1998_Efficient Backprop笔记
A few practical tricks
1. Stochastic vs Batch learning


在最小值附近震荡的幅度与学习速率成比例,为了减小震荡,可以减小学习速率或者使用自适应的batch size。
有理论证明以下这种形式的学习速率最好:
其中t是类别数,c是一个常量,实际上,这个速率可能太快。
另一种消除噪声的方法是用mini-batch,就是开始用一个小的batch size,然后随着训练进行增加。但是如何增加和调整学习速率一样困难。
2. Shuffling the examples
网络从未知样本学习最快,因此要在每一次迭代选择最不熟悉的样本。这个方法只适用于SGD,最简单的方式是选择连续的不同类的样本。

3. Normalizing the inputs

4. The Sigmoid


用对称的sigmoid函数有一个潜在的问题,那就是误差平面会变得很平坦,因此应该避免用很小的值初始化weights。
5. Choosing Target Values

6. Initializing the weights

7. Choosing Learning Rates
一般情况下权重向量震荡时减小学习速率,而始终保持稳定的方向则增加,但是不适用于SGD和online learning,因为他们始终在震荡。

Momentum:
其中u是momentum的强度,当误差平面是非球形(nonspherical),它增加了收敛速度因为它减小了高曲率方向的step,从而在低曲率部分增加了学习速率的影响。它通常在batch learning中比SGD更有效。
Adaptive Learning Rates:


这个方法实际上很容易实现,其实就是track公式18中的矩阵,平均梯度r。这个矩阵的norm控制学习速率的大小。
8. Radial Basis Functions vs Sigmoid Units
RBF神经网络:
sigmoid单元可以覆盖整个输入空间,但是一个RBF单元只能覆盖一个小的局部空间,因此它的学习更快。但是在高维空间中它需要更多的单元去覆盖整个空间,因此RBF适合作为高层而sigmoid适合作为低层单元。
Convergence of Gradient Descent
1. A little theory
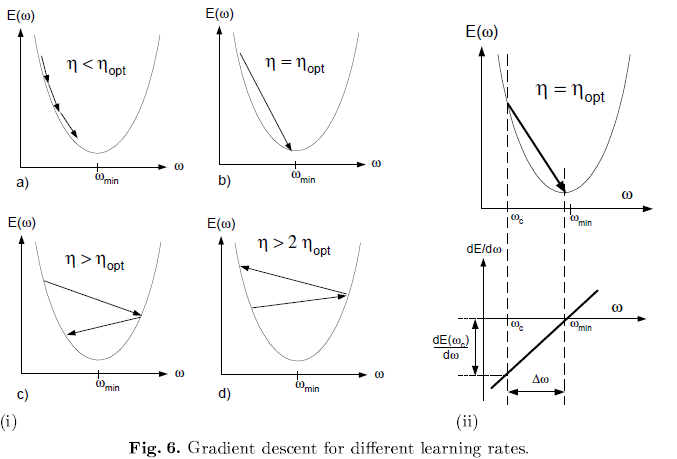
具体理论分析见文章。
结论:
如果对所有的weight约定一个学习速率,那么

2. Two examples
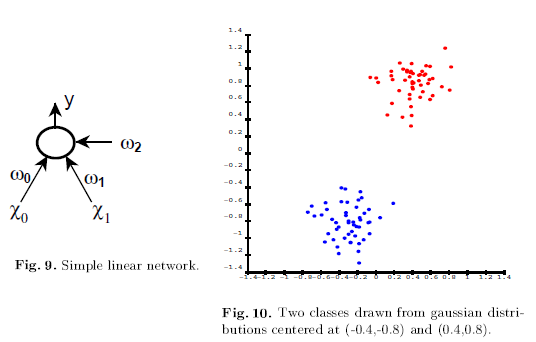

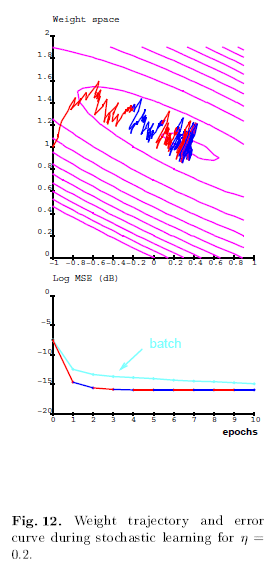
b. Multilayer Network


3. 以上的理论可以证明这几个tricks: