一.dex文件的生成
我们可以通过java文件来生成一个简单的dex文件
编译过程:

首先编写java代码如下:
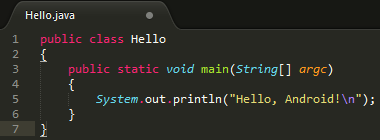
(1) 编译成 java class 文件
执行命令 : javac Hello.java
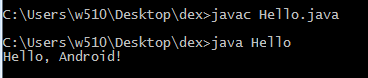
编译完成后 ,目录下生成 Hello.class 文件
(2) 编译成 dex 文件
dx --dex --output=Hello.dex Hello.class
编译正常会生成 Hello.dex 文件
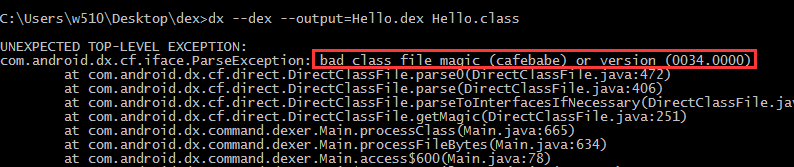
00 34指明jdk版本,这个原因是jdk版本过高了,我们得使用1.6版本的JDK来进行编译
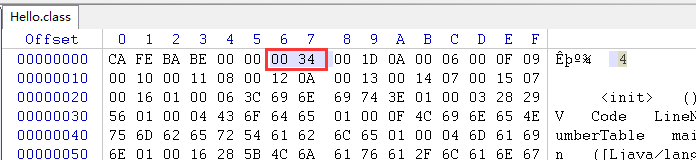
这个时候我们可以指明编译指定版本的来进行编译class文件
javac -source 1.6 -target 1.6 Hello.java
(3). 使用 ADB 运行测试
测试命令和输出结果如下 :
adb push Hello.dex /mnt/sdcard/
adb shell dalvikvm -cp /mnt/sdcard/Hello.dex Hello

第一次运行会在data/dalvik-cache目录生成一个odex的文件
有些加固没有考虑这个文件,dex的加固直接就废掉了
直接把这个文件拖到ida是可以分析的,拖到jeb就显示未知的文件格式
我们使用winhex查看,发现前面多了一些内容
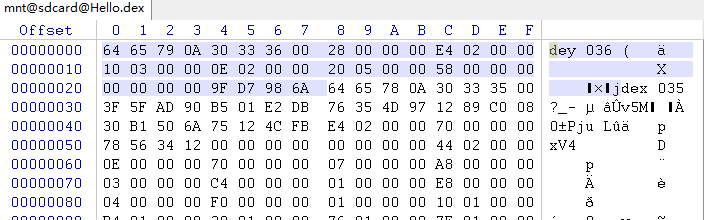
把这些内容剪切掉,在用jeb分析,就成功解析出来了
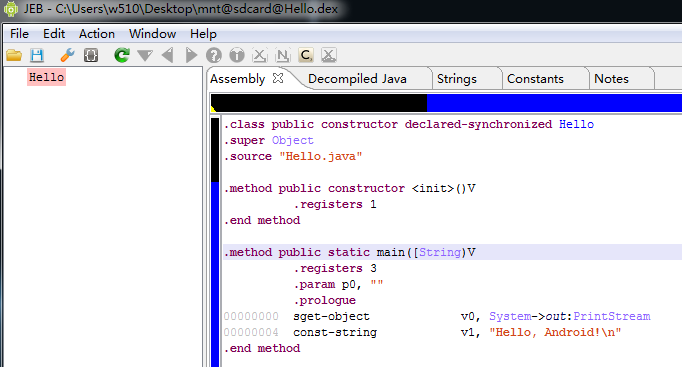
二.dalvik文件文档
文档目录
android2.3.7/dalvik/docs/dex-format.html
相关源码目录:
android2.3.7dalviklibdex
android2.3.7dalviklibdexDexFile.c dexFileParse 做主要的解析工作
需要注意的是每个Android源码版本的路径可能不一样,dex文件的格式也可能会有细微的变化,请参考相关平台的源码
用source insight来进行源码分析
分析可以使用010Editor脚本进行分析

