(一)Series初始化
1.通过列表,index自动生成
se = pd.Series(['Tom', 'Nancy', 'Jack', 'Tony'])
print(se)

2.通过列表,指定index
se = pd.Series(['Tom', 'Nancy', 'Jack', 'Tony'], index=['idx_a', 'idx_b', 'idx_c', 'idx_d'])
print(se)

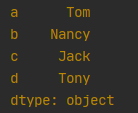
3.通过字典,字典的key为Series的index
se = pd.Series({'a': 'Tom', 'b': 'Nancy', 'c': 'Jack', 'd': 'Tony'})
print(se)
4.通过迭代器,index自动生成
se = pd.Series(range(4))
print(se)

5.通过numpy.arange,index自动生成
se = pd.Series(np.arange(4))
print(se)

(二)Dataframe初始化
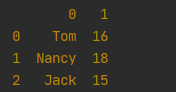
1.1 通过列表,columns及index自动生成
df = pd.DataFrame([['Tom', 16], ['Nancy', 18], ['Jack', 15]])
print(df)
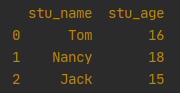
1.2 通过列表,指定columns
df = pd.DataFrame([['Tom', 16], ['Nancy', 18], ['Jack', 15]], columns=['stu_name', 'stu_age'])
print(df)
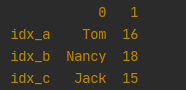
1.3 通过列表,指定index
df = pd.DataFrame([['Tom', 16], ['Nancy', 18], ['Jack', 15]], index=['idx_a', 'idx_b', 'idx_c'])
print(df)
1.4 通过列表,指定columns跟index
df = pd.DataFrame([['Tom', 16], ['Nancy', 18], ['Jack', 15]], columns=['stu_name', 'stu_age'], index=['idx_a', 'idx_b', 'idx_c'])
print(df)
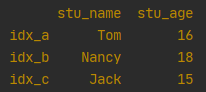
2.1 通过字典,字典key为column,index自动生成
df = pd.DataFrame({'stu_name': ['Tom', 'Nancy', 'Jack', 'Tony'], 'stu_age': [16, 18, 15, 20]})
print(df)
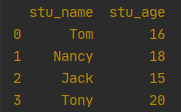
2.2 通过字典,字典key为column,并指定index
df = pd.DataFrame({'stu_name': ['Tom', 'Nancy', 'Jack', 'Tony'], 'stu_age': [16, 18, 15, 20]}, index=['a', 'b', 'c', 'd'])
print(df)
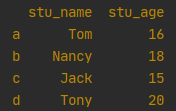
3. 通过值为字典的列表,一个字典为一行,列数目不相等自动补充NaN
df = pd.DataFrame([{'col1': 1, 'col2': 2}, {'col1': 5, 'col2': 10, 'col3': 20}, {'col1': 98, 'col2': 99}])
print(df)
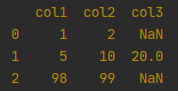
4. 通过迭代器
df = pd.DataFrame({'col1': range(3), 'col2': range(3)})
print(df)

5. 通过numpy.arange
df = pd.DataFrame({'col1': np.arange(3), 'col2': np.arange(5, 8)})
print(df)
6. 读取csv
df = pd.read_csv('test.csv')