美团对话理解技术及实践
阅读数:73892019 年 6 月 4 日 08:00
智能客服是一种使用自然语言与用户交互的人工智能系统,通过分析用户意图,以人性化的方式与用户沟通,向用户提供客户服务。
本议题首先介绍美团智能客服的对话交互框架,然后就我们在其中意图挖掘、意图理解、情绪识别、对话管理等核心模块中用到的机器学习算法进行详细的介绍。
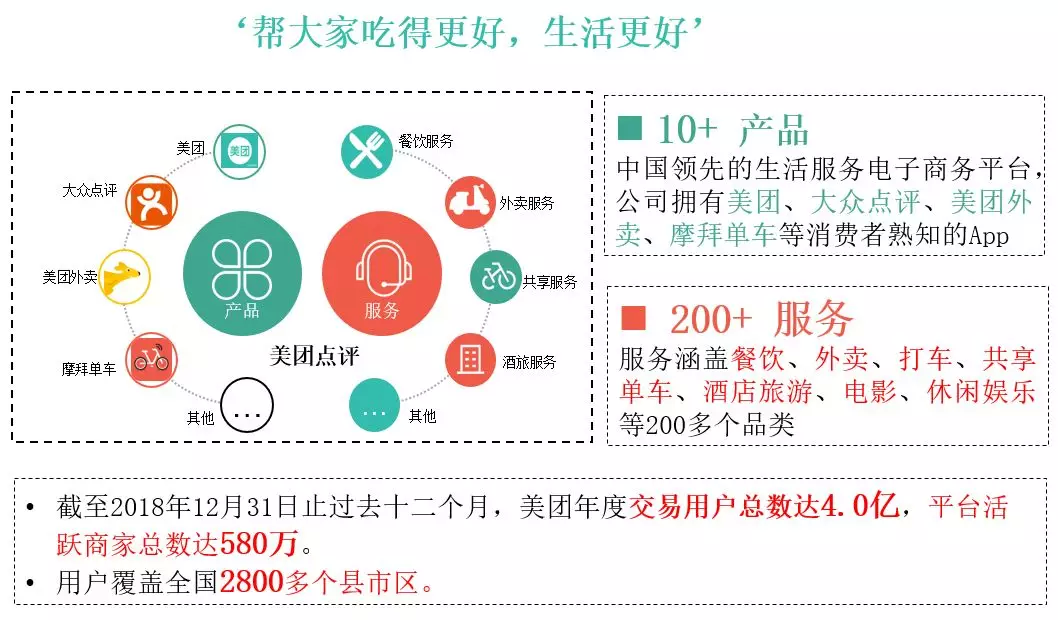
美团点评的使命是 " 帮大家吃得更好,生活更好 " 。美团线上服务的 APP 涵盖了生活服务方方面面,包括餐饮、外卖、打车、酒店业务等。2018 年全年美团的总交易金额达 5156.4 亿元人民币,同比增加 44.3%;2018 年美团单日外卖交易笔数超过 2100 万笔。美团的各个 APP 上具有大量的客服信息类的数据,这也为工程师提供了很好的练兵场。
一、智能客服对话框架
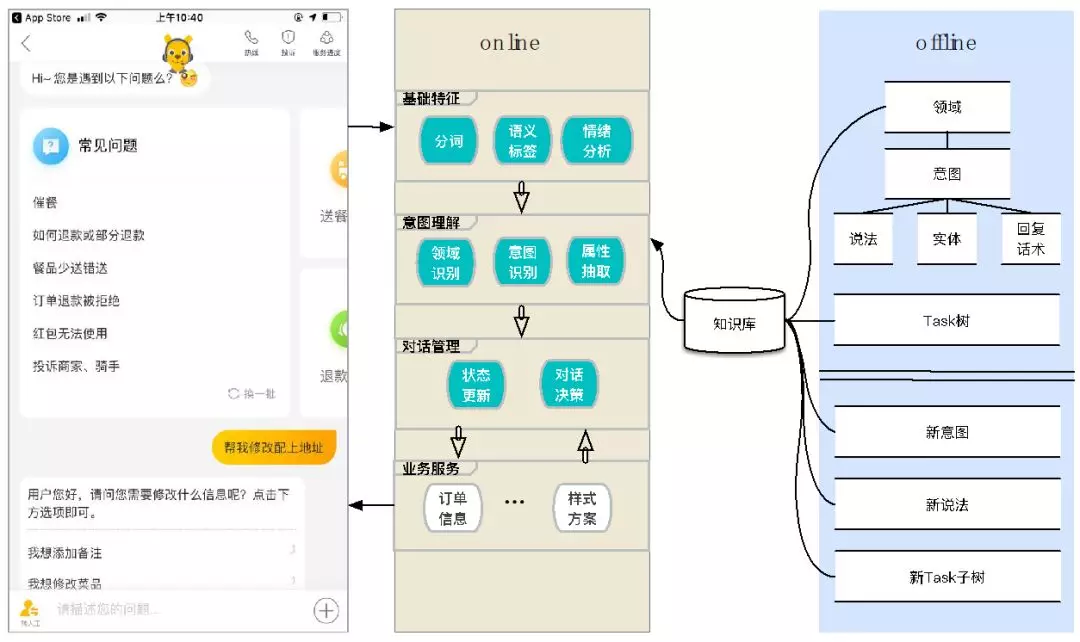
当用户进入到客服界面时往往是带着一个问题来的,那么我们需要做的就是对这个问题进行理解,然后根据理解结果去请求相应服务,去解决用户的问题。这里面主要分为两大块,一方面是离线训练和知识库整理部分,另一部分是在线处理部分。
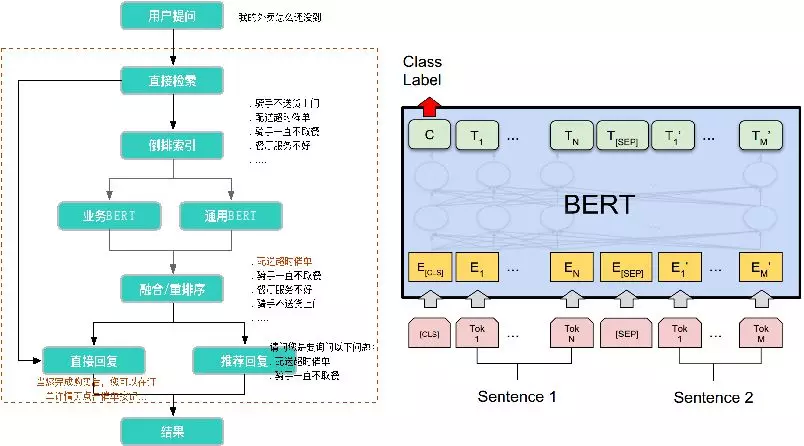
在在线部分,首先需要对问题进行基础特征的提取,比如:分词、语义标签抽取、情绪分析、NER 识别等;进而进入下面一层 - 意图理解层,主要有问题领域分类、意图识别和属性抽取;意图理解之后就进入到了对话管理这个阶段,对话管理模块主要包括两个部分,状态追踪 ( DST ) 和对话决策,DST 根据上下文状态明确当前用户的领域和意图,而对话决策模块则根据用户当前意图决定后续动作;再之下是业务服务层,包括各业务的数据服务接口以及业务数据呈现样式等。
二、意图理解
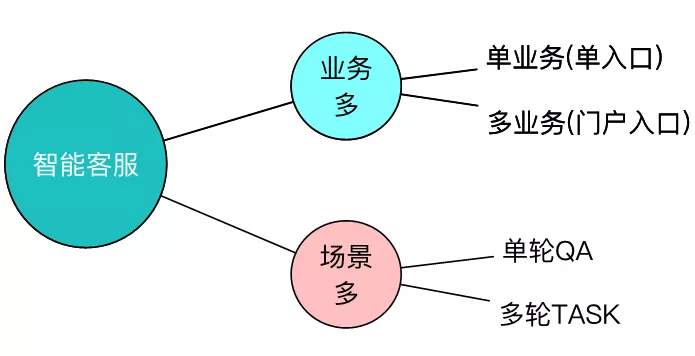
美团围绕着生活服务有着许许多多场景和业务,针对客服服务而言,用户可能是从单一的业务窗口进入到客服中,这时我们是知道该客服服务属于哪个领域;用户也有可能是从美团的综合门户入口进入到客服中,在这种情况下我们无法判断用户需要进行哪个业务领域方面的咨询。
除此之外,在场景方面,主要涉及单轮 QA 和多轮 Task,针对一些简单的问题,单轮的 QA 就可以解决,举个例子:
U: 美团送餐时间
S: 用户您好,能否配送是以商家营业时间为准的。如您所选的商家正在营业,便代表可以提供点餐及配送服务。
而大量复杂的业务通过单轮的 QA 是无法完成的,这时候就需要多轮对话,举个例子:
如何成为美团商家?
