这已经是一个被说得很烂的一个话题了,今天我想在这一篇文章补充一些细节上的东西,供备忘!
在看这篇文章之前,请先仔细看下链接这篇博文,关于字节序说得很详细!http://blog.chinaunix.net/uid-25367385-id-188322.html
在今天,碰到了这样一条语句:
#define get16bits(d) (*((const uint16_t *) (d)))
很明显宏参数d必须是一个指针,它可以是位数大于等于16位的类型指针,short int、long int,甚至是float或double,只要有需求就可以。
1 #include "stdio.h" 2 3 typedef unsigned short uint16_t; 4 #define get16bits(d) (*((const uint16_t *) (d))) 5 6 int _tmain(int argc, _TCHAR* argv[]) 7 { 8 //如果为小端字节序,那么读出来的是0x0001;如果为大端字节序,读出来的是0xFFFFF 9 int d = 0xFFFF0001; //int占4个字节 10 int *p = &d; 11 uint16_t a = get16bits(p); 12 printf("%d", a); 13 return 0; 14 }
为什么上面的代码在不同的机器上面可能会得到不同的结果呢?
下面将解释为什么CPU为小端字节序时,读出来的是0x0001。
这一篇文章,唯一想说的是p指向的是d所在内存单元的最低地址而已!
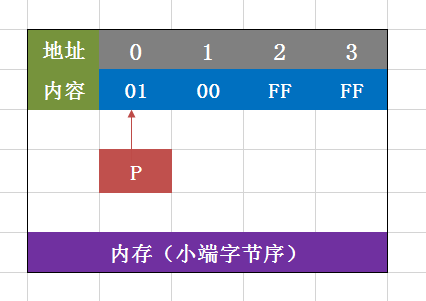
小端字节序的机器在存储0xFFFF0001这4个字节的数据时,它是按照上面的形式存储的。
在代码中(*((const uint16_t *) (p))),p被转化成指向16位的整形指针,此时对这16位的整形指针解引用,它读出来的也就是16位数据,而不是原来的32位了,这也就是指针类型转换的作用了。我们假设p指针指向的是内存单元的高地址,那么小端字节序的机器读出来会是0xFF,所以这一假设是错误的,p指针指向的是内存单元的低地址!
总结一下:在讲解字节序的同时,也要注意强调指针是指向内存单元低地址,否则有时会引起一些误解。