1、说在前面
过完今天就放假回家了(挺高兴),于是提前检查了下个服务集群的状况,一切良好。正在我想着回家的时候突然发现手机上一连串的告警,spark任务执行失败,spark空间不足。我的心突然颤抖了一下,于是赶紧去看服务器的磁盘容量:
#df -h
确实,还剩下6.8G,赶紧排查是什么占用了空间。发现hadoop、spark站的空间比较大,一个50多G(data)、一个30多G(spark-events)。不对啊,这也没占多少啊,于是登录到hadoop的webui去看资源的使用情况:
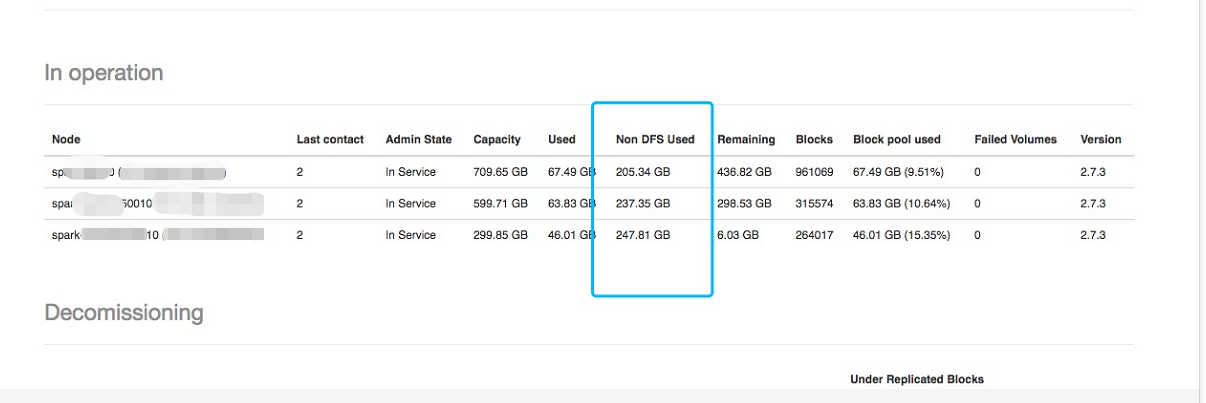
发现Non DFS Used的值很大,接下来就是名词解释时间:
Capacity:可用的总空间
Used:已用的空间
Non DFS Used:非hdfs文件占用dfs的空间(侵占)
Remaining:剩余可用空间
发现Non DFS Used的值都很大,证明有很多的非hdfs文件侵占了大量的dfs空间。可以看到其中有一个加点只剩6.03G了。这个总空间的大小默认就是磁盘的大小,不过hadoop有个磁盘的配置项dfs.datanode.du.reserved,这个配置是设置hadoop保留一部分不用于hdfs存储的空间默认是0。
2、好了,明白这个后,开始去排查到底是什么文件侵占了dfs的空间。看了一下服务器上面部署的服务,有spark、hadoop(hdfs)、presto,如果是对大数据相对熟悉的人第一判断应该是spark,首先想到的是spark work和spark-events,检查是否运行了history。简单科普一下,spark work存放的是一个spark work任务运行的依赖环境和日志输出,集群其他的节点都来这个地方拉取,spark-events存放的是运行日志,history web就是去的这里的数据。经检查发现是work,已经201G了。
使用spark standalone模式执行任务,每提交一次任务,在每个节点work目录下都会生成一个文件夹,命名规则app-20180212191730-0249。该文件夹下是任务提交时,各节点从主节点下载的程序所需要的资源文件。 这些目录每次执行都会生成,且不会自动清理,执行任务过多会将内存撑爆。将历史没用的work目录下面的app目录删除:
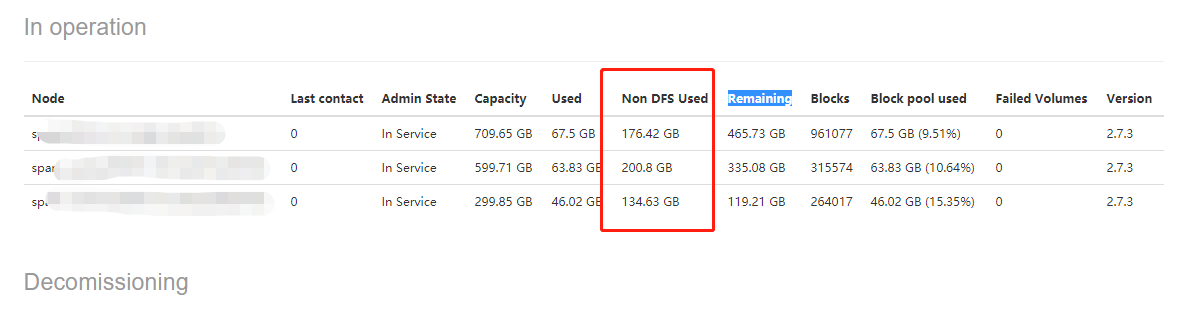
3、解决方案
需要添加定时清理策略,只针对于standalong模式:
在spark-env.sh里面添加如下配置
-Dspark.worker.cleanup.interval=1800:清理周期,每隔多长时间清理一次,单位秒
-Dspark.worker.cleanup.appDataTtl=3600:保留最近多长时间的数据