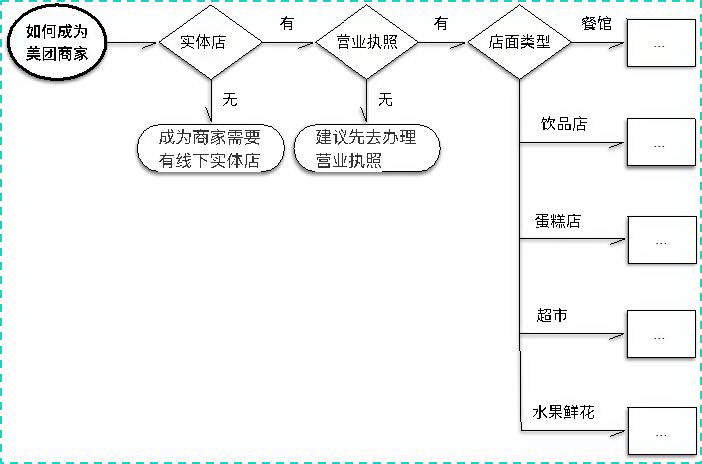
像这种就需要多轮的任务 Task 才能解决。
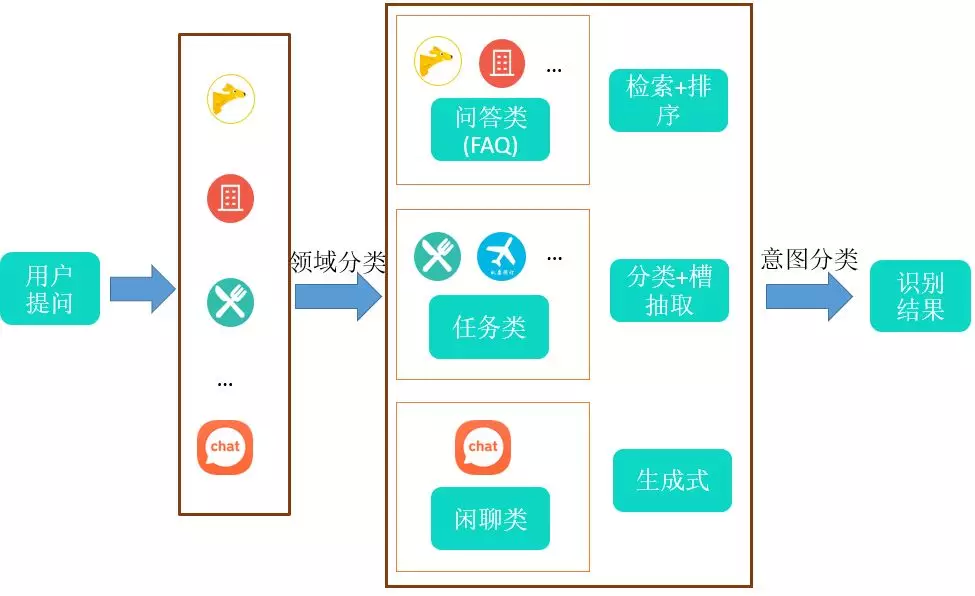
由于美团涵盖众多的业务领域,所以当用户提出一个问题时,我们首先要将这个问题进行领域分类,把它分到某个业务领域去,然后用业务知识去解决这个问题;领域明确后就是意图分类,根据问题的不同类别,比如问答类的、闲聊类的等,采用的方式也会有所差异。接下来将对这两个方面做详细介绍。
2.1 领域分类
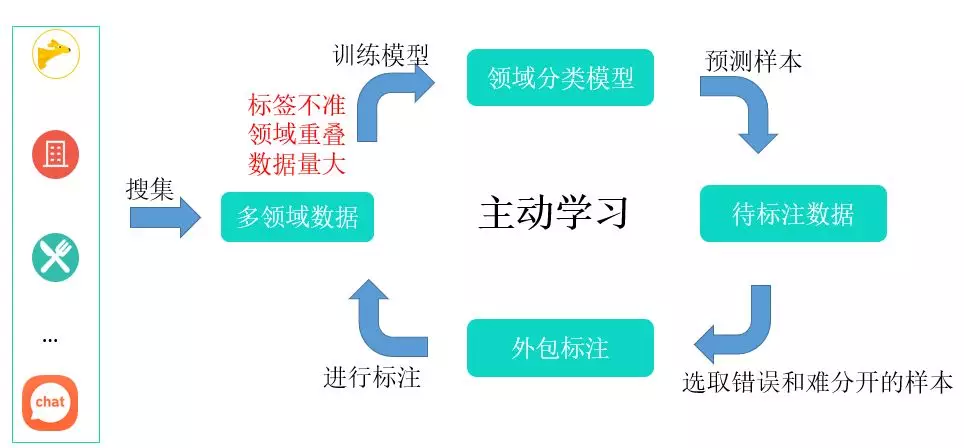
针对领域分类任务,如上图所示,我们首先会从不同的业务中收集大量的业务数据,作为基础的训练数据,虽然这些数据来自不同的业务,但是依然存在一些问题,主要有以下两方面:
- 标签不准:用户有可能会在某个业务对话中提问其它领域的问题;
- 领域重叠:某些问题可能会在多个领域中出现。
所以,原始数据不能直接拿来作为训练数据,必须要经过人工筛选和标注方可使用。 为了节约人力成本和提高迭代速度,我们采用了主动学习框架,模型的迭代主要分为如下几步:
- 搜集业务数据,为每条业务数据打上相应的业务标签
- 对数据进行模型训练
- 将上步训练好的模型对样本进行预测
- 标注人员对预测样本进行标注,选出错误和难分开的样本
- 返回第 2 步,对标注好的数据重新进行训练
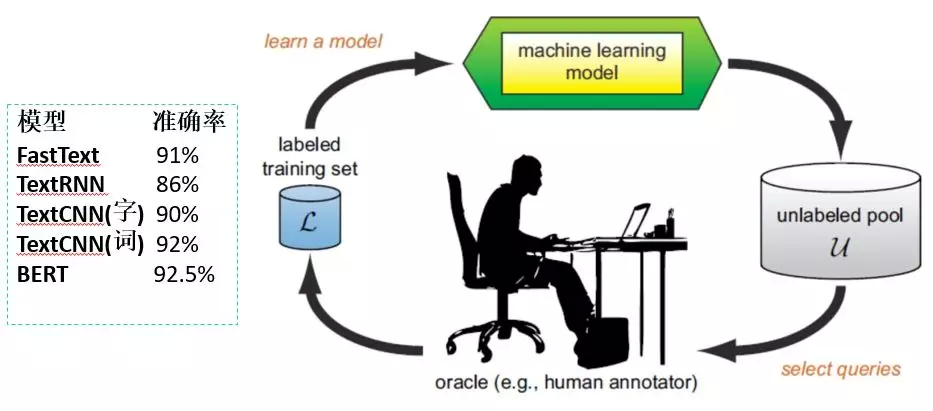
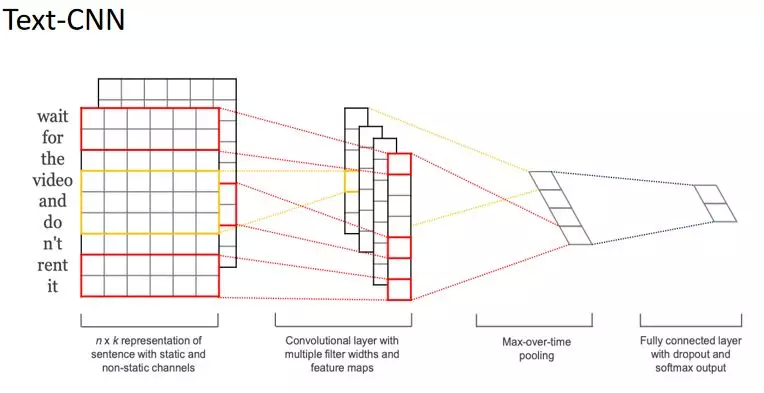
我们同时也在不同的模型上测试领域分类效果,实践中的各模型效果如上图所示。 从结果中我们可以看出,BERT 的效果是非常高的,但是呢我们也会考虑模型在实际运行中的效率问题。 对于一个 15 个字左右的 query 来说,用 TextCNN 模型在 10ms 以内就可以解决,如果用 BERT 模型的话可能需要 70ms 左右,这个时间还是比较长的,当前实际上线的时候我们采用的是 TextCNN 模型。 这是 2014 年 Yoon Kim 提出的一种方法。
2.2 意图分类
针对意图分类,主要包括问答型意图理解和任务型意图理解两个方面。
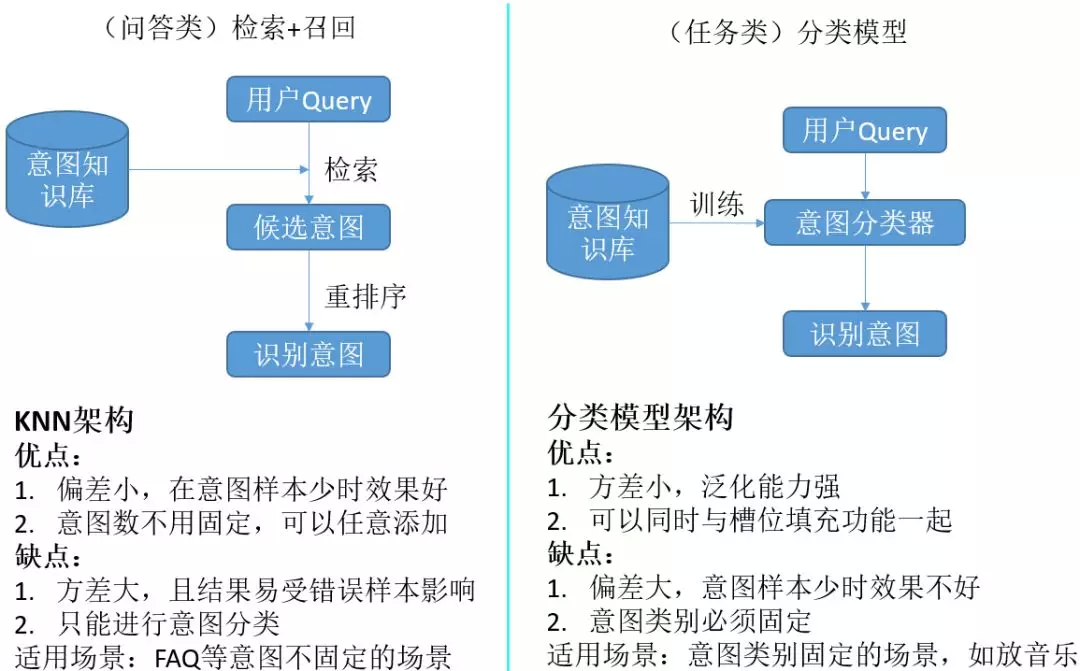
