网络中的机器学习
节点分类
链接预测
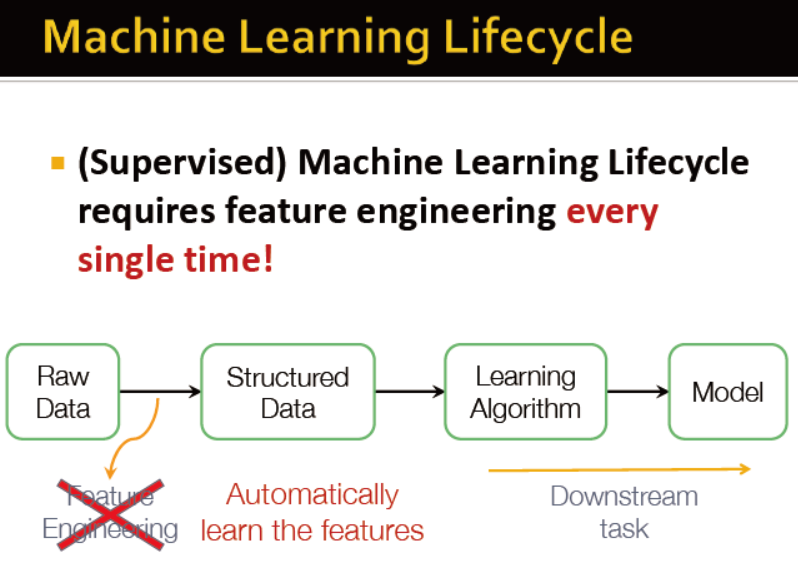
机器学习的生命圈需要特征工程
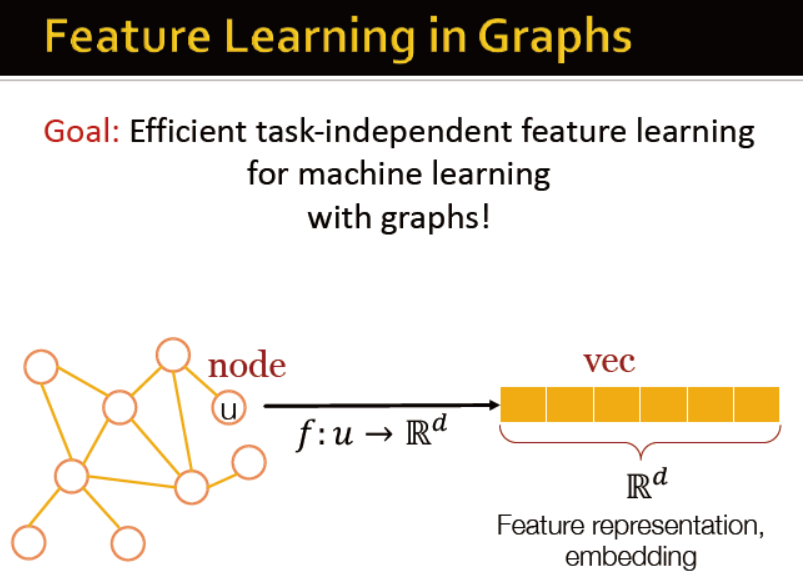
网络的特征学习——特征向量 embedding
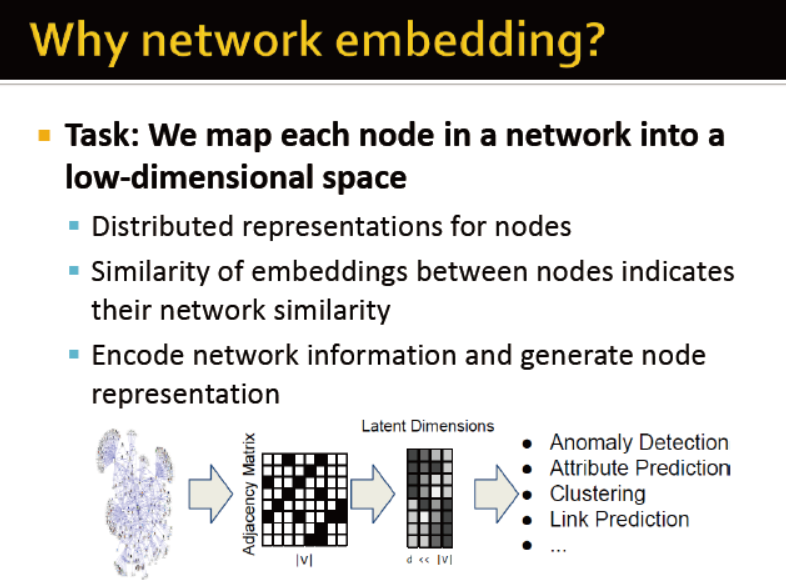
network embedding的意义
节点的表征
节点的相似度衡量→网络相似度衡量
网络信息编码,生成节点表征
用途:异常检测,属性预测,聚类,关系预测
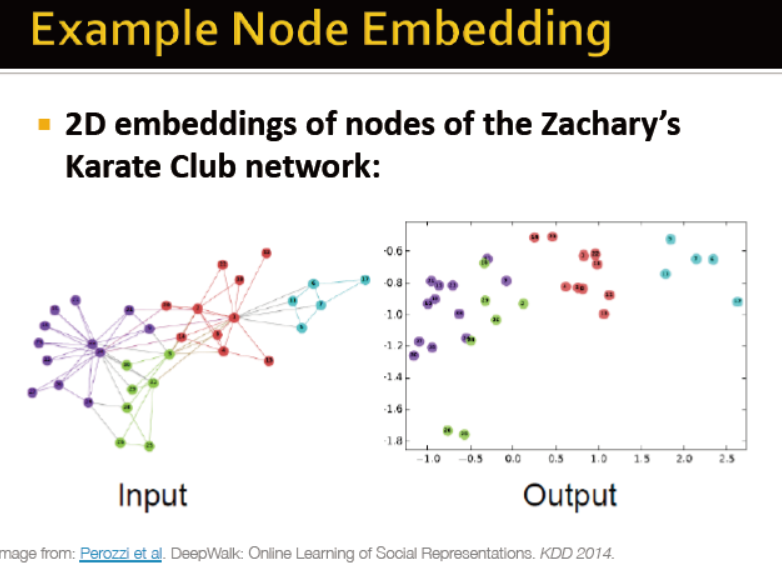
例子:deepwalk
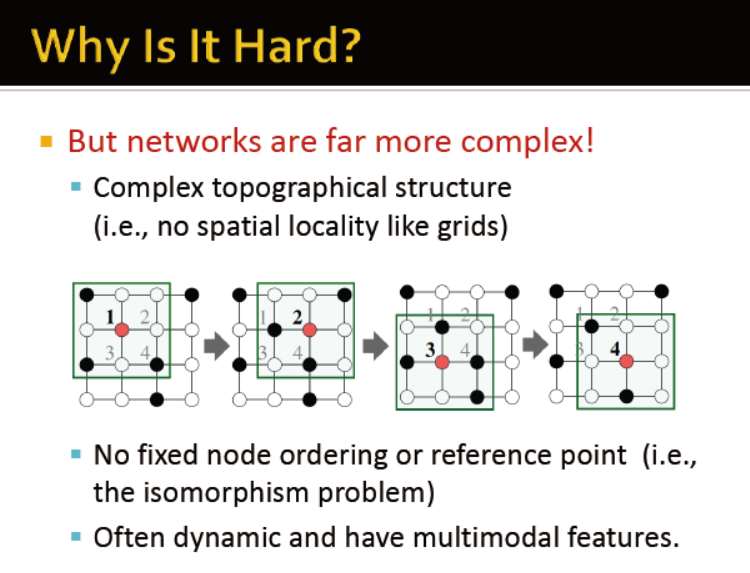
难度:当前的深度学习视为序列或网格数据而设计的,但网络结构比这些更复杂,没有固定的空间结构,没有固定的顺序,是动态的,并且有多类特征

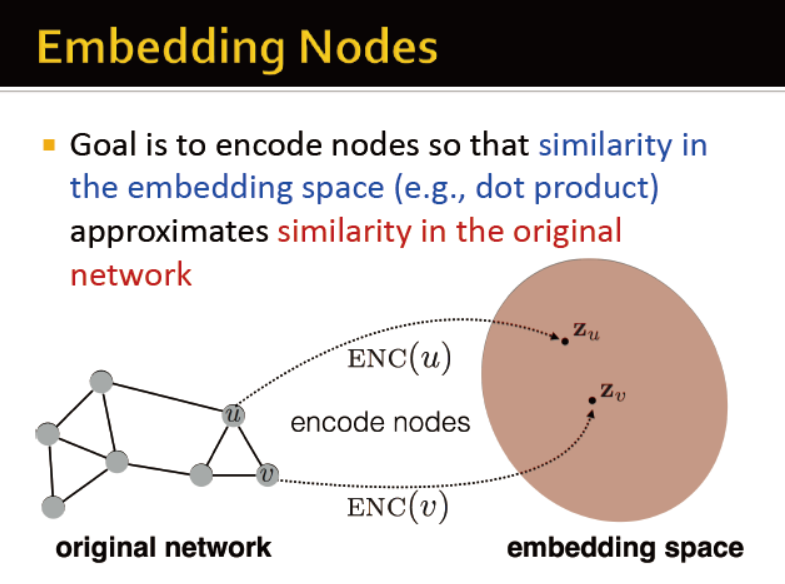
Embedding Nodes

假设我们有图G,V是节点集合,A是邻接矩阵,
将节点编码,编码后的向量计算得到的相似度与原网络的一致
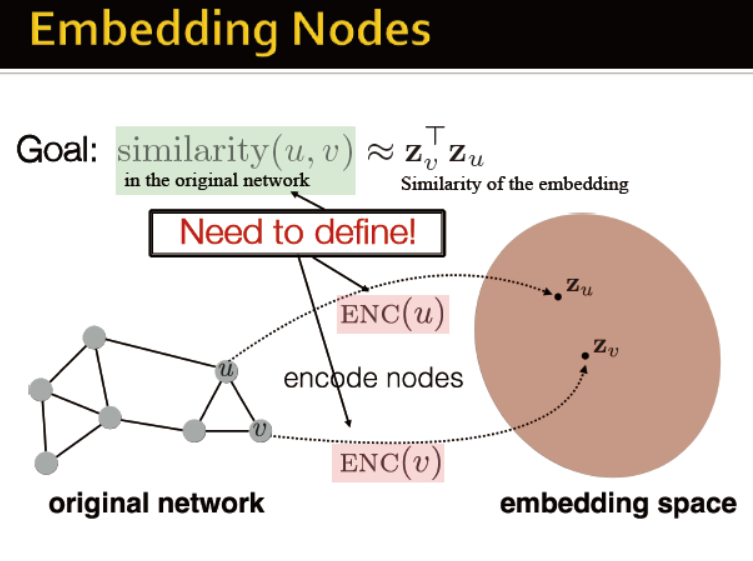
因此需要定义一个编码器,以及计算节点相似度的函数,并优化encoder


浅层encoding,有一个大矩阵,存储各类节点的向量,encoder只是look-up,类似于word embedding


常见的方法:deepwalk,node2vec,transE

如何定义节点相似性
例子:若两个节点的embedding相似,那么在物理结构上,他们:相连?有相同邻居?相似的结构角色?等

随机游走→node embedding

随机游走:从一个节点出发,随机选择一个邻居节点,游走到该节点,再重复上述步骤。经过的节点组成的序列即为图的random walk

公式表示节点u,v在random walk中共同出现的概率

步骤:
1. 随机游走,得到若干序列
2. 优化encoder,使共同出现的节点的序列相似度更近
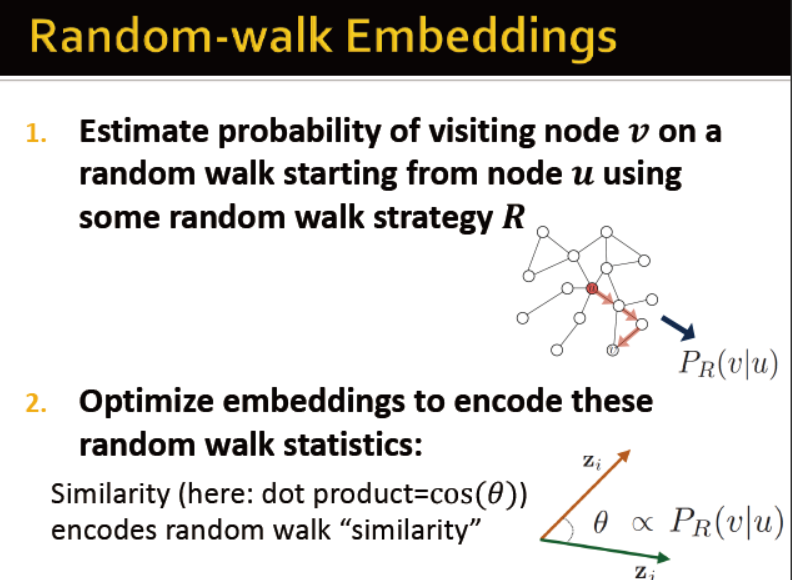
random walk的意义:
能充分表达网络的结构(邻居信息)
高效性,不需要考虑网络中的所有节点

非监督的学习,整体的过程类似于词向量,此处不加赘述







负样本抽样 窗口 + 负样本


演变为固定短长度的random walk

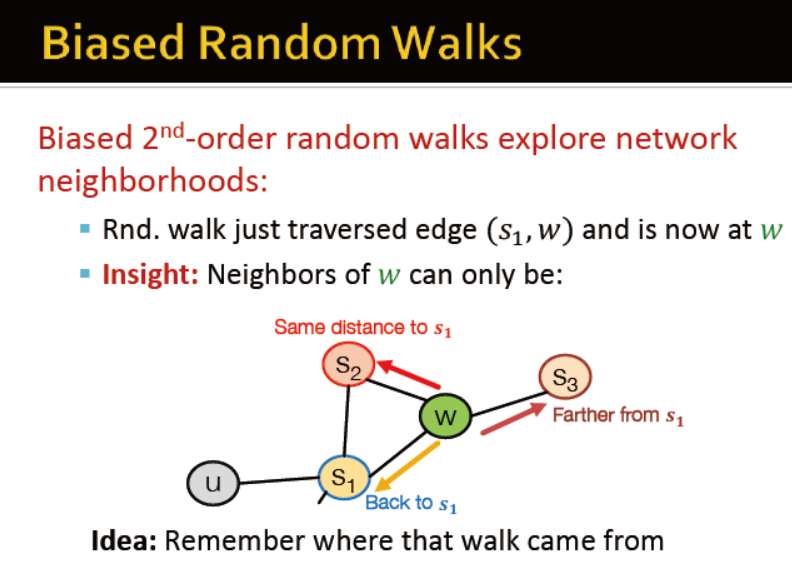
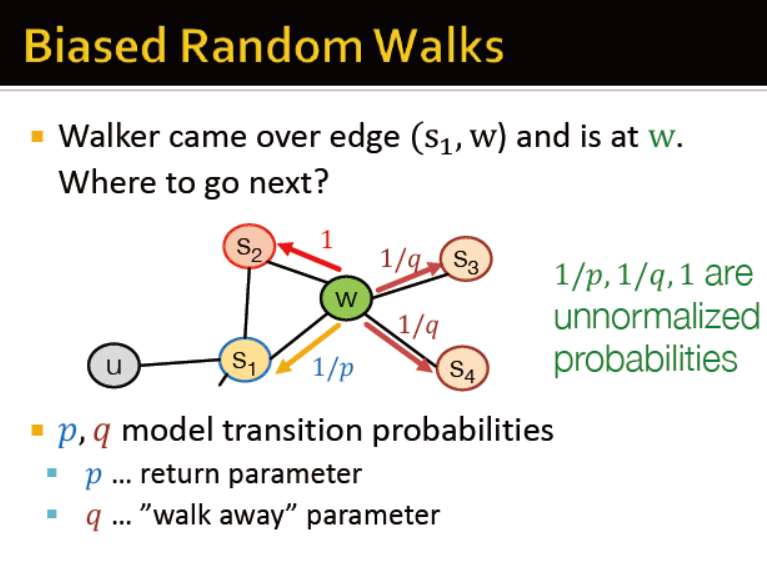
如何随机游走?

node2vec的概述
:
具有相似邻居的节点得到的向量相似

游走:广度,深度
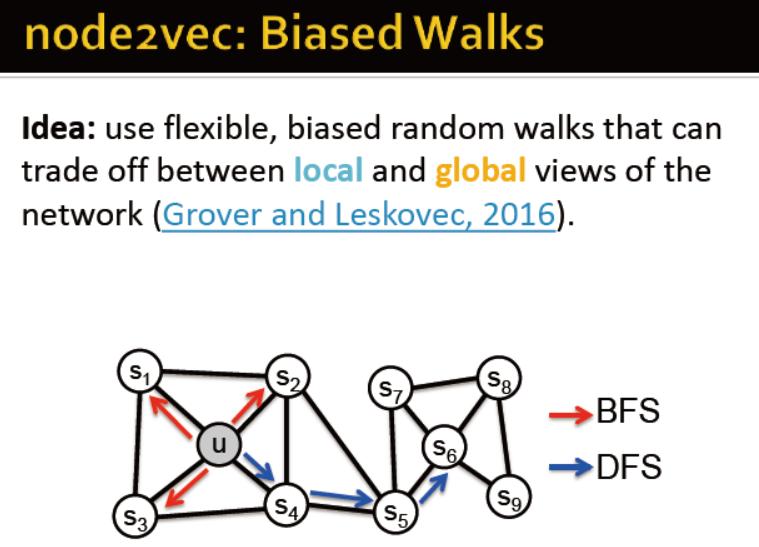
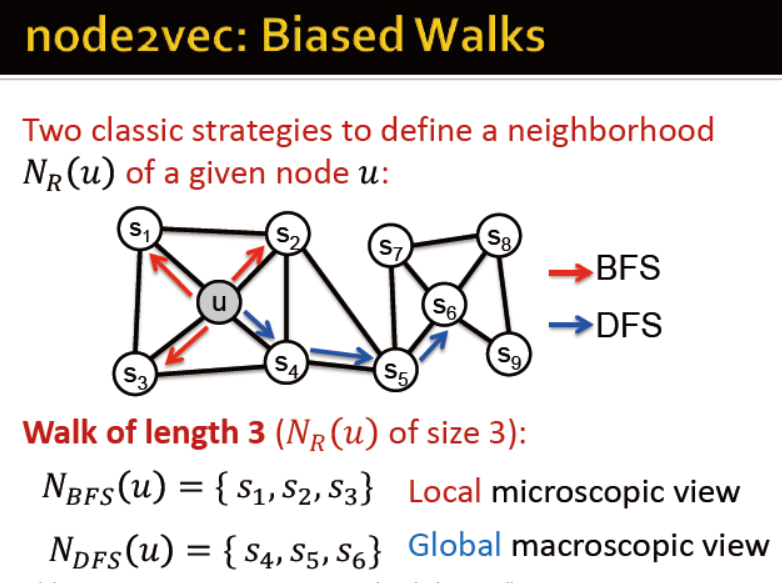
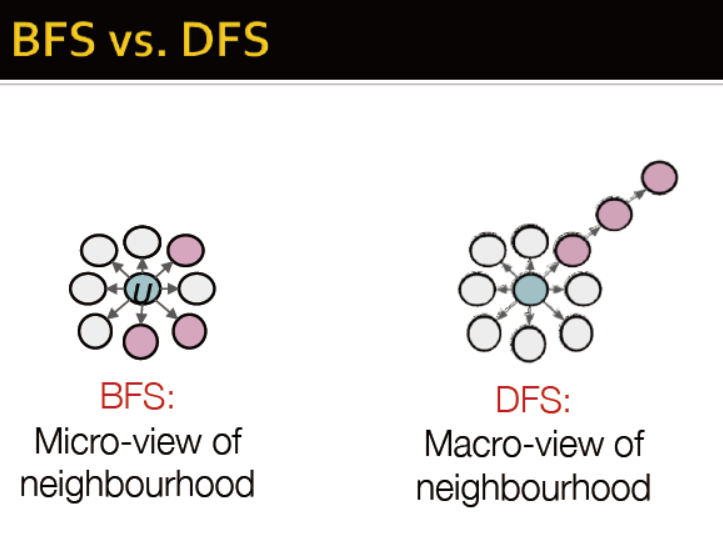

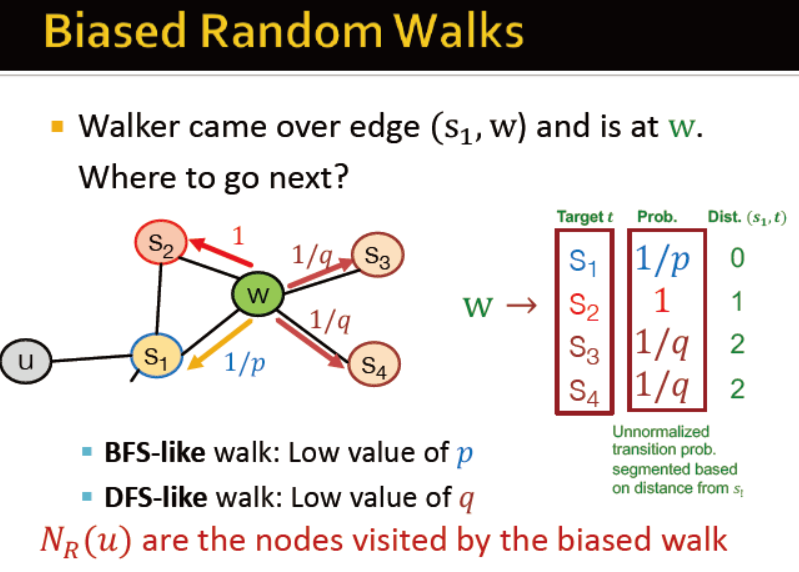
node2vec的步骤

embedding的使用:
聚类,社区发现
节点分类
关系预测

多关系数据模型的translating Embeddings
多关系模型,例如,知识图谱,边具有多类关系
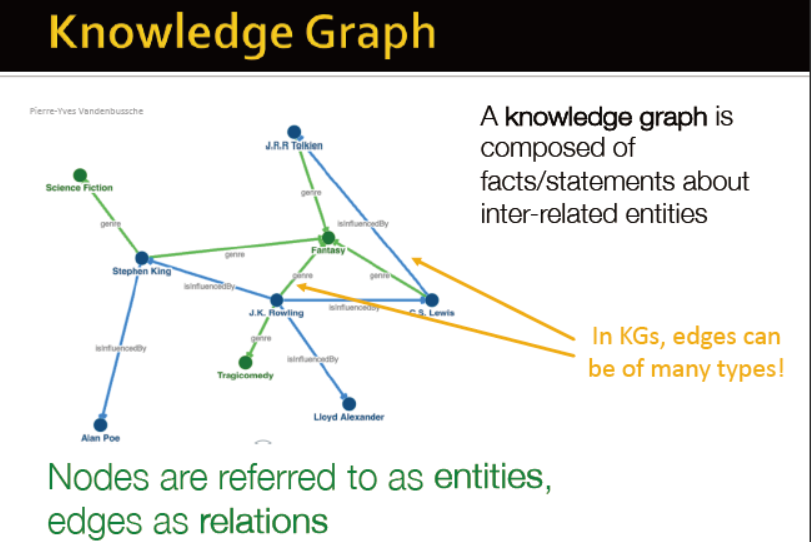
知识图谱填充→关系预测
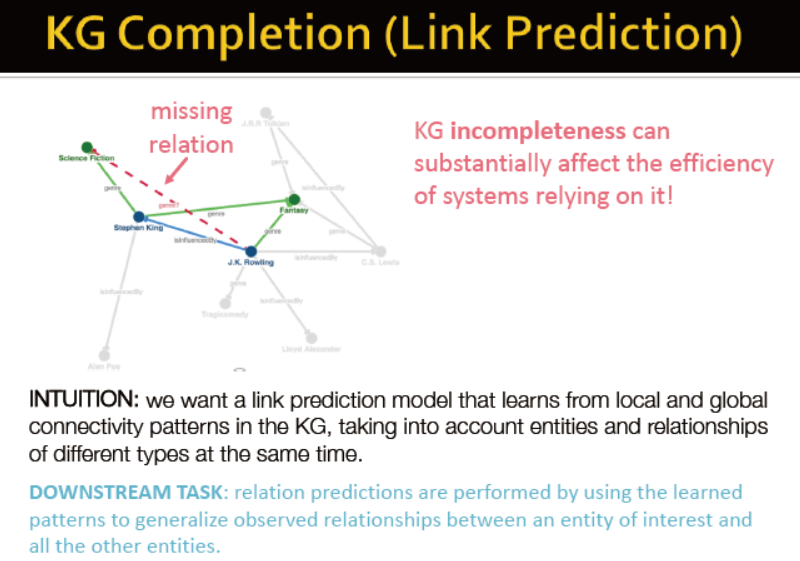
transE
三元组关系 (实体1,关系,实体2)(h,l,t)
首先,实体已被表示未向量
那么关系如何表示呢?若l也是一个向量,那么应满足 h+l≈t

transE算法

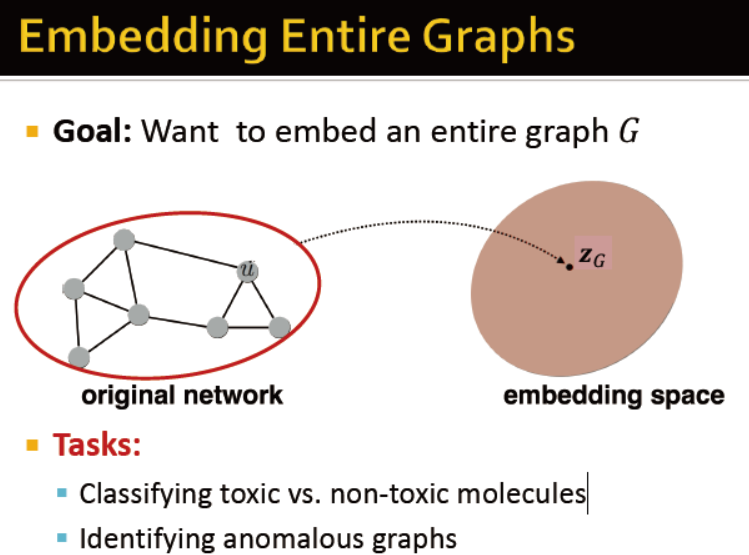
整图的Embedding

将整个图通过向量表示
用途:鉴别分子是否有毒;鉴别网络是否异常
方法1:
基于node2vec得到每个节点的向量,求和或平均得到整个网络的向量

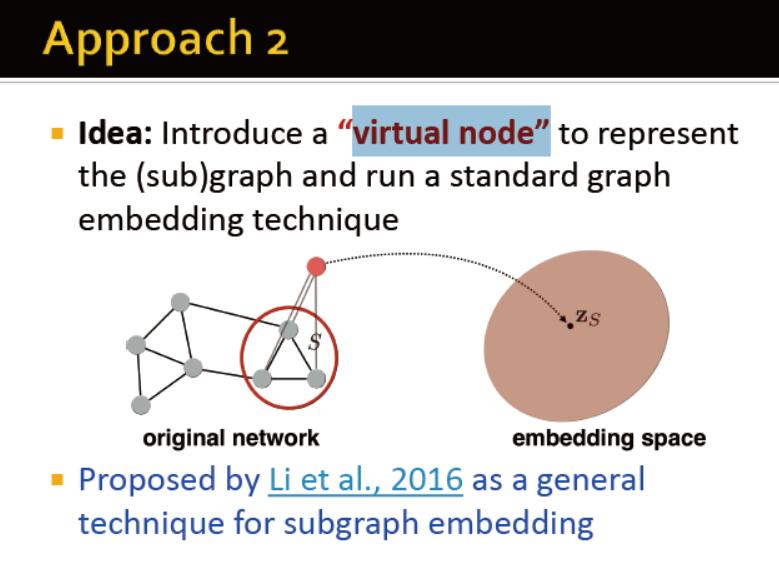
方法2:
引入虚拟节点来表征网络向量??
方法3:
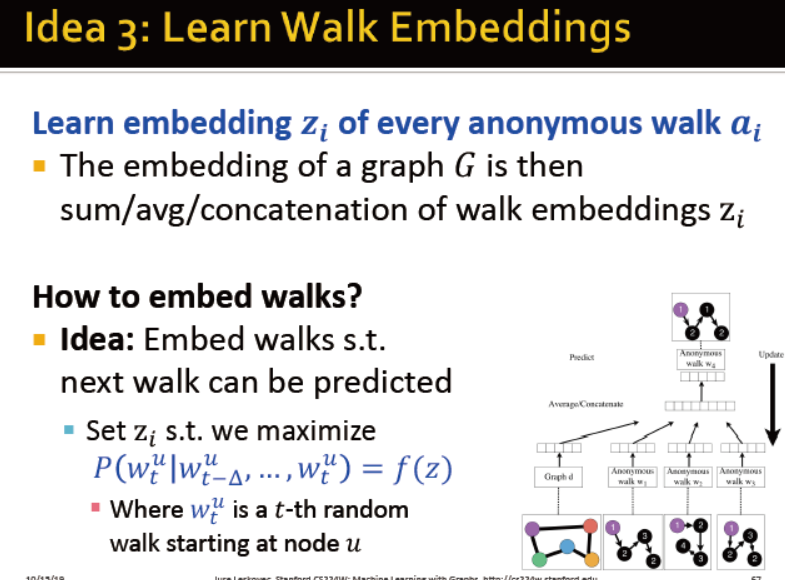
匿名游走??需要看论文才能了解
每个节点是匿名的
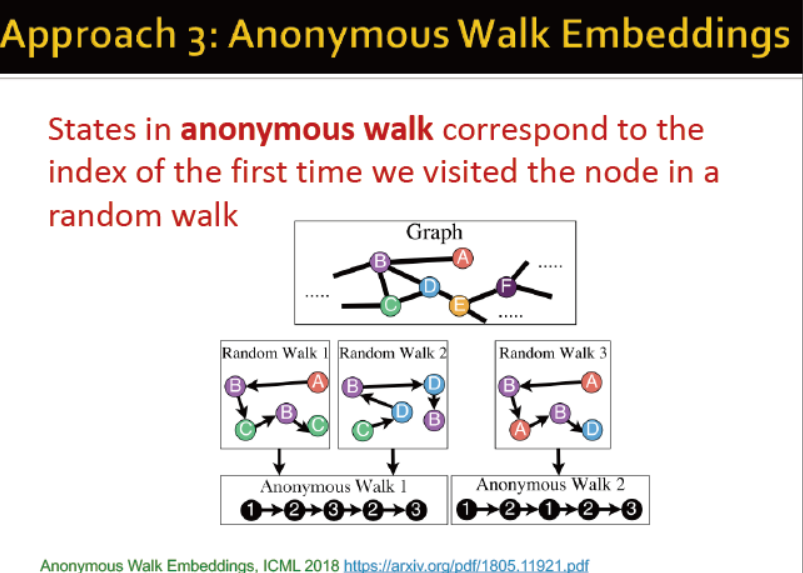
当游走长度为3时,共有5个匿名。游走长度增长时,匿名的类别数如图所示
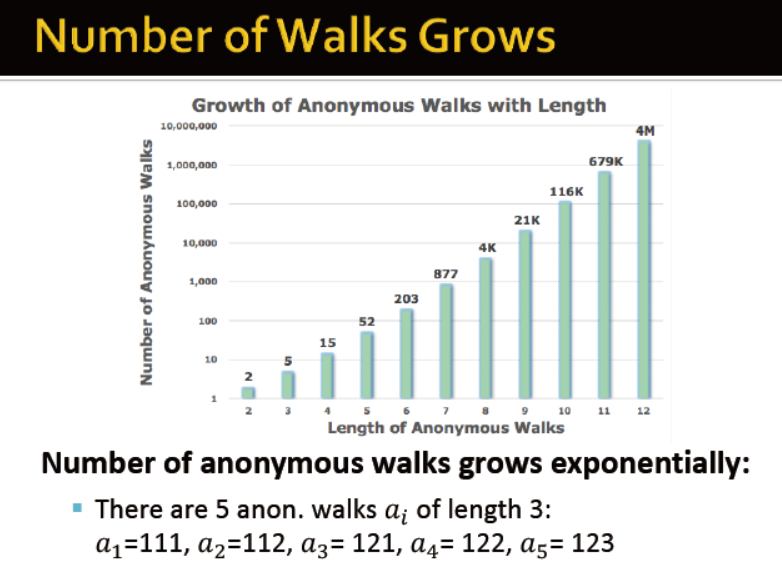
枚举步长为l的ai游走,并记录出现的次数
将图表示为这些游走的概率分布

计算图中所有的匿名游走可能是不可行的
抽样得到近似的分布
需要的random walk的次数如公式所示

学习每个匿名walk的Embedding,求和/平均/拼接后的结果即为图的表征