均值偏移(Mean shift)聚类算法是一种基于滑动窗口(sliding-window)的算法,它视图找到密集的数据点。而且,它还是一种基于中心的算法,他的目标是定位每一组群/类的中心点,通过更新中心点的候选点来实现滑动窗口中点的平均值。这些候选窗口在后期处理阶段被过滤,以消除几乎重复的部分,形成最后一组中心点及其对应的组。
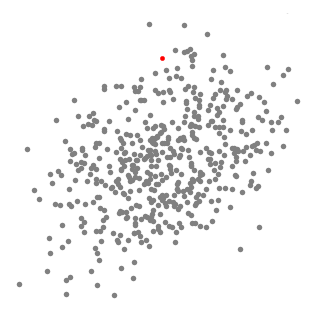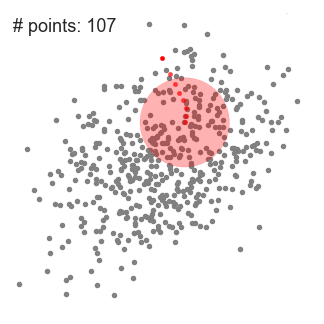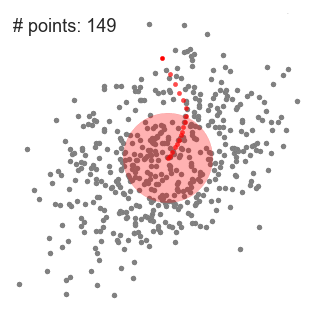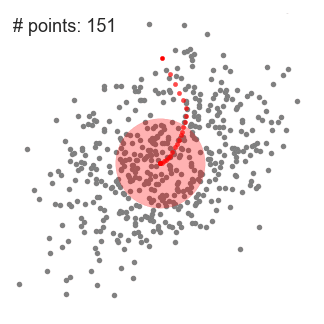
- 为了解释这一变化,我们将考虑二维空间中的一组点。我们从一个点C(随机选择)为中心的圆形滑窗开始,以半径r为内核。均值偏移是一种爬山算法,他需要在内个步骤中反复地将这个内核移动到一个更高的密度区域,直到收敛。
- 在每一次迭代中,滑动窗口会移向密度较高的区域,将中心点移动到窗口内的点的平均值(因此得名)。滑动窗口中的密度与它内部的点的数量成比例。自然地,通过移向窗口中的点的平均值,它将逐渐向更高的点密度方向移动。
- 我们继续根据均值移动滑动窗口,知道没有方向移动可以容纳内核中的更多点。看看上面的图表;我们一直在移动这个圆,知道我们不在增加密度(也就是窗口中的点数)。
- 步骤1到3的过程是用许多滑动窗口完成的,知道所有的点都位于一个窗口内。当多个滑动窗口重叠的时候,包含最多的点的窗口会被保留。然后,数据点根据它们所在的滑动窗口聚类。
下面展示了从端到端所有滑动窗口的这个过程演示。每个黑点代表一个滑动窗口的质心,每个灰色点都是一个数据点。

与K-Means聚类相比,均值偏移不需要选择聚类的数量,因为它会自动地发现这一点。这是一个巨大的优势。聚类中心收敛于最大密度的事实也是非常可取的,因为它非常直观地理解并适合于一种自然数据驱动。缺点是选择窗口大小/半径r是非常关键的,所以不能疏忽。