之前有个需求要将文件解析再处理,当时直接将整个文件内容读到内存中然后解析,也是没有考虑到大文件的问题,那么要如何解析大文件呢?
输入:文件的内容是多个json,按顺序排列
输出:解析后的json数据
代码:
1 let fs = require('fs'); 2 3 let log = (str) => { console.log(`${new Date().toLocaleString()} ${str}`); }; 4 5 let readStream = fs.createReadStream('./input.txt', {encoding: 'utf-8'}); 6 let chunkTotal = '', 7 res = [], 8 reg = /(}s*{)/g; 9 10 console.time('parse'); 11 12 readStream.on('readable', () => { 13 log('readable triggerd'); 14 let chunk; 15 16 while ((chunk = readStream.read()) !== null) { 17 log(`read triggerd, chunk length ${chunk.length}, current res length ${res.length}`); 18 chunkTotal += chunk; 19 20 let regRes, matchedIndex = 0, srcIndex = 0; 21 while ((regRes = reg.exec(chunkTotal))) { 22 matchedIndex = regRes.index; 23 let json = chunkTotal.slice(srcIndex, matchedIndex + 1); 24 try { 25 res.push(JSON.parse(json.trim())); 26 } catch (e) { 27 console.log(json); 28 } 29 30 srcIndex = matchedIndex + 1; 31 } 32 chunkTotal = chunkTotal.slice(matchedIndex + 1).trim(); 33 } 34 35 let json; 36 try { 37 json = JSON.parse(chunkTotal.trim()); 38 res.push(json); 39 chunkTotal = ''; 40 } catch (e) {} 41 }); 42 43 readStream.on('end', () => { 44 log(`总共编译得到数据:${res.length}个`); 45 console.timeEnd('parse'); 46 });
实际运行过程中发现程序越跑越慢:
当解析到100多w条json数据时,慢的不能忍
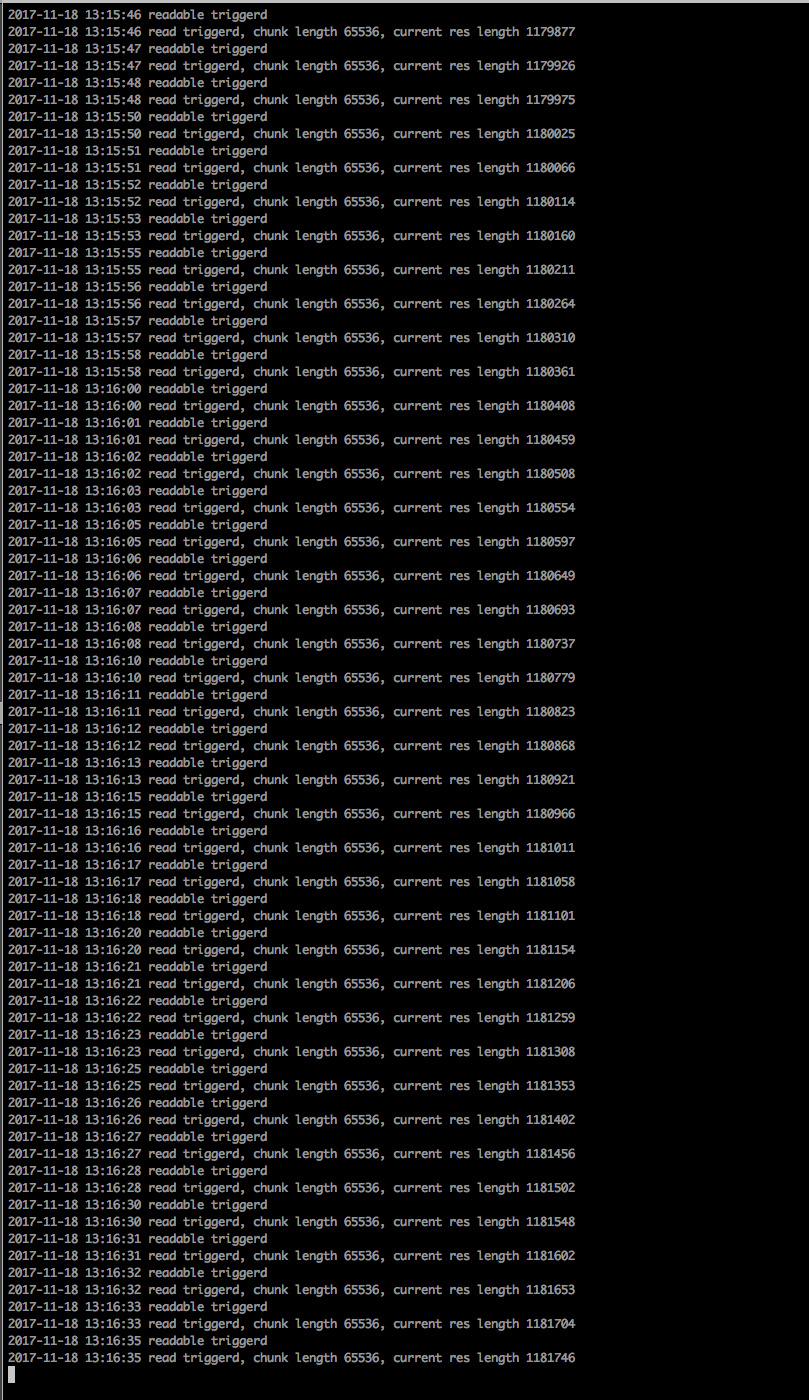
当把代码改成只统计能解析得到的json数量,不保存json数据后,代码就嗖嗖的跑完了。
难道是因为占用内存过高,影响垃圾回收速度?
能不能利用多进程来处理一个大文件?
原因是正则的问题导致效率下降,按行读取还是用readline比较好