▶ 继上一篇(http://www.cnblogs.com/cuancuancuanhao/p/8536734.html)中用到的中括号记法
● 中括号记法,实际就是数组的矩阵写法而已(参见下面的甘永超公式![]() ,just for fun)。在本次编程中大量使用了二维数组还有 float4 这种数据类型,采用中括号记法有助于减少书写量和占用空间,方便理解。一方面是在并行编程环境中,不同的工作项具有不等的索引号(get_gloabal_id(X),get_group_id(X),get_local_id(X)),在核函数代码中共用一个(全局内存 / 局部内存)的数组名时分别指向了不同的位置,希望用一种简单的写法来理解不同的工作项究竟是怎么安排的(行优先 / 列优先?连续几个元素?等间隔跨越几个元素?);另一方面是在循环的不同迭代中,需要读写的数组索引随循环变量的改变而改变,也需要一种方法来呈现所有次迭代下来,究竟取遍了目标数组中的哪些元素。
,just for fun)。在本次编程中大量使用了二维数组还有 float4 这种数据类型,采用中括号记法有助于减少书写量和占用空间,方便理解。一方面是在并行编程环境中,不同的工作项具有不等的索引号(get_gloabal_id(X),get_group_id(X),get_local_id(X)),在核函数代码中共用一个(全局内存 / 局部内存)的数组名时分别指向了不同的位置,希望用一种简单的写法来理解不同的工作项究竟是怎么安排的(行优先 / 列优先?连续几个元素?等间隔跨越几个元素?);另一方面是在循环的不同迭代中,需要读写的数组索引随循环变量的改变而改变,也需要一种方法来呈现所有次迭代下来,究竟取遍了目标数组中的哪些元素。

● 定义简单的中括号记法,对于代码 for (int i = 0; i < 2; tempA[i] = A[i * 2], i++); ,我们可以把这个过程记作下面这张图,其实代表了两个独立的赋值过程。
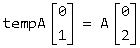
● 对于索引数量较多的情形,使用 “~” 来省略中间的部分,如对于代码(变量定义同前面的乘法代码,TILE_DIM = 16,colA = 256) for (int i = 0; i < TILE_DIM; tempA[i] = A[i * colA], i++); ,写作下面这张图,索引连续时写个开头和结尾元素就够了,不连续的时候要写清楚是怎么取值的。
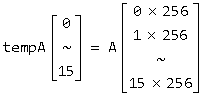
♠ 加法。只有一个维度的两个中括号记法的元素可以相加,意思是 “索引取到更多单值”,只是合并了两个独立的循环而已,与矩阵加法(对应元素相加)不同。基本原理如下图(1)。对于代码 for (int i = 0; i < 2; tempA[i] = A[...], i++);for (int i = 2; i < 4; tempA[i] = A[...], i++); ,可以写作如下图(2)。
(1)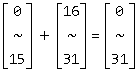 (2)
(2)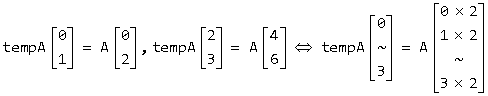
● 数乘。中括号记法的元素可以与一个标量相乘,表示取一些等间隔的离散的值,如下图。常见的是在一个循环的不同次迭代中需要从一个二维数组中等间隔的读取或写入元素。
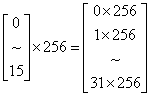
● 直和。具有两个维度的两个中括号记法的元素可以相加,但是加的结果是遍历两个相加的中括号中值的所有组合,而不是简单的把两个中括号连接在一起。相当于合并两个嵌套的循环,将高维的数组索引压扁为一维的索引,如下代码可以写作后面的图。
1 #define TILE_DIM 16 // size_t globalSize[2] = { rowA, colA = 256 }, localSize[2] = { 16, 16 }; 2 3 __kernel void kernel(__global float *A, int colA) 4 { 5 __local float tempA[TILE_DIM * TILE_DIM] 6 const int localRow = get_local_id(0), localCol = get_local_id(1); 7 const int globalRow = get_global_id(0), globalCol = fet_global_id(1); 8 9 ... 10 11 tempA[localRow * TILE_DIM + lobalCol] = A[globalRow * colA + globalCol]; 12 13 ... 14 }
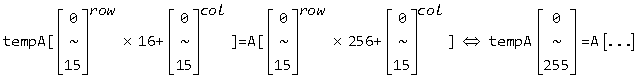
● 顺着捋一遍 multiply06 的算法过程。
1 // multiply.cl 2 #define TILE_DIM 16 3 #define nAsub 2 4 #define nBsub 2 5 6 __kernel void multiply06(__global float *inputA, __global float *inputB, __global float *outputC, int colA, int colB) 7 { 8 __local float4 Asub[TILE_DIM * nAsub][TILE_DIM], Bsub[TILE_DIM * nBsub][TILE_DIM]; 9 const int localRow = get_local_id(0), localCol = get_local_id(1); 10 const int groupRow = get_group_id(0) * get_local_size(0) * 4 * nAsub, groupCol = get_group_id(1) * get_local_size(1) * 4 * nBsub; 11 const int nTile = colA / TILE_DIM; 12 int t, k, subi, subj; 13 float4 acc[4 * nAsub][nBsub], tempA, tempB; 14 for (k = 0; k < 4 * nAsub; k++) 15 { 16 for (subj = 0; subj < nBsub; subj++) 17 acc[k][subj] = (float4)(0.f); 18 } 19 for (t = 0; t < nTile; t++) 20 { 21 for (subi = 0; subi < nAsub; subi++) 22 { 23 Asub[TILE_DIM * subi + localRow][localCol] = (float4)(inputA[(groupRow + TILE_DIM * (4 * subi + 0) + localRow) * colA + TILE_DIM * t + localCol], 24 inputA[(groupRow + TILE_DIM * (4 * subi + 1) + localRow) * colA + TILE_DIM * t + localCol], 25 inputA[(groupRow + TILE_DIM * (4 * subi + 2) + localRow) * colA + TILE_DIM * t + localCol], 26 inputA[(groupRow + TILE_DIM * (4 * subi + 3) + localRow) * colA + TILE_DIM * t + localCol]); 27 } 28 for (subj = 0; subj<nBsub; subj++) 29 Bsub[TILE_DIM * subj + localRow][localCol] = vload4(((TILE_DIM * t + localRow) * colB + groupCol + TILE_DIM * 4 * subj + localCol * 4) / 4, inputB); 30 barrier(CLK_LOCAL_MEM_FENCE); 31 32 for (k = 0; k < TILE_DIM; k++) 33 { 34 for (subi = 0; subi < nAsub; subi++) 35 { 36 for (subj = 0; subj < nBsub; subj++) 37 { 38 tempA = Asub[TILE_DIM * subi + localRow][k]; 39 tempB = Bsub[TILE_DIM * subj + k][localCol]; 40 acc[4 * subi + 0][subj] += tempA.x * tempB; 41 acc[4 * subi + 1][subj] += tempA.y * tempB; 42 acc[4 * subi + 2][subj] += tempA.z * tempB; 43 acc[4 * subi + 3][subj] += tempA.w * tempB; 44 } 45 } 46 } 47 barrier(CLK_LOCAL_MEM_FENCE); 48 } 49 for (k = 0; k < 4 * nAsub; k++) 50 { 51 for (subj = 0; subj < nBsub; subj++) 52 vstore4(acc[k][subj], ((groupRow + TILE_DIM * k + localRow) * colB + groupCol + TILE_DIM * 4 * subj + localCol * 4) / 4, outputC); 53 } 54 }
■ 第 23 行左边,最后一个等价是考虑到子矩阵 Asub 的尺寸
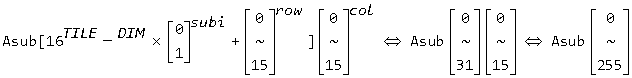
■ 第 23 行右边,写成列的形式(一行写不下),可见 Aub 的一个元素的四个分量分别取遍 inputA 中特定行上的所有列,最后一个矩阵四个元素合并的话刚好等于 inputA 的所有元素。
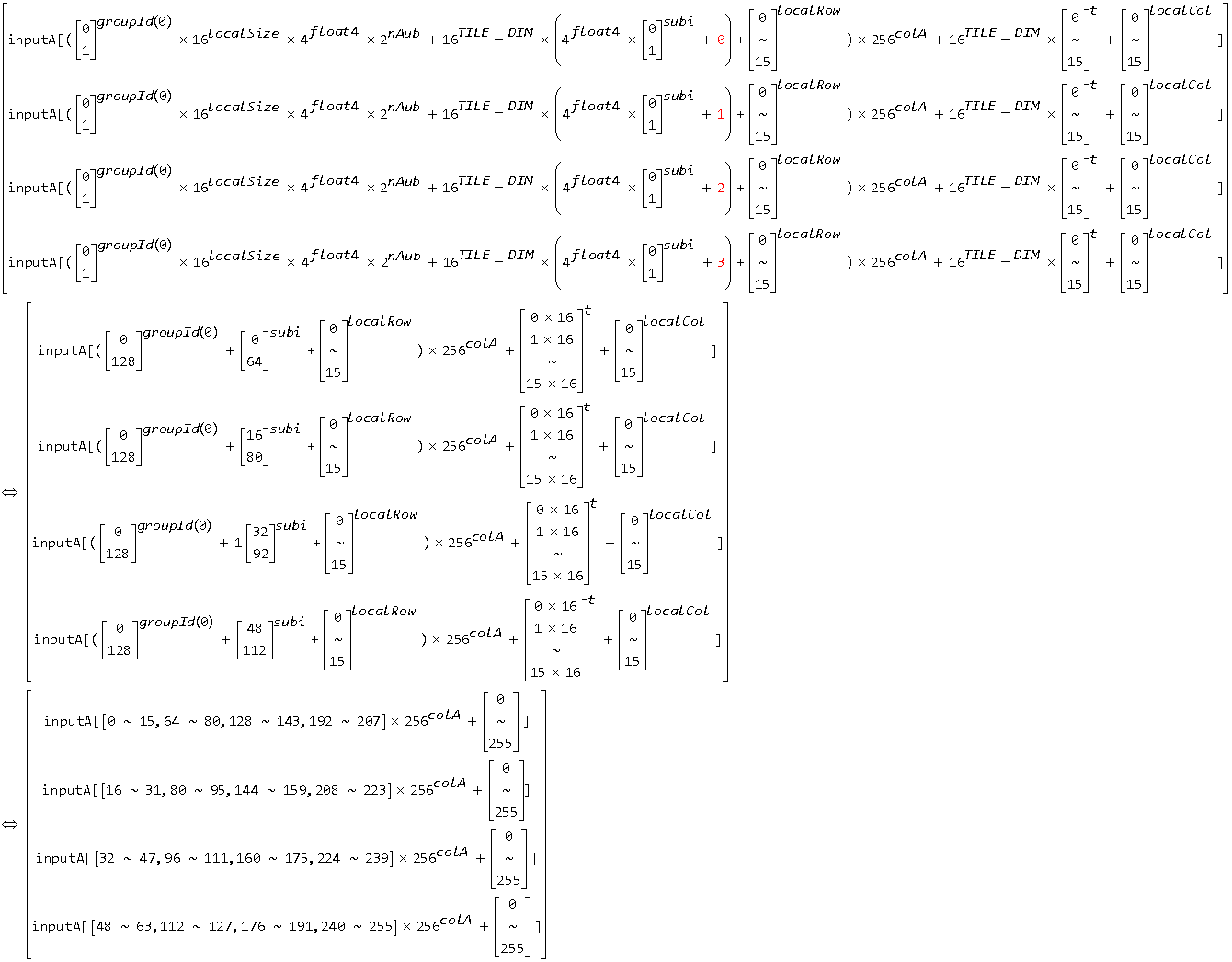
■ 第 29 行,左边类似上面等式左边的结果,右边取遍了 inputB 的所有元素(考虑到 一个 Bsub 的元素存储了 inputB 中横向上连续 4 个元素)。
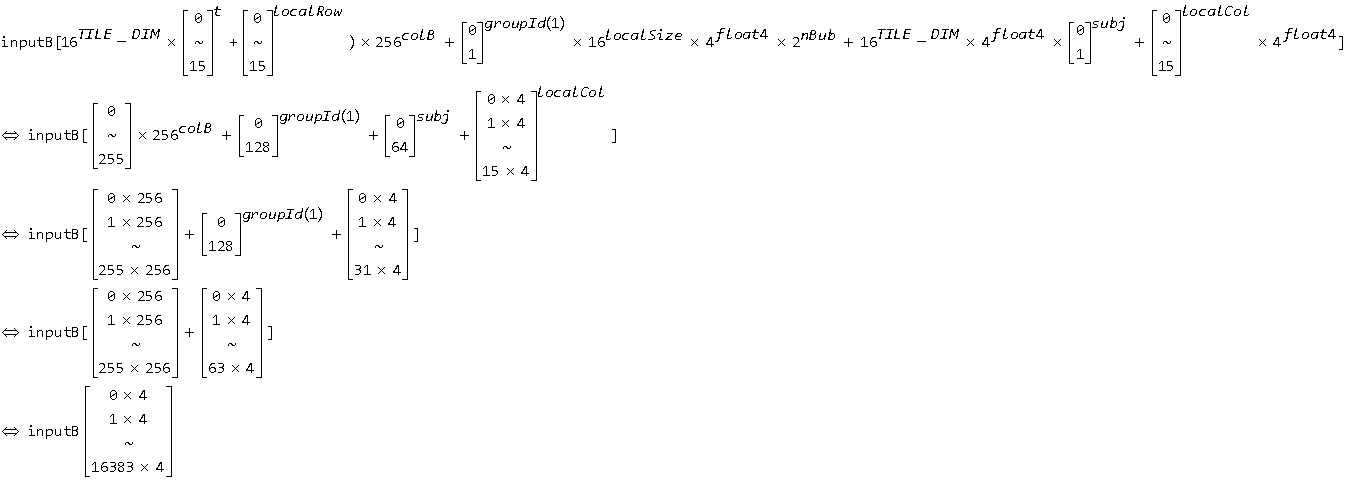
■ 第 52 行类似第 29 行,只不过把 TILE_DIM * t 换成了 groupRow + TILE_DIM * k 而已,而这两个式子本身等价。
● 总结
■ 上述计算中经常出现【[不超过256内每隔128 元素取一个] + [不超过128内每隔 64 元素取一个] + [不超过64内每隔 16 个元素取一个] + [取遍 0 到 15 号元素]】的直和形式,实际上表现了嵌套循环中不同层次的循环变量对最内层数组索引的控制,或者说是对数组的透视。
■ 在写代码时使用这种方法进行检查,有助于检查数组索引是否有重叠或者间断区域(检查发生直和的部分是否恰好能连接起来,没有对同一个索引的多次计算,或者漏掉某个索引根本没用到),防止出错。