sql:
数据库一二三范式:(normal form/normalization)
https://www.guru99.com/database-normalization.html
第一范式:每个属性不可再分
第二范式:一个表中每个属性和主键有依赖
第三范式:一个表每个属性和主键有直接依赖 不能是传递依赖
没理解,之后再看
平衡二叉树、B树、B+树
数据库索引储存在磁盘上,可能到达几个G,内存无法一下子读取,在考虑磁盘IO的情况下,平衡二叉树的读取由树的纵向高度决定。
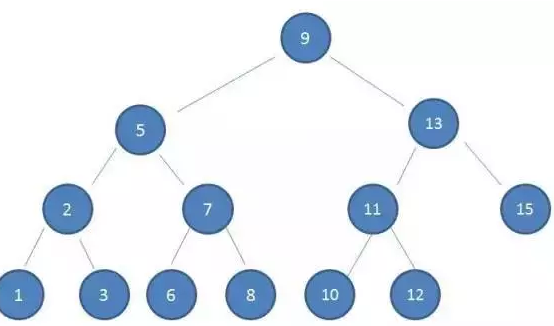
(这里值是基于自己的算法规则而定的,比如hash值) 平衡二叉树查询性能和树的层级(h高度)成反比,h值越小查询越快
REF:https://blog.csdn.net/lkforce/article/details/79041657

1,除了叶子节点外,树中每个节点,最少有ceil(m/2)个子节点,最多有m个子节点。(上图有三根枝 三阶B树)
2,只要根节点不是叶子节点(那种情况只能是整个树就一个根节点),那么根节点最少有2个子节点。
3,所有叶子节点出现在同一层,即根节点到所有子节点的距离相同。(左右B树高度不相差一)
4,除了根节点之外,树中每个节点最少有ceil(m/2)-1个关键字,最多有m-1个关键字。 2-1<=关键字<=3-1 关键字可以是两个或一个 例:(3,5)(1)
5,假设一个节点中有x个关键字(K1,K2,……Kx),那么需要满足以下条件:
有x+1个子节点(P0,P1,……Px)。(俩关键字底下三根枝)
节点中的x个关键字升序排列,即K(n-1)<Kn
子节点Pn中的元素都小于Kn,都大于K(n-1),也就是说,节点和子节点中的关键字排序是P0,K1,P1,K2,P2,……Kx,Px。(底下枝按值域来)
卫星数据(即索引指向所在的行信息)
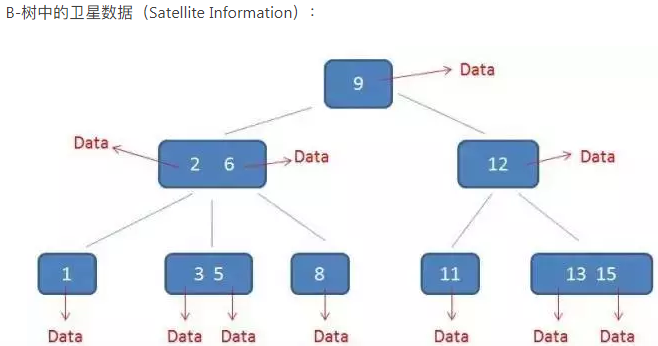
B树添加删除元素
https://www.jianshu.com/p/8b653423c586
B+树
https://www.jianshu.com/p/1f2560f0e87f
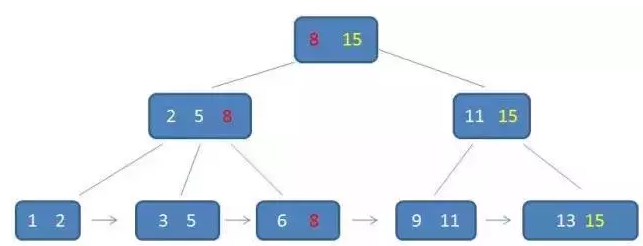
每个节点有几个子枝就有几个元素
B+树中的卫星数据

需要补充的是,在数据库的聚集索引(Clustered Index)中,叶子节点直接包含卫星数据。在非聚集索引(NonClustered Index)中,叶子节点带有指向卫星数据的指针
在B+树中,遍历有巨大优势
B+树的优势:
1.单一节点存储更多的元素,使得查询的IO次数更少。
2.所有查询都要查找到叶子节点,查询性能稳定。
3.所有叶子节点形成有序链表,便于范围查询。
Hbase:
postgre(慢查询):