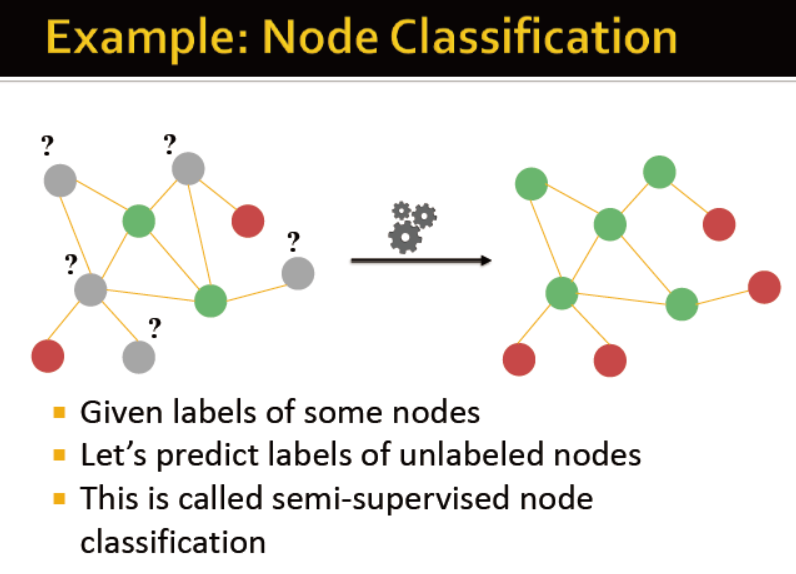
信息传播和节点分类
给定网络中一些节点的label,如何确定其他节点的label
例如,一个网络中一些节点是诈骗犯,一些节点是可信度高的人,那么如何判断其他节点?
半年监督节点分类
协作分类:collective classification
利用网络中的关联关系
接下来,今天会学3个技巧:
1)relational classification : 关系分类
2)iterative classification:迭代分类
3)belief propagation:置信传播
网络中的关联存在
导致相关关系的3类主要依赖类型:
1)趋同性
2)影响力
3)交互性?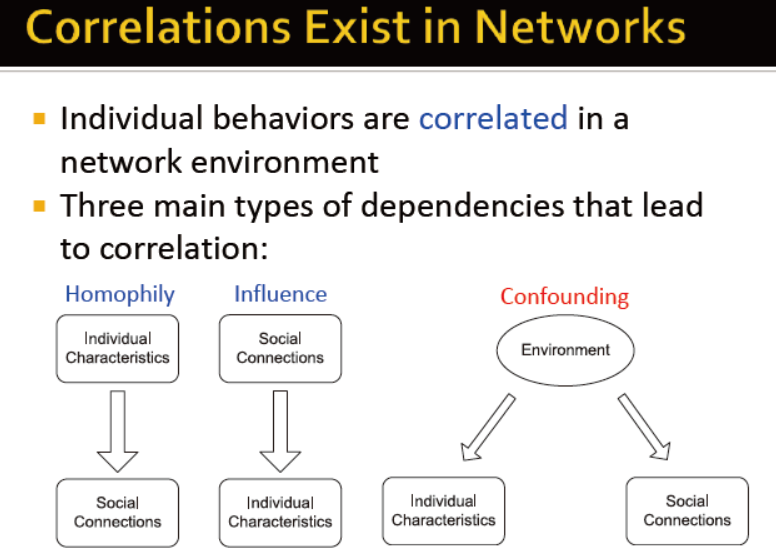


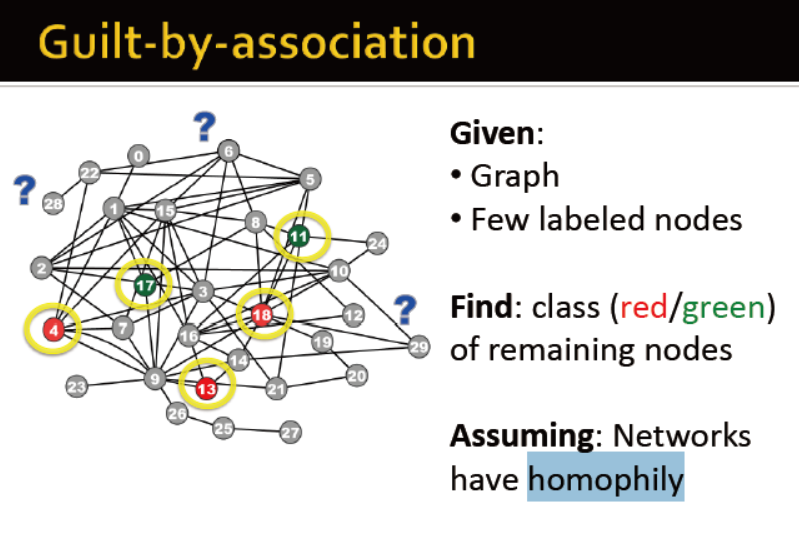
预测米黄色的节点的label
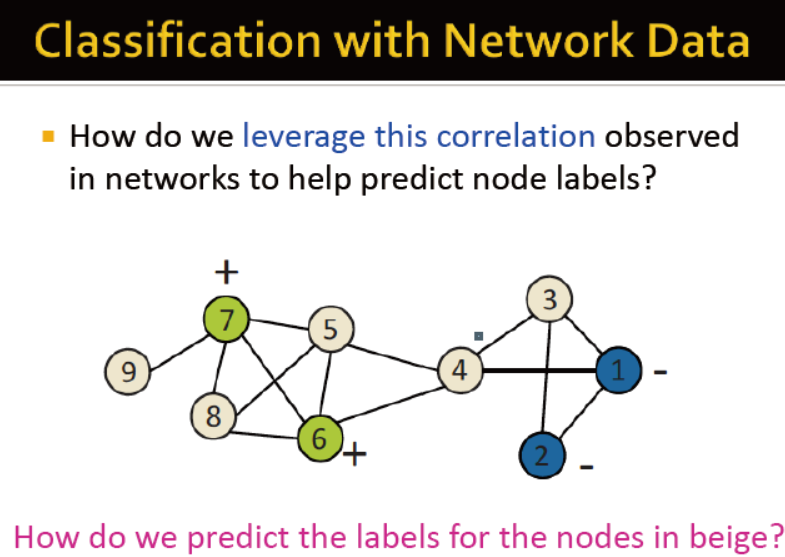
1)相似的节点通常会紧密关联或者直接相连
2)节点的label通常依赖于:节点的特征;节点的邻居;节点邻居的特征

假设网络具备趋同性,那么预测灰色节点的label
W:带权重的连接矩阵
Y:label +1,-1,0(待打标签)

使用节点间的相互关联关系进行分类

马尔科夫假设:节点i的label yi由他的邻居们Ni决定
分为三步:1)local classifier:分配初始的label 2)relational classifier:捕捉节点间的关联关系 3)collective inference:相关关系的传播

local classifier: 使用节点自身属性进行分类,不实用网络关联信息
relational classifier:学习一个分类器用于基于节点邻居的标签或属性给节点打标签
collective inference:迭代的将relational classifier应用于每一个节点,直到邻居间变得较为一致。网络结果会影响最终的判断

