数据来源:阿里天池,杭州地铁刷卡数据
https://tianchi.aliyun.com/competition/entrance/231708/information
目的:预测未来一天地铁站刷卡人次
1、数据处理
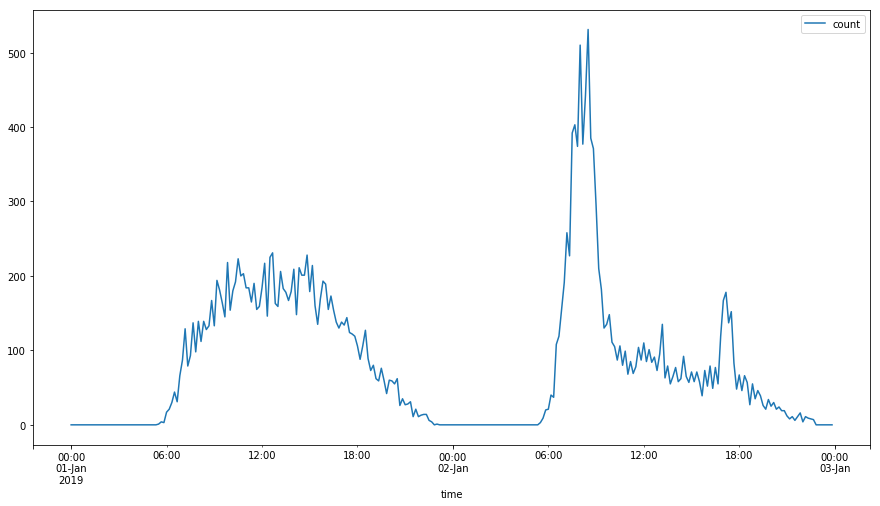
(1)统计某个站点每10分钟刷卡人次
(2)补全空白时间点数据为0
# -*- coding: utf-8 -*- """ Created on Fri Mar 22 21:03:34 2019 @author: coshaho """ import pandas as pd import numpy as np #from datetime import datetime #from datetime import timedelta filenames = [] basepath = 'D:\pworkspace\data\Metro_train\' for i in range(1, 3): if i < 10: filenames.append(basepath + 'record_2019-01-0' + str(i) + '.csv') else: filenames.append(basepath + 'record_2019-01-' + str(i) + '.csv') flag = True for filename in filenames: df = pd.read_csv(filename) df['time'] = df['time'].str[:-4] + '0:00' df['time'] = pd.to_datetime(df['time']) df0 = df[df['stationID'] == 0].copy() del df user_in = df0[df0['status'] == 1] user_out = df0[df0['status'] == 0] user_in = user_in.groupby('time') user_out = user_out.groupby('time') user_in = user_in.count() user_out = user_out.count() user_in['count'] = user_in['userID'] user_out['count'] = user_out['userID'] user_in = user_in.drop(['lineID', 'stationID', 'deviceID', 'status', 'payType', 'userID'], axis=1) user_out = user_out.drop(['lineID', 'stationID', 'deviceID', 'status', 'payType', 'userID'], axis=1) if flag: user_in_all = user_in #user_out_all = user_out flag = False else: user_in_all = pd.concat([user_in_all,user_in], axis=0) #user_out_all = pd.concat([user_out_all,user_out], axis=0) #start = datetime(2019,1,1,0,0,0) #timelist = [ str(start + timedelta(seconds=600*i)) for i in range(24 * 6 * 2)] all_time_data = pd.DataFrame({'time' : pd.date_range(start='2019-01-01 00:00:00', end='2019-01-02 23:50:00', freq='10T')}) all_time_data['count'] = 0 all_time_data.index = all_time_data['time'] all_time_data = all_time_data.drop('time', axis=1) user_in_all = pd.merge(all_time_data, user_in_all, right_on='time', left_index=True, how='outer') user_in_all[np.isnan(user_in_all['count_y'])] = 0 user_in_all['count_x'] = user_in_all['count_x'] + user_in_all['count_y'] user_in_all['count'] = user_in_all['count_x'] user_in_all = user_in_all.drop(['count_x', 'count_y'], axis=1) user_in_all.plot(figsize=(15,8))
关键:时间处理、DataFrame数据分组统计、数据合并