http://blog.csdn.net/jokes000/article/details/7839686
后缀数组sa:将s的n个后缀从小到大排序后将 排序后的后缀的开头位置 顺次放入sa中,则sa[i]储存的是排第i大的后缀的开头位置。简单的记忆就是“排第几的是谁”。
名次数组rank:rank[i]保存的是suffix(i){后缀}在所有后缀中从小到大排列的名次。则 若 sa[i]=j,则 rank[j]=i。简单的记忆就是“你排第几”。
对于 后缀数组sa 与 名次数组rank ,有rank[ sa[i] ]=i (这是很重要的一点,通过sa与rank的关系可以求出后缀数组)
由此可看出,后缀数组sa 与名次数组rank的关系为互逆关系。
求出了rank和sa数组还不够,通常我们需要由rank与sa数组计算出一个辅助工具height数组——最长公共前缀(LCP)。
height 数组: 定义height[i]=suffix(sa[i-1]) 和 suffix(sa[i]) 的最长公共前缀,也就是排名相邻的两个后缀的最长公共前缀。
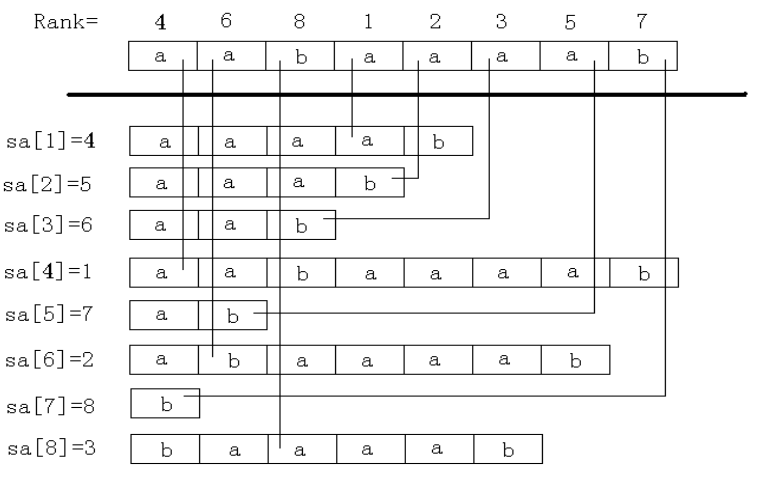
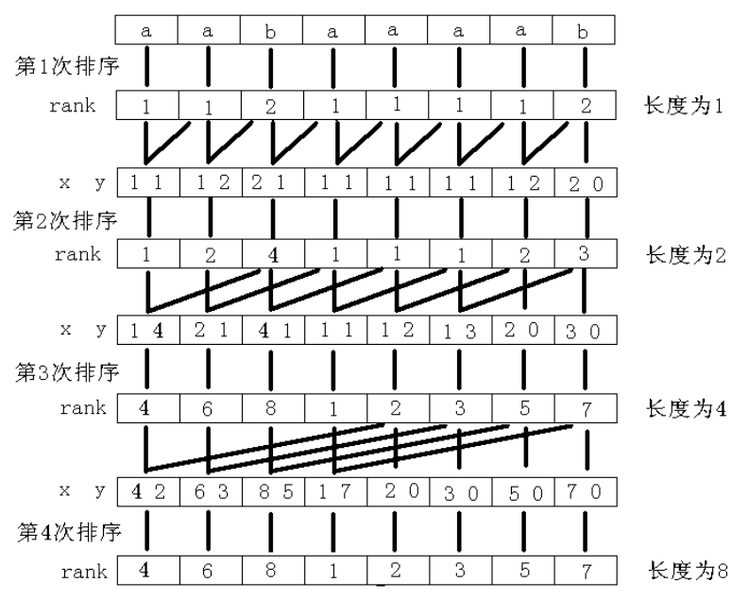
字符串aabaaaab的sa数组与rank数组 倍增算法的计算过程
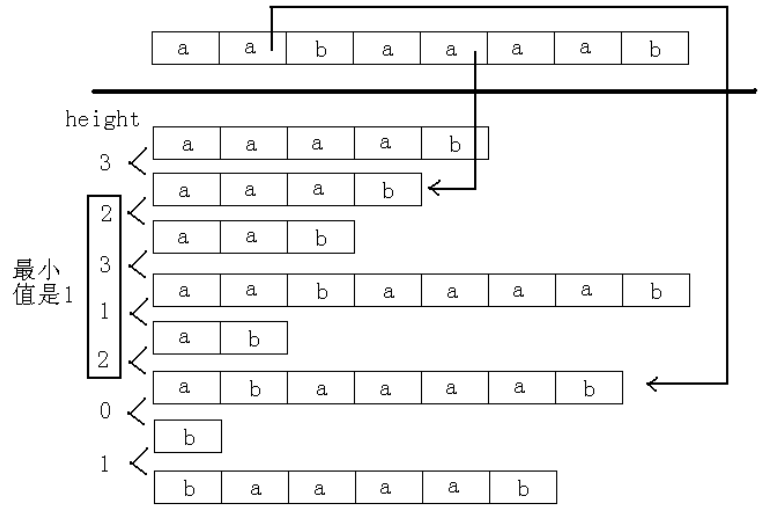
计算后缀"abaaaab"和后缀"aaab"的最长公共前缀
1 #include <iostream> 2 3 using namespace std; 4 5 #define maxn 110010*2 6 7 #define cls(x) memset(x, 0, sizeof(x)) 8 9 int wa[maxn],wb[maxn],wv[maxn],wss[maxn]; 10 11 int cmp(int *r,int a,int b,int l){return r[a]==r[b]&&r[a+l]==r[b+l];} 12 13 //倍增算法 14 void da(char *r,int *sa,int n,int m) 15 { 16 cls(wa); 17 cls(wb); 18 cls(wv); 19 cls(wss); 20 int i,j,p,*x=wa,*y=wb,*t; 21 //基数排序 22 for(i=0;i<m;i++) wss[i]=0; 23 for(i=0;i<n;i++) wss[x[i]=r[i]]++; 24 for(i=1;i<m;i++) wss[i]+=wss[i-1]; 25 for(i=n-1;i>=0;i--) sa[--wss[x[i]]]=i; 26 27 // 在第一次排序以后,rank数组中的最大值小于p,所以让m=p。整个倍增算法基本写好,代码大约25行。 28 for(j=1,p=1;p<n;j*=2,m=p) 29 { 30 //接下来进行若干次基数排序,在实现的时候,这里有一个小优化。基数排序要分两次,第一次是对第二关键字排序,第二次是对第一关键字排序。对第二关键字排序的结果实际上可以利用上一次求得的sa直接算出,没有必要再算一次 31 for(p=0,i=n-j;i<n;i++) y[p++]=i; 32 for(i=0;i<n;i++) if(sa[i]>=j) y[p++]=sa[i]-j; 33 34 //其中变量j是当前字符串的长度,数组y保存的是对第二关键字排序的结果。然后要对第一关键字进行排序, 35 for(i=0;i<n;i++) wv[i]=x[y[i]]; 36 for(i=0;i<m;i++) wss[i]=0; 37 for(i=0;i<n;i++) wss[wv[i]]++; 38 for(i=1;i<m;i++) wss[i]+=wss[i-1]; 39 for(i=n-1;i>=0;i--) sa[--wss[wv[i]]]=y[i]; 40 41 //这样便求出了新的sa值。在求出sa后,下一步是计算rank值。 42 for(t=x,x=y,y=t,p=1,x[sa[0]]=0,i=1;i<n;i++) 43 x[sa[i]]=cmp(y,sa[i-1],sa[i],j)?p-1:p++; 44 } 45 } 46 47 int rank[maxn],height[maxn]; 48 49 //得到height数组:排名相邻的两个后缀的最长公共前缀 50 void calheight(char *r,int *sa,int n) 51 { 52 cls(rank); 53 cls(height); 54 int i,j,k=0; 55 for(i=1;i<n;i++) rank[sa[i]]=i; 56 for(i=0;i<n;height[rank[i++]]=k) 57 for(k?k--:0,j=sa[rank[i]-1];r[i+k]==r[j+k];k++); 58 return; 59 } 60 61 char ca[maxn]; 62 int sa[maxn]; 63 64 int main() 65 { 66 while (cin >> ca) 67 { 68 int len = strlen(ca); 69 int lenstr1 = len; 70 ca[len] = '#'; 71 cin >> (ca + len + 1); 72 len = strlen(ca); 73 da(ca, sa, len, 130); 74 75 int i; 76 calheight(ca,sa,len); 77 78 int max = 0; 79 for (i = 1; i < len; ++i) 80 { 81 if (height[i] > max) 82 { 83 if ((sa[i] > lenstr1 && sa[i - 1] < lenstr1) || (sa[i - 1] > lenstr1 && sa[i] < lenstr1)) 84 { 85 max = height[i]; 86 } 87 } 88 } 89 cout << max << endl; 90 cls(ca); 91 } 92 return 0; 93 }