精确的推力是一个NP-hard问题,需要一些近似的推理。
每一节点有特征向量fi
找到节点对应的label的概率P(yi)
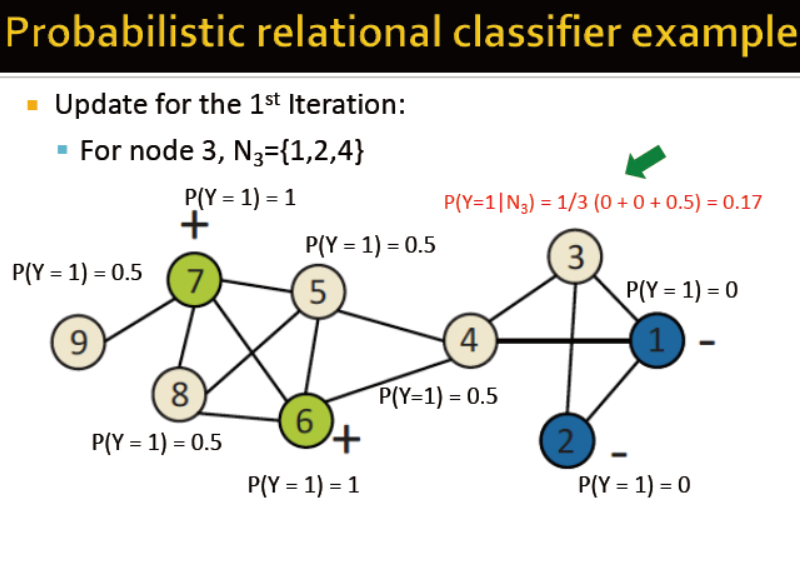
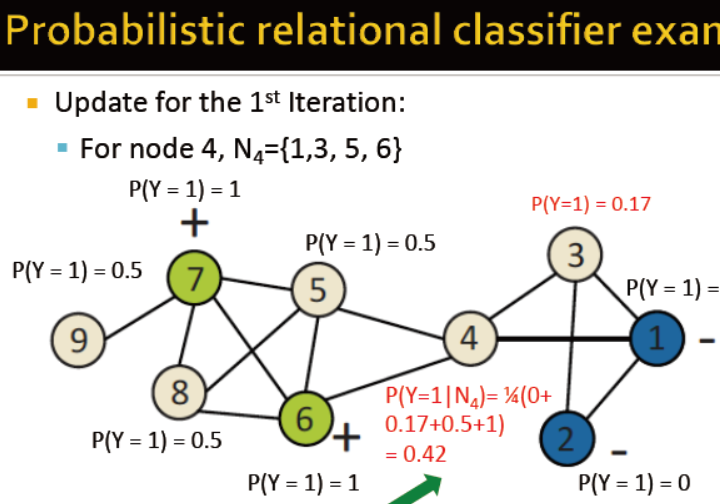
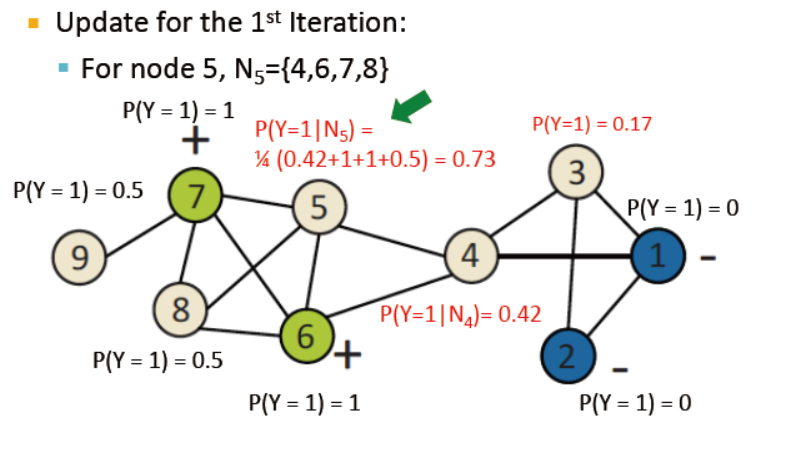
基于概率的关系分类
对于待labeled的节点,统一初始化标签Y
随机更新节点直到最大迭代次数达到

公式如下,但收敛并不能保证,并且模型未使用节点特征信息

例子如下,已打好标签的p=1或0,其余的统一设为0.5

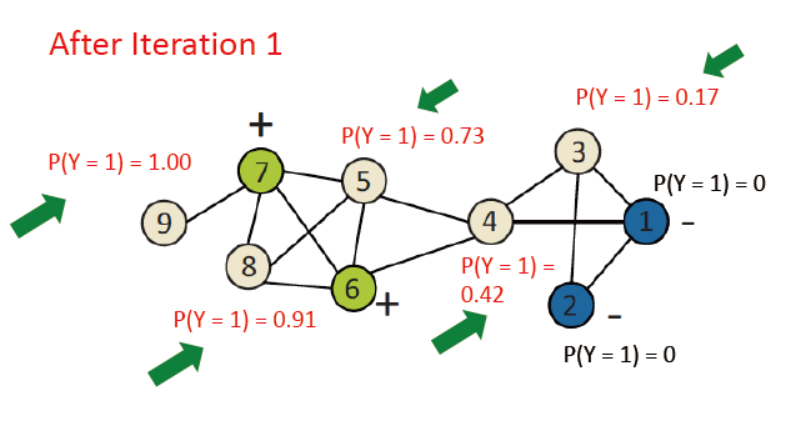
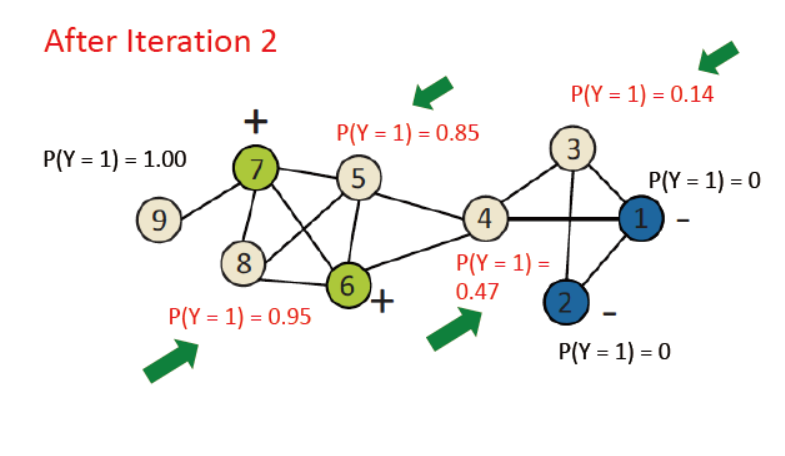
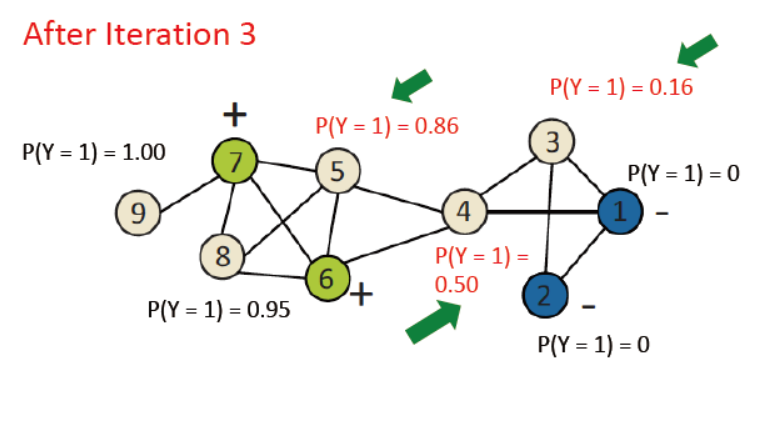