三.dex文件格式
整体格式概要
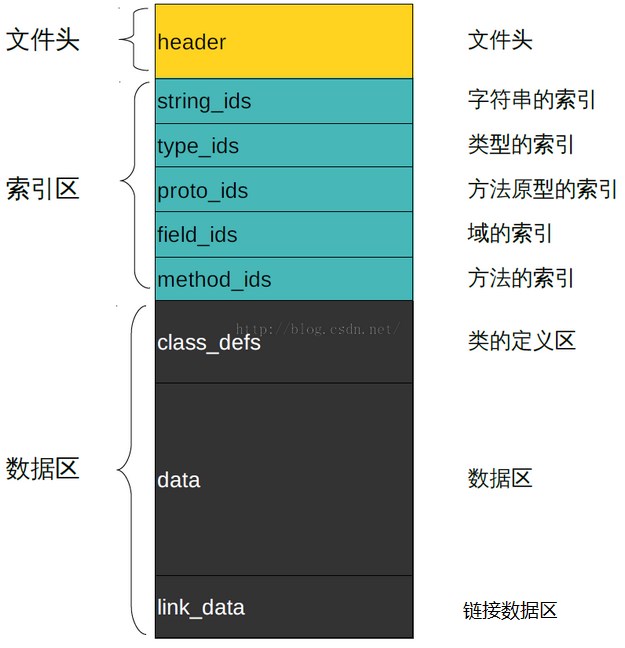
Android dex文件格式样例
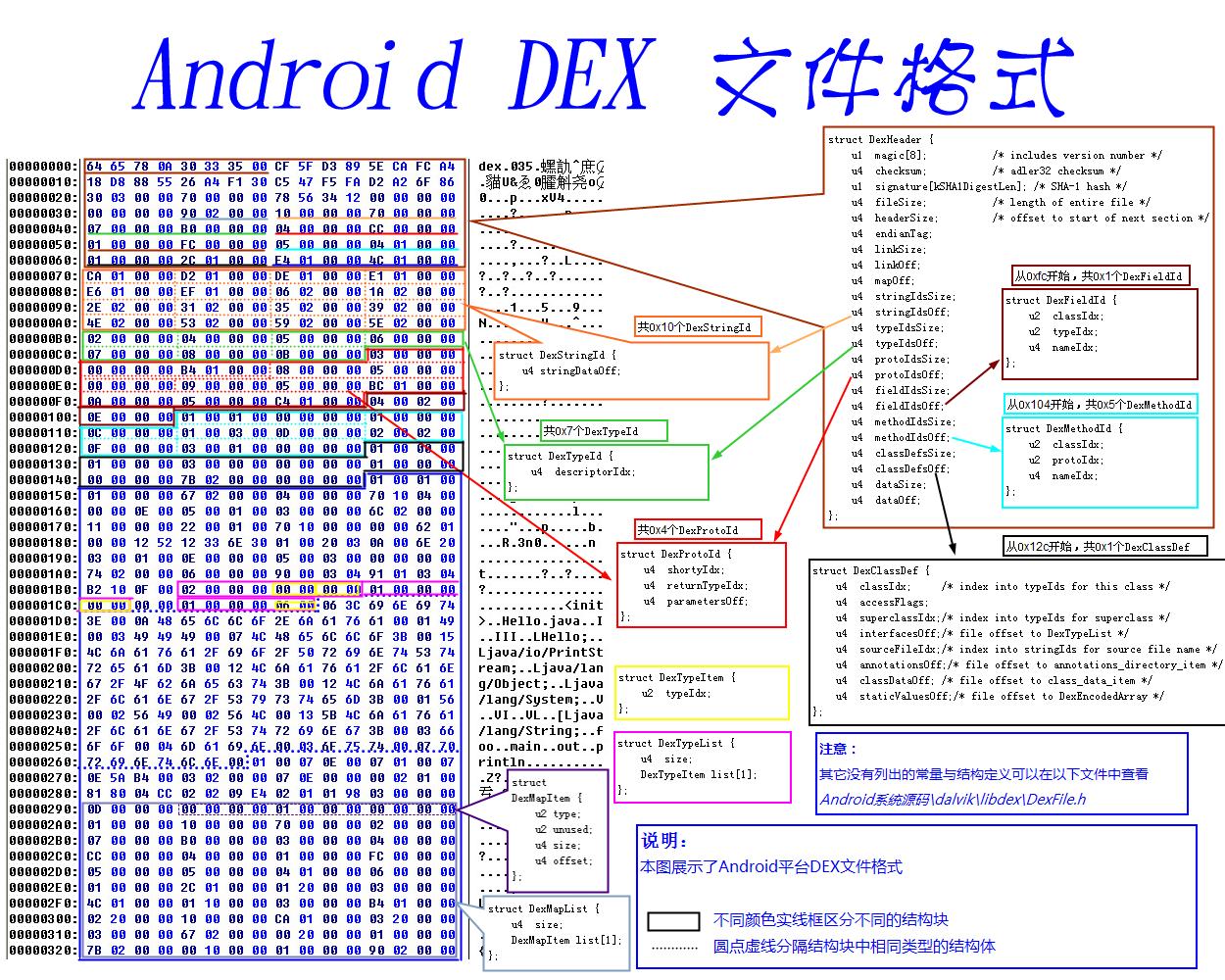
文件格式相互之间的联系

