环境要求:
centos7:CentOS Linux release 7.3.1611
版本:hadoop-2.7.4,hive-2.1.1,hbase-1.2.6,scala-2.11.12 ,spark-2.2.1
hadoop服务部署:
参考地址:http://m.blog.csdn.net/qq_33314107/article/details/74932763
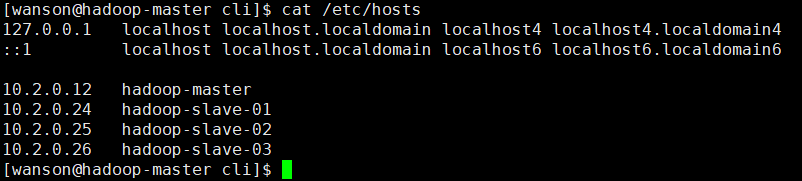
一、 配置hosts文件
先简单说明下配置hosts文件的作用,它主要用于确定每个结点的IP地址,方便后续master结点能快速查到并访问各个结点。在上述3个虚机结点上均需要配置此文件。由于需要确定每个结点的IP地址,所以在配置hosts文件之前需要先查看当前虚机结点的IP地址是多少,可以通过ifconfig命令进行查看,如本实验中,master结点的IP地址为:
二、建立hadoop运行帐号
sudo groupadd hadoop //设置hadoop用户组
sudo useradd -s /bin/bash -d /home/wanson -m wanson -g hadoop //添加一个wanson用户,此用户属于hadoop用户组
sudo passwd wanson //设置用户zhm登录密码
三、配置ssh免密码连入(三台之间互相免密码登录)
四、下载并解压hadoop安装包
wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.5/hadoop-2.7.5-src.tar.gz
五、配置namenode,修改site文件
在配置site文件之前需要作一些准备工作,下载Java最新版的JDK软件,可以从Oracle官网上下载,我使用的jdk软件版本为:jdk1.7.0_09,我将java的JDK解压安装在/opt/jdk1.7.0_09目录中,接着配置JAVA_HOME宏变量及hadoop路径,这是为了方便后面操作,这部分配置过程主要通过修改/etc/profile文件来完成,在profile文件中添加如下几行代码:
三台服务器环境配置一样: 
source /home/wanson/.bash_profile
cat /ebsig/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>/ebsig/hadoop/data</value>
<final>true</final>
</property>
<property>
<name>dfs.name.dir</name>
<value>/ebsig/hadoop/source/hdfs</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<final>true</final>
</property>
</configuration>
cat /ebsig/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://10.2.0.12:9000</value> #hadoop主节点地址
<final>true</final>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/ebsig/hadoop/tmp</value>
<description>A base for other temporary directories</description>
</property>
</configuration>
vim /ebsig/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>10.2.0.12:9001</value>
</property>
</configuration>
整个目录同步到两台从服务器
六、配置/ebsig/hadoop/etc/hadoop/hadoop-env.sh文件
export HADOOP_HOME=/ebsig/hadoop
export HIVE_HOME=/ebsig/hadoop/apache-hive
export JAVA_HOME=/home/wanson/jdk1.8.0_131
export HADOOP_CLASSPATH=.:$CLASSPATH:$HADOOP_CLASSPATH:$HADOOP_HOME/bin:/home/wanson/jdk1.8.0_131
七、/ebsig/hadoop/etc/hadoop/配置masters和slaves文件


八、向各节点复制hadoop
向两个从节点复制
九、格式化namenode
执行hadoop namenode -format #在主节点上执行,交互时选“Y”
十、启动hadoop和关闭hadoop
/ebsig/hadoop/sbin/start-all.sh
/ebsig/hadoop/sbin/stop.all.sh
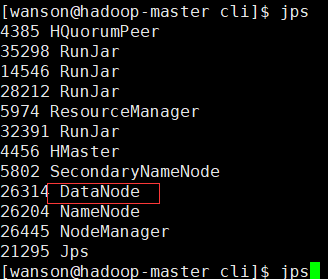
十一、用jps检验各后台进程是否成功启动
十二、通过网站查看集群情况
http://10.2.0.12:8088/cluster
http://10.2.0.12:50070/dfshealth.html#tab-datanode
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
参考地址: http://blog.csdn.net/jssg_tzw/article/details/72354470
hive部署:软件包下载:wget http://mirror.bit.edu.cn/apache/hive/hive-2.1.1/apache-hive-2.1.1-bin.tar.gz
tar -zxvf apache-hive-2.1.1-bin.tar.gz
mv apache-hive-2.1.1 apache-hive
#拷贝hive-default.xml.template
并重命名为hive-site.xml:cp hive-default.xml.template hive-site.xml
#编辑hive-site.xml
vim hive-site.xml #远程连接hive免密码需要设置NOSASL


cd $HADOOP_HOME #进入Hadoop主目录
bin/hadoop fs -mkdir -p /hive/warehouse #创建目录
bin/hadoop fs -chmod -R 777 /hive/warehouse #新建的目录赋予读写权限
bin/hadoop fs -mkdir -p /tmp/hive/#新建/tmp/hive/目录
bin/hadoop fs -chmod -R 777 /tmp/hive #目录赋予读写权限
#用以下命令检查目录是否创建成功
bin/hadoop fs -ls /user/hive bin/hadoop fs -ls /tmp/hive
修改hive-site.xml中的临时目录

mkdir -p /ebsig/hadoop/apache-hive/tmp/wanson/
touch /ebsig/hadoop/apache-hive/tmp/wanson/operation_logs



数据库授权:创建mysql-5.7 并创建hive和并对该库进行授权和密码


以上临时目录报错参考链接:http://blog.csdn.net/fhg12225/article/details/45817477
数据库创建参考链接: http://blog.csdn.net/jssg_tzw/article/details/68944693
将MySQL驱动包上载到Hive的lib目录下
cp /home/dtadmin/spark_cluster/mysql-connector-java-5.1.36.jar $HIVE_HOME/lib/
对mysql数据库初始化:
对MySQL数据库初始化:
#进入到hive的bin目录 cd $HIVE_HOME/bin
#对数据库进行初始化 schematool -initSchema -dbType mysql
启动服务:nohup hive --service hiveserver2 &
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
参考链接:参考地址:https://www.cnblogs.com/lzxlfly/p/7221890.html
Hbase部署:wget http://mirrors.hust.edu.cn/apache/hbase/1.2.6/hbase-1.2.6-bin.tar.gz
1、添加环境变量:
export HBASE_HOME=/ebsig/hbase-1.2.6
export HBASE_PID_DIR=/ebsig/hadoop/pids
export PATH=$HBASE_HOME/bin:$PATH
export HADOOP_CLASSPATH=$HBASE_HOME/lib/*:classpath
vim /ebsig/hbase-1.2.6/conf/hbase-env.sh #使用hbase自带zookeeper
2、vim /ebsig/hbase-1.2.6/conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name> <!-- hbase存放数据目录 -->
<value>hdfs://10.2.0.12:9000/hbase</value>
<!-- 端口要和Hadoop的fs.defaultFS端口一致-->
</property>
<property>
<name>hbase.cluster.distributed</name> <!-- 是否分布式部署 -->
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name> <!-- list of zookooper -->
<value>hadoop-master,hadoop-slave-01,hadoop-slave-02</value>
</property>
<property><!--zookooper配置、日志等的存储位置 -->
<name>hbse.zookeeper.property.dataDir</name>
<value>/ebsig/hbase/zookeeper</value>
</property>
</configuration>
3、cat /ebsig/hbase-1.2.6/conf/regionservers #去掉默认的localhost,添加图片内容

把以上目录同步到两台从服务器
在主master启动hbase:/ebsig/hbase-1.2.6/bin/start-hbase.sh #启动命令
在主master上用jps查看:有HMaster、HQuormPeer进程
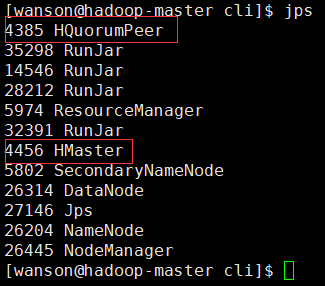
在slave上查看:jps查看有HRegionServer、HQuorumPeer启动成功

验证:用hbase shell然后输入status命令查看以下内容:

在浏览器访问:http://hadoop-master:16010
stop-hbase.sh 关闭服务命令
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
scala环境部署:
1、下载地址:http://www.scala-lang.org/download/

环境变量:
export SCALA_HOME=/ebsig/scala-2.11.12
export PATH=$SCALA_HOME/bin:$PATH
spark环境部署:下载地址:http://spark.apache.org/releases/spark-release-2-2-1.html
环境变量:
#spark
export SPARK_HOME=/ebsig/spark-2.2.1-bin-hadoop2.7
2、vim /ebsig/spark-2.2.1-bin-hadoop2.7/conf/spark-env.sh #添加以下内容到该配置
export SPARK_DIST_CLASSPATH=$(/ebsig/hadoop/bin/hadoop classpath)
#rzx----config
SPARK_LOCAL_DIRS=/ebsig/spark-2.2.1-bin-hadoop2.7/local #配置spark的local目录
SPARK_MASTER_IP=hadoop-master #master节点ip或hostname
SPARK_MASTER_WEBUI_PORT=8085 #web页面端口
#export SPARK_MASTER_OPTS="-Dspark.deploy.defaultCores=4" #spark-shell启动使用核数
SPARK_WORKER_CORES=4 #Worker的cpu核数
SPARK_WORKER_MEMORY=2g #worker内存大小
SPARK_WORKER_DIR=/ebsig/spark-2.2.1-bin-hadoop2.7/worker #worker目录
SPARK_WORKER_OPTS="-Dspark.worker.cleanup.enabled=true -Dspark.worker.cleanup.appDataTtl=604800" #worker自动清理及清理时间间隔
SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://hadoop-master:9000/spark/history" #history server页面端口>、备份数、log日志在HDFS的位置
SPARK_LOG_DIR=/ebsig/spark-2.2.1-bin-hadoop2.7/logs #配置Spark的log日志
JAVA_HOME=/home/wanson/jdk1.8.0_131 #配置java路径
SCALA_HOME=/ebsig/scala-2.11.12 #配置scala路径
HADOOP_HOME=/ebsig/hadoop/lib/native #配置hadoop的lib路径
HADOOP_CONF_DIR=/ebsig/hadoop/etc/hadoop/ #配置hadoop的配置路径
3、vim /ebsig/spark-2.2.1-bin-hadoop2.7/conf/spark-defaults.conf #添加以下内容:
spark.master spark://hadoop-master:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop-master:9000/spark/history
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 1g
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
4、vim /ebsig/spark-2.2.1-bin-hadoop2.7/conf/slaves #添加以下图片内容
参考地址:https://www.cnblogs.com/NextNight/p/6703362.html

5、把scala和spark同步到两台slave服务器上
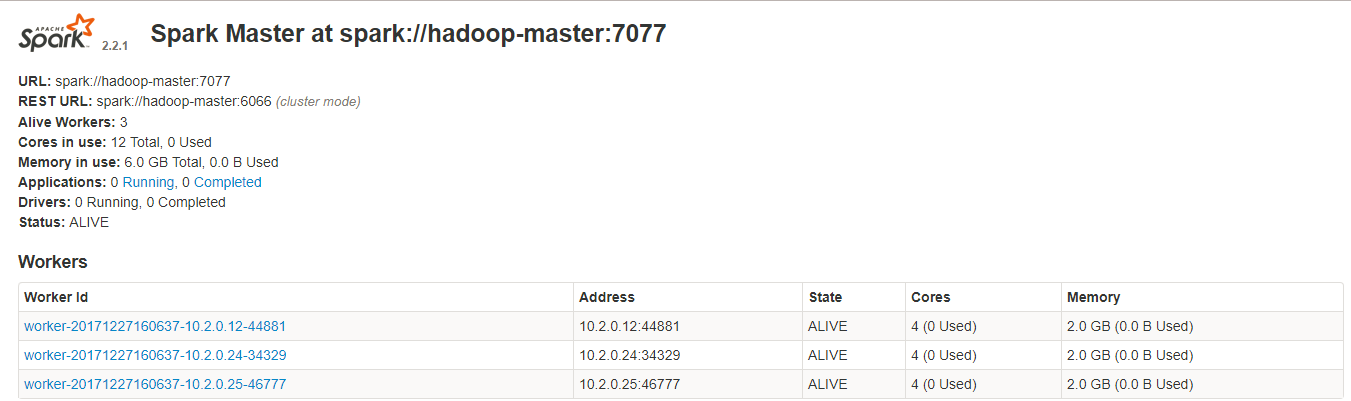
6、启动spark:/ebsig/spark-2.2.1-bin-hadoop2.7/sbin/start-all.sh #启动服务 (两台从服务器也要启动)
/ebsig/spark-2.2.1-bin-hadoop2.7/sbin/stop-all.sh #关闭服务
7、浏览器访问:http://10.2.0.12:8085/ 出现以下页面就已经成功了