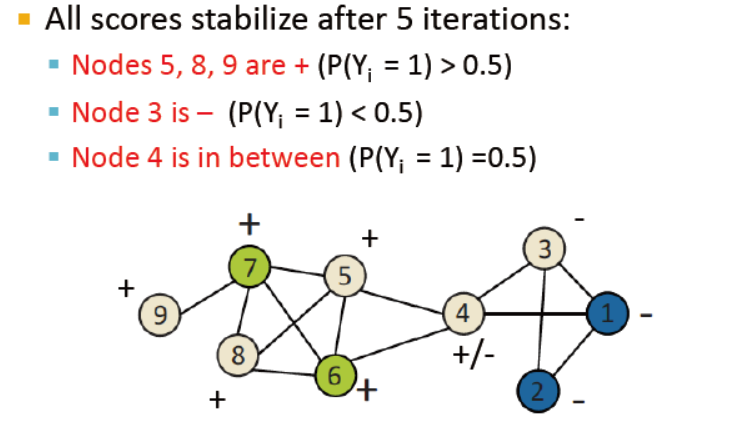
上述中,未使用节点的自身属性,那么如何使用他们呢?
iterative classification的重要思想:综合节点属性及邻居标签对节点进行分类

每个节点有一向量ai
训练一个分类器,输入为ai
节点的邻居数目是多样的,因此可以集合使用:count,mode,proportion,mean, exists等

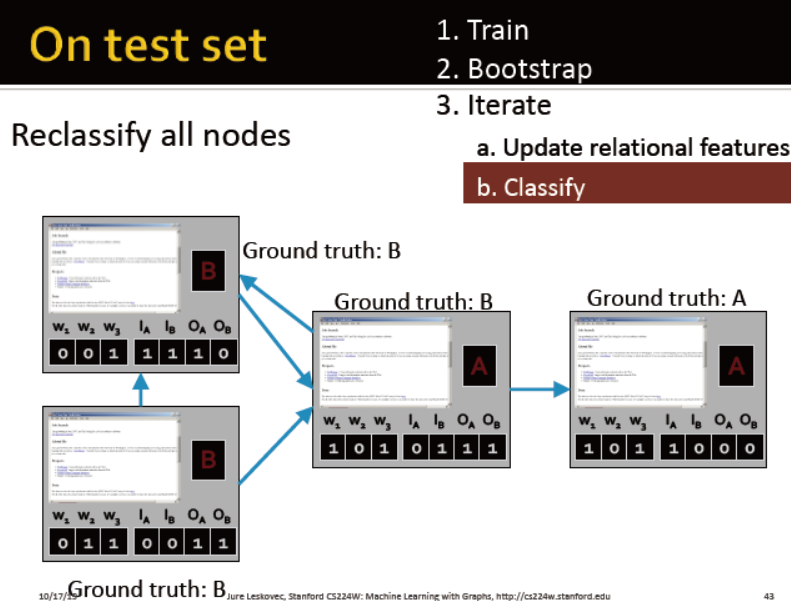
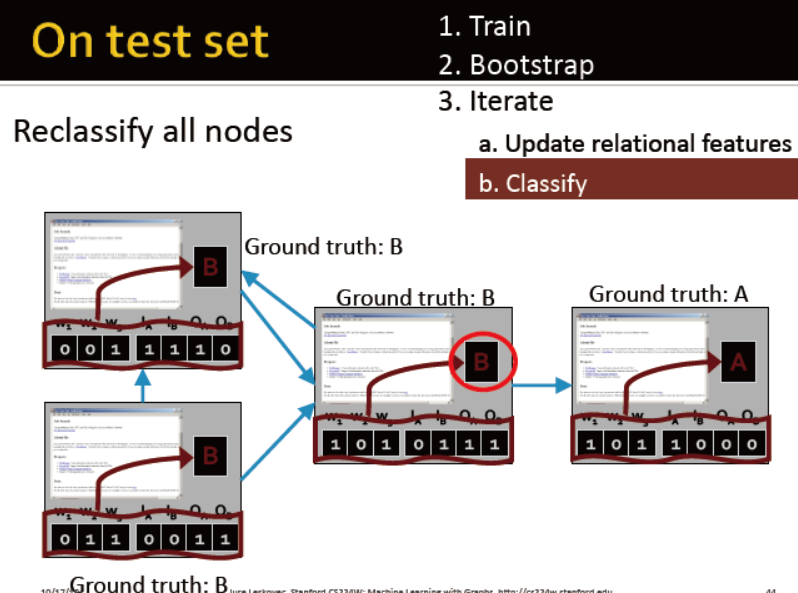
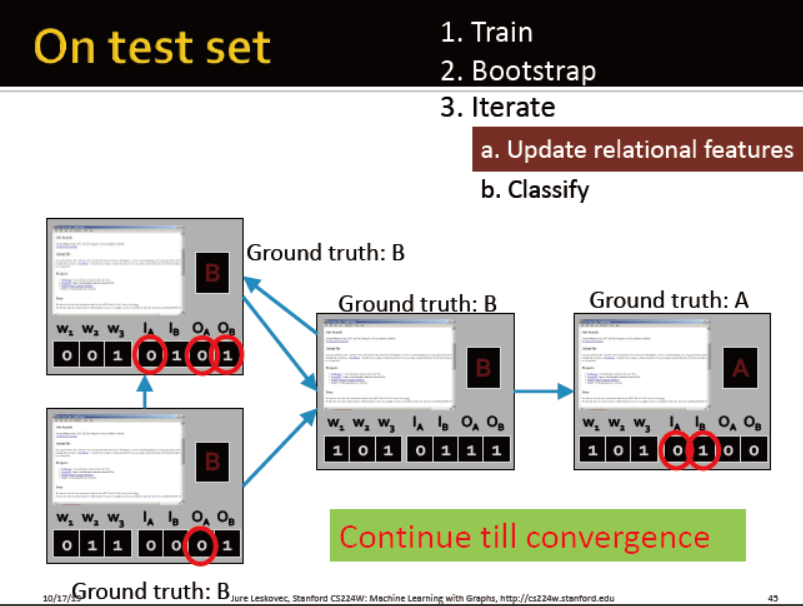
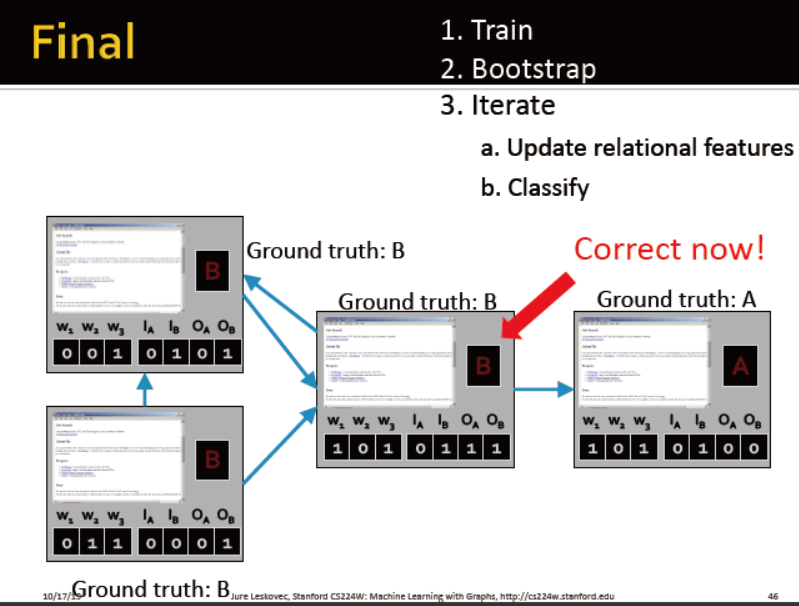
iterative classifiers的框架:
1. bootstrap phase:
节点特征向量的生成
训练分类器,分类器可使用SVM,KNN等
2. iterative phase:
每个节点重复:更新节点特征向量,更新分类器的预测结果yi
迭代直到标签稳定或最大次数完成
注意:不能保证完全收敛

例子:网页分类
特征向量:词袋的生成向量
baseline:训练一个基于特征向量的分类器
如何提高预测准确率?

每个节点有一个代表邻居标签的向量,区分出度与入度
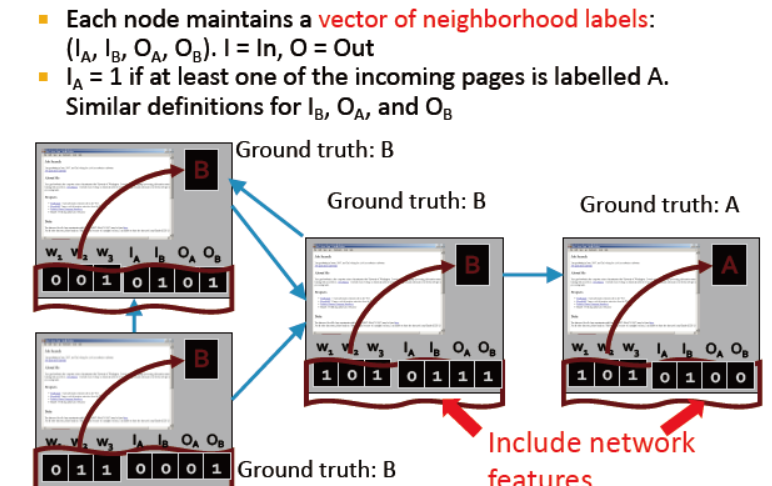
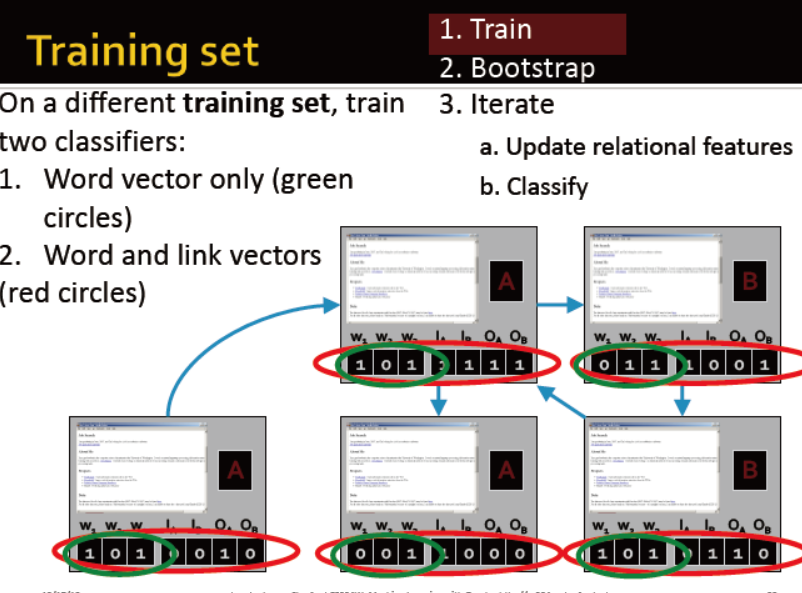
训练两个分类器:
一个分类器只考虑节点自身属性
一个分类器综合考虑自身属性与邻居标签
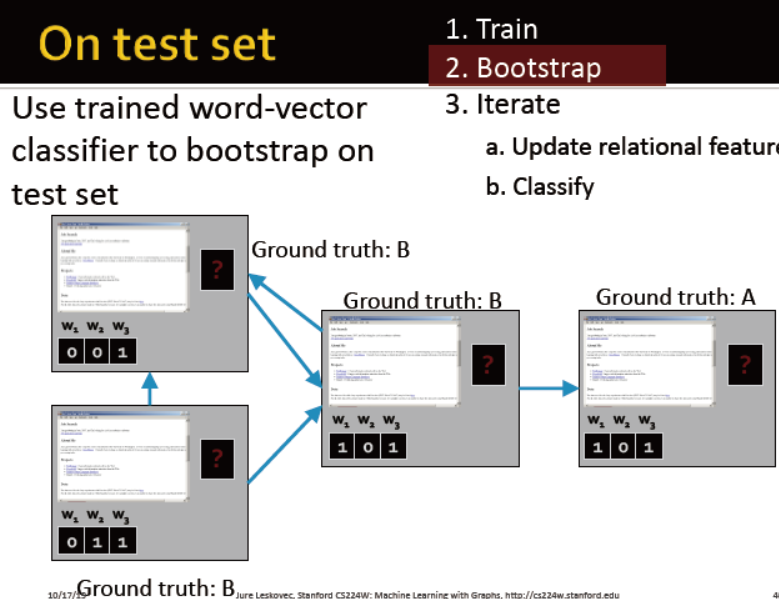
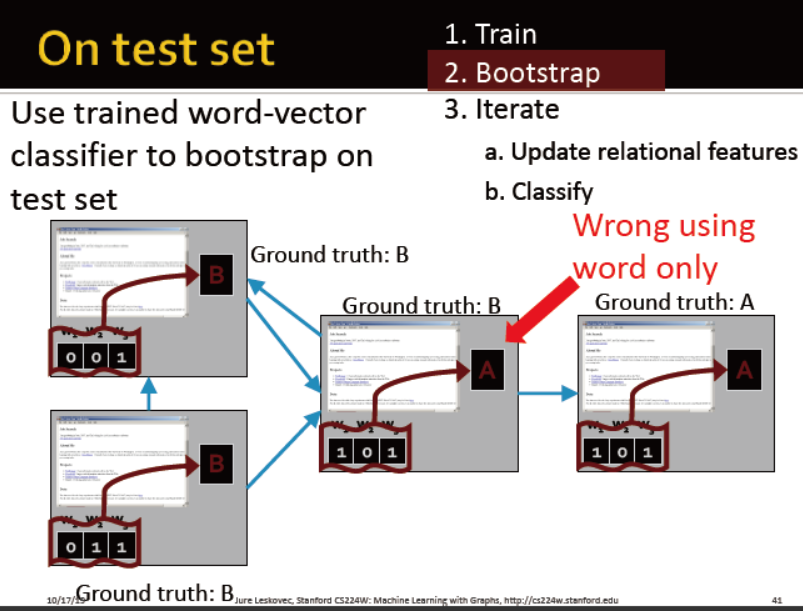
迭代。。。

