(八)如何快速部署 Prometheus?
上一节介绍了 Prometheus 的核心,多维数据模型。本节演示如何快速搭建 Prometheus 监控系统。
(1)环境说明
我们将通过 Prometheus 监控两台 Docker Host:10.0.0.21 和 10.0.0.22,监控 host 和容器两个层次的数据。
按照架构图,我们需要运行如下组件:
(2)Prometheus Server
Prometheus Server 本身也将以容器的方式运行在 host 10.0.0.21 上。
(3)Exporter
Prometheus 有很多现成的 Exporter,完整列表请参考 https://prometheus.io/docs/instrumenting/exporters/
我们将使用:
- Node Exporter,负责收集 host 硬件和操作系统数据。它将以容器方式运行在所有 host 上。
- cAdvisor,负责收集容器数据。它将以容器方式运行在所有 host 上。
(4)Grafana
显示多维数据,Grafana 本身也将以容器方式运行在 host 10.0.0.21上。
(5)运行 Node Exporter
在两个 host 上执行如下命令:
docker run -d -p 9100:9100
-v "/proc:/host/proc"
-v "/sys:/host/sys"
-v "/:/rootfs"
--net=host
prom/node-exporter
--path.procfs /host/proc
--path.sysfs /host/sys
--collector.filesystem.ignored-mount-points "^/(sys|proc|dev|host|etc)($|/)"
注意,这里我们使用了 --net=host,这样 Prometheus Server 可以直接与 Node Exporter 通信。
Node Exporter 启动后,将通过 9100 提供 host 的监控数据。在浏览器中通过 http://10.0.0.21:9100/metrics 测试一下。
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 0
go_gc_duration_seconds{quantile="0.25"} 0
go_gc_duration_seconds{quantile="0.5"} 0
go_gc_duration_seconds{quantile="0.75"} 0
go_gc_duration_seconds{quantile="1"} 0
go_gc_duration_seconds_sum 0
go_gc_duration_seconds_count 0
# HELP go_goroutines Number of goroutines that currently exist.
# TYPE go_goroutines gauge
go_goroutines 9
# HELP go_info Information about the Go environment.
# TYPE go_info gauge
go_info{version="go1.14.4"} 1
# HELP go_memstats_alloc_bytes Number of bytes allocated and still in use.
# TYPE go_memstats_alloc_bytes gauge
go_memstats_alloc_bytes 1.221024e+06
# HELP go_memstats_alloc_bytes_total Total number of bytes allocated, even if freed.
# TYPE go_memstats_alloc_bytes_total counter
go_memstats_alloc_bytes_total 1.221024e+06
# HELP go_memstats_buck_hash_sys_bytes Number of bytes used by the profiling bucket hash table.
# TYPE go_memstats_buck_hash_sys_bytes gauge
go_memstats_buck_hash_sys_bytes 1.445015e+06
# HELP go_memstats_frees_total Total number of frees.
# TYPE go_memstats_frees_total counter
go_memstats_frees_total 616
# HELP go_memstats_gc_cpu_fraction The fraction of this program's available CPU time used by the GC since the program started.
# TYPE go_memstats_gc_cpu_fraction gauge
go_memstats_gc_cpu_fraction 0
# HELP go_memstats_gc_sys_bytes Number of bytes used for garbage collection system metadata.
# TYPE go_memstats_gc_sys_bytes gauge
go_memstats_gc_sys_bytes 3.436808e+06
# HELP go_memstats_heap_alloc_bytes Number of heap bytes allocated and still in use.
# TYPE go_memstats_heap_alloc_bytes gauge
go_memstats_heap_alloc_bytes 1.221024e+06
# HELP go_memstats_heap_idle_bytes Number of heap bytes waiting to be used.
# TYPE go_memstats_heap_idle_bytes gauge
go_memstats_heap_idle_bytes 6.4282624e+07
# HELP go_memstats_heap_inuse_bytes Number of heap bytes that are in use.
# TYPE go_memstats_heap_inuse_bytes gauge
go_memstats_heap_inuse_bytes 2.433024e+06
# HELP go_memstats_heap_objects Number of allocated objects.
# TYPE go_memstats_heap_objects gauge
go_memstats_heap_objects 7382
# HELP go_memstats_heap_released_bytes Number of heap bytes released to OS.
(6)运行 cAdvisor
在两个 host 上执行如下命令:
docker run
--volume=/:/rootfs:ro
--volume=/var/run:/var/run:rw
--volume=/sys:/sys:ro
--volume=/var/lib/docker/:/var/lib/docker:ro
--publish=8080:8080
--detach=true
--name=cadvisor
--net=host
google/cadvisor:latest
注意,这里我们使用了 --net=host,这样 Prometheus Server 可以直接与 cAdvisor 通信。
cAdvisor 启动后,将通过 8080 提供 host 的监控数据。在浏览器中通过 http://10.0.0.22:8080/metrics 测试一下。
# HELP cadvisor_version_info A metric with a constant '1' value labeled by kernel version, OS version, docker version, cadvisor version & cadvisor revision.
