线性数据结构就是:顺序表和链表。
其他的就是非线性数据结构,比如树,图等。线性数据结构的特点是,一对一,一个数据只有一个后继和一个前驱;而非线性数据结构则是一对多。
1、顺序表
顺序表是个逻辑概念,顺序表的相邻元素在物理位置上也是相邻的。通常我们采用数组实现顺序表,我们可能会把这两者混为一谈。数组是基于顺序表逻辑实现的,但在细微之处有些许差别,比如数组下标从0开始,顺序表下标从1开始。
顺序表的特点是随机存取方便,不可扩充。

2、链表
当我们需要存放大量动态的数据时,这时就需要链表登场了。链表不需要数据存在连续的位置,它的存储结构是每个数据都有下一个结点的地址,所有的数据串成一条链,从第一个数据开始问,我们可以找到任何一个数据。相对于顺序表直接给出了每个数据的位置编号,链表的查找比较费事。

- 链表可以有一个空的头节点dummy,不存放数据,只用来做标识。方便数据的增删,并且对于空表方便处理。
- 除了上面的单向链表,链表还有双向链表,循环链表,十字链表等变式。
单链表反转
链表反转一般有三种方法,原地反转,头插法反转,递归反转。其中递归反转最简单简洁,但是空间复杂度更高。下面分别介绍。
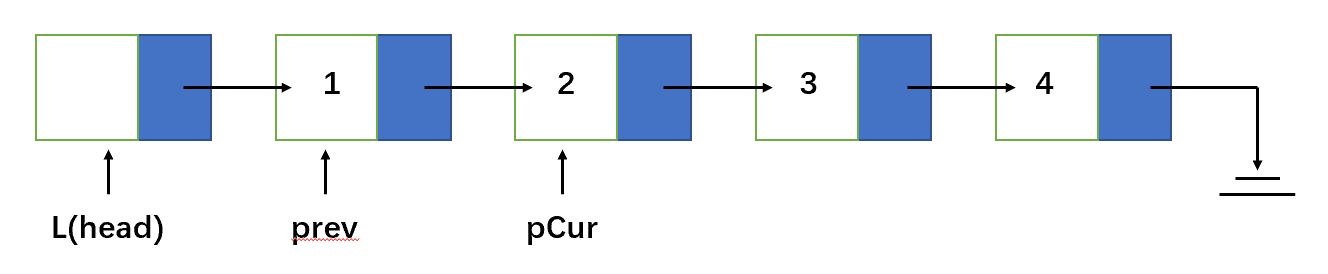
1.原地反转
首先让pre的next指向cur的next;再让cur的next指向头节点的下一个结点;这时已经反转了结点,此时链表第一个结点变成了当前反转的结点;再让头节点的next指向cur;最后移动cur到下一个要反转的结点。重复上述步骤,直到cur为null。此时头节点也指向最后一个节点了。
带头节点的链表:
static LinkNode reverse1(LinkNode l){
if(l.next == null || l.next.next == null){
return l;
}
LinkNode pre = l.next; // pre 不动, 移动头节点
LinkNode cur = pre.next;
while(cur != null){
pre.next = cur.next;
cur.next = l.next;
l.next = cur;
cur = pre.next;
}
return l;
}
不带头结点的链表:
一样的做法一个指向pre,一个指向cur。而且比有头节点的更加简单。
public LinkNode reverse2(LinkNode l){
LinkNode pre = l;
LinkNode cur = pre.next;
while(cur != null){
LinkNode next = cur.next;
cur.next = pre;
pre = cur;
cur = next;
}
l.next = null; // 记得将最开始的头节点指向null,否则形成环路
return pre;
}
2.头插法
新建一个链表,遍历原链表,用头插法插入到新链表中。
值得注意的是,在遍历开始前,还要断开第一个结点和第二个结点之间的链。初始化工作做完后,从第二个结点开始遍历链表,依次插入新链表中,即实现反转。
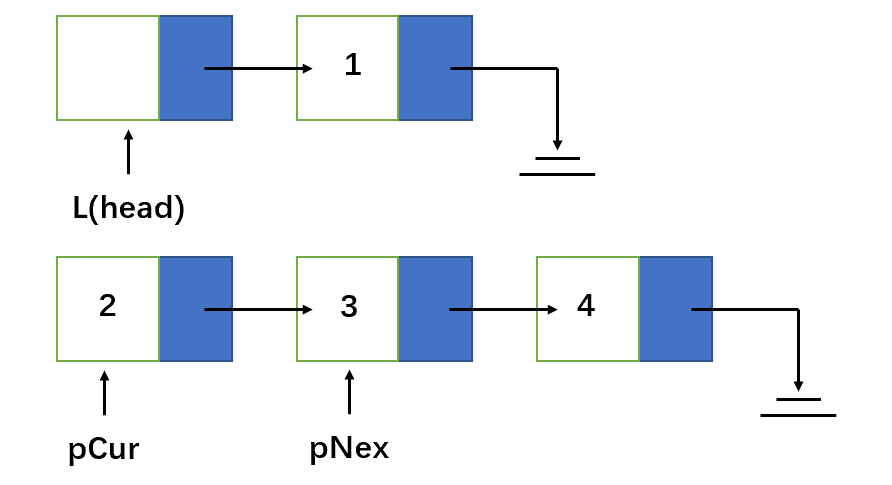
带头节点的链表:
static LinkNode reverse3(LinkNode l){
if(l.next == null || l.next.next == null){
return l;
}
LinkNode cur = l.next.next;
LinkNode next;
l.next.next = null;
while (cur != null){
next = cur.next;
cur.next = l.next;
l.next = cur;
cur = next;
}
return l;
}
不带头结点的链表:
static LinkNode reverse4(LinkNode l){
if(l == null || l.next == null){
return l;
}
LinkNode cur = l.next;
LinkNode next;
l.next = null;
while (cur != null){
next = cur.next;
cur.next = l;
l = cur;
cur = next;
}
return l;
}
3.递归反转
直接递归得到最后一个节点,然后每层就是将这个节点的下一个节点指向这个节点,这个节点指向null,最后返回末尾节点。(不带头节点)
static LinkNode reverse5(LinkNode l){
if(l == null || l.next == null){
return l;
}
LinkNode p = reverse5(l.next);
l.next.next = l;
l.next = null;
return p;
}
3、栈
栈是一种特殊的操作受限的线性数据结构,可以用用顺序表实现也可以用链表实现。在计算机中经典的应用就是函数调用或中断时,保护现场数据时使用。
因为每次都是对栈顶元素进行操作,所以一般需要一个top指针指向栈顶。
为了操作方便,和链一样,通常我们设置了一个头节点,因此top不是指向栈顶第一个元素,而是第一个元素再上一个位置。由于栈的特性,非常适合使用头插法插入数据。
-
栈的基本操作:
push:入栈操作
pop:出栈操作
top:查看栈顶元素操作
-
实现:
我们可以用链表实现栈,也可以用数组实现。如果是链表,非常简单,只需要一个指针指向头节点即可,链表的优点是出栈入栈非常的快。而使用数组就面临着如何选择数组大小的问题,一般来说我们应该让数组根据元素的个数动态改变大小,java中给出的方法是每次满了就扩大一倍数组大小,同时随着不断弹出元素数组大小也应该减小,策略是元素个数小于数组的1/4,那么就把数组缩小一半。
-
应用
- 函数调用
- 浏览器回退前进(两个栈)
- 运算表达式求解(双栈,数值一个栈,运算符一个栈)
- ...
4、队列
队列也是一种线状了操作的线性数据结构。和栈不一样,它是先进的先出FIFO,在计算机中经典的应用是进程队列。因为队列类似于现实中的排队,计算机中有排队的地方通常就会有它。
队列也有多种实现方法,常见的是基于链表实现。
-
队列的操作有:
入队(enqueue)添加到队尾
出队(dequeue)从队头移出