应用: fake reviewer 或 review detection 虚假评论检测

行为分析:自有特征??(individual features),地理位置,登陆时间,session历史
语言分析:使用最高级,许多自我参考,拼写错误,协议性的词
但以上,有较容易仿造
难以仿造的是:关系结构(评论者,评论与商店的关系)

输入:排序后的二分图,节点:用户及商品 边:评分,-1到1
输出:给虚假评价的用户集
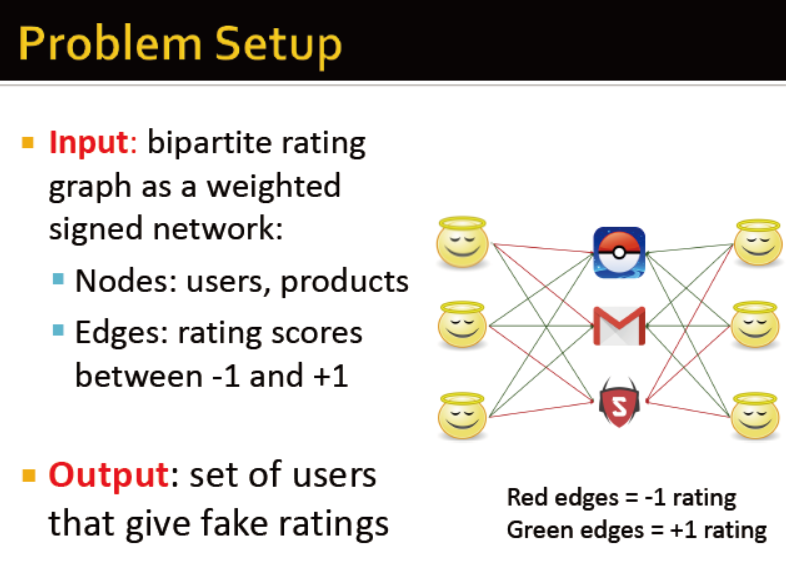
基础思想:用户,商品,评论有原有的评分
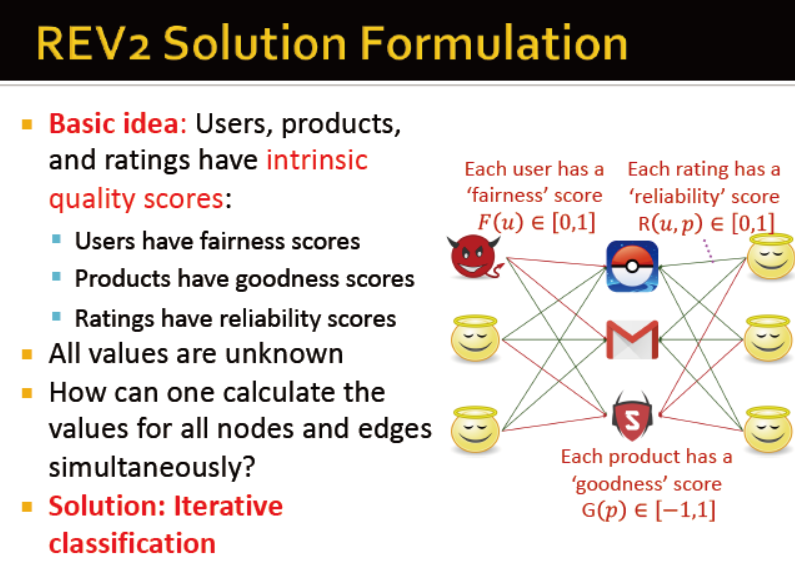
用户分值更新:
商品分值更新:

评论的可靠性更新:
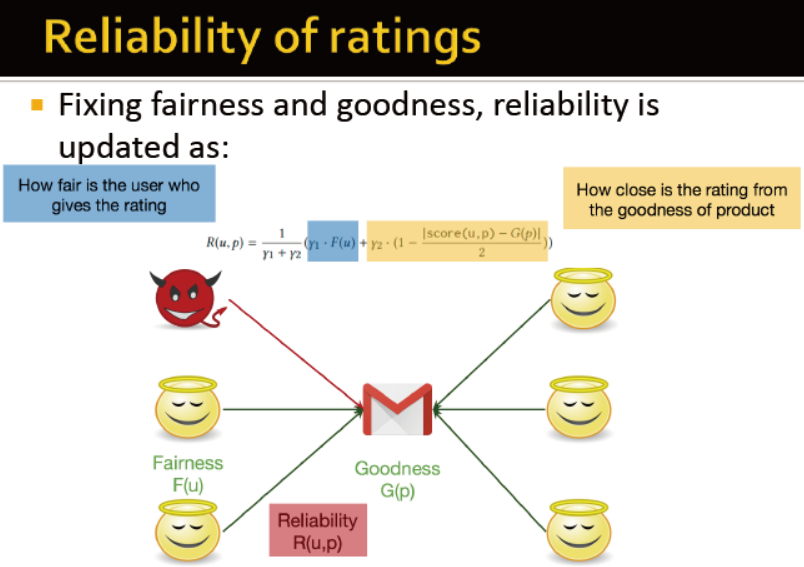
初始化,每个分数都为好与坏的最高分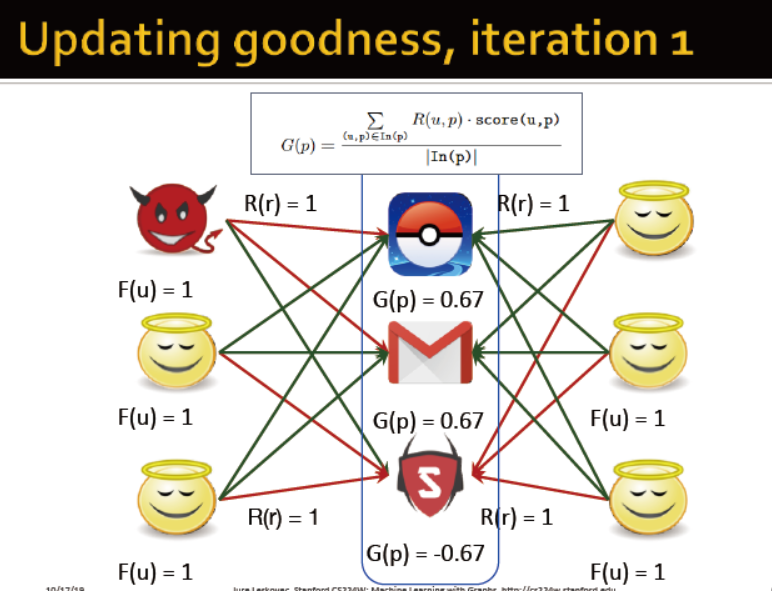
迭代1:更新商品的分数

更新评论的可靠度
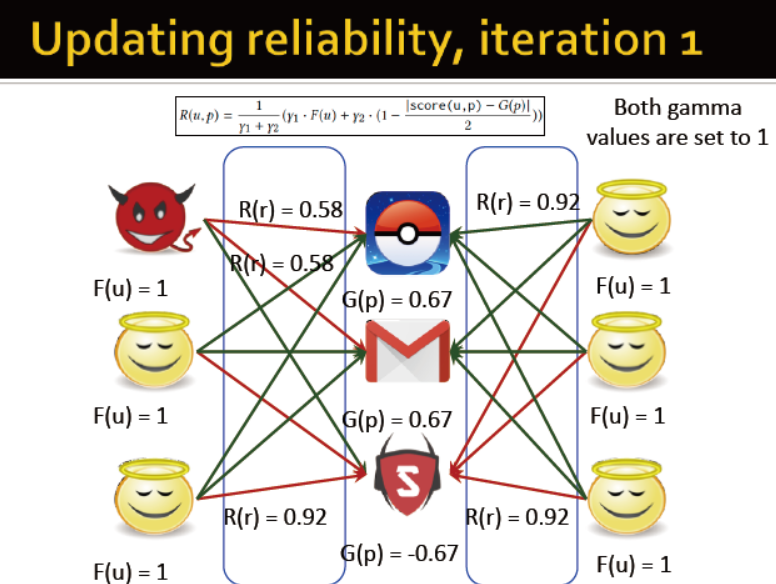
更新用户分数
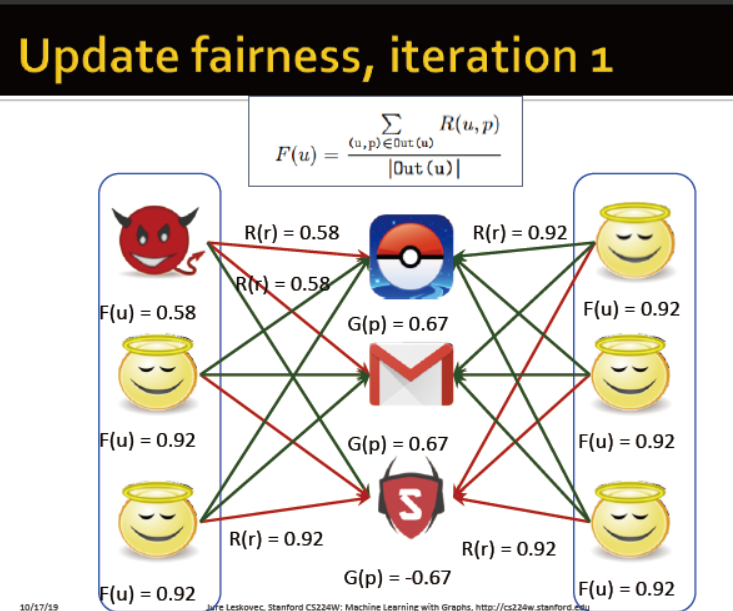
收敛后:
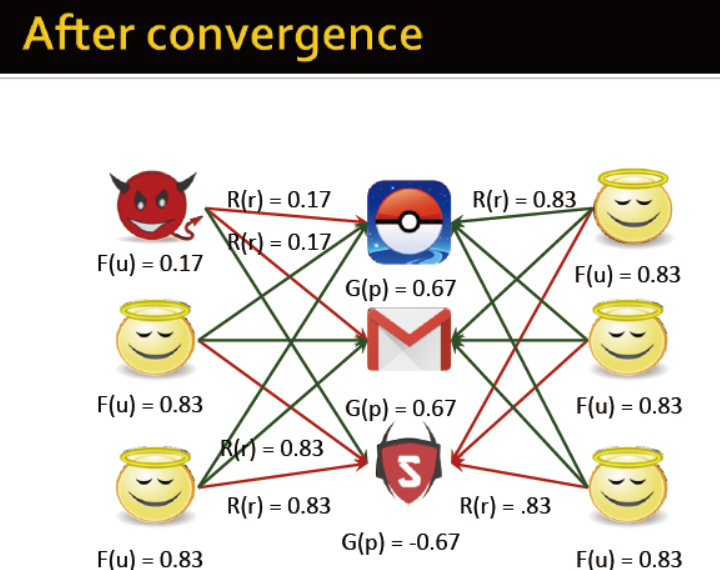
Rev2 能确保收敛 时间性能为编书的线性

