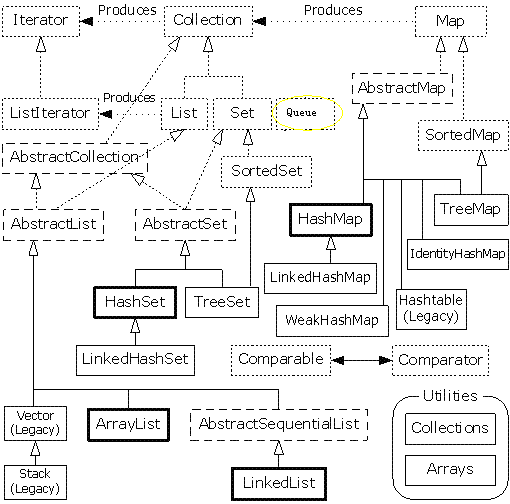
如上图:java完整容器的结构图
个人觉得java的容器结构是比较复杂的,想弄懂Java的容器,那么这个图会有很大的帮助!
图中短虚线部分为接口,长虚线部分为抽象类,实线部分为实现类,其中实线加粗为常用类。
Java SE5以后的版本新增了一些容器,主要是针对于多线程机制的
值得注意的是Java SE5之后新增了Queue接口继承于Collection,以及实现PriorityQueue和各种风格的BlockingQueue。
做为容器家族的长老级人物,个人觉得研究一下Collection还是有必要的,下面是Collection中的方法摘要,其中包括继承自Object的方法(注:Collection并没有显示的继承于Object,而继承于Iterable,同时Iterable也非继承于Object,网上有说自动继承于Object,同时给出了 权威的出处,一时间找不到了)
方法摘要
boolean add(E e)
确保此 collection 包含指定的元素(可选操作)。
boolean addAll(Collection<? extends E> c)
将指定 collection 中的所有元素都添加到此 collection 中(可选操作)。
void clear()
移除此 collection 中的所有元素(可选操作)。
boolean contains(Object o)
如果此 collection 包含指定的元素,则返回 true。
boolean containsAll(Collection<?> c)
如果此 collection 包含指定 collection 中的所有元素,则返回 true。
boolean equals(Object o)
比较此 collection 与指定对象是否相等。
int hashCode()
返回此 collection 的哈希码值。
boolean isEmpty()
如果此 collection 不包含元素,则返回 true。
Iterator<E> iterator()
返回在此 collection 的元素上进行迭代的迭代器。
boolean remove(Object o)
从此 collection 中移除指定元素的单个实例,如果存在的话(可选操作)。
boolean removeAll(Collection<?> c)
移除此 collection 中那些也包含在指定 collection 中的所有元素(可选操作)。
boolean retainAll(Collection<?> c)
仅保留此 collection 中那些也包含在指定 collection 的元素(可选操作)。
int size()
返回此 collection 中的元素数。
Object[] toArray()
返回包含此 collection 中所有元素的数组。
<T> T[] toArray(T[] a)
返回包含此 collection 中所有元素的数组;返回数组的运行时类型与指定数组的运行时类型相同。
值得注意的是,其实不包括访问元素的get()方法,主要是因为Collection包括Set,而Set是自己维护内部顺序的(这使得随机访问是没有意义的)。因此,如果想检查Collection中的元素,那就必须使用迭代器。
提到迭代器让我想起了一个问题,如上文的addAll方法,继承于Collection的容器可以将另一种继承于Collection的容器向上转型,然后通过迭代器来遍历,添加到该容器,这是一种适配器的设计模式。这样就方便了不同Collection子集的数据传递。
看看这个标题又想起一个问题,面试的时候经常为问到Collection与Collections的区别,大三来IBM实习的时候就被问到了,其实很简单,Collection我就不说了,Collections就类似于Arrays,是容器的一个工具类。
Map是Java容器的又一长老,映射表(也称为关联数组),基本思想是维护一对键-值对,通过键来查找值。
标准Java类库中包含Map的几种基本实现,包括:HashMap,TreeMap,LinkedHashMap,WeakHashMap,ConcurrentHashMap,IdentityHashMap,他们之间各自有一个自己的特性。
- HashMap:HashMap采用特殊的形式进行存储,这种形式被称为散列码,通过HashMap的实现可以看出,HashMap保存了一个数组,在插入数据的时候,同一个Key可以有一个固定的HashCode,通过这个HashCode将<K,V>这样的键值对映射到数组对应的位置,当然在采用这种散列码映射的时候难免会产生冲突,所以数组的每一个位置相当于指向了一个链表,当多个Key映射到同一个hashCode的时候,就要通过equals和==来比较key,所以这样在查找时的效率是相当快的。可以通过构造器设置容量和负载因子,以调整容器的性能。从迭代方法上来说,HashMap有两种迭代方式,一种是根据HashMap内部的HashIterator进行迭代,也就是对HashMap.Entry进行迭代;而另一种方法HashMap提供了一个KeySet功能,让使用者可以通过遍历Key来进行迭代。
- LinkedHashMap:类似于HashMap,但是迭代便利他时,取得“键值对”的顺序是插入次序,或者是最近最少使用(LRU)次序。只比HashMap慢一点;而在迭代访问时HashMap相当于是对数组的遍历,而LinkedHashMap是对一个链表的遍历,因为它使用链表来维护内部次序。从内部结构来说LinkedHashMap继承于HashMap又重新实现了自己的Entry和Iterator,这样就具有了上面的功能。
