1. TDSQL 开发规范
总体架构
分布式数据库(Tencent Distributed SQL,TDSQL)是腾讯打造的一款分布式数据库产品,具备强一致高可用、全球部署架构、分布式水平扩展、高性能、企业级安全等特性,同时提供智能 DBA、自动化运营、监控告警等配套设施,为客户提供完整的分布式数据库解决方案。目前 TDSQL 已经为超过500+的政企和金融机构提供数据库的公有云及私有云服务,客户覆盖银行、保险、证券、互联网金融、计费、第三方支付、物联网、互联网+、政务等领域。TDSQL 亦凭借其高质量的产品及服务,获得了多项国际和国家认证,得到了客户及行业的一致认可。
总体架构如下:
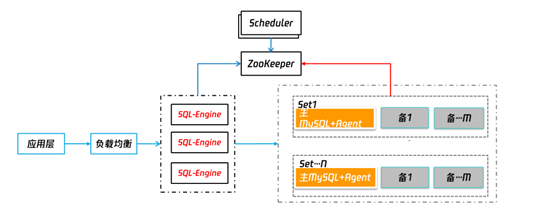
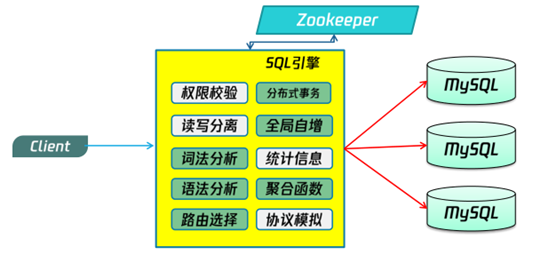
计算节点[sql引擎]
l SQ引擎也会被叫做Proxy 或网关
l 在TDSQL中位于接入层的位置,属于CPU密集型服务
l SQL引擎没有主备之分,本身无状态,多节点部署
数据节点
l 数据节点上部署MYSQL数据库服务
l Agent属于旁路模块,主要承担MYSQL实例的状态监控
l MYSQL实例通过AGENT和TDSQL集群建立联系
l SET:TDSQL最小数据单无, 包含一主N备 ,N+1个数据节点

设计规范
l 充分考虑业务逻辑和数据分离
l 尽量避免使用自定义函数,存储过程,触发器和视图
l 数据库管理和使人员权限分离
l 充分考虑数据增长模型,决策是否采用SHARD模式
l 充公考虑业务可用性数据,可靠性需求,设计合适的备份和恢复策略
l 使用InnoDB存储引擎(默认)
l 使用UTF8或UTF8MB4字符集
l 不在数据库中存储图片,二进制文件等大数据
l 提前规划好单表规模,行数和大小
l 对象命名要使用富有意义英文词汇,不要使用SQL关键字和特殊字符
l 字段属性尽量加上NOT NULL 约束以及默认值
l 数据库用户权限授权按照最小分配原则
l 除核心维护人员外,其他用户不能拥有SUPER权限帐号
l 避免使用简单密码
l 开发,测试和 生产环境中用户权限 设置要保持一至
l 严格禁止在数据库存储任何形式的密码明文。
开发规范
l 合理使用USE INDEX 和 IGNORE INDEX 进行索引的选择
l 查询条件尽量使用索引
l 注意字段类型,避免类型转换
l 尽量不要让数据库做算术运算,交给应用层来做
l 尽量不要直接select * , 直接列出需要查询的字段
l Where 子句使用原则:尽量使用索引,尽量简单,尽量匹配更少的行
l LIKE 子句的条件中,%不要是第一个字符,尽量靠后
l 表尽量避免用去类似count(*) 的全表扫描查询。
2. TBASE 开发设计规范
设计规范
l 充分考虑业务逻辑和数据分离
l 尽量不使用外键
l 尽量避免使用自定义函数,存储过程和触发器
l 充分考虑数据增长模型,决定表的存储方式
l 充分考虑业务可用性和可靠性要求,设计合适的备份和恢复策略
l 避免在数据库中存储图片二进制等大数据
l 对象命名要使用富有意义词汇,不使用SQL关键字和特殊字符
l 数据库用户权限授权按照最小分配原则
l 除核心维护人员外,其他用户不能拥有SUPER权限帐号
l 避免使用简单密码
l 开发,测试和 生产环境中用户权限 设置要保持一至
l 严格禁止在数据库存储任何形式的密码明文。
命名规范
l 小写字母,下划线组合。不使用双引号,除非必须包含大写字母或都特殊字符
l 长度不超过63个字符
l 不建议用pg_或pgxc_ 开头,禁止使用关键字
l 见名知意
表设计规范
l 指定shard key 和 group
l 最多支持1600个例
l 不建议用public schema ,建议为每个应用分配单独的schema
l 尽量添加comment
l 多表中相同的列,必须保证列名,数据类型一致
列设计规范
l 能用数值类型的,不使用字符类型
l 尽量用varchar2(n) 代替char(n)
l 如有国际化业务的话,使用timestamp with time zone (timestamptz)
l 使用numeric(precision,scale) 来存储货币金额和其它要求精确计算的数值
l 尽量添加comment
INDEX设计规范
l Tbase 提供的index类型:B-treee ,hash,gist,建议create 或 drop index 时加 concurrently 参数
l 建议对where 中带多个字段and 条件的高频query,参考数据分布情况,建多个字段的联合index
l 建议对固定条件的(一般有特定业务含义)且选择比较好(数据占比低的)query,建带where的 partial indexes
l 建议对经常使用表达式作为查询条件的query,可以使用达式,或函数索引加速query
l 建议不要建过多index ,一般不超过5个,核心table 可以适当增加index 个数
l 建议使用count(1) 或 count(*) 来统计行数
dml/ddl规范
l 建议非必须时避免select * ,只取所需字段,以减少包括不限于网络带宽消耗。
l 避免在业务高峰期做DDL操作
l 大批量的数据入库,使用COPY代替insert
l 避免大事务