# TYPE cadvisor_version_info gauge
cadvisor_version_info{cadvisorRevision="8949c822",cadvisorVersion="v0.32.0",dockerVersion="19.03.13",kernelVersion="4.15.0-122-generic",osVersion="Alpine Linux v3.7"} 1
# HELP container_cpu_load_average_10s Value of container cpu load average over the last 10 seconds.
# TYPE container_cpu_load_average_10s gauge
container_cpu_load_average_10s{container_label_maintainer="",container_label_org_label_schema_description="",container_label_org_label_schema_name="",container_label_org_label_schema_schema_version="",container_label_org_label_schema_url="",container_label_org_label_schema_vcs_ref="",container_label_org_label_schema_vcs_url="",container_label_org_label_schema_vendor="",container_label_org_opencontainers_image_description="",container_label_org_opencontainers_image_revision="",container_label_org_opencontainers_image_source="",container_label_org_opencontainers_image_title="",container_label_org_opencontainers_image_url="",container_label_org_opencontainers_image_vendor="",container_label_works_weave_role="",id="/",image="",name=""} 0
container_cpu_load_average_10s{container_label_maintainer="",container_label_org_label_schema_description="",container_label_org_label_schema_name="",container_label_org_label_schema_schema_version="",container_label_org_label_schema_url="",container_label_org_label_schema_vcs_ref="",container_label_org_label_schema_vcs_url="",container_label_org_label_schema_vendor="",container_label_org_opencontainers_image_description="",container_label_org_opencontainers_image_revision="",container_label_org_opencontainers_image_source="",container_label_org_opencontainers_image_title="",container_label_org_opencontainers_image_url="",container_label_org_opencontainers_image_vendor="",container_label_works_weave_role="",id="/docker",image="",name=""} 0
container_cpu_load_average_10s{container_label_maintainer="",container_label_org_label_schema_description="",container_label_org_label_schema_name="",container_label_org_label_schema_schema_version="",container_label_org_label_schema_url="",container_label_org_label_schema_vcs_ref="",container_label_org_label_schema_vcs_url="",container_label_org_label_schema_vendor="",container_label_org_opencontainers_image_description="",container_label_org_opencontainers_image_revision="",container_label_org_opencontainers_image_source="",container_label_org_opencontainers_image_title="",container_label_org_opencontainers_image_url="",container_label_org_opencontainers_image_vendor="",container_label_works_weave_role="",id="/docker/95ddff3ce5af3f26e027ba9247838f8f0186f3cd104afcfb2109aa14bc49dd56",image="google/cadvisor:latest",name="cadvisor"} 0
(7)运行 Prometheus Server
在 host 10.0.0.22上执行如下命令:
docker run -d -p 9090:9090
-v /root/prometheus.yml:/etc/prometheus/prometheus.yml
--name prometheus
--net=host
prom/prometheus
注意,这里我们使用了 --net=host,这样 Prometheus Server 可以直接与 Exporter 和 Grafana 通信。
prometheus.yml 是 Prometheus Server 的配置文件。
最重要的配置是:
static_configs:
- targets: ['localhost:9090','localhost:8080','localhost:9100','10.0.0.21:8080','10.0.0.21:9100']
指定从哪些 exporter 抓取数据。这里指定了两台 host 上的 Node Exporter 和 cAdvisor。
另外 localhost:9090 就是 Prometheus Server 自己,可见 Prometheus 本身也会收集自己的监控数据。同样地,我们也可以通过 http://10.0.0.22:9090/metrics 测试一下。
在浏览器中打开 http://10.0.0.22:9090 ,点击菜单 Status -> Targets。
如下图所示:
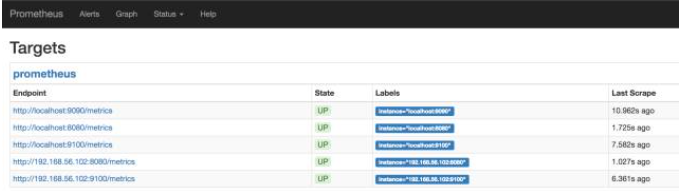
所有 Target 的 State 都是 UP,说明 Prometheus Server 能够正常获取监控数据。
(8)运行 Grafana
在 host 10.0.0.22 上执行如下命令:
docker run -d -i -p 3000:3000
-e "GF_SERVER_ROOT_URL=http://grafana.server.name"
-e "GF_SECURITY_ADMIN_PASSWORD=secret"
--net=host
grafana/grafana
注意,这里我们使用了 --net=host,这样 Grafana 可以直接与 Prometheus Server 通信。
-e "GF_SECURITY_ADMIN_PASSWORD=secret 指定了 Grafana admin用户密码 secret。
Grafana 启动后。在浏览器中打开 http://10.0.0.22:3000/
Name 为 Data Source 命名,例如 prometheus。
Type 选择 Prometheus。
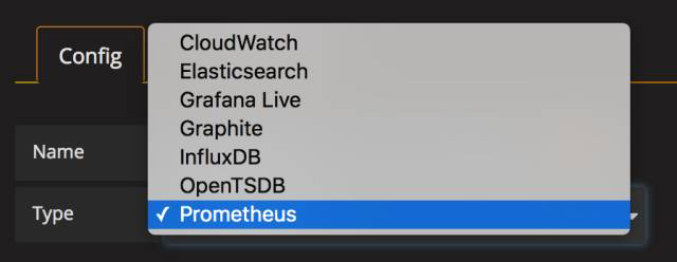
Url 输入 Prometheus Server 的地址 http://10.0.0.22:9090
其他保持默认值,点击 Add。
如果一切顺利,Grafana 应该已经能够访问 Prometheus 中存放的监控数据了,那么如何展示呢?
Grafana 是通过 Dashboard 展示数据的,在 Dashboard 中需要定义:
- 展示 Prometheus 的哪些多维数据?需要给出具体的查询语言表达式。
- 用什么形式展示,比如二维线性图,仪表图,各种坐标的含义等。
可见,要做出一个 Dashboard 也不是件容易的事情。幸运的是,我们可以借助开源社区的力量,直接使用现成的 Dashboard。
访问 https://grafana.com/dashboards?dataSource=prometheus&search=docker,将会看到很多用于监控 Docker 的 Dashboard。
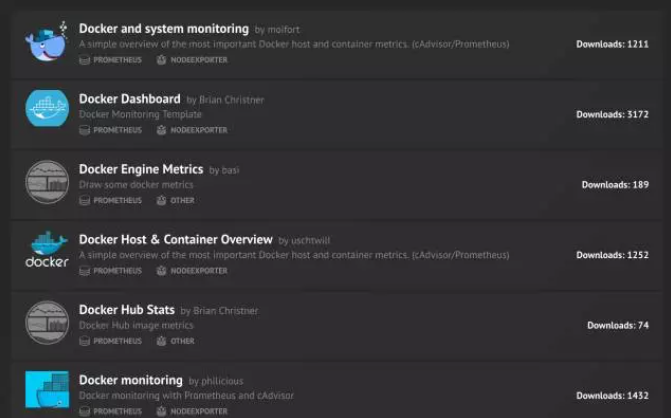
我们可以下载这些现成的 Dashboard,然后 import 到我们的 Grafana 中就可以直接使用了。
比如下载 Docker and system monitoring,得到一个 json 文件,然后点击 Grafana 左上角菜单 Dashboards -> Import。导入我们下载的 json 文件。
Dashboard 将立刻展示出漂亮的图表。
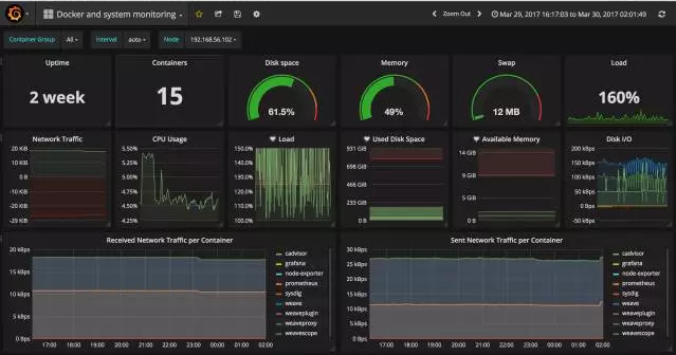
在这个 Dashboard 中,上部分是 host 的数据,我们可以通过 Node 切换不同的 host。
Dashboard 的下半部分展示的是所有的容器监控数据。Grafana 的 Dashboard 是可交互的,我们可以在图表上只显示指定的容器、选取指定的时间区间、重新组织和排列图表、调整刷新频率,功能非常强大。
好了,以上就完成了 Prometheus 监控系统的部署,更多功能大家可以自行探索。到这里我们已经学习了多种 Docker 监控方案,是时候对它们做个比较了,下一节见。