相关文章:1.初步分析 2.记号对象 3.词法分析
上一篇中介绍通过词法分析将表达式转换成TokenRecord对象列表。在第一篇中提到将表达式用树形结构表示,然后就可以很方便的从下级节点取值计算了。那么如何将列表分析成一棵树的结构呢?
还是以例子来说明,比如3*7+56/8-2*5,分析成TokenRecord列表就是
|
记号对象
|
对应表达式
|
|
TokenValue
|
3
|
|
TokenMultiply
|
*
|
|
TokenValue
|
7
|
|
TokenPlus
|
+
|
|
TokenValue
|
56
|
|
TokenDivide
|
/
|
|
TokenValue
|
8
|
|
TokenMinus
|
-
|
|
TokenValue
|
2
|
|
TokenMultiply
|
*
|
|
TokenValue
|
5
|
分析成树就是

根据实际的算术规则,运算符优先级高的要先计算,然后由低优先级的运算符去调用它的运算结果。表现在树视图上就是高优先级的节点是低优先级节点的下级,即优先级越高,其位置越靠近树叶。因为这里采用统一的对象,把所有元素都用TokenRecord表示,所以TokenValue也是有优先级的。而通过对树视图的分析,所有的TokenValue都是处在叶子的位置,则TokenValue的优先级最高。
分析到这里就要用代码实现了。这里需要用到TokenRecord中的优先级Priority属性,还要用到堆栈。和词法分析一样,也是需要用循环依次分析各个TokenRecord。拿上面的TokenRecord列表进行分析,粗体字代表当前分析的TokenRecord。分析的过程中有一个原则叫“高出低入原则”,需要解释一下。
“高出低入原则”是指:
1.栈顶TokenRecord的优先级高于当前TokenRecord的优先级,则将栈顶TokenRecord弹栈(高出)到临时变量。
1.1如果堆栈为空,将临时变量中的TokenRecord加入当前TokenRecord的ChildList中,然后将当前TokenRecord压栈(低入)。
1.2如果堆栈不为空,找出栈顶TokenRecord和当前TokenRecord中优先级高的一个(相同则按栈顶高算),将临时变量中的TokenRecord加入高优先级TokenRecord的ChildList中。再用高出低入原则处理栈顶和当前TokenRecord。
2.栈顶TokenRecord的优先级低于当前TokenRecord的优先级,则将当前TokenRecord直接压栈。
可能文字表述的并不清晰,其中涉及到循环和递归的操作,具体的过程通过下面的例子来讲解。
1.列表分析状态:
|
TokenValue(3)
|
TokenMultiplay
|
TokenValue(7)
|
…...
|
堆栈分析:当前堆栈为空,将当前分析的TokenRecord压栈。
堆栈对应树视图:

2.列表分析状态:
|
TokenValue(3)
|
TokenMultiply
|
TokenValue(7)
|
…...
|
堆栈分析:栈顶为TokenValue,当前TokenRecord为TokenMultiply,TokenValue优先级最高。遵循高出低入原则,将TokenValue弹栈并添加到TokenMultiply的ChildList中,然后将TokenMultiplay压栈。
堆栈对应树视图:
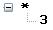
3.列表分析状态
|
…...
|
TokenMultiply
|
TokenValue(7)
|
TokenPlus
|
…...
|
堆栈分析:栈顶为TokenMultiplay,当前TokenRecord为TokenValue,TokenMultiply优先级高于TokenValue,则将TokenValue加入TokenMultiplay的ChildList中。
堆栈对应树视图:

4.列表分析状态
|
……
|
TokenValue(7)
|
TokenPlus
|
TokenValue(56)
|
…...
|
堆栈分析:栈顶为TokenMultiply,当前TokenRecord为TokenPlus,TokenMultiply优先级高于TokenPlus。遵循高出低入原则,将TokenMultiply弹栈并添加到TokenPlus的ChildList中,然后将TokenPlus压栈。
堆栈对应树视图:

