▶ 使用Jacobi 迭代求泊松方程的数值解
● 首次使用 OpenACC 进行加速。
■ win10下使用 -acc 选项时报错找不到结构 _timb,我把其定义(实际是结构 __timeb64)写到本文件中,发现计时器只能精确到秒,Ubuntu 中正常运行。
■ 把 win10 把计时器改回 <time.h> 中的 clock_t(下一部分代码起都改了),可以精确计时。
■ win10 下使用 PGI_ACC_TIME=1 来计时会报错:Error: internal error: invalid thread id,暂时无解。
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <math.h> 4 #include <openacc.h> 5 6 #if defined(_WIN32) || defined(_WIN64) 7 #include <C:Program FilesPGIwin6419.4includewrapsys imeb.h> 8 #define gettime(a) _ftime(a) 9 #define usec(t1,t2) ((((t2).time - (t1).time) * 1000 + (t2).millitm - (t1).millitm)) 10 //typedef struct _timeb timestruct; // 使用 -acc 选项时报错找不到 _timb 结构,只能把原始定义写在这里 11 typedef struct 12 { 13 __time64_t time; 14 unsigned short millitm; 15 short timezone; 16 short dstflag; 17 } timestruct; 18 #else 19 #include <sys/time.h> 20 #define gettime(a) gettimeofday(a, NULL) 21 #define usec(t1,t2) (((t2).tv_sec - (t1).tv_sec) * 1000000 + (t2).tv_usec - (t1).tv_usec) 22 typedef struct timeval timestruct; 23 #endif 24 25 inline float uval(float x, float y) 26 { 27 return x * x + y * y; 28 } 29 30 int main() 31 { 32 const int row = 8191, col = 1023; 33 const float height = 1.0, width = 2.0; 34 const float hx = height / row, wy = width / col; 35 const float fij = -4.0f; 36 const float hx2 = hx * hx, wy2 = wy * wy, c1 = hx2 * wy2, c2 = 1.0f / (2.0 * (hx2 + wy2)); 37 const int maxIter = 100; 38 const int colPlus = col + 1; 39 40 float *restrict u0 = (float *)malloc(sizeof(float)*(row + 1)*colPlus); 41 float *restrict u1 = (float *)malloc(sizeof(float)*(row + 1)*colPlus); 42 float *utemp = NULL; 43 44 // 初始化 45 for (int ix = 0; ix <= row; ix++) 46 { 47 u0[ix*colPlus + 0] = u1[ix*colPlus + 0] = uval(ix * hx, 0.0f); 48 u0[ix*colPlus + col] = u1[ix*colPlus + col] = uval(ix*hx, col * wy); 49 } 50 for (int jy = 0; jy <= col; jy++) 51 { 52 u0[jy] = u1[jy] = uval(0.0f, jy * wy); 53 u0[row*colPlus + jy] = u1[row*colPlus + jy] = uval(row*hx, jy * wy); 54 } 55 for (int ix = 1; ix < row; ix++) 56 { 57 for (int jy = 1; jy < col; jy++) 58 u0[ix*colPlus + jy] = 0.0f; 59 } 60 61 // 计算 62 timestruct t1, t2; 63 gettime(&t1); 64 acc_init(acc_device_nvidia); // 初始化设备,定义在 openacc.h 中,acc_device_nvidia 可用 4 代替 65 for (int iter = 0; iter < maxIter; iter++) 66 { 67 #pragma acc kernels copy(u0[0:(row + 1) * colPlus], u1[0:(row + 1) * colPlus]) // 使用 kernels 和 loop 68 #pragma acc loop independent // 显式说明各次循环之间独立 69 for (int ix = 1; ix < row; ix++) 70 { 71 #pragma acc loop independent // PGI 18.04 上不加这一行也行,PGI 19.04 上不加这一行会报 72 for (int jy = 1; jy < col; jy++) // Complex loop carried dependence of u0->,u1-> prevents parallelization. Inner sequential loop scheduled on accelerator. 