这两类问题有着各自的特点,针对问答类,我们采用检索和相似度排序的策略,下图是问答类的设计架构。
针对任务型的意图理解,我们采用规则和模型结合的方式,一种是通过规则的方式,比如上下文无关文法,另一种是采用模型训练的方式。
上下文无关文法

上图就是其中一个例子,在工业界这种方式还是非常通用的,对于问题冷启动,高频出现的问题和常规的问题,采用规则的方式能够很好的解决。
多任务学习模型
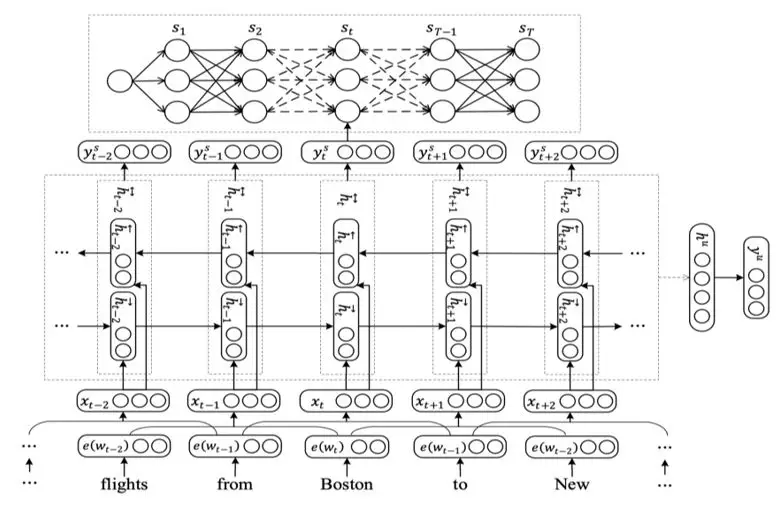
模型部分我们把意图分类和属性抽取联合建模,作为一个多任务学习 ( Multi-task Learning ) 任务,如上图所示 ( 算法详见 Zhang, Xiaodong 2016IJCAI ) 。双向 LSTM 处理后,一方面会通过 softmax 分类输出意图多分类的结果 ( 右边的 y^u );另外通过 CRF 层,标记每一个词的槽位标签。具体来说,对于 " 帮我找一家明天中午适合 10 人聚餐的川菜馆 ",模型应该能识别出来它是属于订餐意图,同时又能够抽取出时间 " 明天中午 " 、人数 " 10 " 和口味菜系 " 川菜 " 等属性信息。
2.3 对话状态追踪 ( DST )
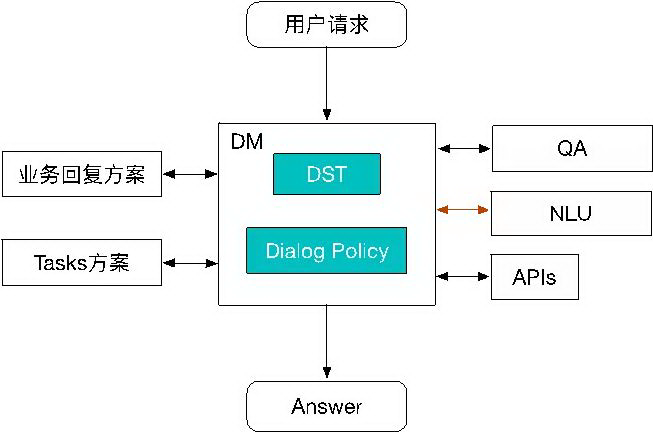
DST 解决的还是一个意图的问题,根据当前上下文的环境或者状态来明确当前用户的确切意图。
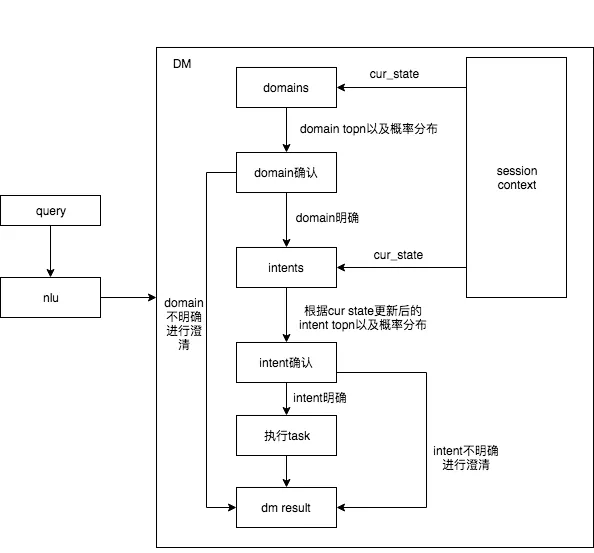
上图是我们当前的框架,这个 session context 为上下文信息,NLU 模块的输出信息可能是多个意图,我们需要根据其他的一些信息,比如,订单信息、门户信息,入口信息等,结合 session context 去明确它是属于哪个领域。
如果这个领域不能明确怎么办?我们的做法是会跟用户进行一轮的澄清,反问用户一次,来解决这个问题,也就是框架最左边的 " domain 不明确进行澄清 " 逻辑。
领域一旦明确后,下一步会进入到意图这一块,我们要明确它当前是什么意图,当然接收到的 query 也面临多意图判断的问题,同样我们也可以去做澄清,澄清包括利用上下文信息判定,或者增加一轮与用户的交互来澄清,如果明确则继续下面的流程,这是我们整体的架构。