二、dex文件的解析
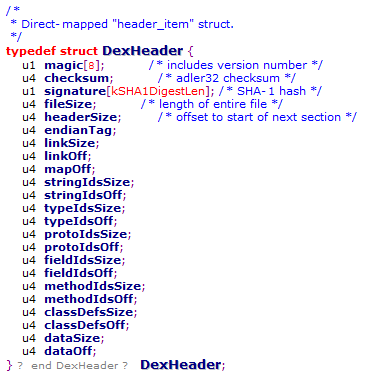
一. dex文件头
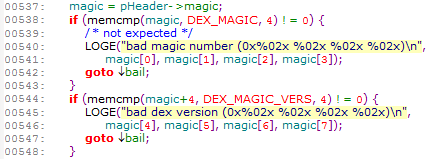
(1) magic value
在DexFile.c dexFileParse函数中 会先检查magic opt
啥是magic opt呢? 我们刚刚从cache目录拷贝出来的那个

前面的dey 036就是magic opt
在源码中会先解析magic opt,然后重设dexfile指针

重设magic opt指针后开始解析magic value
这 8 个 字节一般是常量。数组的值可以转换为一个字符串如下 :
{ 0x64 0x65 0x78 0x0a 0x30 0x33 0x35 0x00 } = "dex
035�"
(2) checksum
文件校验码 ,使用alder32 算法校验文件
先用dexheader先校验,校验失败在使用opt header去校验

其校验算法如下除去maigc,checksum 外余下的所有文件区域 ,用于检查文件错误

(3) signature
signature , 使用 SHA-1 算法 hash 除去 magic ,checksum 和 signature 外余下的所有文件区域 ,用于唯一识别本文件

由此可见我们在修改了dex文件之后,得先修正signature然后在修正checksum
(4) file_size
Dex 文件的大小 ,源码中会拿该字段和传入的长度值进行比较

(5) header_size
header 区域的大小 ,单位 Byte ,一般固定为 0x70 常量
在DexSwapVerify.c dexSwapAndVerify

高版本不知道是不是这样校验的 大于居然没有置为okay
(6) endian_tag
大小端标签 ,标准 .dex 文件格式为小端 ,此项一般固定为 0x12345678常量
CmdUtils.c 程序调用主线从
dexOpenAndMap->dexSwapAndVerifyIfNecessary->dexSwapAndVerify->swapDexHeader

这里逻辑有点绕,他默认就会转换一次, 如果是小尾,转换之后就是大尾,那么校验就不会通过
如果是大尾方式, 就转换成小尾, 校验通过,继续后面的转换流程
还一个校验是如果是odex格式,那么已经是优化之后的,则不需要转换

其转换算法如下:
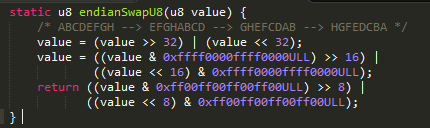
(6) link_size和link_off
这个两个字段是表示链接数据的大小和偏移值

CHECK_OFFSET_RANGE 只是检查是否超出文件指针范围

(7) map_off
map item 的偏移地址 ,该 item 属于 data 区里的内容 ,值要大于等于 data_off 的大小 。

其结构体指向:

MapItem结构体

对应的枚举值
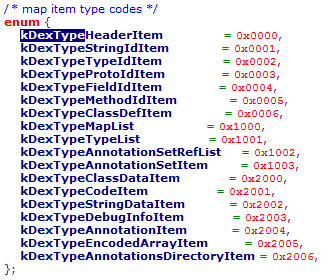
010Editor中呈现

(8) string_ids_size和string_ids_off
这两个字段表示dex中用到的所有的字符串内容的大小和偏移值,我们需要解析完这部分,然后用一个字符串池存起来,后面有其他的数据结构会用索引值来访问字符串,这个池子也是非常重要的。后面会详细介绍string_ids的数据结构
(9) type_ids_size和type_ids_off
这两个字段表示dex中的类型数据结构的大小和偏移值,比如类类型,基本类型等信息,后面会详细介绍type_ids的数据结构
(10) proto_ids_size和type_ids_off
这两个字段表示dex中的元数据信息数据结构的大小和偏移值,描述方法的元数据信息,比如方法的返回类型,参数类型等信息,后面会详细介绍proto_ids的数据结构
(11) field_ids_size和field_ids_off
这两个字段表示dex中的字段信息数据结构的大小和偏移值,后面会详细介绍field_ids的数据结构
(12) method_ids_size和method_ids_off
这两个字段表示dex中的方法信息数据结构的大小和偏移值,后面会详细介绍method_ids的数据结构
(13) class_defs_size和class_defs_off
这两个字段表示dex中的类信息数据结构的大小和偏移值,这个数据结构是整个dex中最复杂的数据结构,
他内部层次很深,包含了很多其他的数据结构,所以解析起来也很麻烦,所以后面会着重讲解这个数据结构

没有类的话,dex校验会失败
(14) data_size和data_off
这两个字段表示dex中数据区域的结构信息的大小和偏移值,这个结构中存放的是数据区域,比如我们定义的常量值等信息。
到这里我们就看完了dex的头部信息,头部包含的信息还是很多的,主要就两个个部分:
1) 魔数+签名+文件大小等信息
2) 后面的各个数据结构的大小和偏移值,都是成对出现的
先来看看整体的结构,结构体定义在DexFile.h里面

在dexFileSetupBasicPointers中设置各个子结构体,当然是在解析DexHeader之后
源码在DexFile.c文件中

在解析每个子结构体之前我们先了解下leb128格式,
源码leb128.c中解析这种格式

LEB128 ( little endian base 128 ) 格式 ,是基于 1 个 Byte 的一种不定长度的编码方式 。若第一个 Byte 的最高位为 1 ,则表示还需要下一个 Byte 来描述 ,直至最后一个 Byte 的最高位为 0 。每个 Byte 的其余 Bit
用来表示数据,这个数据类型的出现其实就是为了解决一个问题,那就是减少内存的浪费,他就是表示int类型的数值,但是int类型四个字节有时候在使用的时候有点浪费,所以就应运而生了
一. string_ids数据结构
string_ids 区索引了 .dex 文件所有的字符串
如何定位:
先在DexHeader中拿到偏移和数量

在文件偏移112(10进制)的地方有11713项string_ids也就是一个DexStringId数组
DexStringId只有一个结构体成员,他保存一个string_data_item的偏移值
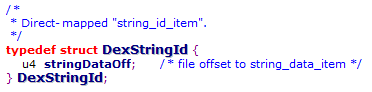
这个数组看起来是像下面这个样子的

DexStringId指向的是一个leb128的字符串(文件偏移)
在源码中简单的拿到偏移直接读取leb128即可拿到字符串
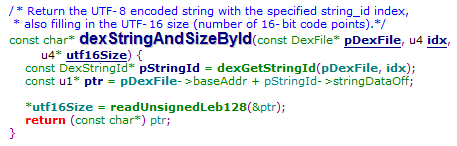
010Editor脚本解析如下:

