awk具备完整的编程特性,同时也是一种语言解析引擎。
log.txt
2 this is a test
3 Are you like awk
This's a test
10 There are orange,apple,mongo
1.打印指定的列
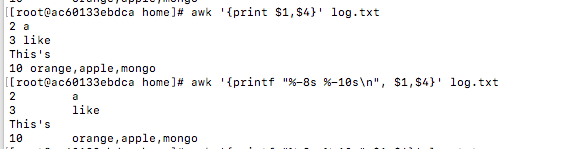
awk '{print $1,$4}' log.txt
# 格式化打印
awk '{printf "%-8s %-10s
",$1,$4}' log.txt
2.指定分隔符
-F 相当于内建变量FS,-F 指定分隔符,不加默认空格或tab分隔符,print打印自定义的内容需要用" "扩起来
#指定分隔符
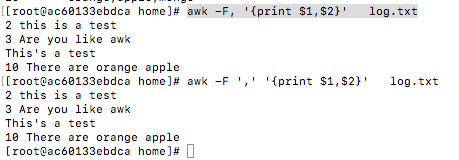
awk -F, '{print $1,$2}' log.txt #不加单引号
awk -F ',' '{print $1,$2}' log.txt #加单引号
#指定多个分隔符
awk -F '[<>]' '{print $1,$4}' text.txt
#指定汉字作为分隔符
awk -F字 filename;
awk -F '(路|非)' filename
使用内建变量FS指定分隔符
awk 'BEGIN{FS=","}{print $1,$2}' log.txt
部分结果
3.指定变量-v
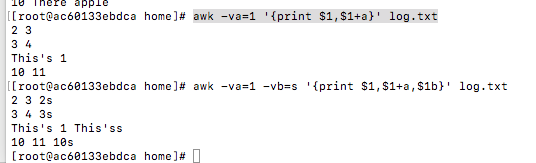
awk -va=1 '{print $1,$1+a}' log.txt
awk -va=1 -vb=s '{print $1,$1+a,$1b}' log.txt
4.运算符
# 过滤第一列大于2的行
awk '$1>2' log.txt
# 过滤第1列等于2的行
awk '$1==2 {print $1,$3}' log.txt
# 过滤第1列大于2且第第2列等于Are的行
awk '$1>2 && $2="Are" {print $1,$2}'.log.txt

5.内置变量
| $n | 当前记录的第n个字段,字段间由FS分隔 |
| $0 | 完整的输入记录 |
| ARGC | 命令行参数的数目 |
| FILENAME | 当前文件名 |
| FNR | 各文件分别计数的行号 |
| FS | 字段分隔符(默认是任何空格),field列 |
| NF | 一条记录的字段的数目,field列数 |
| NR | 已经读出的记录数,就是行号,从1开始 |
| OFS | 输出记录分隔符(输出换行符),输出时用指定的符号代替换行符 |
| ORS | 输出记录分隔符(默认值是一个换行符) |
| RS | 记录分隔符(默认是一个换行符),row行 |
6.正则表达式
~表示开始 / /表示模式
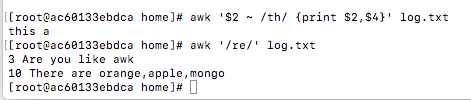
awk '$2 ~ /th/ {print $2,$4}' log.txt #打印第2列匹配th的行的第2和第4个字段
awk '/re/' log.txt
awk '/root/ {print $1} /system/ {print $1}' text.txt #匹配多个结果,第一列包含root或system
7.忽略大小写
awk 'BEGIN{IGNORECASE=1} /this/' log.txt

8.取反
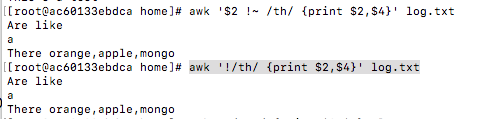
awk '$2 !~ /th/ {print $2,$4}' log.txt
awk '!/th/ {print $2,$4}' log.txt
9.awk数学运算
#将某个字段改成指定的字符串
awk '{$7=$3+$4;print{$3,$4,$7}}' text.txt
#计算某个段的总和
awk '{(tot+=$3)};END {print tot}' text.txt
10.条件操作符
== != > < >= <= && ||
awk可以用逻辑运算符号判断,但是awk会将所有内容视为字符,而非数字,因此此处的< > <= <=不是指数学关系
awk '$1=="100"' text.txt #精确匹配
awk '$1>="100"' text.txt
#!= 即为不匹配
awk '$2!="100" {print $2}' text.txt
awk '$2=="100" || $2=="44" ' text.txt
awk '$2<="44" && $2 >='100'' ' text.txt
#在awk中可以使用if判断,for循环
awk '{if ($1=="root") print $0}' text.txt
11.awk脚本
BEGIN{执行前的语句}
{处理每一行时要执行的语句}
END{处理完所有的行后要执行的语句}
对以下内容的第一列求和
1 2 3
4 5 6
7 8 9
awk '{sum+=$1}END{print sum}' lianxi.txt #12
成绩
Marry 2143 78 84 77
Jack 2321 66 78 45
Tom 2122 48 77 71
Mike 2537 87 97 95
Bob 2415 40 57 62
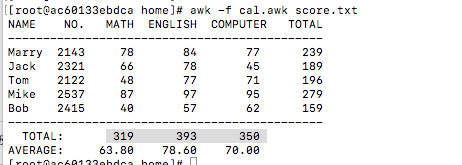
awk脚本
#!/bin/awk -f
#运行前,初始化成绩参数
BEGIN {
math = 0
english = 0
computer = 0
printf "NAME NO. MATH ENGLISH COMPUTER TOTAL
"
printf "---------------------------------------------
"
}
#运行中,打印学生信息及总分,并将每门分数汇总
{
math+=$3
english+=$4
computer+=$5
printf "%-6s %-6s %4d %8d %8d %8d
", $1, $2, $3,$4,$5, $3+$4+$5
}
#运行后,打印每个学科的平均分
END {
printf "---------------------------------------------
"
printf " TOTAL:%10d %8d %8d
", math, english, computer
printf "AVERAGE:%10.2f %8.2f %8.2f
", math/NR, english/NR, computer/NR
}
awk 'BEGIN{print "Hello world"}{print $1,$2}END{print Bye world}' score.txt

12其他:
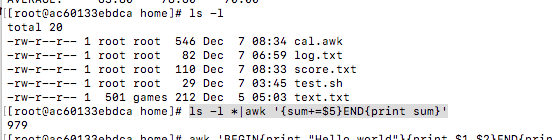
查看当前目录全部文件的大小
ls -l *|awk '{sum+=$5}END{print sum}'
打印长度大于18的行
awk 'length>18' log.txt

拿到第2列的最小值
awk 'NR==1{min=$2;next}{min=min<$2}END{print min}' sum.txt