- TreeMap:基于AVL Tree(也叫平衡树或者红黑树)的实现。查看“键”或“键值对”时,他们会被排序(次序由Comparable或Comparator决定)。TreeMap的特点在于,所得到的结果是经过排序的。TreeMap是唯一的带有subMap()方法的Map,它可以返回一个子树。
- WeakHashMap, 弱键(weak key)映射,允许释放映射所指的对象;这是为解决某类特殊问题而设计的。如果映射之外没有引用指向某个“键”,则此“键”可被垃圾回收器回收。
- ConcurrentHashMap,一种线程安全的Map,他不涉及同步加锁。
- IdentityHashMap,使用==代替equals对“键”进行比较的散列映射。
Set,大概看了一些Set的实现类,如HashSet,TreeSet,发现Set其实是基于Map来搭建的,如果你了解了Map的结构那你就知道Set是怎么回事儿了,看了jdk的源码就会知道,原来所谓的Set都是由Map构成的,只不过Map是通过<Key,Value>的形式存储,而Set中的Value都指向同一个对象,jdk中给他起名叫PRESENT(替代者),这样就不会造成太大的空间浪费了。
HashSet的实现
- public class HashSet<E>
- extends AbstractSet<E>
- implements Set<E>, Cloneable, java.io.Serializable
- {
- static final long serialVersionUID = -5024744406713321676L;
- private transient HashMap<E,Object> map; //内部结构的维护使用的HashMap
- // Dummy value to associate with an Object in the backing Map
- private static final Object PRESENT = new Object();
- /**
- * Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
- * default initial capacity (16) and load factor (0.75).
- */
- public HashSet() {
- map = new HashMap<E,Object>();
- }……
而LinkedHashSet继承自HashSet,
再看一下TreeSet
- public class TreeSet<E> extends AbstractSet<E>
- implements NavigableSet<E>, Cloneable, java.io.Serializable
- {
- /**
- * The backing map.
- */
- private transient NavigableMap<E,Object> m;
- // Dummy value to associate with an Object in the backing Map
- private static final Object PRESENT = new Object();
- /**
- * Constructs a set backed by the specified navigable map.
- */
- TreeSet(NavigableMap<E,Object> m) {
- this.m = m;
- }
List和存储顺序
从List接口展开的实现类有ArrayList,LinkedList,Vector和Stack,其中Vector和Stack被称为遗留类,是用于支持遗留代码,向前兼容,你不应该再去使用这样的东西,但Vector在处理并发的时候加了同步,而ArrayList没有这个功能,以前因为同步的问题总觉得ArrayList并不能完全的替代Vector,但后来才知道Jdk早就提供了一个CopyOnWriteArrayList,专门用于处理并发,所以Vector确实不应该再用了。
关于ArrayList:ArrayList底层是由数组来实现的,默认会初始化一个初度为10的Object数组,随着数据的增加,创建一个新的数组然后将就数据拷贝过来,长度变换规律如下:
- public void ensureCapacity(int minCapacity) {
- modCount++;
- int oldCapacity = elementData.length;
- if (minCapacity > oldCapacity) {
- int newCapacity = (oldCapacity * 3)/2 + 1;
- if (newCapacity < minCapacity)
- newCapacity = minCapacity; // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity);
- }
- }
- }
新的容量=(旧容量×3)/2+1;有兴趣也可以看一下Vector的实现。
关于LinkedList:LisnedList底层采用双向链表的链式结构,学过数据结构的都知道,这样的链式结构相对于ArrayList来说优点是插入删除快,缺点是搜索相对较慢。