一切的一切源于这学期选了门大数据与搜索引擎这门课
作业啊(一把眼泪
=======================陈伟文=10125210217====================
amzon.txt是该童车第一页评论用BeautifulSoup改的规范的网页代码(不要在意拼写错误
通过对网页和代码的观察发现:要爬的评论都有固定格式,比如第一个
<span class="a-size-base review-text">
收到一堆破烂连充电器都没有螺丝板子等工具都没有。
</span>所以重点是这里:
>>>soup.find_all('span', attrs={"class": "a-size-base review-text"})前面还用过find_all(“span”)等一系列find姿势,结果出来很多多余的东西
结果跑出来发现第一页10条评论只爬出来7个
最后发现问题在这
<span class="a-size-base review-text">
收到之后有灰尘,要我自己擦干净在组装。
<br/>
还有我的发票在那里?
<br/>
<br/>
上述别人的问题我也有.
<br/>
<br/>
另外,既然需要安装,安装说明书应该清楚易懂,可惜厂家给的说明书很粗糙,安装步骤只有文字说明没有配图...很不方便
</span>有3个评论里面带回车,没能find出来,还没能解决这个问题(目前只把其他的几个爬了出来- -
comments.py是爬评论的代码
其中get_comments函数是获取某一页的评论
网页上看见一共6页,就写了个6上去
(python版本3.5.1
import urllib.request
from bs4 import BeautifulSoup
webheader = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
#'Accept-Encoding': 'gzip, deflate',
'Host': 'www.douban.com',
'DNT': '1'
}
def get_comments(weburl):
req = urllib.request.Request(url=weburl, headers=webheader)
webPage=urllib.request.urlopen(req)
data = webPage.read()
data = data.decode('UTF-8')
soup = BeautifulSoup(data,"lxml")
for list in soup.find_all('span', attrs={"class": "a-size-base review-text"}):
st = list.string
if st != None and st[0] != '¥':
f.write(st)
f.write("
")
f = open("result.txt", "w")#get comments of one childrenbike
f.write("""
==============================
by cww97
here is the children bike