举个栗子:
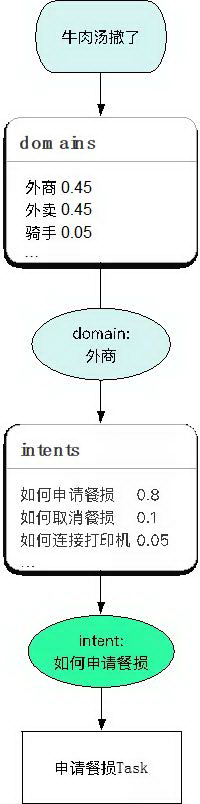
如果接收到一个信息是 " 牛肉汤撒了 ",首选我们要判断它是属于哪个领域的,它是属于外卖商家这个领域,接着判断其意图,对意图进行澄清后得知意图是 " 如何申请餐损 ",然后走餐损的流程。
三、知识发现
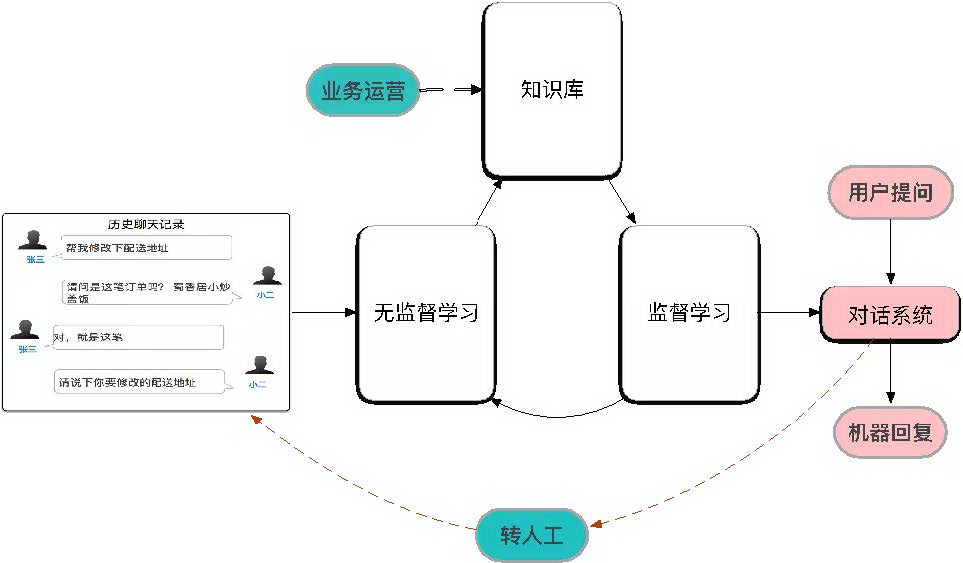
3.1 人在回路
客服的目的是为了解决用户的问题,AI 在现有的 work flow 中节省人力,但是机器解决不了的事情还是要交给人来解决。所以在下图中,我们一定要加一条转人工的服务。另外我们利用无监督学习从日志中挖掘出的知识点也需要人工 " 业务运营 " 来 check 。在整个环路里监督学习从知识库中学习到的语义表示能力又可以提供给无监督学习使用,这个在下面会进一步提到。
3.2 无监督学习在知识发现中应用
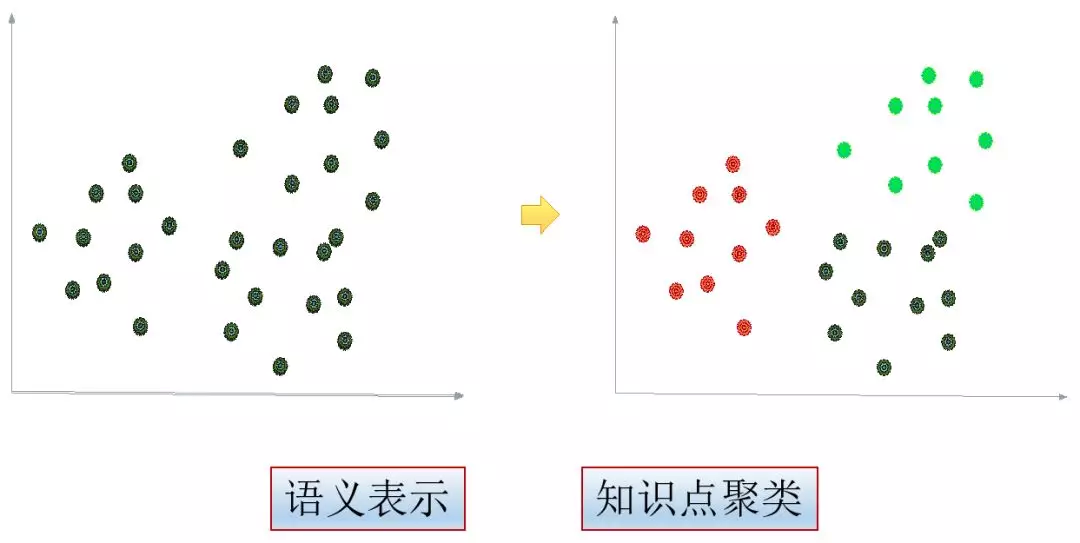
无监督机器学习主要涉及两个问题,一个是句子的语义表示,另一个就是如何做知识聚类。
在语义表示问题上,我们做了大量的试验,在迭代的过程中,我们用到了 DSSM 模型、seq2seq 模型和 BERT 模型来做意图的相似度计算,在这个过程中我们发现不同的模型有各自的特点,它可能抓住不同维度的特征,在离线模型中我们用多个模型的拼接的方式来表示其语义向量。
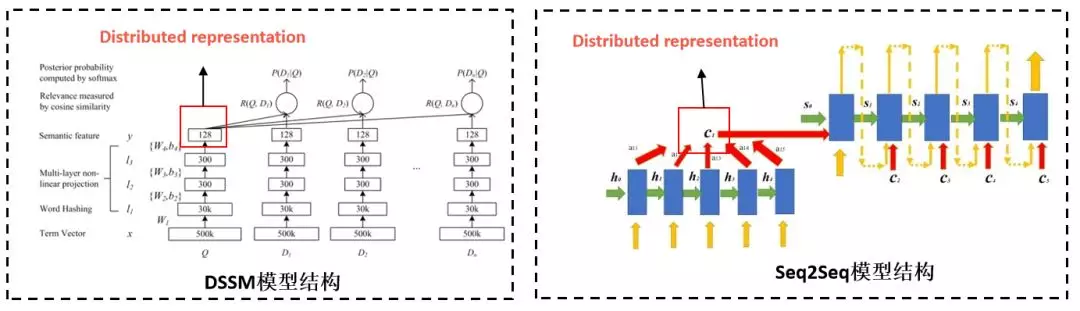
在知识点聚类这个问题上,我们采用用了最通用的 K-means 模型来做的。

上面讲到的是意图和说法的挖掘,在实际业务中我们有大量的 Task 的问题。下图呈现的是一个 " 如何申请餐损 " 的 Task 树。
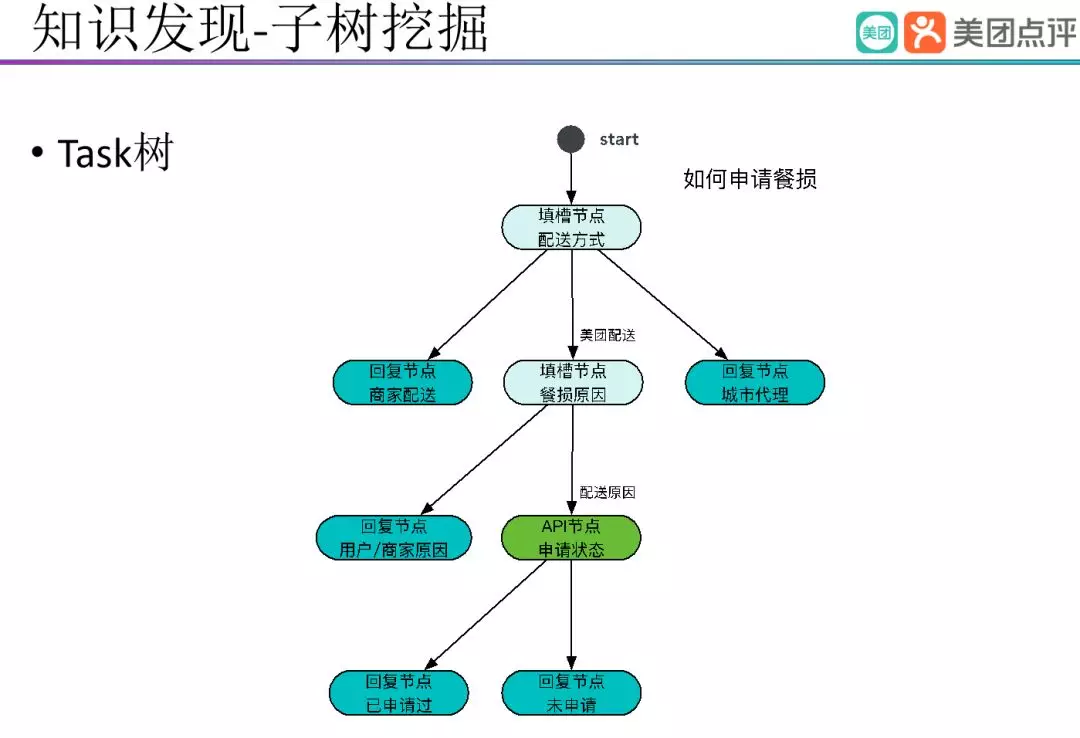
当用户的问题触发 Task 后,Task 机器人根据和用户的交流来获取槽信息,调用不同 API 接口来获取槽信息,进而回复用户。上图 " 如何申请餐损 " Task 需要明确的槽包括 " 配送方式 " 、" 餐损原因 " 、 " 申请状态 “,其中 " 配送方式 " 和 " 餐损原因 " 是通过与用户的交互来明确,” 申请状态 " 则是通过请求后台服务来明确。
在这个环节中我们需要做的就是辅助运营人员构建 Task 类的知识。