5.列表分析状态
|
……
|
TokenPlus
|
TokenValue(56)
|
TokenDivide
|
…...
|
堆栈分析:栈顶为TokenPlus,当前TokenRecord为TokenValue,TokenPlus优先级低于TokenValue。遵循高出低入原则,不需要弹栈,直接将TokenValue压栈。
|
TokenValue(56)
|
|
TokenPlus
|
|
栈底
|
堆栈对应树视图:

6.列表分析状态
|
……
|
TokenValue(56)
|
TokenDivide
|
TokenValue(8)
|
…...
|
堆栈分析:栈顶为TokenValue,当前TokenRecord为TokenDivide,TokenValue优先级高于TokenDivide。遵循高出低入原则,将TokenValue弹栈并加入TokenDivide的ChildList中。此时栈顶为TokenPlus,TokenDivide优先级高于TokenPlus,遵循高出低入原则,将TokenDivide压栈。
堆栈对应树视图:

7.列表分析状态
|
……
|
TokenDivide
|
TokenValue(8)
|
TokenMinus
|
…...
|
堆栈分析:栈顶为TokenDivide,当前TokenRecord为TokenValue,TokenDivide优先级高于TokenValue。遵循高出低入原则,将TokenValue加入TokenDivide的ChildList中。
堆栈对应树视图:

8列表分析状态
|
……
|
TokenValue(8)
|
TokenMinus
|
TokenValue(2)
|
……
|
堆栈分析:栈顶为TokenDivide,当前TokenRecord为TokenMinus,TokenDivde优先级高于TokenMinus。遵循高出低入原则,将TokenDivide弹栈到临时变量。检测到堆栈不为空,此时栈顶为TokenPlus,TokenPlus优先级和TokenMinus一样。这里相同优先级的按高优先级处理,遵循高出低入原则,则将临时变量中的TokenDivide加入高优先级TokenPlus的ChildList中。继续用高出低入原则,将TokenPlus弹栈并加入TokenMinus的ChildList中,再将TokenMinus压栈。
堆栈对应树视图:

9.列表分析状态
|
……
|
TokenMinus
|
TokenValue(2)
|
TokenMultiply
|
…...
|
堆栈分析:栈顶是TokenMinus,当前TokenRecord是TokenValue,TokenMinus优先级低于TokenValue。遵循高出低入原则,将TokenValue压栈。
|
TokenValue(2)
|
|
TokenMinus
|
|
栈底
|
堆栈对应树视图:
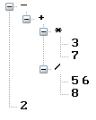
10.列表分析状态
|
……
|
TokenValue(2)
|
TokenMultiply
|
TokenValue(5)
|
堆栈分析:栈顶是TokenValue,当前TokenRecord是TokenMultiply,TokenValue优先级高于TokenMultiply。遵循高出低入原则,将TokenValue弹栈到临时变量,检测堆栈不为空,此时栈顶为TokenMinus,TokenMinus优先级低于TokenMultiply,则将临时变量中的TokenValue加入TokenMultiplay的ChildList中。遵循高出低入原则,将TokenMultiplay加入到栈顶TokenMinus的ChildList中。
|
TokenMultiply
|
|
TokenMinus
|
|
栈底
|
堆栈对应树视图:

11.列表分析状态
|
……
|
TokenValue(2)
|
TokenMultiply
|
TokenValue(5)
|
堆栈分析:栈顶是TokenMultiply,当前是TokenValue,TokenMultiply优先级高于TokenValue。遵循高出低入原则,将TokenValue加入TokenMultiply的ChildList中。
|
TokenMultiply
|
|
TokenMinus
|
|
栈底
|
堆栈对应树视图:

12.堆栈分析:此时列表分析结束,堆栈不为空,需要对堆栈进行处理。经过上面的堆栈分析,遵循高出低入原则,堆栈中的TokenRecord肯定是栈底优先级最低,栈顶优先级最高。只需要将堆栈中的TokenRecord依次弹栈,然后加入到新栈顶的ChildList中即可。最后弹栈的一个TokenRecord就是整个树视图的根节点,也就是返回值。到此,堆栈为空,也得到了预期的树视图,返回根节点TokenRecord即可。
上面是对语法分析整个流程的分析,下面给出具体的代码。程序中的语法分析放在一个单独的文件中,SyntaxTreeAnalyse.cs,文件中也只有一个SyntaxTreeAnalyse类,专门用于语法树的分析。这个类只有一个入口即一个公开方法SyntaxTreeGetTopTokenAnalyse,传入TokenRecord列表,经过分析后返回一个顶级TokenRecord对象,即树形结构的根节点。具体代码如下:

 Code
Code
/// <summary>
/// 语法树分析
/// </summary>
/// <remarks>Author:Alex Leo</remarks>
internal class SyntaxTreeAnalyse
{
/// <summary>
/// 记号段提取,提取顶级操作记号
/// </summary>
/// <param name="IndexStart">起始序号</param>
/// <param name="IndexEnd">结束序号</param>
/// <returns>传入记号段的顶级操作记号记录对象</returns>
/// <remarks>Author:Alex Leo</remarks>
internal static TokenRecord SyntaxTreeGetTopTokenAnalyse(List<TokenRecord> TokenList, int IndexStart, int IndexEnd)
{
int intIndexCurrent = IndexStart;//当前处理序号
int intIndexSubStart = IndexStart;//子记号段的起始序号
TokenRecord Token;//获取当前Token
Stack<TokenRecord> StackCompart = new Stack<TokenRecord>();//括号堆栈
Stack<TokenRecord> StackOperate = new Stack<TokenRecord>();//操作记号堆栈
for (int intIndex = IndexStart; intIndex <= IndexEnd; intIndex++)
{
Token = TokenList[intIndex];
intIndexCurrent = intIndex;
if (Token is TokenLeftBracket)
{
StackCompart.Push(TokenList[intIndexCurrent]);//把左括号压栈
//获取该括号对中包含的记号段
intIndexSubStart = intIndexCurrent + 1;//设置子记号段的起始序号
//提取记号段
//如果语法错误,比如在记号段的末尾没有配对的右括号记号,则会出错,这里假设为语法正确
while (StackCompart.Count > 0)
{
intIndexCurrent += 1;
if (intIndexCurrent >= TokenList.Count)
{
//Error or auto add lossed bracket
throw new SyntaxException(Token.Index, Token.Length, "缺少配对的括号");
}
if (TokenList[intIndexCurrent] is TokenLeftBracket)
{
StackCompart.Push(TokenList[intIndexCurrent]);
}
else if (TokenList[intIndexCurrent] is TokenRightBracket)
{
StackCompart.Pop();
}
}
TokenRecord TokenInnerTop = SyntaxTreeGetTopTokenAnalyse(TokenList, intIndexSubStart, intIndexCurrent - 1);
if (TokenInnerTop != null)//只有在取得括号中的顶级节点才添加
{
Token.ChildList.Add(TokenInnerTop);
}
else
{
//无法获取括号内的顶级节点
throw new SyntaxException(Token.Index, Token.Length, "括号内不包含计算表达式");
}
intIndex = intIndexCurrent;//移动序号到当前序号
SyntaxTreeStackAnalyse(StackOperate, Token);
}//if token is TokenLeftBracket
else if (Token is TokenMethod)//方法处理
{
//检查方法后是否接着左括号
if (intIndexCurrent >= IndexEnd || !(TokenList[intIndexCurrent + 1] is TokenLeftBracket))
{
throw new SyntaxException(Token.Index, Token.Length, "方法后缺少括号");
}