73 { 74 u1[ix*colPlus + jy] = (c1*fij + wy2 * (u0[(ix - 1)*colPlus + jy] + u0[(ix + 1)*colPlus + jy]) + 75 hx2 * (u0[ix*colPlus + jy - 1] + u0[ix*colPlus + jy + 1])) * c2; 76 } 77 } 78 utemp = u0, u0 = u1, u1 = utemp; 79 } 80 gettime(&t2); 81 82 long long timeElapse = usec(t1, t2); 83 #if defined(_WIN32) || defined(_WIN64) 84 printf(" Elapsed time: %13ld ms. ", timeElapse); 85 #else 86 printf(" Elapsed time: %13ld us. ", timeElapse); 87 #endif 88 free(u0); 89 free(u1); 90 acc_shutdown(acc_device_nvidia); // 关闭设备 91 //getchar(); 92 return 0; 93 }
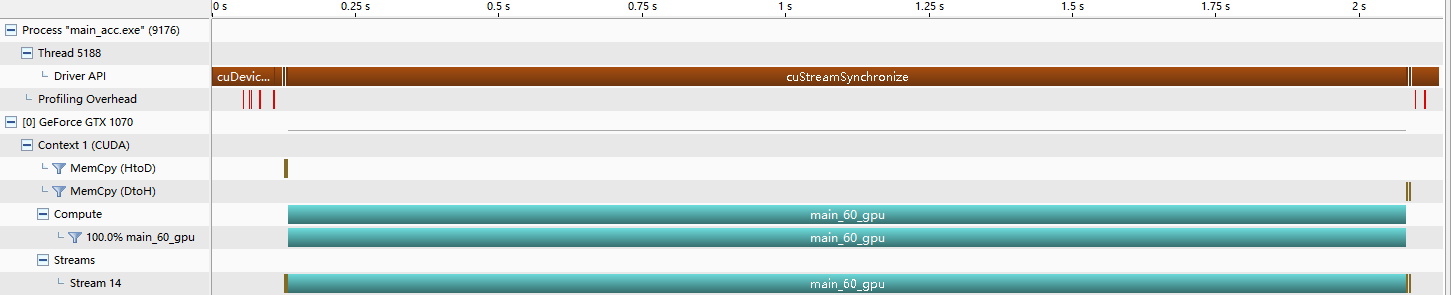
● 输出结果,win10 下改了计时器以后运行时间 2370 ms
cuan@CUAN:~$ pgcc -c99 -acc -Minfo main.c -o main.exe main: 57, Memory zero idiom, loop replaced by call to __c_mzero4 65, Generating copy(u1[:colPlus*(row+1)],u0[:colPlus*(row+1)]) FMA (fused multiply-add) instruction(s) generated 69, Loop is parallelizable 72, Loop is parallelizable Generating Tesla code 69, #pragma acc loop gang, vector(4) /* blockIdx.y threadIdx.y */ 72, #pragma acc loop gang, vector(32) /* blockIdx.x threadIdx.x */ uval: 28, FMA (fused multiply-add) instruction(s) generated cuan@CUAN:~$ ./main.exe launch CUDA kernel file=/home/cuan/main.c function=main line=72 device=0 threadid=1 num_gangs=32768 num_workers=4 vector_length=32 grid=32x1024 block=32x4 ... //98 行相同的内容,每个展开的循环一个 kernel launch CUDA kernel file=/home/cuan/main.c function=main line=72 device=0 threadid=1 num_gangs=32768 num_workers=4 vector_length=32 grid=32x1024 block=32x4 Elapsed time: 2114716 us. Accelerator Kernel Timing data /home/cuan/main.c main NVIDIA devicenum=0 time(us): 1,065,303 65: data region reached 200 times 65: data copyin transfers: 400 device time(us): total=517,460 max=1,436 min=1,284 avg=1,293 78: data copyout transfers: 600 device time(us): total=514,281 max=1,359 min=3 avg=857 67: compute region reached 100 times 72: kernel launched 100 times grid: [32x1024] block: [32x4] device time(us): total=33,562 max=380 min=331 avg=335 elapsed time(us): total=35,879 max=433 min=349 avg=358 cuan@CUAN:~$ pgcc -c99 -acc -Minfo main.c -o main-fast.exe -fast // 使用 -fast 选项 main: 47, uval inlined, size=3 (inline) file main.c (26) // 47 ~ 53 行也尝试优化 45, Loop not fused: different loop trip count Loop not vectorized: data dependency Loop unrolled 2 times 48, uval inlined, size=3 (inline) file main.c (26) 52, uval inlined, size=3 (inline) file main.c (26) 50, Loop not vectorized: data dependency Loop not vectorized: may not be beneficial Loop unrolled 2 times 53, uval inlined, size=3 (inline) file main.c (26) 57, Memory zero idiom, loop replaced by call to __c_mzero4 65, Generating copy(u1[:colPlus*(row+1)],u0[:colPlus*(row+1)]) Loop not vectorized/parallelized: contains call // 65 行拒绝优化 FMA (fused multiply-add) instruction(s) generated 69, Loop is parallelizable Loop not fused: no successor loop // 69 行拒绝优化 72, Loop is parallelizable Generating Tesla code 69, #pragma acc loop gang, vector(4) /* blockIdx.y threadIdx.y */ 72, #pragma acc loop gang, vector(32) /* blockIdx.x threadIdx.x */ 72, Loop not vectorized: data dependency // 72 行拒绝优化 Loop unrolled 2 times cuan@CUAN:~$ ./main-fast.exe launch CUDA kernel file=/home/cuan/main.c function=main line=72 device=0 threadid=1 num_gangs=32768 num_workers=4 vector_length=32 grid=32x1024 block=32x4 ... // 跟没有 -fast 一样 launch CUDA kernel file=/home/cuan/main.c function=main line=72 device=0 threadid=1 num_gangs=32768 num_workers=4 vector_length=32 grid=32x1024 block=32x4 Elapsed time: 2147056 us. // 速度影响不大 Accelerator Kernel Timing data /home/cuan/main.c main NVIDIA devicenum=0 time(us): 1,071,217 65: data region reached 200 times 65: data copyin transfers: 400 device time(us): total=520,516 max=1,478 min=1,283 avg=1,301 78: data copyout transfers: 600 device time(us): total=516,921 max=1,370 min=2 avg=861 67: compute region reached 100 times 72: kernel launched 100 times grid: [32x1024] block: [32x4] device time(us): total=33,780 max=363 min=333 avg=337 elapsed time(us): total=41,693 max=1,077 min=369 avg=416
● 使用 Nvvp 分析,发现密密麻麻的都是内存拷贝,计算反而是瞬间完成:
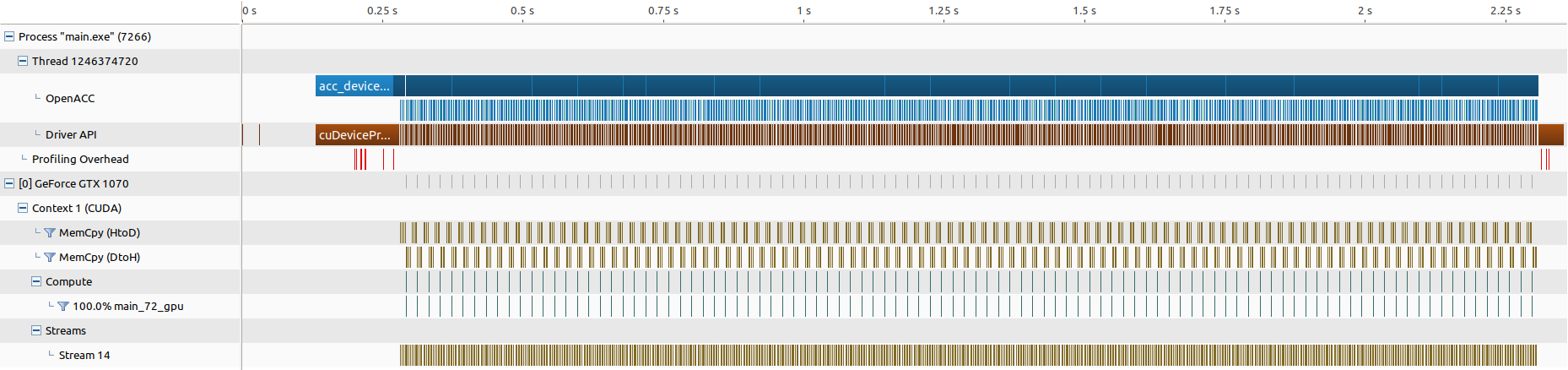
■ 注意数据管理导语 copy 是在 for(int iter=1;...) 内部的,所以会生成 100 个独立内核来运行,如果把它放到外侧(第 67 行改到 65 行之前)则会报错有以下报错:
PGC-S-0155-Cannot determine bounds for array u0 (main.c: 65) // 指针中不含有数组大小的信息 PGC-S-0155-Cannot determine bounds for array u1 (main.c: 65) main: 57, Memory zero idiom, loop replaced by call to __c_mzero4 66, Loop carried scalar dependence for u0 at line 74,78 Scalar last value needed after loop for u0 at line 88 Loop carried scalar dependence for u1 at line 74 Scalar last value needed after loop for u1 at line 89 Scalar last value needed after loop for u0 at line 88 Parallelization would require privatization of array u1[(colPlus)*i2+colPlus+1:i1+i2+1022] Generating Tesla code 66, #pragma acc loop seq // 串行执行 69, #pragma acc loop seq 72, #pragma acc loop vector(128) /* threadIdx.x */ 66, Loop carried scalar dependence for u1 at line 78 Loop carried scalar dependence for u0 at line 78 Loop carried scalar dependence for u1 at line 78 Parallelization would require privatization of array u1[(colPlus)*i2+colPlus+1:i1+i2+1022]
● 使用静态数组,此时可将数据管理导语 copy 放到 for之前,win10 下能运行,Linux上默认栈为 8 MB(ulimited -a),最大可调整为 64 MB(ulimited -s),两个数组除非调小否则刚好装不下,会报 dump core。
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <math.h> 4 #include <time.h> 5 #include <openacc.h> 6 7 #if defined(_WIN32) || defined(_WIN64) 8 #include <C:Program FilesPGIwin6419.4includewrapsys imeb.h> 9 #define timestruct clock_t 10 #define gettime(a) (*(a) = clock()) 11 #define usec(t1,t2) (t2 - t1) 12 #else 13 #include <sys/time.h> 14 #define gettime(a) gettimeofday(a, NULL) 15 #define usec(t1,t2) (((t2).tv_sec - (t1).tv_sec) * 1000000 + (t2).tv_usec - (t1).tv_usec) 16 typedef struct timeval timestruct; 17 #endif 18 19 inline float uval(float x, float y) 20 { 21 return x * x + y * y; 22 } 23 24 int main() 25 { 26 const int row = 8191, col = 1023, colPlus = col + 1; 27 const float height = 1.0, width = 2.0; 28 const float hx = height / row, wy = width / col; 29 const float fij = -4.0f; 30 const float hx2 = hx * hx, wy2 = wy * wy, c1 = hx2 * wy2, c2 = 1.0f / (2.0 * (hx2 + wy2)); 31 const int maxIter = 100; 32 33 float u0[(row + 1) * (col + 1)]; 34 float u1[(row + 1) * (col + 1)]; 35 36 // 初始化 37 for (int ix = 0; ix < (row+1) * colPlus; ix++) 38 u0[ix] = 0.0f; 39 for (int ix = 0; ix <= row; ix++) 40 { 41 u0[ix*colPlus + 0] = u1[ix*colPlus + 0] = uval(ix * hx, 0.0f); 42 u0[ix*colPlus + col] = u1[ix*colPlus + col] = uval(ix*hx, col * wy); 43 } 44 for (int jy = 0; jy <= col; jy++) 45 { 46 u0[jy] = u1[jy] = uval(0.0f, jy * wy); 47 u0[row*colPlus + jy] = u1[row*colPlus + jy] = uval(row*hx, jy * wy); 48 } 49 50 // 计算 51 timestruct t1, t2; 52 gettime(&t1); 53 acc_init(acc_device_nvidia); 54 #pragma acc kernels copy(u0[0:(row + 1) * colPlus], u1[0:(row + 1) * colPlus]) // 换到 for (int iter = 0;...) 前面 55 for (int iter = 0; iter < maxIter; iter++) 56 { 57 if (iter % 2) // iter 奇偶性分类源数组和目标数组 58 { 59 #pragma acc loop independent 60 for (int ix = 1; ix < row; ix++) 61 { 62 for (int jy = 1; jy < col; jy++) 63 { 64 u0[ix*colPlus + jy] = (wy2 * (u1[(ix - 1) * colPlus + jy] + u1[(ix + 1) * colPlus + jy]) + 65 hx2 * (u1[ix * colPlus + (jy - 1)] + u1[ix * colPlus + (jy + 1)]) + c1 * fij) * c2; 66 } 67 } 68 } 69 else 70 { 71 #pragma acc loop independent 72 for (int ix = 1; ix < row; ix++) 73 { 74 for (int jy = 1; jy < col; jy++) 75 { 76 u1[ix*colPlus + jy] = (wy2 * (u0[(ix - 1) * colPlus + jy] + u0[(ix + 1) * colPlus + jy]) + 77 hx2 * (u0[ix * colPlus + (jy - 1)] + u0[ix * colPlus + (jy + 1)]) + c1 * fij) * c2; 78 } 79 } 80 } 81 } 82 gettime(&t2); 83 84 long long timeElapse = usec(t1, t2); 85 #if defined(_WIN32) || defined(_WIN64) 86 printf(" Elapsed time: %13ld ms. ", timeElapse); 87 #else 88 printf(" Elapsed time: %13ld us. ", timeElapse); 89 #endif 90 acc_shutdown(acc_device_nvidia); 91 //getchar(); 92 return 0; 93 }
● 输出结果,在 Windows 里结果如下,在 WSL 里运行时间为 849 ms
● 使用 Nvvp 分析,发现内存拷贝只有首尾两次,中间全在 GPU: