’s not a human move. I’ve never seen a human play this move(这不是人类的下棋策略。我从来没见过任何人这样下棋。)”
2016年,谷歌AlphaGo挑战世界上最伟大的围棋选手之一,李世石,当AlphaGo最终击败世石,取得决定性胜利时,另一位围棋专家樊麾如此评论道。
樊麾的这句经典点评,恰恰反映了我们正在使用超精确的机器学习(ML)模型时所面临的问题。尽管这些模型展示了超越人类的能力,但我们尚不确定输入的数据中的哪些具体信息,使它们做出决定。深度学习模型通常包含深度嵌套的非线性结构,使其变得不那么透明。缺乏透明度, 对AlphaGo本身来说不是问题。然而,在可解释性(explainability)、可诠释性(interpretability)和透明度至关重要的领域(如医疗诊断、军事和战斗行动)中,模型的不透明性则大大阻碍了AI/ML的扩展。
在人工智能和机器学习中,可解释性(explainability)和可诠释性(interpretability)经常互换使用。然而,这两者之间有一个细微的区别。可解释性是关于理解为什么某些事情发生的机制,而可诠释性是关于如何用人类的术语很好地来说明白这些机制。可诠释性的研究目前发展迅速;但有很多还需要做。

ML模型中精确度和可解释性之间的权衡,神经网络是最缺乏解释性的。
解决方案:
上图所示,经典的机器学习算法(如线性算法或基于树的算法)的可诠释性很好。而现有的模型不可知方法可分为5大类:
- 可视化(Visualizations): 提高模型可诠释性的常用可视化方法有:部分依赖图(Partial Dependenc Https://Christophm.Github.Io/Interpretable-Ml-Book/e Plots, PDP)、个体条件期望图(Individual Conditional Expectation , ICE)和累积局部效应图(Accumulated Local Effects , ALE)PDP和ICE可以用来显示特征对预测值的影响,特别是当关系是线性的、单调的(特征对目标的影响总是在同一方向,但不以恒定的速度)或更复杂的情况下。当特征互相关联时,ALE图则更有用(在这种情况下,PDPs不是很有用)。
- 基于特性的(Feature-based): 特征的交互和特征重要性也是了解模型的方法。H值 (H-statistic, 由Friedman提出的一种度量方法)是一种广泛应用于特征交互的度量方法。特征重要性的概念相当简单。特征的重要性是通过对特征值进行变更后,预测误差的增加来衡量的。若预测误差没有变化,说明该特性“不重要”。
- 代理模型:代理模型在许多工程领域都很常见。代理建模背后的概念是,如果测量输出值耗时且麻烦,我们可以使用更快的代理模型。在机器学习中,代理模型需是可诠释的机器学习模型。
Shapley Values(Shapley Values): Shapley技术博弈论(game theory)为基础。博弈论中的一个经典问题是,倘若玩家拥有不同的技能水平,他们将如何为总支出做出贡献。在机器学习中,支出是对单个实例的预测,而特征就是不同的玩家。非常坦白地说,个人认为Shapley值对于计算任何ML模型(不仅仅是线性模型)中特征对单个预测的贡献特别有用。 - LIME: LIME(Local interpretable model-agnostic explanations的缩写,局部保真可诠释的与模型无关的解释)背后的关键想法是,通过一个简单的本地模型来近似一个黑盒子模型,要比试图全局近似一个模型容易得多。LIME将模型视为一个黑盒子,对于每个感兴趣的实例,生成一个新的数据集,该数据集由变更后的样本和黑盒子模型的相应预测组成。这个经过更改的数据集构成了可诠释模型的基础,该模型通过采样的实例与目标实例之间的接近程度来加权。
然而,不是每一个上述方法都能对深度神经网络管用。
在今后, 我会讨论其他方法来提高卷积神经网络(CNN)和 循环神经网络(RNN)的诠释性。