其他一些子结构,如 type-ids , method_ids 也会引用到这些字符串
二. type_ids数据结构
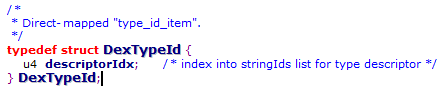
这个数据结构中存放的数据主要是描述dex中所有的类型,比如类类型,基本类型等信息。type_ids 区索引了 dex 文件里的所有数据类型 ,包括 class 类型 ,数组类型(array types)和基本类型(primitive types) 。 本区域里的元素格式为 type_ids_item ,
type_ids_item 里面 descriptor_idx 的值的意思 ,是 string_ids 里的 index 序号 ,是用来描述此type 的字符串
我们来手工找一找
第一项保存的值为695

我们定位到字符串表第695项,成功找到B

源码中调用dexStringByTypeIdx拿到指定type字符串

同JNI一样
L 表示 class 的详细描述 ,一般以分号表示 class 描述结束 ;
V 表示 void 返回类型 ,只有在返回值的时候有效 ;
[ 表示数组 ,[Ljava/lang/String; 可以对应到 java 语言里的 java.lang.String[] 类型 。
后面的其他数据结构也会使用到type_ids类型,所以我们这里解析完type_ids也是需要用一个池子来存放的,后面直接用索引index来访问即可
三. proto_ids数据结构
proto的意思是 method prototype 代表 java 语言里的一个 method 的原型
其保存的是这样一个结构体

shorty_idx :跟 type_ids 一样 ,它的值是一个 string_ids 的 index 号 ,最终是一个简短的字符串描述 ,用来说明该 method 原型
return_type_idx :它的值是一个 type_ids 的 index 号 ,表示该 method 原型的返回值类型
parameters_off :后缀 off 是 offset , 指向 method 原型的参数列表 type_list ; 若 method 没有参数 ,值为0 。

参数列表的格式是 type_list ,结构从逻辑上如下描述 。
size 表示参数的个数 ;
type_idx 是对应参数的类型 ,它的值是一个 type_ids 的 index 号 ,跟 return_type_idx 是同一个品种的东西

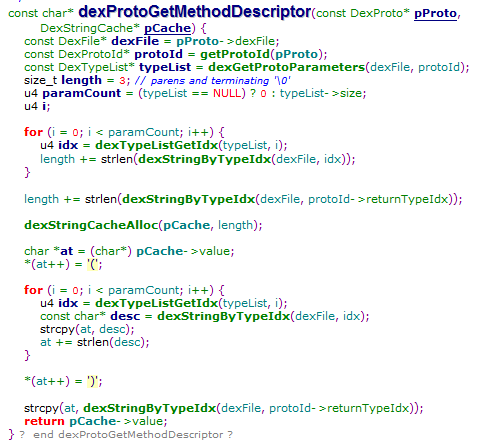
其描述Method原型算法如下:(DexProto.c)
四、field_ids数据结构
filed_ids 区里面存放的是dex 文件引用的所有的 field 。本区的元素格式是 field_id_item

class_idx :表示本 field 所属的 class 类型 , class_idx 的值是 type_ids 的一个 index , 并且必须指向一个class 类型
type_idx :表示本 field 的类型 ,它的值也是 type_ids 的一个 index
name_idx : 表示本 field 的名称 ,它的值是 string_ids 的一个 index

注意:这里的字段都是索引值,一定要区分是哪个池子的索引值,还有就是,这个数据结构我们后面也要使用到,所以需要用一个池子来存储
五、 method_ids数据结构
method_ids 是索引区的最后一个条目 ,它索引了 dex 文件里的所有的 method.

method_ids 的元素格式是 method_id_item , 结构跟 fields_ids 很相似:
class_idx :表示本 method 所属的 class 类型 , class_idx 的值是 type_ids 的一个 index , 并且必须指向一个 class 类型
name_idx :表示本 method 的名称 ,它的值是 string_ids 的一个 index
proto_idx :描述该 method 的原型 ,指向 proto_ids 的一个 index