intIndexSubStart = intIndexCurrent;//设置子记号段的起始序号
intIndexCurrent += 1;//指针后移
StackCompart.Push(TokenList[intIndexCurrent]);//把左括号压栈
//提取记号段
//如果语法错误,比如在记号段的末尾没有配对的右括号记号,则会出错,这里假设为语法正确
while (StackCompart.Count > 0)
{
intIndexCurrent += 1;
if (intIndexCurrent >= TokenList.Count)
{
//Error or auto add lossed bracket
throw new SyntaxException(Token.Index, Token.Length, "缺少配对的括号");
}
if (TokenList[intIndexCurrent] is TokenLeftBracket)
{
StackCompart.Push(TokenList[intIndexCurrent]);
}
else if (TokenList[intIndexCurrent] is TokenRightBracket)
{
StackCompart.Pop();
}
}
if ((intIndexCurrent - intIndexSubStart) == 2)//如果右括号的序号和方法的序号之差是2,说明中间只有一个左括号
{
throw new SyntaxException(TokenList[intIndexCurrent - 1].Index, 1, "括号内不包含计算表达式");
}
//分析方法记号段,因为方法括号段中可能有多个运算结果,比如if,max等,不能用获取顶级节点的方法SyntaxTreeGetTopTokenAnalyse
SyntaxTreeMethodAnalyse(TokenList, intIndexSubStart, intIndexCurrent);
intIndex = intIndexCurrent;//移动序号到当前序号
SyntaxTreeStackAnalyse(StackOperate, Token);
}//if token is TokenKeyword
else if (Token is TokenSymbol || Token is TokenValue)
{
SyntaxTreeStackAnalyse(StackOperate, Token);
}
else
{
//不做处理
throw new SyntaxException(Token.Index, Token.Length, "运算符位置错误");
}
}
return SyntaxTreeStackGetTopToken(StackOperate);//返回顶级记号
}
/// <summary>
/// 方法记号段分析(处于括号中间的代码段)
/// </summary>
/// <param name="ListToken">记号列表</param>
/// <param name="IndexStart">括号开始的序号</param>
/// <param name="IndexEnd">括号结束的序号</param>
/// <remarks>只处理完整的方法段,比如if( ), round()</remarks>
), round()</remarks>
/// <remarks>Author:Alex Leo</remarks>
private static void SyntaxTreeMethodAnalyse(List<TokenRecord> ListToken, int IndexStart, int IndexEnd)
{
int intIndexSubStart = IndexStart;//子记号段的起始序号
intIndexSubStart = IndexStart + 2;//移动子记号段的开始序号到括号后面
int intIndexSubEnd = IndexEnd;//子记号段的结束序号
TokenRecord TokenMethod = ListToken[IndexStart];//方法记号对象
TokenRecord TokenCurrent;//获取当前Token
Stack<TokenRecord> StackCompart = new Stack<TokenRecord>();//分隔符堆栈
for (int intIndex = IndexStart; intIndex <= IndexEnd; intIndex++)
{
TokenCurrent = ListToken[intIndex];
if (TokenCurrent is TokenLeftBracket)
{
StackCompart.Push(TokenCurrent);
}
else if (TokenCurrent is TokenRightBracket)
{
StackCompart.Pop();
if (StackCompart.Count == 0)//如果是最后一个右括号
{
intIndexSubEnd = intIndex - 1;//设置段结束序号
TokenMethod.ChildList.Add(SyntaxTreeGetTopTokenAnalyse(ListToken, intIndexSubStart, intIndexSubEnd));//递归
}
}
else if (TokenCurrent is TokenComma)
{
if (StackCompart.Count == 1)//如果是方法的子段
{
intIndexSubEnd = intIndex - 1;//设置段结束序号
TokenMethod.ChildList.Add(SyntaxTreeGetTopTokenAnalyse(ListToken, intIndexSubStart, intIndexSubEnd));//递归
intIndexSubStart = intIndex + 1;//把子记号段序号后移
}
}
else
{
//不作处理
}
}
//TokenMethod.GetType().GetMethod("CheckChildCount").Invoke(TokenMethod, new object[] { "运算元素数量不合法" });
}
/// <summary>
/// 语法树堆栈分析,基于记号的优先级
/// </summary>
/// <param name="SyntaxTreeStack">语法树堆栈</param>
/// <param name="NewToken">新记号</param>
/// <remarks>Author:Alex Leo</remarks>
private static void SyntaxTreeStackAnalyse(Stack<TokenRecord> SyntaxTreeStack, TokenRecord NewToken)
{
if (SyntaxTreeStack.Count == 0)//如果语法树堆栈中不存在记号,则直接压栈
{
SyntaxTreeStack.Push(NewToken);
}
else//否则,比较优先级进行栈操作
{
//比较优先级,如果新Token优先级高,则压栈;
//如果新Token优先级低,则弹栈,把弹出的Token设置为新Token的下级,并把新Token压栈;
//相同优先级也弹栈,并将新Token压栈
//if (this.m_DicTokenTypePriority[SyntaxTreeStack.Peek().TokenType] < this.m_DicTokenTypePriority[NewToken.TokenType])//低进
if (SyntaxTreeStack.Peek().Priority < NewToken.Priority)//低进
{
SyntaxTreeStack.Push(NewToken);//低进
}
else
{
TokenRecord TempToken = null;
//如果堆栈中有记号,并且栈顶的记号优先级大于等于新记号的优先级,则继续弹栈
while (SyntaxTreeStack.Count > 0 && (SyntaxTreeStack.Peek().Priority >= NewToken.Priority))
{
TempToken = SyntaxTreeStack.Pop();
if (SyntaxTreeStack.Count > 0)//检测栈顶是否可能为空,如果为空则退出
{
if (SyntaxTreeStack.Peek().Priority >= NewToken.Priority)
{
SyntaxTreeStack.Peek().ChildList.Add(TempToken);
}
else
{
NewToken.ChildList.Add(TempToken);
}
}
else
{
NewToken.ChildList.Add(TempToken);
}
}
SyntaxTreeStack.Push(NewToken);//压栈
}
}
}
/// <summary>
/// 获取语法树堆栈的顶级记号
/// </summary>
/// <param name="SyntaxTreeStack">语法树堆栈</param>
/// <returns>顶级记号</returns>
/// <remarks>Author:Alex Leo</remarks>
private static TokenRecord SyntaxTreeStackGetTopToken(Stack<TokenRecord> SyntaxTreeStack)
{
TokenRecord TempToken = null;
if (SyntaxTreeStack.Count > 0)
{
TempToken = SyntaxTreeStack.Pop();
while (SyntaxTreeStack.Count > 0)
{
SyntaxTreeStack.Peek().ChildList.Add(TempToken);
TempToken = SyntaxTreeStack.Pop();
}
}
return TempToken;
}
}//class SyntaxTreeAnalyse
代码中对括号进行了特殊处理,遇到左括号之后需要查找到配对的右括号,然后对这一段调用SyntaxTreeGetTopTokenAnalyse进行递归处理,找出括号中的顶级节点。而对于方法也需要特殊处理,方法必须带括号,而且括号中不止一个根节点。处理过程是以逗号为分隔符,依次找出括号中的几个节点,然后添加到方法的ChildList中。实际的代码在SyntaxTreeMethodAnalyse方法中实现。
这一篇写的我自己都头晕了,呵呵,堆栈一个个分析,截图都挺烦。代码里方法互相递归调用,也是比较让人容易头晕的,希望有人能看懂吧。
代码下载:
https://files.cnblogs.com/conexpress/ConExpress_MyCalculator.rar
Author:Alex Leo
Email:conexpress@qq.com
Blog:http://conexpress.cnblogs.com/