监督学习是指:利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程。
我们来看一个例子:预测房价(注:本文例子取自业界大牛吴恩达老师的机器学习课程)
如下图所示:横轴表示房子的面积,单位是平方英尺,纵轴表示房价,单位是千美元。那基于这组数据,假如你有一个朋友,他有一套 750 平方英尺房子,现在他希望把房子卖掉,他想知道这房子能卖多少钱。

我们应用学习算法,可以在这组数据中画一条直线,或者换句话说,拟合一条直线,根据这条线我们可以推测出,这套房子可能卖$150, 000,当然这不是唯一的算法。可能还有更好的,比如我们不用直线拟合这些数据,用二次方程去拟合可能效果会更好。根据二次方程的曲线,我们可以从这个点推测出,这套房子能卖接近$200, 000。
可以看出,监督学习指的就是我们给学习算法一个数据集。这个数据集由“正确答案” 组成。在房价的例子中,我们给了一系列房子的数据,我们给定数据集中每个样本的正确价格,即它们实际的售价然后运用学习算法,算出更多的正确答案。比如你朋友那个新房子的价格。用术语来讲,这叫做回归问题(回归这个词的意思是,我们在试着推测出这一系列连续值属性)。我们试着推测出一个连续值的结果,即房子的价格。 一般房子的价格会记到美分,所以房价实际上是一系列离散的值,但是我们通常又把房价看成实数,看成是标量,所以又把它看成一个连续的数值。
再看一个例子:
假设说你想通过查看病历来推测乳腺癌良性与否,假如有人检测出乳腺肿瘤,恶性肿瘤有害并且十分危险,而良性的肿瘤危害就没那么大,所以人们显然会很在意这个问题。
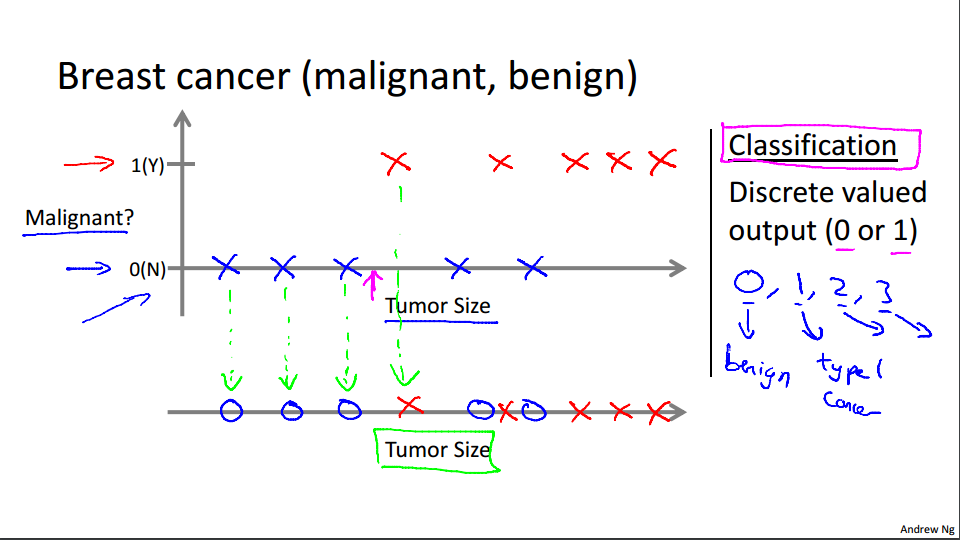
让我们来看一组数据:这个数据集中,横轴表示肿瘤的大小,纵轴上,我标出 1 和 0 表 示是或者不是恶性肿瘤。我们之前见过的肿瘤,如果是恶性则记为 1 ,不是恶性,或者说良性记为 0。 我有 5 个良性肿瘤样本,在 1 的位置有 5 个恶性肿瘤样本。现在我们有一个朋友很不幸检查出乳腺肿瘤。假设说她的肿瘤大概这么大,那么机器学习的问题就在于,你能否估算出肿瘤是恶性的或是良性的概率。用术语来讲,这是一个分类问题。 分类指的是,我们试着推测出离散的输出值:0 或 1 良性或恶性,而事实上在分类问题中,输出可能不止两个值。比如说可能有三种乳腺癌,所以你希望预测离散输出 0、1、2、 3。0 代表良性,1 表示第一类乳腺癌,2 表示第二类癌症,3 表示第三类,但这也是分类问题。
因为这几个离散的输出分别对应良性,第一类第二类或者第三类癌症,在分类问题中我们可以用另一种方式绘制这些数据点。
现在我用不同的符号来表示这些数据。既然我们把肿瘤的尺寸看做区分恶性或良性的特征,那么我可以这么画,我用不同的符号来表示良性和恶性肿瘤。或者说是负样本和正样本现在我们不全部画 X,良性的肿瘤改成用 O 表示,恶性的继续用 X 表示。来预测肿瘤的恶性与否。
总结,监督学习的基本思想是——我们的数据集中,每个样本都有相应的“正确答案”,再根据这些样本作出预测。