train集:
包含若干条与保险相关的问题,每一组问题对为一行,示意如下:
![]()
可分为四项,第三项为问题,第四项为答案:

1.build_vocab
统计训练集中出现的词,返回结果如下(一个包含3085个元素的dict,每个词作为一个key,value为这些词出现的顺序):![]()
2. load_word_embedding(vocab,embedding_size)
vocab为第一步获取的词集,embedding_size=100
load_vectors()
获取预先训练好的保存在vectors.nobin中的词向量
返回的vector中保存有22353个词的向量
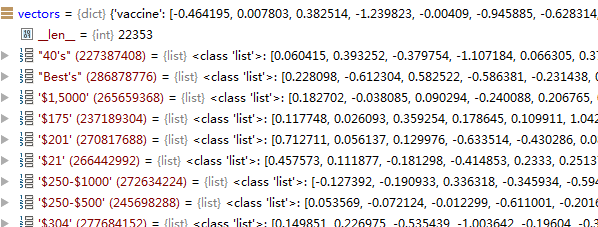
然后通过暴力匹配,获取vocab中每个词的词向量,存在embeddings中,embedding中的序数对应的是vacab中的key的value

3. load_train_list
获取保存在train中18540个问题与答案

4. load_test_list
获取保存在test.sample中的问题与答案,共10000条
在测试集中,共有20个问题,每个问题包含若干个正确答案与错误答案,共500个答案,由每一行的第一个元素标识,为1时为正确答案,为0时为错误答案
5.load_data(trainList,vocab,batch_size)
batch_size=256
encode_sent(vocab,string,size) 讲string中的词转换成vocab中所对应的的序号
得到一个batch_size的train_1(问题),train_2(正确答案), train_3(错误答案)
同时返回3个mask,用于标识数据集语句除去 < a > 后的真实的长度
6. LSTM Model

proj_size=100
初始化LSTM的参数
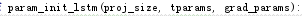
project_size=100
tparams={}
grad_params=[]
 随机生成ndimndim的矩阵W,对其进行SVD分解得到 u,s,v,返回floatX的u,维度100100
随机生成ndimndim的矩阵W,对其进行SVD分解得到 u,s,v,返回floatX的u,维度100100
初始化W,维度为100400

W_t=W
tparam[‘lstm_W’]=W_t
初始化U,维度为100400,U_T=U,tparam[‘lstm_U’]=W_t

初始化b,b的维度为4001,初始化为0,b_t=b,tparam[‘lstm_b’]=b_t
grad_params=[W_t, U_t,b_t]
返回tparam和grad_params
返回后的分别赋值给tparam和self.params
初始化CNN的参数
![]()
filter_sizes=[1,2,3,5]
num_filters=500
proj_size=100
tparam={lstm_U, lstm_w, lstm_b} 之前lstm初始化时赋好的值
self.params=lstm赋好的self.params
对于filter_sizes中的每一个元素(以2为例):
filter_shape=(num_filters,1,filter_size,proj_size)=(500,1,2,100)
fan_in=filter_shape[1:]的乘积=200
fan_out=filter_shape[0]np.prod(filter_shape[2:]) 500filter_shapefilter_sizeproj_size=100000
W_bound=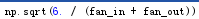
W初始化为最低值为-w_bound,最大值为w_bound,size=filter_shape
 =tparams[‘cnn_w_2’]=W
=tparams[‘cnn_w_2’]=W
初始化b为5001维的向量
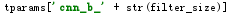 =tparams[‘cnn_b_2’]=b
=tparams[‘cnn_b_2’]=b
grand_params+=[W,b]
最终返回tparams和grad_params 各含有11个元素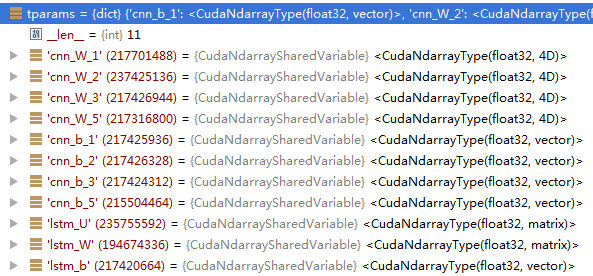
lookup_table=word_embedding
tparams[‘lookup_table’]=lookup_table


input1, input2, input3分别是问题,正确答案,错误答案
![]()
这一函数首先将input的训练集转成词向量模式的
将input的矩阵reshape成(sequence_len,batch_size, embedding_size)(100,256,100)的input_x
state_below就是input
nsteps=训练数据的sequence_len
n_samples=训练数据的batch_size
input=input*lstm_W+lstm_b
通过scan做lstm的相关步骤
得到的输出在输入CNN中,抽取特征,计算问题,正确答案,错误答案的相似度,余下的与QACNN类同