1、glmfit()
功能:构建一个广义线性回归模型。
使用格式:b=glmfit(X,y,distr),根据属性数据X以及每个记录对应的类别数据y构建一个线性回归模型,distr可取值为:binomial、gamma、inverse gaussian、normal(默认值)和poisson,分别代表不同类型的回归模型。
2、patternnet()
功能:构建一个模式识别神经网络。
模式识别神经网络是一个前馈神经网络,通过对已知含有标签的数据进行训练得到神经网络模型,从而可以对新的不含标签的数据进行分类。用于输入的标签数据需要进行特殊编码,即一个类别使用一个向量进行表示,比如一共有3个类别,那么类别1可以编码为[1,0,0],类别3可以编码为[0,0,1]。
使用格式:net=patternnet(hiddenSizes,trainFcn,performFcn),构建一个隐含层神经元个数为hiddenSizes,模型函数为trainFcn,性能函数为performFcn的神经网络net。
主要的模型函数有:
Trainscg:使用标度共梯度算法更新权值和偏移值
Trainlm:使用LM算法更新权值和偏移值
Trainbr:使用LM算法更新权值和偏移值(贝叶斯正则化)
Trainrp:根据弹反向传播算法更新权值和偏移值
3、fitctree()
功能:构建一个二叉分类树,每个分支节点根据输人数据进行确定。
使用格式:tree=fitctree(x,y),根据数据的属性数据x以及每个记录对应的类别数据y构建一个二叉分类树tree。
4、fitensemble()
功能:创建一个模型,该函数可以根据不同的参数构建不同的模型,可以用于分类或者回归。
使用格式:Ensemble=fitensemble(x,y,Method,NLearn,Learners),根据输入属性数据x以及每个记录对应的y值(如y是离散型变量,则模型为分类模型;如y是连续型变量,则模型为回归模型)、Method(用于构建的模型名称)、NLearn(模型学习的循环次数)以及Learners值(弱学习算法名称,有三个值,分别是“Discriminant”“KNN”“Tree”)构建一个分类或者回归模型。该模型的性能依赖于弱学习算法的参数设置,如果这些参数设置不合理,将导致较差的性能。
常用的method:
①参数值:AdaBoostM1
适用范围:适用于二类别分类
②参数值:LogitBoost
适用范围:适用于二类别分类
③参数值:GentleBoost
适用范围:适用于二类别分类
④参数值:AdaBoostM2
适用范围:适用于三类别分类及以上
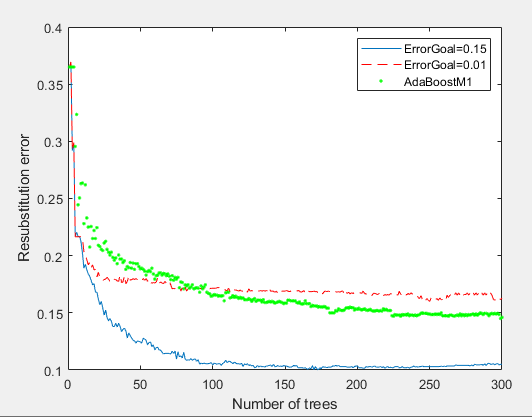
使用fitensemble函数构建三个模型,对比三个模型的误差。
rng(0,'twister') Xtrain=rand(2000,20); Ytrain=sum(Xtrain(:,1:5),2)>2.5; idx=randsample(2000,200); Ytrain(idx)=~Ytrain(idx); %构建一个AdaBoostM1模型 ada=fitensemble(Xtrain,Ytrain,'AdaBoostM1',300,'Tree','LearnRate',0.1); %构建一个RobustBoost模型,设置误差阈值为0.15 rb1=fitensemble(Xtrain,Ytrain,'RobustBoost',300,'Tree','RobustErrorGoal',0.15,'RobustMaxMargin',1); %构建一个RobustBoost模型,设置误差阈值为0.01 rb2=fitensemble(Xtrain,Ytrain,'RobustBoost',300,'Tree','RobustErrorGoal',0.01) figure plot(resubLoss(rb1,'Mode','Cumulative')) hold on plot(resubLoss(rb2,'Mode','Cumulative'),'r--'); plot(resubLoss(ada,'Mode','Cumulative'),'g.'); hold off xlabel('Number of trees'); ylabel('Resubstitution error'); legend('ErrorGoal=0.15','ErrorGoal=0.01','AdaBoostM1','Location','NE');
5、fitNaiveBayes()
功能:创建一个朴素贝叶斯分类器。
使用格式:NBModel=fitNaiveBayes(x,y),根据输入数据x以及每个x对应的类别号y(如果y为NaN或者空字符串‘’或者unidefined,都会被视为缺失值,朴素贝叶斯分类器会直接忽略这些值对应的x)构建一个朴素贝叶斯分类器。