一、基本介绍-为什么需要多表查询

说明: 我们在实际开发中,必然会遇到,数据来自不同的表,这时,我们就需要使用多表联合查询。
快速入门案例

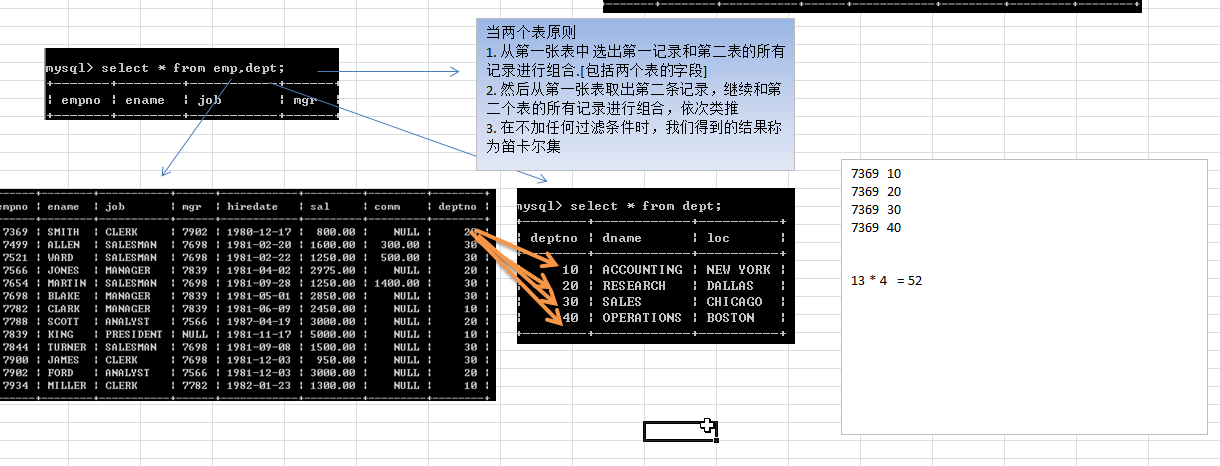
?显示雇员名,雇员工资及所在部门的名字
分析1: 因为上面的数据来自 emp 表和 dept 因此联合查询
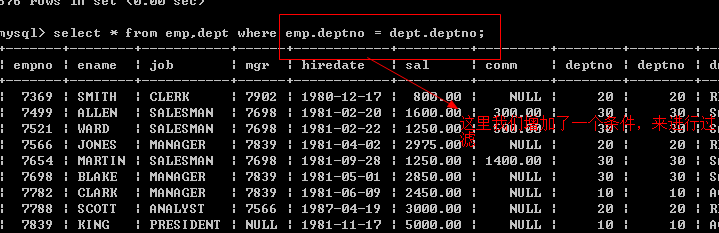
select * from emp,dept
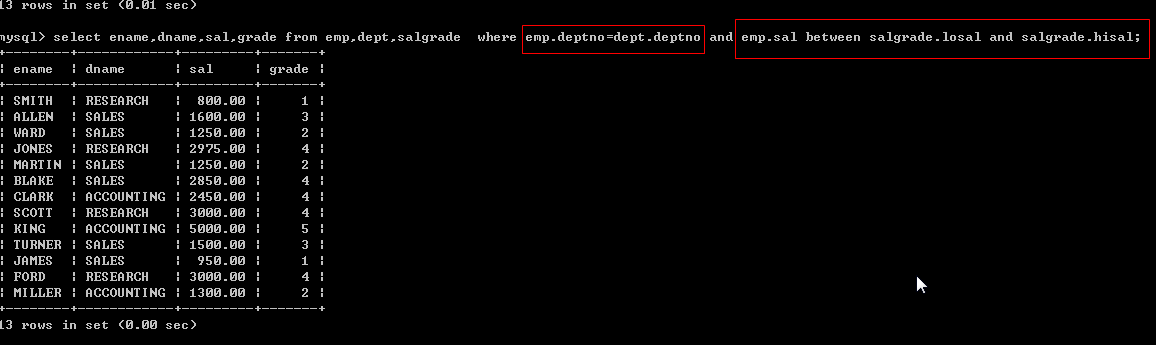
加强: ?显示雇员名,雇员工资及所在部门的名字, 显示工资的级别
思考(1) 一共要用到 3 张表 [emp, dept, salgrade]
select * from emp, dept, salgrade;
再次过滤
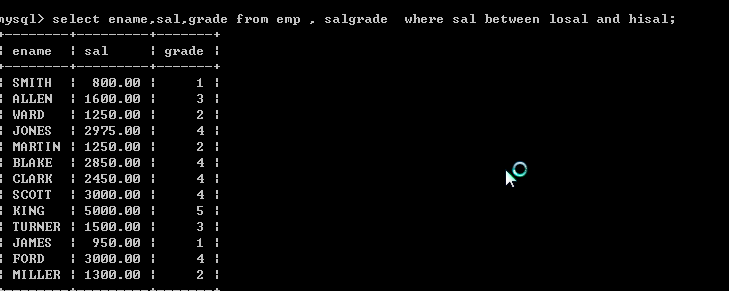
增加一个过滤条件即可
可以根据需要选择我们要的字段

说明:如果我们显示额字段名,没有冲突【没有相同的,则可以不要表名】.
?如何显示部门号为10的部门名、员工名和工资
select dept.dname,emp.sal from emp , detp where emp.deptno = dept.deptno and dept.deptno=10

显示各个员工的姓名,工资,及其工资的级别
二、自连接
基本介绍

案例说明

比如显示’FORD’的上级名字
思路: 我们先查询到'ford' 的上级的编号
思路: 当得到 'ford' 上级编号后,就可以通过这个编号,获取到这个人的所有信息

要求大家使用多表查询.

显示所有员工的上级名字

三、子查询
基本介绍:

Where型子查询:内层的查询结果最为外层sql的比较条件。如果 where 列=(内层sql),则内层sql返回的必是单行单列,单个值,如果 where 列 in (内层sql), 则内层sql只返回单列,可以多行.
Form型子查询:把select后的结果集取个别名当做表来用。
Exists型子查询:先获取外层sql所有数据,并把数据带入到内查询条件中,看能否查到数据。
示例:查询栏目表,看cat_id对应的商品是否存在,如果存在,则这行记录就要,否则不要;


关键字主要包括:in not in = != exists not exists等
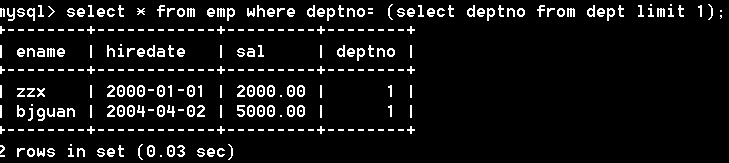

如果子查询记录数唯一,还可以用 = 代替 in;
四、子查询的分类

案例说明
请思考:如何显示与SMITH同一部门的所有员工?
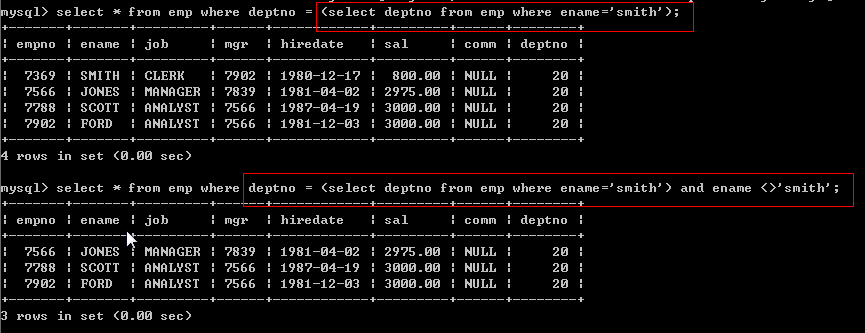
练习:如何查询和部门10的工作相同的雇员的名字、岗位、工资、部门号, 但是不含10自己的.

综合查询

说明: 在 ecs_goods 表中查看 ,要求显示 每个类别中,价格最高的商品的名称和价格。
思路:
先根据 类别和 价格进行排序处理
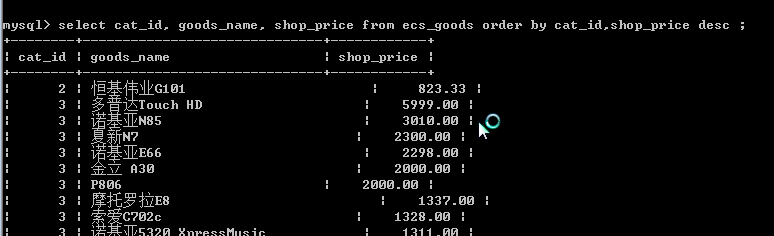
把上面的结果,看做是一个临时表,然后对其进行分组

五、all/any关键字的使用
案例说明:
请思考:如何显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
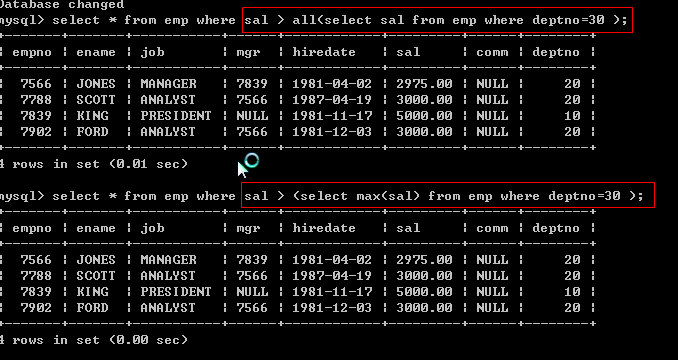
请思考:如何显示工资比部门30的任意一个员工的工资高的员工的姓名、工资和部门号

六、多列子查询
基本介绍:

说明: 多列子查询就是指,我们的子查询的结果是多列,而不是单列 。
请查询和宋江数学,英语,语文 完全相同的学生

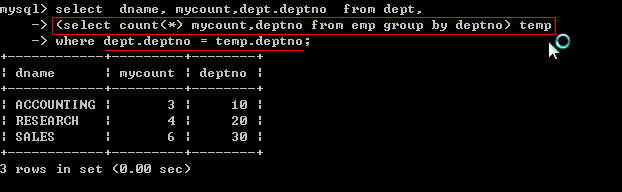
七、在from 子句中使用子查询
基本介绍: 即你的子查询出现在from 子句中.这里要用到数据查询的小技巧,把一个子查询当作一个临时表使用
案例说明:
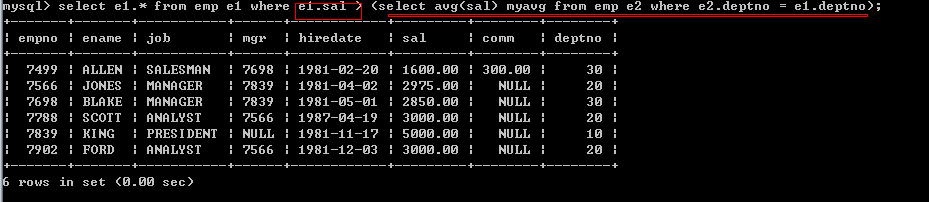
请思考:如何显示高于自己部门平均工资的员工的信息
思路: 先获取到各个部门的平均工资,然后将其看成临时表,具体 sql语句如下
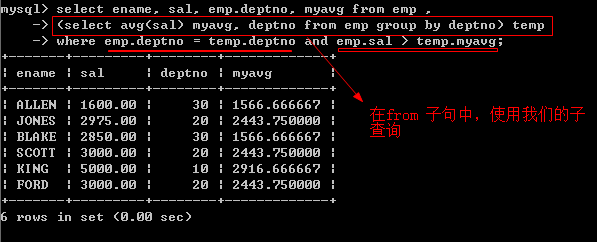
第二种解决方法
请思考:查找每个部门工资最高的人的详细资料 ?
思路: 先查询到每个部门工资最高的人.

练习:

方法: 多表查询,子查询

第二种方式,使用了子查询
八、自我复制(蠕虫复制)
基本介绍:
有时,为了对某个sql语句进行效率测试,我们需要海量数据时,可以使用此法为表创建海量数据
案例说明
我们希望把emp 表的数据,快速的变成80000
步骤如下[自我复制]



九、删除某个表中的重复记录
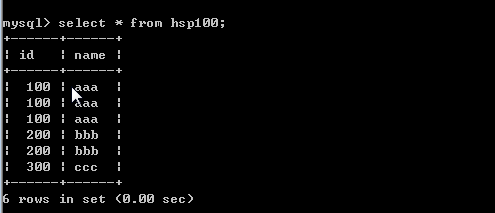
要求,将上面表中重复的记录删除.
思路
先创建一张空表(temp_hsp100),空表的结构和 hsp100一样.

把hsp100进行 distinct ,把数据导入到 (temp_hsp100)

删除 hsp100

将temp_hsp100 改成 hsp100

十、union合并查询
基本介绍: 有时在实际应用中,为了合并多个select语句的结果,可以使用集合操作符号 union , union all
注意:只要各语句取出的字段数要相同,字段名不是必须相同,会以第一个sql的字段名为准
案例说明
union 使用: 该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中重复行。过滤会比较费时,推荐使用union all
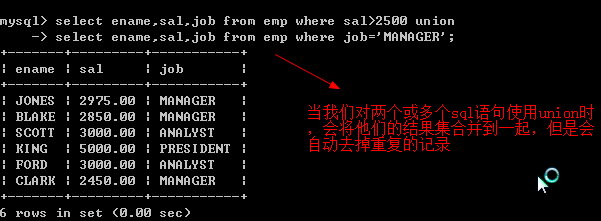
union all 使用: 该操作符用于取得两个结果集的并集。当使用该操作符时,不会自动去掉结果集中重复行。

思考如下,内层语句的desc怎么没发挥作用呢?
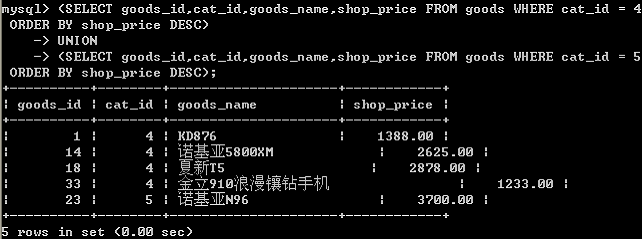
思考如下语句:
(SELECT goods_id,cat_id,goods_name,shop_price FROM goods WHERE cat_id = 4 ORDER BY shop_price DESC)
UNION
(SELECT goods_id,cat_id,goods_name,shop_price FROM goods WHERE cat_id = 5 ORDER BY shop_price DESC)
order by shop_price asc;
外层语句还要对最终结果,再次排序.
因此,内层的语句的排序,就没有意义.
因此:内层的order by 语句单独使用,不会影响结果集,仅排序,
在执行期间,就被Mysql的代码分析器给优化掉了.
内层的order by 必须能够影响结果集时,才有意义.
比如 配合limit 使用. 如下例.
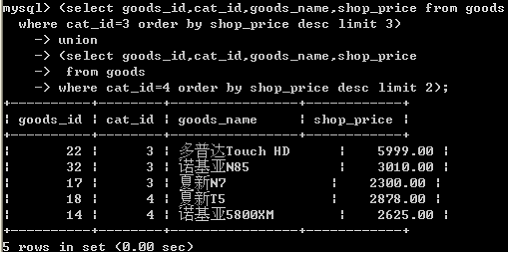
查出: 第3个栏目下,价格前3高的商品,和第4个栏目下,价格前2高的商品.
用union来完成,这一次:内层的order by 发挥了作用,因为有limit ,order 会实际影响结果集,有意义.