说明:本文只是对相关数据库知识的笔记,一般不会出现长篇大论的理论,以简洁实用好查为目的编辑整理;
一、索引
关于索引:数据库索引类似与书本的目录,使用索引查找数据,无需对整表进行扫描,可以快速找到所需数据;
- 创建索引语法:
1 --创建索引 2 CREATE INDEX index_name ON ‘table_name’(‘column’) ; 3 4 --更新索引 5 ALTER TABLE ‘table_name’ ADD INDEX index_name(‘column’) ; 6 7 --查看索引 8 SHOW INDEX FROM table_name; 9 10 --删除索引 11 DROP index index_name on table_name ; 12 alter table table_name drop index index_name ;
- 使用索引说明
- 最普通的情况,是为出现在where子句的字段建一个索引。索引并不是每个字段都可以加,给主键加索引没有意义。
- 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
- 索引的重建
当我们发现索引索引覆盖范围不够或者存在大量索引锁片,影响性能的时候,我们就需要对索引进行重建。而关于索引碎片的形成,也是源于数据库长时间的运行,大量的增删该查造成了B-Tree结构的不准确,确切的说是不能正确的提供平衡查询的性能,或者大量的数据分页造成索引碎片,进而增大了IO,影响了性能。
--关于索引碎片的查看,可以通过以下DMV语句进行 --下面语句相当耗时,执行时注意(以下语句执行环境为SQL Server2008) SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED -–上面一句是更改SQL Server的事务隔离级别,只对当前连接生效 SELECT DB_NAME() AS DatbaseName , SCHEMA_NAME(o.Schema_ID) AS SchemaName , OBJECT_NAME(s.[object_id]) AS TableName , i.name AS IndexName , ROUND(s.avg_fragmentation_in_percent,2) AS [Fragmentation %] INTO #TempFragmentation FROM sys.dm_db_index_physical_stats(db_id(),null, null, null, null) s INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id INNER JOIN sys.objects o ON i.object_id = O.object_id WHERE 1=2 EXEC sp_MSForEachDB 'USE [?]; INSERT INTO #TempFragmentation SELECT TOP 20 DB_NAME() AS DatbaseName , SCHEMA_NAME(o.Schema_ID) AS SchemaName , OBJECT_NAME(s.[object_id]) AS TableName , i.name AS IndexName , ROUND(s.avg_fragmentation_in_percent,2) AS [Fragmentation %] FROM sys.dm_db_index_physical_stats(db_id(),null, null, null, null) s INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id INNER JOIN sys.objects o ON i.object_id = O.object_id WHERE s.database_id = DB_ID() AND i.name IS NOT NULL AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0 ORDER BY [Fragmentation %] DESC' SELECT top 20 * FROM #TempFragmentation ORDER BY [Fragmentation %] DESC DROP TABLE #TempFragmentation
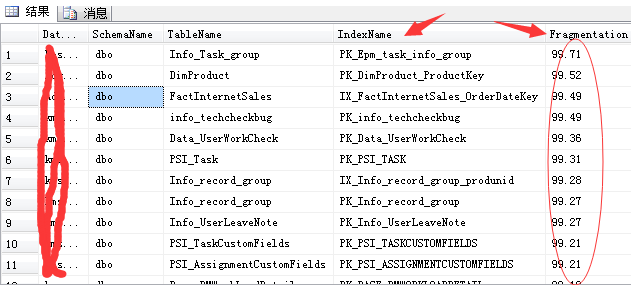
看到了,这部分索引的碎片到大了99%...这就需要我们重建进行维护了,否则将严重拖垮数据的性能。
如果需要重建聚集索引请注意:在我们重新创建聚集索引的时候,SQL Server会默认的重新生成全部非聚集索引,如果表数据量特别大,这个过程会很漫长,如果不指定ONLINE的话,这个过程会是锁定索引B-Teee的,这就意味着是阻塞的,业务就要停下来等待完成操作,切记不要将此事发生在生产机上。
二、视图
- 语法
1 --创建视图 2 --AS 后面就是一个普通的sql查询语句,将查询出来的字段创建成字段 3 CREATE VIEW user_card_info_view 4 ( app_id , approle , user_id , cust_id, card_id, card_member_id ) 5 AS 6 SELECT t1.appId , t1.approle , t1.user_id , t1.customer_id, t2.card_id, t2.id 7 FROM table1 t1, table2 t2 8 WHERE t1.user_id = t2.user_id and t1.status=1 and t2.isvalid=true and t1.isvalid=true
- 使用视图的优点
- 安全性:一般来时当我们创建一个数据库的时候有一些重要的信息是不希望用户看见的,那么我们就可以建立一个视图来设置一个权限,使得用户只能查看自己的基本数据,更重要的数据用户是无法得到的。
- 查询的性能有所改善。
- 对于复杂查询的需求,可以进行问题分解,然后将创建多个视图获取数据。将视图联合起来就能得到需要的结果了。比如进行多表查询时,我们希望使用一个统一的方式进行查询,那么我们建立一个视图,将每一个表的数据都放入到视图当中去,最后我们对视图进行操作,我们就可以得到想要的数据信息了。
- 关于视图的说明
- 视图的字段都是从各个表里取出来的,当表的字段被修改时视图会自动更新因此不存在数据差异;
- 创建视图时,分析查询所需要的信息区构建视图,视图查询效率较高;
- 视图的结构是一个表,一个虚表,不进行实际的存储,但是通过视图可以改变真实表的数据