注意:这里的字段都是索引值,一定要区分是哪个池子的索引值,还有就是,这个数据结构我们后面也要使用到,所以需要用一个池子来存储。
六、class_defs数据结构
1、class_def_item
从字面意思解释 ,class_defs 区域里存放着 class definitions , class 的定义 。它的结构较 dex 区都要复杂些 ,因为有些数据都直接指向了data 区里面 。
class_defs 的数据格式为 class_def_item

(1) class_idx:描述具体的 class 类型 ,值是 type_ids 的一个 index 。值必须是一个 class 类型 ,不能是数组类型或者基本类型 。
(2) access_flags: 描述 class 的访问类型 ,诸如 public , final , static 等 。在 dex-format.html 里 “access_flagsDefinitions” 有具体的描述 。
(3) superclass_idx:描述 supperclass 的类型 ,值的形式跟 class_idx 一样 。
(4) interfaces_off:值为偏移地址 ,指向 class 的 interfaces , 被指向的数据结构为 type_list 。class 若没有interfaces ,值为 0。
(5) source_file_idx:表示源代码文件的信息 ,值是 string_ids 的一个 index 。若此项信息缺失 ,此项值赋值为NO_INDEX=0xffff ffff
(6) annotions_off:值是一个偏移地址 ,指向的内容是该 class 的注释 ,位置在 data 区,格式为annotations_direcotry_item 。若没有此项内容 ,值为 0 。
(7) class_data_off:值是一个偏移地址 ,指向的内容是该 class 的使用到的数据 ,位置在 data 区,格式为class_data_item 。若没有此项内容 ,值为 0 。该结构里有很多内容 ,详细描述该 class 的 field ,method, method 里的执行代码等信息 ,后面有一个比较大的篇幅来讲述
class_data_item 。
(8) static_value_off:值是一个偏移地址 ,指向 data 区里的一个列表 ( list ) ,格式为 encoded_array_item。若没有此项内容 ,值为 0 。
header 里 class_defs_size = 0x01 , class_defs_off = 0x 0110 。则此段二进制描述为 :
其实最初被编译的源码只有几行 ,和 class_def_item 的表格对照下 ,一目了然
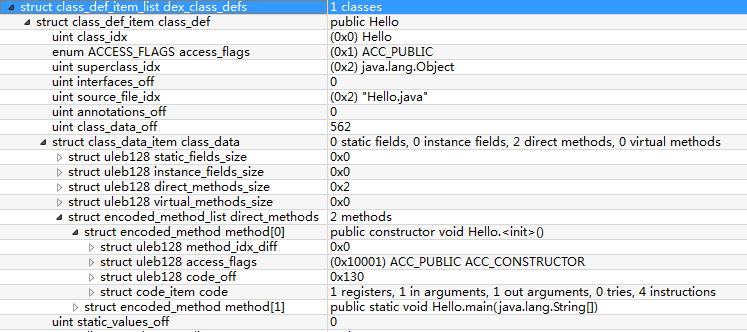
source file : Hello.java
public class Hello
{
element value associated strinigs
class_idx 0x00 LHello;
access_flags 0x01 ACC_PUBLIC
superclass_idx 0x02 Ljava/lang/Object;
interface_off 0x00
source_file_idx 0x02 Hello.java
annotations_off 0x00
class_data_off 0x0234
static_value_off 0x00
public static void main(String[] argc)
{
System.out.println("Hello, Android!
");
}
}
2、 class_def_item => class_data_item
class_data_off 指向 data 区里的 class_data_item 结构 ,class_data_item 里存放着本 class 使用到的各种数据
在DexClass.c中dexReadAndVerifyClassData来读取DexClassData
相关结构体定义如下:

3.对于DexMethod有
(1) method_idx_diff:前缀 methd_idx 表示它的值是 method_ids 的一个 index ,后缀 _diff 表示它是于另外一个 method_idx 的一个差值 ,就是相对于 encodeed_method [] 数组里上一个元素的 method_idx 的差值 。其实 encoded_filed
- > field_idx_diff 表示的也是相同的意思 ,只是编译出来的 Hello.dex 文件里没有使用到class filed 所以没有仔细讲 ,详细的参考 dex_format.html 的官网文档
(2) access_flags:访问权限 , 比如 public、private、static、final 等 。
(3) code_off:一个指向 data 区的偏移地址 ,目标是本 method 的代码实现 。被指向的结构是
code_item ,有近 10 项元素 ,后面再详细解释

4、class_def_item => class_data_item => code_item
到这里 ,逻辑的描述有点深入了 。先理一下是怎么走到这一步的 ,code_item在 dex 里处于一个什么位置
遍历过程如下:
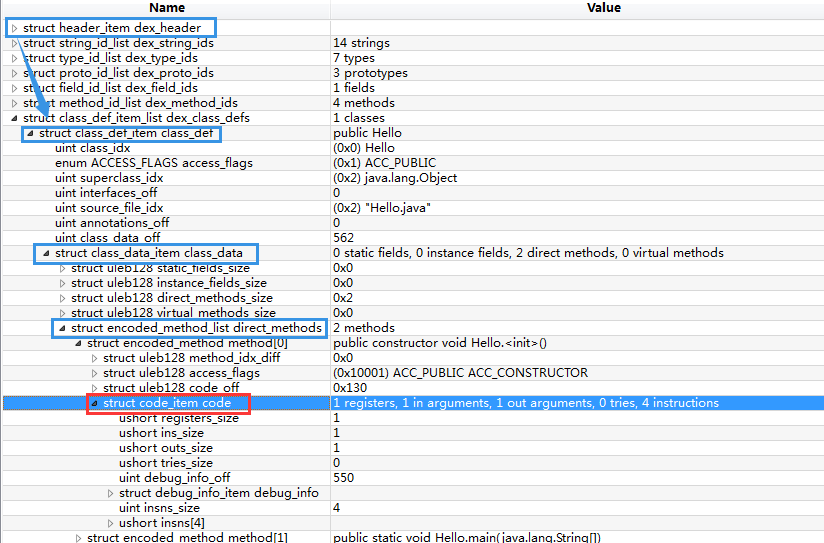
(1) dex_header拿到class_def_item_list偏移,遍历解析class_def_item
(2) 对于指定的class_def_item,每一项都有class_data_off,通过该offset定位到dex_class_data
(3) 解析dex_class_data其中在method_item中有一个code_off,即可定位到code_data在文件中的偏移

(1) registers_size:本段代码使用到的寄存器数目。
(2) ins_size:method传入参数的数目 。
(3) outs_size: 本段代码调用其它method 时需要的参数个数 。
(4) tries_size: try_item 结构的个数 。
(5) debug_off:偏移地址 ,指向本段代码的 debug 信息存放位置 ,是一个 debug_info_item 结构。
(6) insns_size:指令列表的大小 ,以 16-bit 为单位 。 insns 是 instructions 的缩写 (这里就该对着dalvik去做指令解析)
(7) padding:值为 0 ,用于对齐字节 。
(8) tries 和 handlers:用于处理 java 中的 exception , 常见的语法有 try catch 。
4、 分析 main method 的执行代码并与 smali 反编译的结果比较
在 8.2 节里有 2 个 method , 因为 main 里的执行代码是自己写的 ,分析它会熟悉很多 。偏移地址是
directive_method [1] -> code_off = 0x0148 ,二进制描述如下 :
insns 数组里的 8 个二进制原始数据 , 对这些数据的解析 ,
需要对照官网的文档 《Dalvik VM InstructionFormat》和《Bytecode for Dalvik VM》。
分析思路整理如下
(1) 《Dalvik VM Instruction Format》 里操作符 op 都是位于首个 16bit 数据的低 8 bit ,起始的是 op =0x62。
(2) 在 《Bytecode for Dalvik VM》 里找到对应的 Syntax 和 format 。
syntax = sget_object
format = 0x21c 。
(3) 在《Dalvik VM Instruction Format》里查找 21c , 得知 op = 0x62 的指令占据 2 个 16 bit 数据 ,格式是 AA|op BBBB ,解释为 op vAA, type@BBBB 。因此这 8 组 16 bit 数据里 ,前 2 个是一组 。对比数据得 AA=0x00,
BBBB = 0x0000。
(4)返回《Bytecode for Dalvik VM》里查阅对 sget_object 的解释, AA 的值表示 Value Register ,即0 号寄存器; BBBB 表示 static field 的 index ,就是之前分析的field_ids 区里 Index = 0 指向的那个东西 ,当时的 fields_ids
的分析结果如下 :
对 field 常用的表述是
包含 field 的类型 -> field 名称 :field 类型 。
此次指向的就是 Ljava/lang/System; -> out:Ljava/io/printStream;
(5) 综上 ,前 2 个 16 bit 数据 0x 0062 0000 , 解释为
sget_object v0, Ljava/lang/System; -> out:Ljava/io/printStream;
其余的 6 个 16 bit 数据分析思路跟这个一样 ,依次整理如下 :
0x011a 0x0001: const-string v1, “Hello, Android!”
0x206e 0x0002 0x0010:
invoke-virtual {v0, v1}, Ljava/io/PrintStream; -> println(Ljava/lang/String;)V
0x000e: return-void
(6) 最后再整理下 main method , 用容易理解的方式表示出来就是 。
ACC_PUBLIC ACC_STATIC LHello;->main([Ljava/lang/String;)V
{
sget_object v0, Ljava/lang/System; -> out:Ljava/io/printStream;
const-string v1,Hello, Android!
invoke-virtual {v0, v1}, Ljava/io/PrintStream; -> println(Ljava/lang/String;)V
return-void
}
看起来很像 smali 格式语言 ,不妨使用 smali 反编译下 Hello.dex , 看看 smali 生成的代码跟方才推导出
来的有什么差异 。
.method public static main([Ljava/lang/String;)V
.registers 3
.prologue
.line 5
sget-object v0, Ljava/lang/System;->out:Ljava/io/PrintStream;
const-string v1, "Hello, Android!
"
index 0
class_idx 0x04
type_idx 0x01
name_idx 0x0c
class string Ljava/lang/System;
type string Ljava/io/PrintStream;
name string out
invoke-virtual {v0, v1}, Ljava/io/PrintStream;->println(Ljava/lang/String;)V
.line 6
return-void
从内容上看 ,二者形式上有些差异 ,但表述的是同一个 method 。这说明刚才的分析走的路子是没有跑偏
的 。另外一个 method 是 <init> , 若是分析的话 ,思路和流程跟 main 一样 。走到这里,心里很踏实了
七、总结
到这里我们就解析完了dex文件的所有东东,讲解的内容有点多,在这里就来总结一下:
学习到的技术
1、我们学习到了如何不是用任何的IDE工具,就可以构造一个dex文件出来,主要借助于java和dx命令。
同时,我们也学会了一个可以执行dex文件的命令:dalvikvm;不过这个命令需要root权限。
2、我们了解到了Android中的DVM指令,如何翻译指令代码
3、学习了一个数据类型:uleb128,如何将uleb128类型和int类型进行转化
我们解析dex的目的是啥?
我们开始的时候,并没有介绍说解析dex干啥?那么现在可以说,解析完dex之后我们有很多事都可以做了。
1、我们可以检测一个apk中是否包含了指定系统的api(当然这些api没有被混淆),同样也可以检测这个apk是否包含了广告,以前我们可以通过解析AndroidManifest.xml文件中的service,activity,receiver,meta等信息来判断,因为现在的广告sdk都需要添加这些东西,如果我们可以解析dex的话,那么我们可以得到他的所有字符串内容,就是string_ids池,这样就可以判断调用了哪些api。那么就可以判断这个apk的一些行为了,当然这里还有一个问题,假如dex加密了我们就蛋疼了。好吧,那就牵涉出第二件事了。
2、我们在之前说过如何对apk进行加固,其实就是加密apk/dex文件内容,那么这时候我们必须要了解dex的文件结构信息,因为我们先加密dex,然后在动态加载dex进行解密即可
3、我们可以更好的逆向工作,其实说到这里,我们看看apktool源码也知道,他内部的反编译原理就是这些,只是他会将指令翻译成smail代码,这个网上是有相对应的jar包api的,所以我们知道了dex的数据结构,那么原理肯定就知道了,同样还有一个dex2jar工具原理也是类似的
作者关于dex文件的学习和总结,写的不错,支持。
感谢链接: