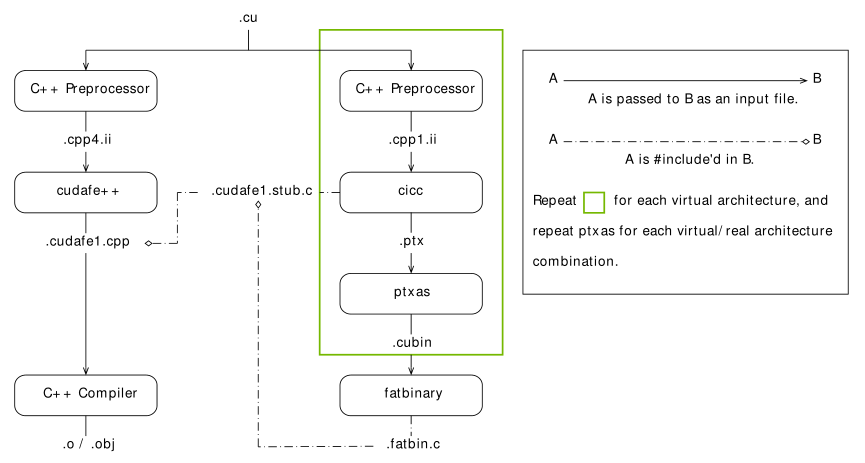
● nvcc 编译流程图
● sm 是向前兼容的,高的版本号是在低版本号的基础上添加了新功能得到的,同一 compute_XY 编译的 .cu 文件仅能向后 sm_ZW 的实 GPU 版本(Z > X)


● 虚拟 GPU 完全由它提供给应用程序的一组功能或特征来定义
● PTX 可以视为虚拟 GPU 的 汇编,以文本格式表示,便于进一步编译为各格式的二进制机器码
● 编译时应尽量降低虚拟 GPU 版本(增加兼容性),同时尽量提高实际 GPU 版本(在知道运行 GPU 的情况下)
● 即时编译(JIT)模式下驱动知道 runtime GPU 的信息,可以编译最佳版本的代码,离线编译和 JIT 的流程图分别如下:

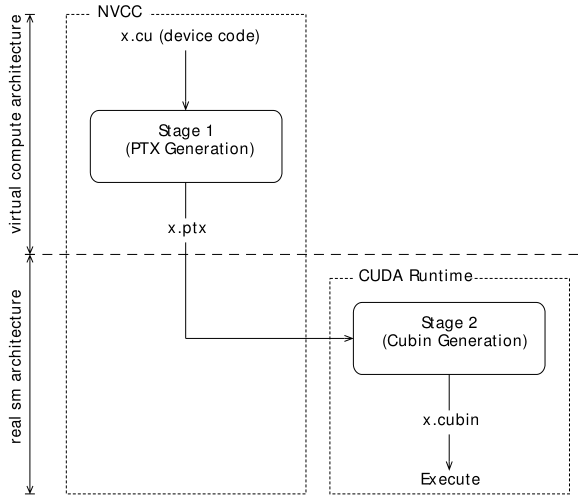
● 仅指定虚 GPU 版本而不指定实 GPU 版本时(如 nvcc x.cu -arch=compute_50 [-code=compute_50]),PTX 将延迟到运行时才进行编译,有启动延迟
● 消灭启动延迟的方法:
■ CUDA 驱动编译缓存
■ 编译时指定多个实 GPU 版本(如 nvcc x.cu -arch=compute_50 -code=sm_50,sm_52),设备函数的多个版本存储在 x.fatbin 中,运行时由驱动自动识别和调用
● 关于 -arch 和 -code 的要点
■ 仅指定 -arch 为虚 GPU 版本,-code 自动匹配最接近的版本(如 nvcc x.cu -arch=compute_50 等价于 nvcc x.cu -arch=compute_50 -code=compute_50)
■ 仅指定 -arch 为实 GPU 版本,-code 自动匹配最接近的版本(如 nvcc x.cu -arch=sm_50 等价于 nvcc x.cu -arch=compute_50 -code=sm_50,compute_50)
■ 同时指定 -arch 和 -code 为虚 GPU 版本,必须一致
■ 均不指定,使用默认值(如 nvcc x.cu 等价于 nvcc x.cu -arch=compute_30 -code=)
■ 默认 -arch 值就是 sm_XX
■ 编译第一阶段中有宏定义 __CUDA_ARCH__ 代表虚 GPU 版本,可用于 __device__ 函数中,用于指明该函数所用的虚 GPU 版本
● 没有指定 --keep 时 nvcc 使用临时目录来保存中间文件,编译完成后立即删除,Windows 中使用环境变量 TEMP 或默认目录 C:Windows emp,Linux 使用环境变量 TMPDIR 或默认目录 /tmp
● CUDA 5.0 开始支持分离编译,流程图如下。
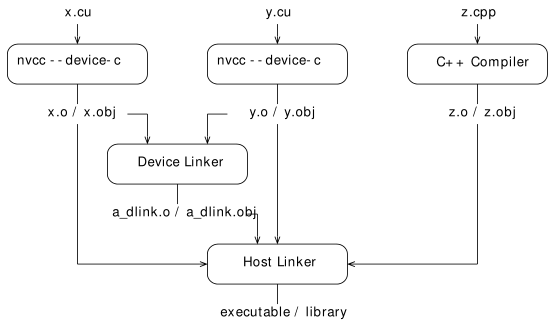
■ 自己在电脑上实验分离编译,VS中能通过,gcc 中没有成功,编译过程没有问题,运行时提示 couldn't get the symbol addr,留坑。
1 //---------- b.h ---------- 2 #define N 8 3 extern __device__ int g[N]; 4 extern __device__ void bar(void); 5 6 //---------- b.cu ---------- 7 #include "b.h" 8 __device__ int g[N]; 9 __device__ void bar(void) 10 { 11 g[threadIdx.x]++; 12 } 13 14 //---------- a.cu ---------- 15 #include <stdio.h> 16 #include "b.h" 17 __global__ void foo(void) 18 { 19 __shared__ int a[N]; 20 a[threadIdx.x] = threadIdx.x; 21 __syncthreads(); 22 g[threadIdx.x] = a[blockDim.x - threadIdx.x - 1]; 23 bar(); 24 } 25 26 int main(void) 27 { 28 unsigned int i; 29 int *dg, hg[N]; 30 int sum = 0; 31 foo << <1, N >> >(); 32 if (cudaGetSymbolAddress((void**)&dg, g)) 33 { 34 printf("couldn't get the symbol addr "); 35 return 1; 36 } 37 if (cudaMemcpy(hg, dg, N * sizeof(int), cudaMemcpyDeviceToHost)) 38 { 39 printf("couldn't memcpy "); 40 return 1; 41 } 42 for (i = 0; i < N; i++) 43 sum += hg[i]; 44 if (sum == 36) 45 printf("PASSED "); 46 else 47 printf("FAILED (%d) ", sum); 48 return 0; 49 }
■ 书上用到的编译命令
nvcc --gpu-architecture=sm_50 --device-c a.cu b.cu nvcc --gpu-architecture=sm_50 a.o b.o nvcc --gpu-architecture=sm_50 --device-c a.cu b.cu nvcc --gpu-architecture=sm_50 --device-link a.o b.o --output-file link.o g++ a.o b.o link.o --library-path=<path> --library=cudart nvcc --gpu-architecture=sm_50 --device-link a.o b.o --cubin --output-file link.cubin nvcc --gpu-architecture=sm_50 --device-c a.cu b.cu nvcc --lib a.o b.o --output-file test.a nvcc --gpu-architecture=sm_50 test.a nvcc --gpu-architecture=sm_50 --device-c a.ptx nvcc --gpu-architecture=sm_50 --device-c a.cu b.cu nvcc --gpu-architecture=sm_50 --device-link a.o b.o --output-file link.o nvcc --lib --output-file libgpu.a a.o b.o link.o g++ host.o --library=gpu --library-path=<path> --library=cudadevrt --library=cudart