确实“人话”解释清楚了 ^_^
池化不只有减少参数的作用,还可以:
不变性,更关注是否存在某些特征而不是特征具体的位置。可以看作加了一个很强的先验,让学到的特征要能容忍一些的变化。
防止过拟合,提高模型泛化能力
获得定长输出。(文本分类的时候输入是不定长的,可以通过池化获得定长输出)
提高感受野大小
参考知乎回答:https://www.zhihu.com/question/36686900
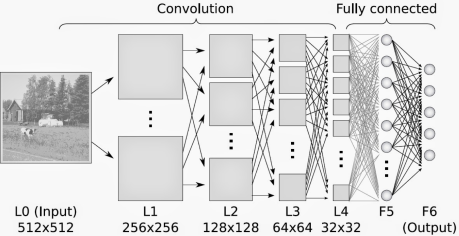
Pycon 2016 tensorflow 研讨会总结 — tensorflow 手把手入门, 用”人话”解释CNN #第三讲 CNN
上一期我们讲到Pycon 2016 tensorflow 研讨会总结 — tensorflow 手把手入门 #第二讲 word2vec . 今天是我们第三讲, 仔细讲一下CNN.
所讲解的Workshop地址:http://bit.ly/tf-workshop-slides
示例代码地址:https://github.com/amygdala/tensorflow-workshop
首先什么是CNN? 其实, 用”人话”简洁地说, 卷积神经网络关键就在于”卷积”二字, 卷积是指神经网络对输入的特征提取的方法不同. 学过卷积的同学一定知道, 在通信中, 卷积是对输入信号经过持续的转换, 持续输出另一组信号的过程.
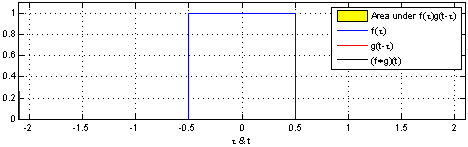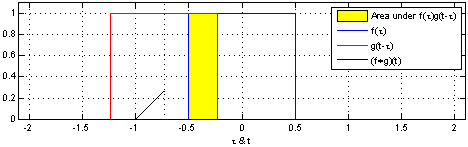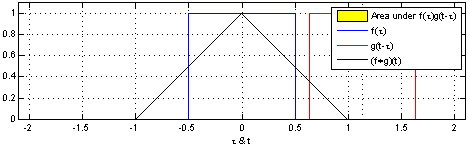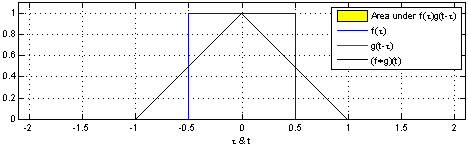
上图来自维基百科, 经过红色方框的持续转换, 我们关注红色方框和蓝色方框的重叠面积, 于是我们得到新的输出: 黑色线的函数. 这正是通过卷积生成新函数的过程.
CNN对输入的处理也是一样, 它把输入用块的单位提取特征, 这样高维的图片马上就降维了:
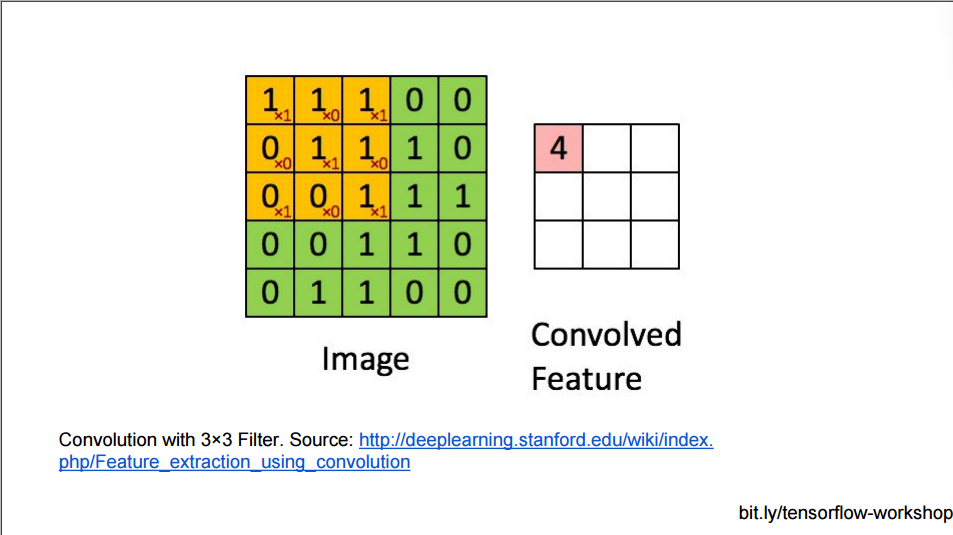
用黄色块提取特征, 上面的大方框, 最多可以提取9个黄色块的特征.
或者从神经网络连接结构的角度, CNN的底层与隐藏不再是全连接, 而是局部区域的成块连接:
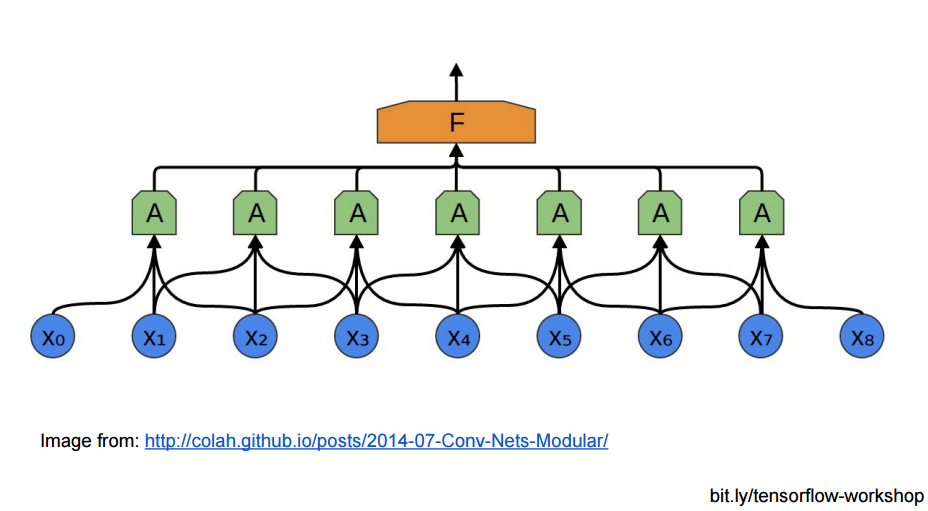
成块连接后, 那些小块, 还能在上层聚集成更大的块:
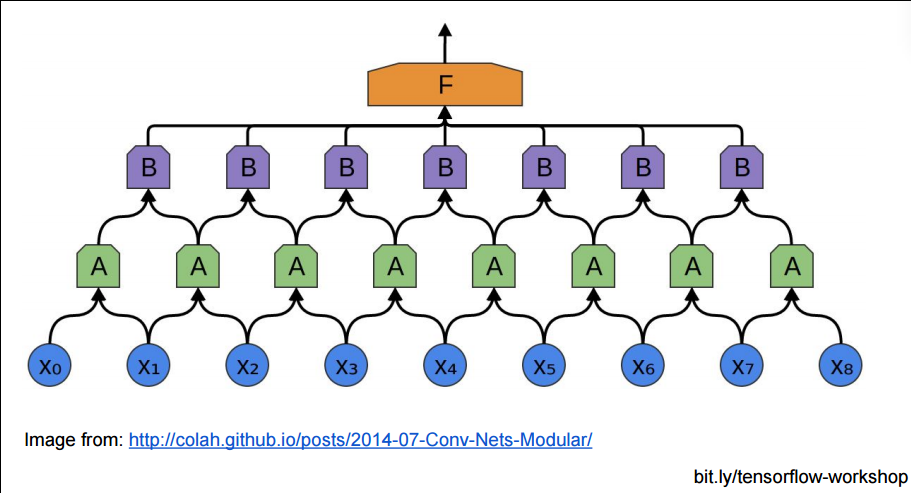
但是, 如果用上面的方法堆砌CNN网络, 隐藏层的参数还是太多了, 不是吗? 每个相邻块都要在上层生成一个大的块.
所以有时我们为了减少参数复杂度, 不严格把相邻的块都至少聚合成一个上层块, 我们可以把下层块分一些区域, 在这些区域中聚合:
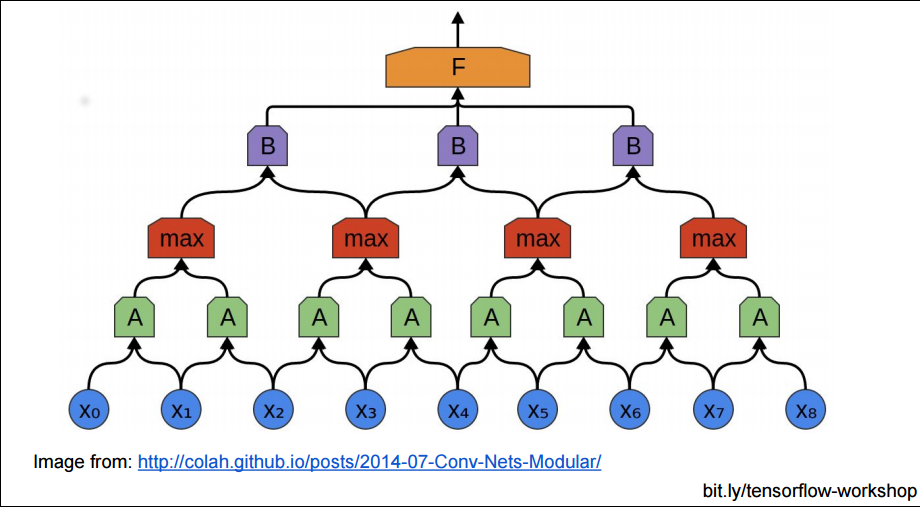
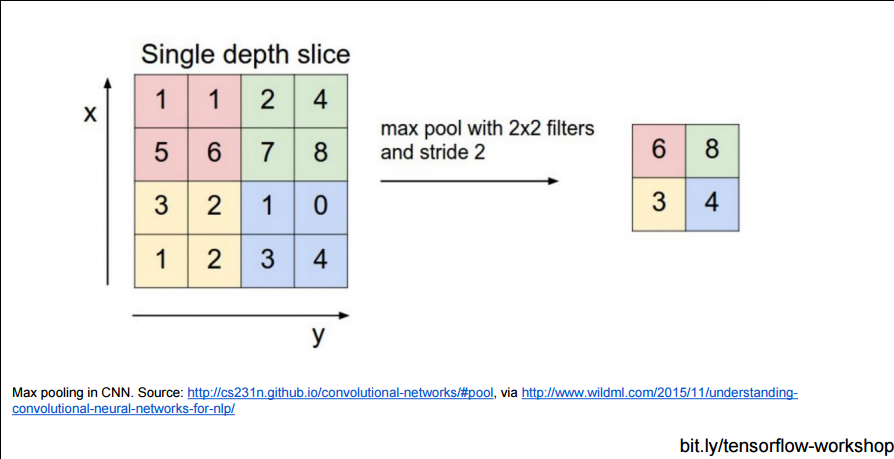
瞧! 这里的红色块的层与绿色块的连接, 是不是就没有原来的密集了? 这就是(Pooling Layer)分池层, 把小的块分割成一个个池子, 也就是大块:
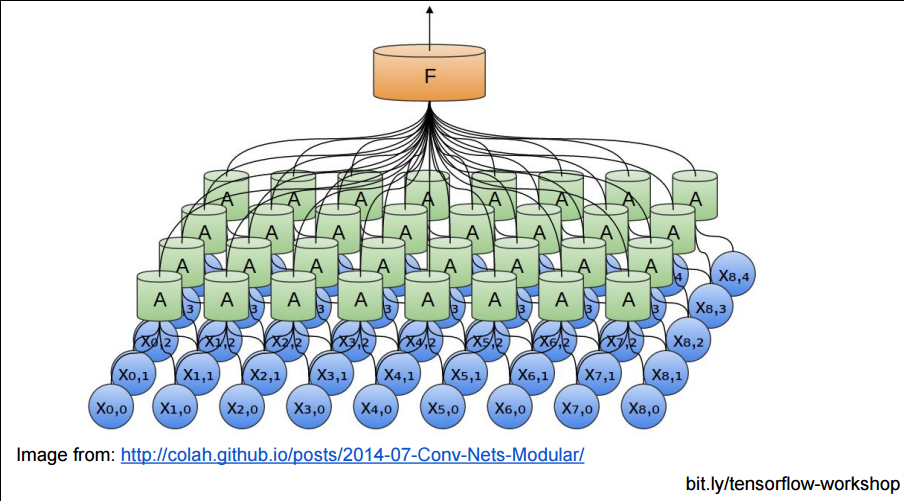
再来看看2D图片输入的CNN效果:
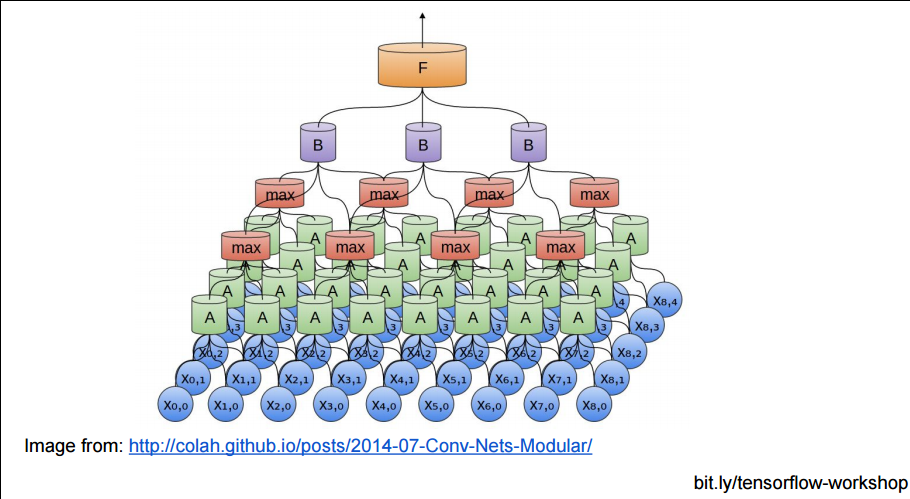
以及用了Pooling Layer的效果:
当然, CNN不仅可以使用在图片分析上, 也可以使用在文本分析上, 因为句子中邻近的单词总是有相关性的, 不是吗?
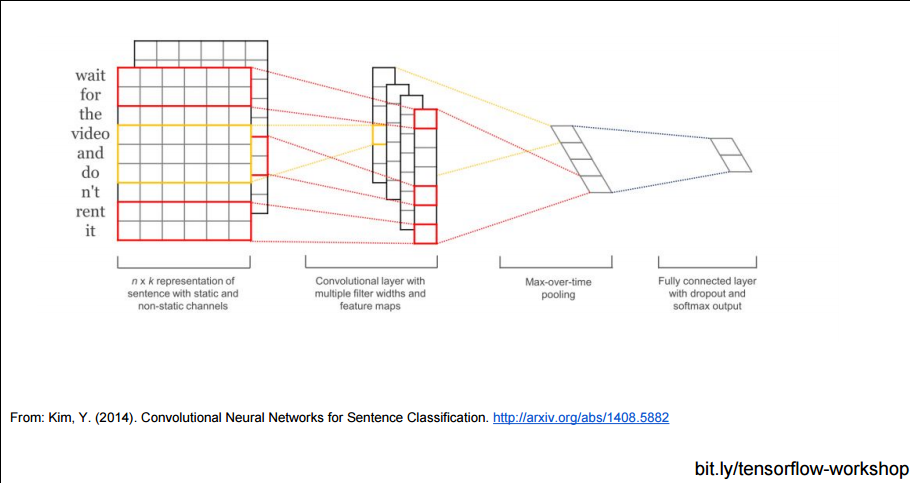
参考文献
重要的Tensorflow资料:
研讨会PPT下载:
研讨会视频:
https://www.youtube.com/watch?v=GZBIPwdGtkk
- Tensorflow backgroud 是一个官方的Tensorflow动画教程非常棒:http://playground.tensorflow.org/
- TFLearn:一个深度学习的tensorflow上层API库。https://github.com/tflearn/tflearn
- 一些Tensorflow模型的实现: https://github.com/tensorflow/models
GAN+增强学习, 从IRL和模仿学习, 聊到TRPO算法和GAIL框架, David 9来自读者的探讨,策略学习算法填坑与挖坑
如果你想成为大师,是先理解大师做法的底层思路,再自己根据这些底层思路采取行动? 还是先模仿大师行为,再慢慢推敲大师的底层思路?或许本质上,两种方法是一样的。 — David 9
聊到强人工智能,许多人无疑会提到RL (增强学习) 。事实上,RL和MDP(马尔科夫决策过程) 都可以归为策略学习算法的范畴,而策略学习的大家庭远远不只有RL和MDP:
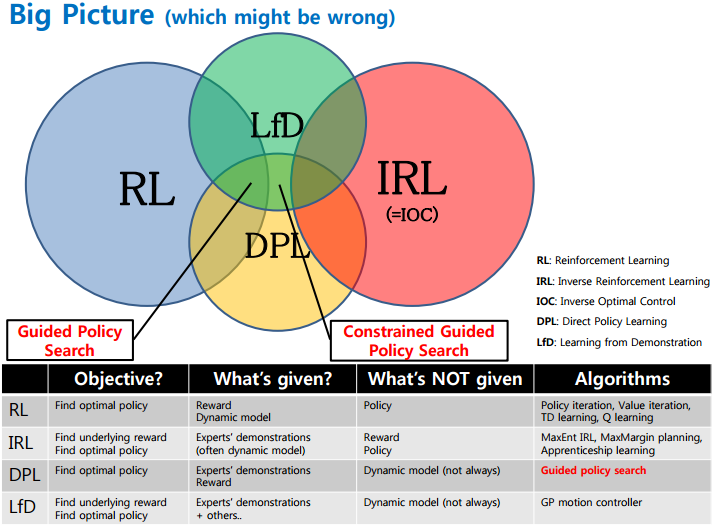 来自:https://www.slideshare.net/samchoi7/recent-trends-in-neural-net-policy-learning
来自:https://www.slideshare.net/samchoi7/recent-trends-in-neural-net-policy-learning
我们熟知的RL是给出行为reward(回报)的,最常见的两种RL如下:
1. 可以先假设一个价值函数(value function)然后不断通过reward来学习更新使得这个价值函数收敛。价值迭代value iteration算法和策略policy iteration算法就是其中两个算法(参考:what-is-the-difference-between-value-iteration-and-policy-iteration)。之前David 9也提到过价值迭代:NIPS 2016论文精选#1—Value Iteration Networks 价值迭代网络)
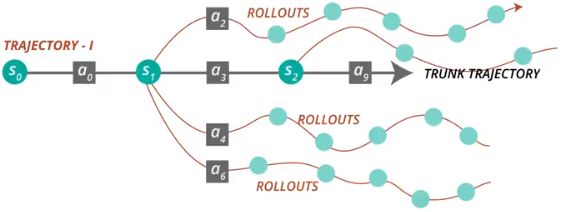 来自:https://www.youtube.com/watch?v=CKaN5PgkSBc
来自:https://www.youtube.com/watch?v=CKaN5PgkSBc
2. 可以先假设一个policy(没有价值函数 ),从这个policy抽样一连串的行为,
得知这些行为的reward后,我们就可以由此更新policy的参数。这就是DPL(Direct Policy Learning)(参考:Whats-the-difference-between-policy-iteration-and-policy-search)
以上两种方法最后都是为了学习到一个好的policy(策略,即状态->行为的映射),所以这些函数都可以归为策略学习算法。
除了这些,还有一种更有意思策略学习问题:如果没有reward(回报)的给出,只有专家(或者说大师)的一系列行为记录,是否能让模型模仿学习到大师的级别?(当然就目前的技术,我们需要大量的大师行为记录)。
这种类似模仿学习的问题就叫IRL(Inverse Reinforcement Learning或者逆向强化学习)。所以请再仔细看一下这些方法的区别:
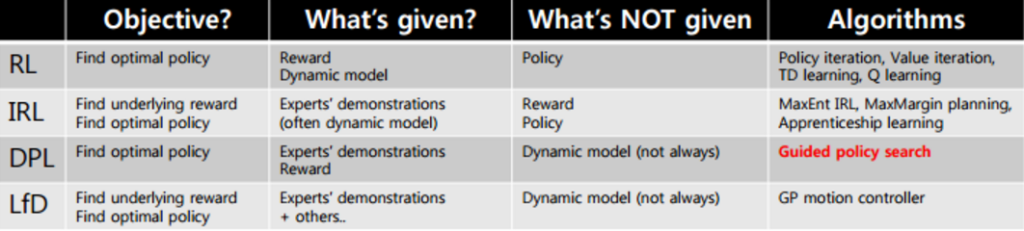 来自:https://www.slideshare.net/samchoi7/recent-trends-in-neural-net-policy-learning
来自:https://www.slideshare.net/samchoi7/recent-trends-in-neural-net-policy-learning
了解了这些大类,我们在回到RL,现在进入我们的正题TRPO算法(Trust Region Policy Optimization)。