https://www.amazon.cn/%E5%AD%A9%E5%AD%90%E5%AE%B6%E4%B8%89%E8%BD%AE%E8%BD%A6%E5%84%BF%E7%AB%A5%E7%94%B5%E5%8A%A8%E6%91%A9%E6%89%98%E8%BD%A6-%E5%84%BF%E7%AB%A5%E7%94%B5%E5%8A%A8%E8%BD%A6-%E7%AB%A5%E8%BD%A6%E7%8E%A9%E5%85%B7%E8%BD%A6%E5%84%BF%E7%AB%A5%E5%8F%AF%E5%9D%90/dp/B00DQGTK4W/ref=sr_1_2?ie=UTF8&qid=1464775734&sr=8-2&keywords=%E7%AB%A5%E8%BD%A6"
===============================
""")
for i in range(6):
url = "https://www.amazon.cn/product-reviews/B00DQGTK4W/ref=cm_cr_dp_see_all_summary?ie=UTF8&showViewpoints=%d&sortBy=helpful"%(i+1)
get_comments(url)result.txt是爬出的结果,输出文件(巨丑,大概张这样
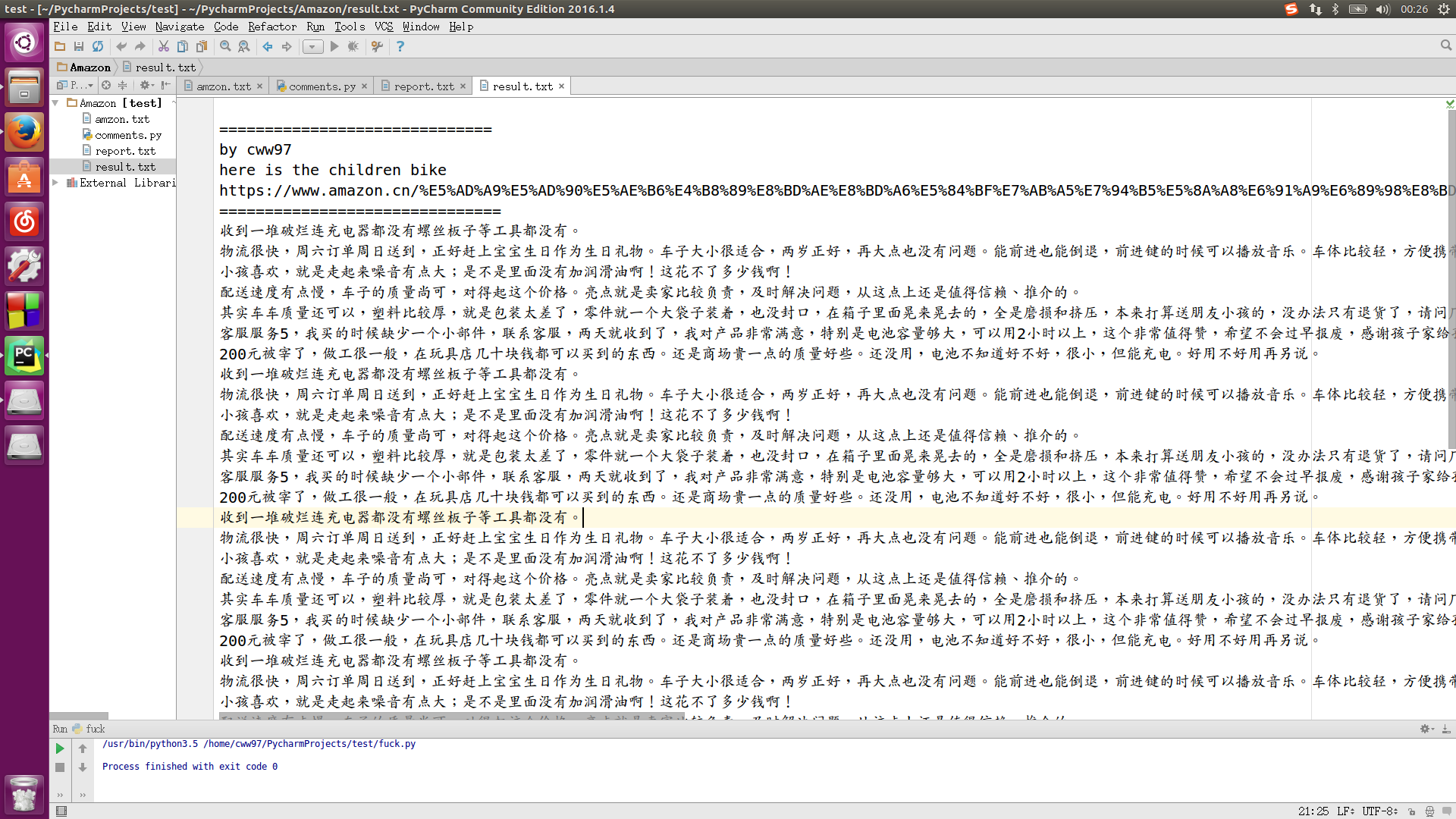
(PS:不是很清楚老师是叫我们爬一个童车的评论还是所有的,如果是后者,其实我写的还不算成功(认怂= =)
之前看过一点点python的语法,这次直接上来写这个,一开始准备写爬虫的论文的,然后问学长们说这很简单,
而且还+10分,果断写爬虫代码不写论文了,也请老师对本篇“实验报告”不要用太专业的眼光来看- -(完))
===========================参考资料===============================
http://beautifulsoup.readthedocs.io/zh_CN/latest/#find-all
http://docs.python-requests.org/zh_CN/latest/user/quickstart.htmlhttp://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000
http://blog.csdn.net/evankaka/article/details/46849095
http://blog.csdn.net/omuyejingfeng1/article/details/24182313
https://github.com/joway/PythonSpider/blob/master/JandanSpider.py
http://www.jianshu.com/p/a5f1df34d184
==================by cww97=2016.6.1=23:46=========================
最后感谢Joway童鞋&&HAN童鞋的指引
感谢Joway童鞋&&HAN童鞋的指引
感谢Joway童鞋&&HAN童鞋的指引(说三遍)
=============================真完了===============================