我们根据用户的日志数据提取相应意图,然后根据意图共现,回复共现去挖掘,当一个用户问了一个问题之后还会提问哪些问题,当用户收到反馈之后还会反问哪些问题。根据这些去构建 Task 子树,离线构建好之后交给运营的同学,运营同学审核通过之后就可以上线了。
四、情绪识别
4.1 背景介绍
客服热线是我们公司对外服务的重要交流通道,在售前、售中和售后的各个环节中发挥着重要作用,为用户提供意见处理、资料管理、技术支持等多项服务。然而目前客服热线在运营过程中还存在一些痛点,如客服人工坐席的服务水平参差导致客户的体验存在差异,另外个别客户还存在动机复杂等问题。因此如何利用技术提升客服热线的服务水平、检测热线中可能的风险是目前需要解决的一个问题。 本项目对客服热线中的语音数据进行挖掘与分析,通过量化用户的情绪能量值,实现对用户情绪状态 ( 是否激动、情感倾向等 ) 的追踪,并且在客户情绪超过设定阈值时提供预警信息,以便相关人员和应急措施的及时介入,从而为相关业务部门提供运营数据支撑和智力支持,最终提升客服热线的服务质量和服务效率。
4.2 特征提取
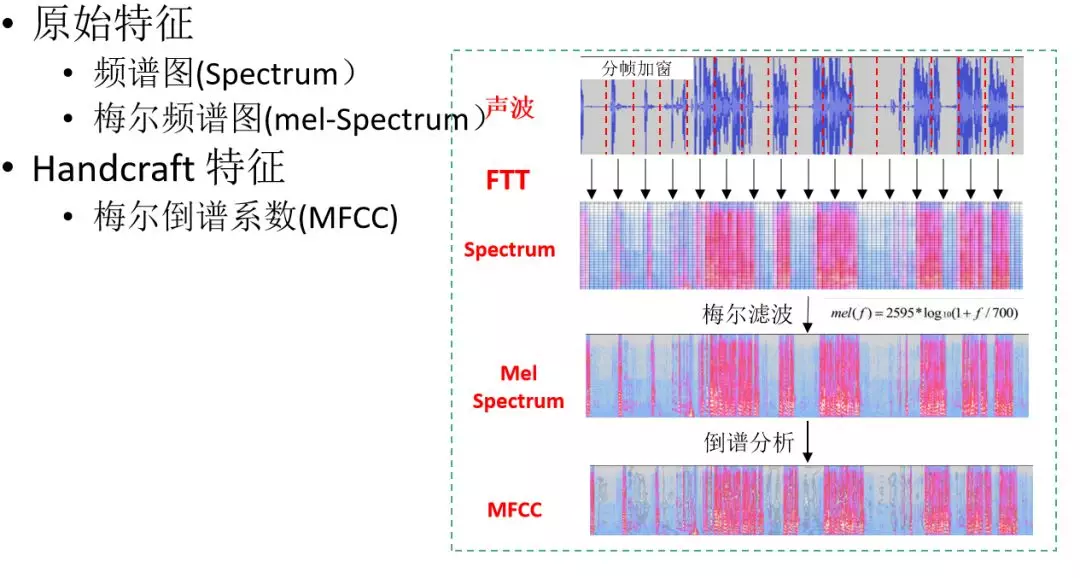
FTT:短时傅里叶变换
每帧语音都对应于一个频谱 ( 通过短时 FFT 计算 ),频谱表示频率与能量的关系。
梅尔滤波:实验观测发现人耳就像一个滤波器组一样,它只关注某些特定的频率分量 ( 人的听觉对频率是有选择性的 ) 。也就说,它只让某些频率的信号通过,而压根就直接无视它不想感知的某些频率信号。
4.3 模型选择
特征处理完成之后就是采用哪种模型来进行训练。
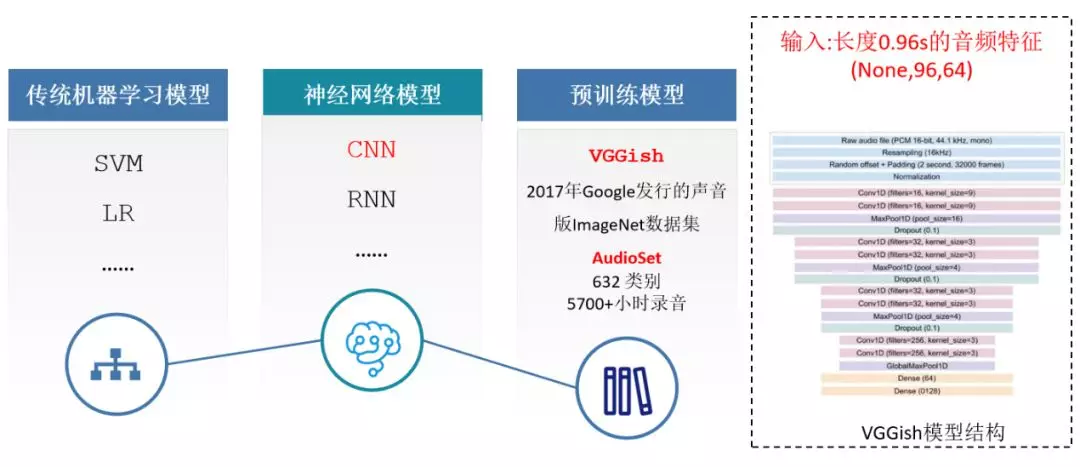
在迭代中我们采用过传统的机器学习模型,比如 LR、SVM 模型,神经网络模型,和一些预训练好的模型,在这个里面我们遇到的一个挑战就是,一个情绪是不是激动的标签是针对整个通话记录标注的,但是用户在通话的过程中,不是一直的激动,而是在某个通话阶段情绪激动,而一个标签无法体现出到底是那一部分激动,是全程激动,还是部分激动,还是全程平静的,其实这个里面就涉及到一个弱标签的学习,如下图所示。
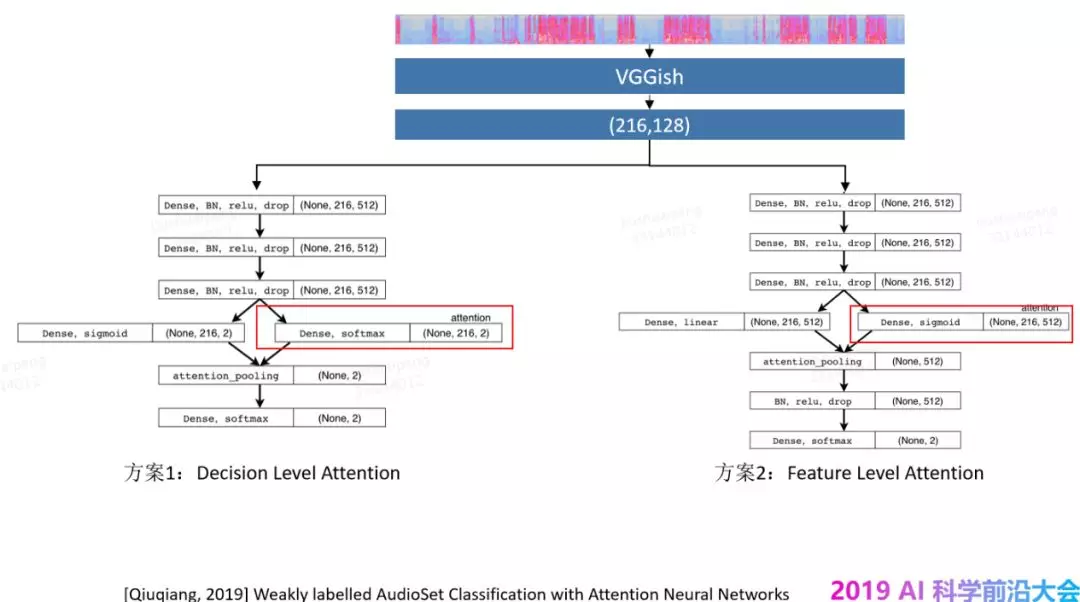
这是 19 年提出的一个算法,在实际应用中效果不错,感兴趣的同学可以根据信息去查找。
在实际的效果上,各个模型的表现如下:
MFCC + LSTM < MFCC + CNN < VGGish + ferture level attention < VGGish + decision level attention
五、展望
- 多轮上下文建模,意图理解
- 让用户做选择题,做意图预判,意图推荐
- 语音与文本多模态,弱标记学习,情绪风险识别
- 对话历史的话题抽取及切割,话术推荐,坐席助理
以上是当前我们正在开展及探索的智能客服理解部分的内容,从 ToC 的用户侧,以及 ToB 的坐席助理侧两方面来优化整个客服闭环。
作者介绍:
江会星博士,美团点评搜索与 NLP 部 NLP 中心的研究员,智能客服团队负责人,主要负责美团智能客服业务及对话平台的建设。曾在阿里达摩院语音实验室从事智能语音对话交互方向研究,主要负责主导的产品有斑马智行语音交互系统、YunOS 语音助理等。
团队介绍:
美团点评搜索与 NLP 部 NLP 中心秉承 " 让机器理解人类语言,让机器与人自然对话,用数据打造知识大脑 " 的信条,致力于建设世界一流的自然语言处理核心技术和服务能力,打造智能客服对话平台,打造自然语言处理平台及知识图谱 ( 美团大脑 ),助力美团业务场景智能化转型,提升美团科技水平和品牌影响力。
当前我们在 NLP 多个方向,包括但不限于意图理解,对话交互,意图推荐,风险识别,知识图谱等岗位招聘算法及工程岗位,Base 北京、上海两地。欢迎加入我们团队,简历请投递至邮箱:
本文来自 DataFun 社区
原文链接:
Deep Reinforcement Learning for Dialogue Generation
本文将会分享一篇深度增强学习在bot中应用的文章,增强学习在很早的时候就应用于bot中来解决一些实际问题,最近几年开始流行深度增强学习,本文作者将其引入到最新的bot问题中。paper的题目是Deep Reinforcement Learning for Dialogue Generation,作者是Jiwei Li,最早于2016年6月10日发在arxiv上。
现在学术界中bot领域流行的解决方案是seq2seq,本文针对这种方案抛出两个问题:
1、用MLE作为目标函数会导致容易生成类似于“呵呵呵”的reply,grammatical、safe但是没有营养,没有实际意义的话。
2、用MLE作为目标函数容易引起对话的死循环,如下图:

解决这样的问题需要bot框架具备以下的能力:
1、整合开发者自定义的回报函数,来达到目标。
2、生成一个reply之后,可以定量地描述这个reply对后续阶段的影响。
所以,本文提出用seq2seq+增强学习的思路来解决这个问题。
说到增强学习,就不得不提增强学习的四元素:
- Action
这里的action是指生成的reply,action空间是无限大的,因为可以reply可以是任意长度的文本序列。
- State
这里的state是指[pi,qi],即上一轮两个人的对话表示。
- Policy
policy是指给定state之后各个action的概率分布。可以表示为:pRL(pi+1|pi, qi)
- Reward
reward表示每个action获得的回报,本文自定义了三种reward。
1、Ease of Answering
这个reward指标主要是说生成的reply一定是容易被回答的。本文用下面的公式来计算容易的程度:

其实就是给定这个reply之后,生成的下一个reply是dull的概率大小。这里所谓的dull就是指一些“呵呵呵”的reply,比如“I don’t know what you are talking about”等没有什么营养的话,作者手动给出了这样的一个dull列表。
2、Information Flow
生成的reply尽量和之前的不要重复。

这里的h是bot的reply表示,i和i+1表示该bot的前后两轮。这个式子表示同一个bot两轮的对话越像reward越小。
3、Semantic Coherence
这个指标是用来衡量生成reply是否grammatical和coherent。如果只有前两个指标,很有可能会得到更高的reward,但是生成的句子并不连贯或者说不成一个自然句子。
 这里采用互信息来确保生成的reply具有连贯性。
这里采用互信息来确保生成的reply具有连贯性。
互信息与多元对数似然比检验以及皮尔森 校验有着密切的联系 [3] ——
校验有着密切的联系 [3] ——
- 杨立娜. 基于相位相关理论的最大互信息图像配准[D].西安电子科技大学,2010.
什么是点互信息机器学习相关文献里面,经常会用到PMI(Pointwise Mutual Information)这个指标来衡量两个事物之间的相关性(比如两个词)。其原理很简单,公式如下:   在概率论中,我们知道,如果x跟y不相关,则p(x,y)=p(x)p(y)。二者相关性越大,则p(x,y)就相比于p(x)p(y)越大。用后面的式子可能更好理解,在y出现的情况下x出现的条件概率p(x|y)除以x本身出现的概率p(x),自然就表示x跟y的相关程度。 这里的log来自于信息论的理论,可以简单理解为,当对p(x)取log之后就将一个概率转换为了信息量(要再乘以-1将其变为正数),以2为底时可以简单理解为用多少个bits可以表示这个变量。 至此,概念介绍完了,后面是例子和相关背景,不感兴趣的话就可以不用看了。 举个自然语言处理中的例子来说,我们想衡量like这个词的极性(正向情感还是负向情感)。我们可以预先挑选一些正向情感的词,比如good。然后我们算like跟good的PMI,即: PMI(like,good)=logp(like,good)p(like)p(good) 其中p(like)是like在语料库中出现的概率(出现次数除以总词数N),p(like,good)表示like跟good在一句话中同时出现的概率(like跟good同时出现的次数除以N2)。 PMI(like,good)越大表示like的正向情感倾向就越明显。 点互信息PMI其实就是从信息论里面的互信息这个概念里面衍生出来的。 互信息即:  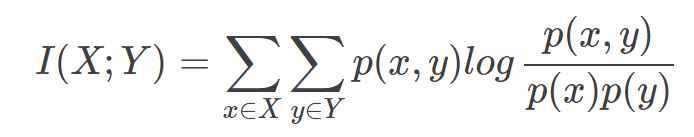 其衡量的是两个随机变量之间的相关性,即一个随机变量中包含的关于另一个随机变量的信息量。所谓的随机变量,即随机试验结果的量的表示,可以简单理解为按照一个概率分布进行取值的变量,比如随机抽查的一个人的身高就是一个随机变量。 可以看出,互信息其实就是对X和Y的所有可能的取值情况的点互信息PMI的加权和。因此,点互信息这个名字还是很形象的。 The following table shows counts of pairs of words getting the most and the least PMI scores in the first 50 millions of words in Wikipedia (dump of October 2015) filtering by 1,000 or more co-occurrences. The frequency of each count can be obtained by dividing its value by 50,000,952. (Note: natural log is used to calculate the PMI values in this example, instead of log base 2)  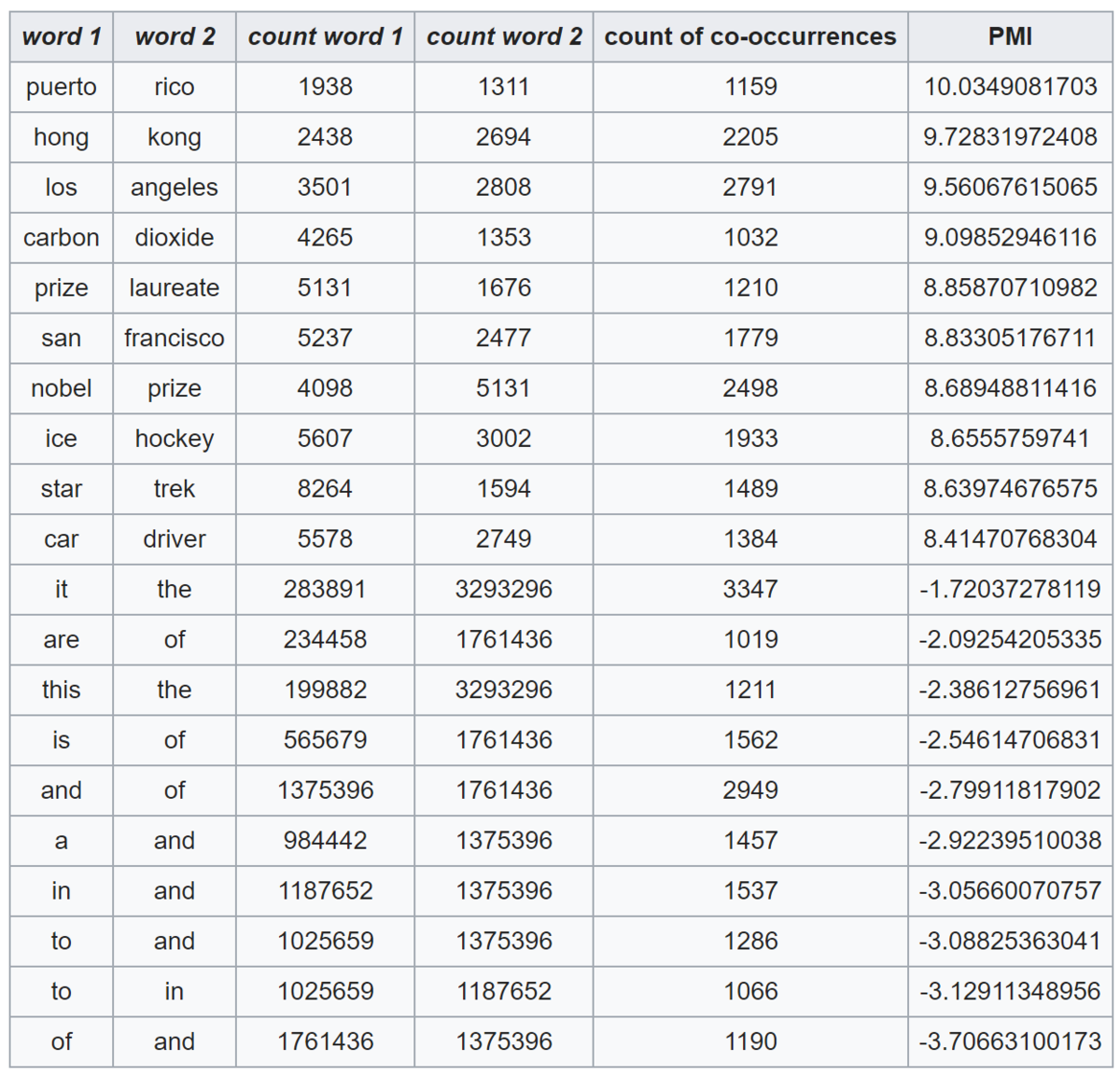 |
|
最终的reward由这三部分加权求和计算得到。
增强学习的几个要素介绍完之后,接下来就是如何仿真的问题,本文采用两个bot相互对话的方式进行。
step 1 监督学习。将数据中的每轮对话当做target,将之前的两句对话当做source进行seq2seq训练得到模型,这一步的结果作为第二步的初值。
step 2 增强学习。因为seq2seq会容易生成dull reply,如果直接用seq2seq的结果将会导致增强学习这部分产生的reply也不是非常的diversity,从而无法产生高质量的reply。所以,这里用MMI(Maximum Mutual Information,这里与之前Jiwei Li的两篇paper做法一致)来生成更加diversity的reply,然后将生成最大互信息reply的问题转换为一个增强学习问题,这里的互信息score作为reward的一部分(r3)。用第一步训练好的模型来初始化policy模型,给定输入[pi,qi],生成一个候选列表作为action集合,集合中的每个reply都计算出其MMI score,这个score作为reward反向传播回seq2seq模型中,进行训练。整个仿真过程如下图:

两个bot在对话,初始的时候给定一个input message,然后bot1根据input生成5个候选reply,依次往下进行,因为每一个input都会产生5个reply,随着turn的增加,reply会指数增长,这里在每轮对话中,通过sample来选择出5个作为本轮的reply。
接下来就是评价的部分,自动评价指标一共两个:
1、对话轮数。

很明显,增强学习生成的对话轮数更多。
2、diversity。

增强学习生成的词、词组更加丰富和多样。
下图给出了一个MMI seq2seq与RL方法的对比结果:

RL不仅仅在回答上一个提问,而且常常能够提出一个新的问题,让对话继续下去,所以对话轮数就会增多。原因是,RL在选择最优action的时候回考虑长远的reward,而不仅仅是当前的reward。
本文是一篇探索性的文章,将seq2seq与RL整合在一起解决bot的问题是一个不错的思路,很有启发性,尤其是用RL可以将问题考虑地更加长远,获得更大的reward。用两个bot相互对话来产生大量的训练数据也非常有用,在实际工程应用背景下数据的缺乏是一个很严重的问题,如果有一定质量的bot可以不断地模拟真实用户来产生数据,将deep learning真正用在bot中解决实际问题就指日可待了。
RL解决bot问题的文章在之前出现过一些,但都是人工给出一些feature来进行增强学习,随着deepmind用seq2seq+RL的思路成功地解决video games的问题,这种seq2seq的思想与RL的结合就成为了一种趋势,朝着data driven的方向更进一步。
一点思考,欢迎交流。