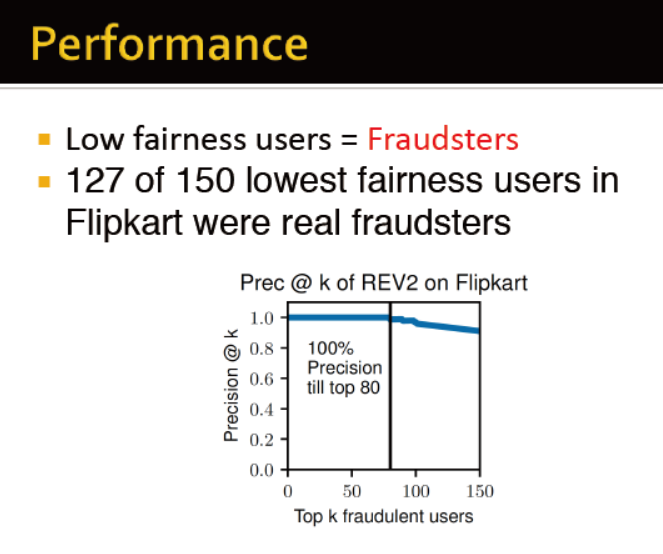
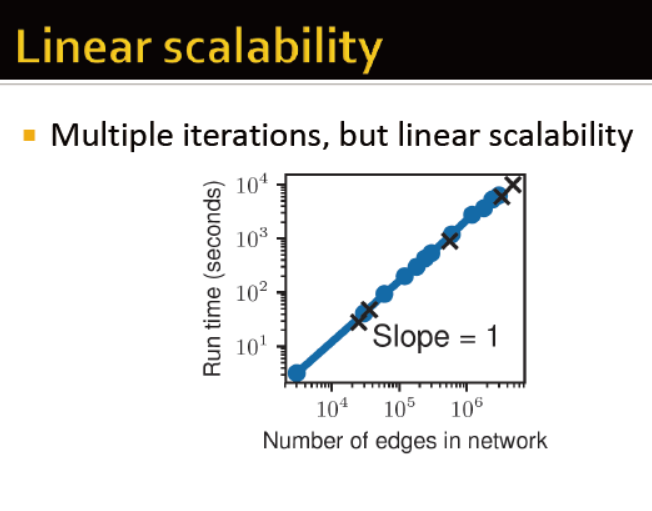
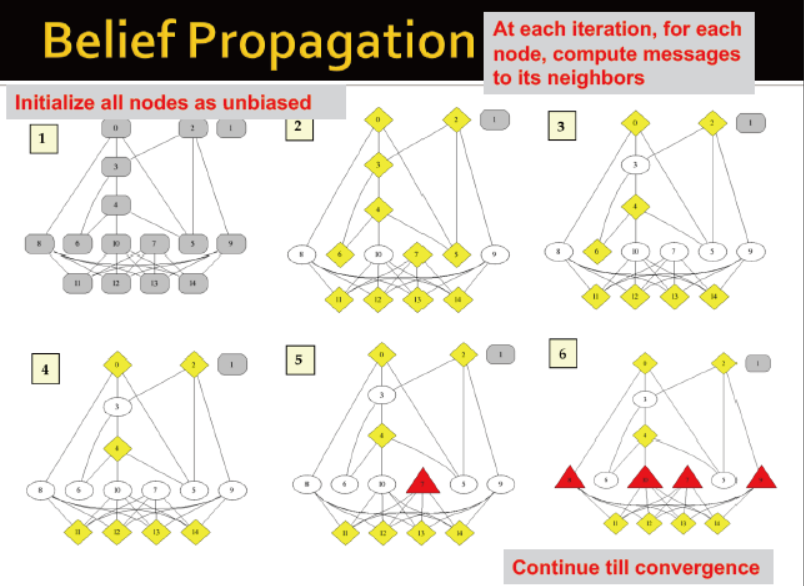
置信传播
是一个动态的问题
当达到一致后,计算最终的置信度

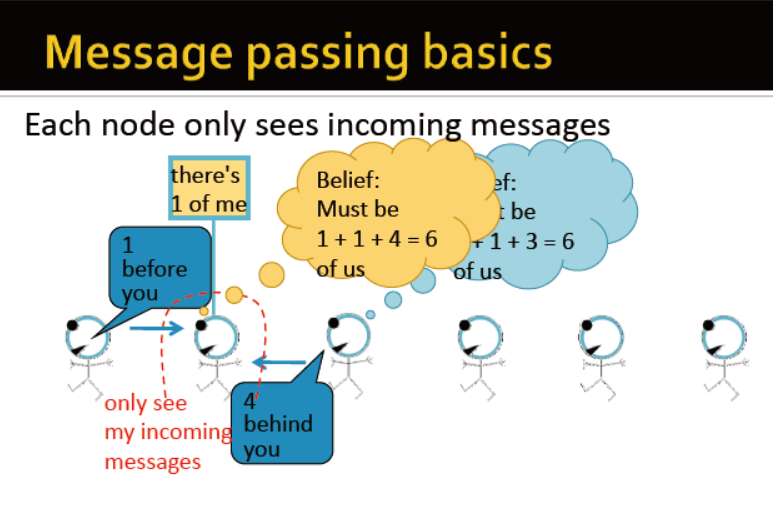
信息传输的基础
每个节点仅能给他的邻居传播信息
因此,每个节点仅能接收邻居的信息,更新并传播

第三个节点仅能接收前两个,后三个,以及自己的信息

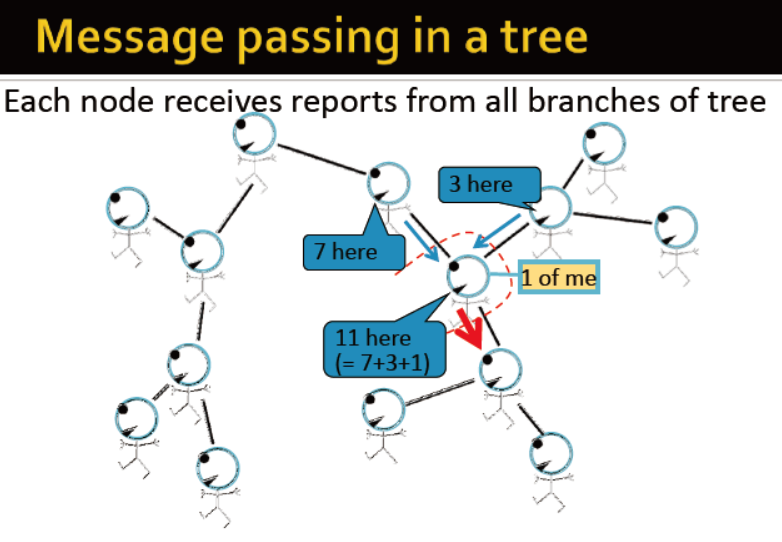
节点接收树中所有分支的信息

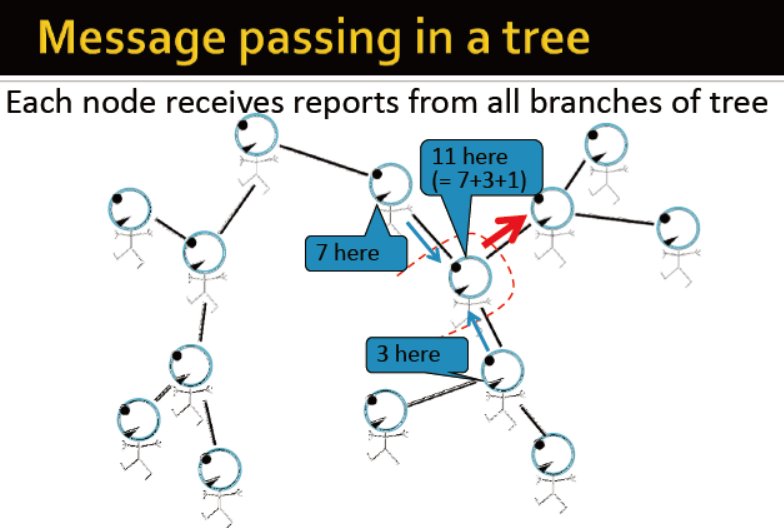

但是,当回路存在时,上述方法是会错误的

Loopy BP algorithm
i发送给j的消息,取决于i从邻居k收到的
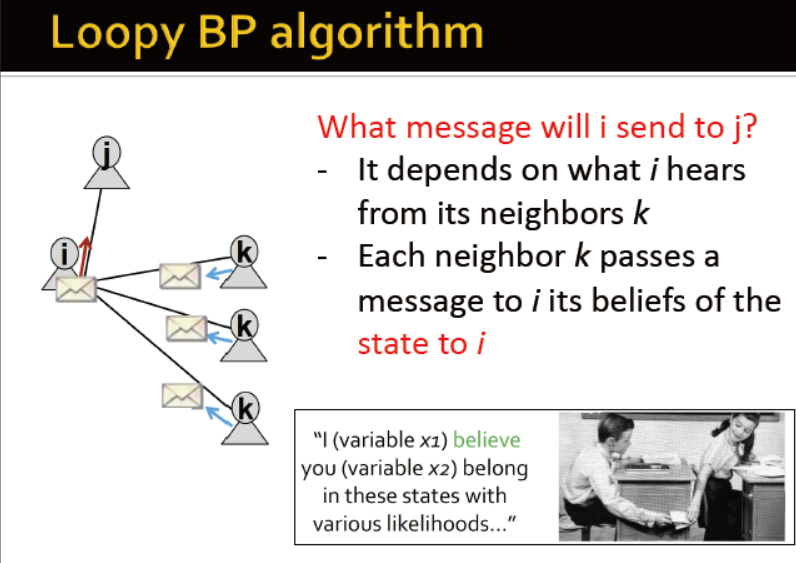
定义:
label-label potential matrix:两个相邻节点间的依赖关系矩阵。(i,j)表示当节点j的邻居i为状态为yi时处于状态yj的概率
prior belief:节点i在状态yi的概率
mij(yj):i对j在状态yj的估计
L:状态集

Loopy BP algorithm
初始化所有信息为1
对每个节点重复: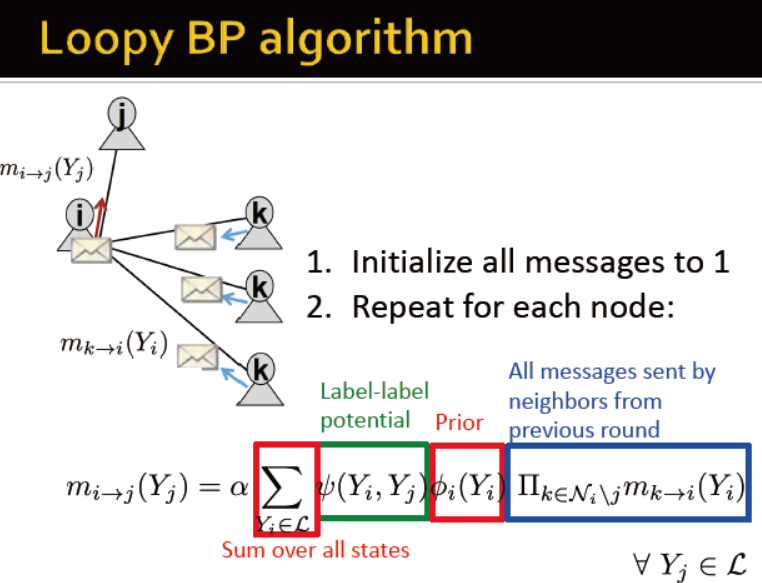
收敛后:

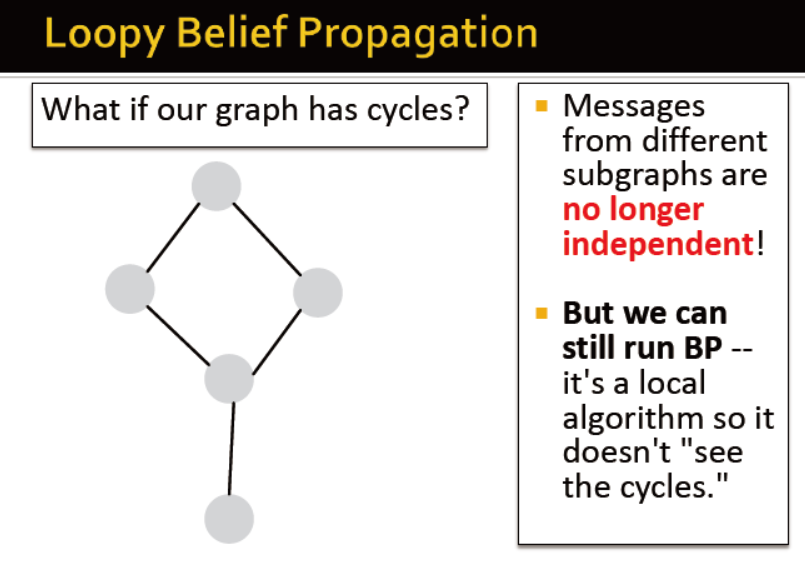
若闭环存在,信息不再独立
但是我们可以跑BP,一种局部的算法,闭环对其无影响

置信度传播应用:在线拍卖欺诈
考虑不充足的解决方案:仅考虑自身信息,如用户属性等

反馈机制
每个用户有一个信用分数,由他人打分
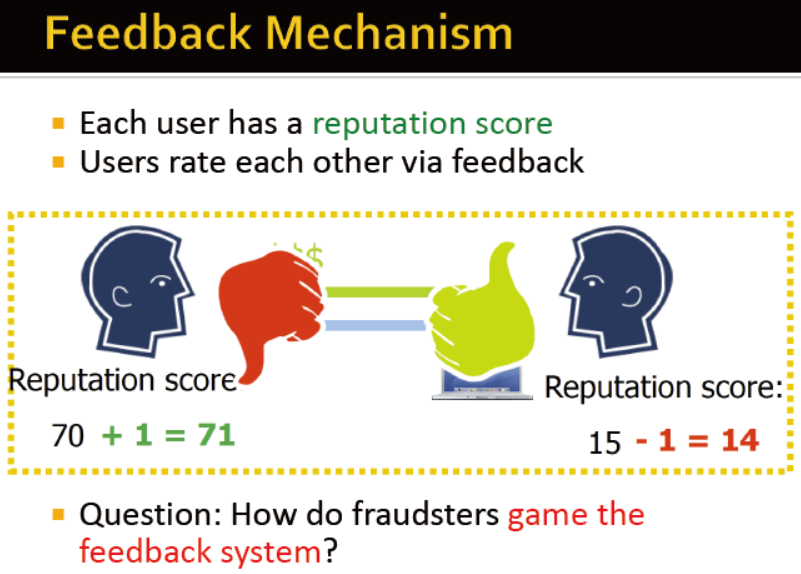
通常,欺诈用户不会相互打分
通常,构建近似的二分图:正常的,欺诈的
三类:绿色——诚信,黄色——看似正常,红色——欺诈
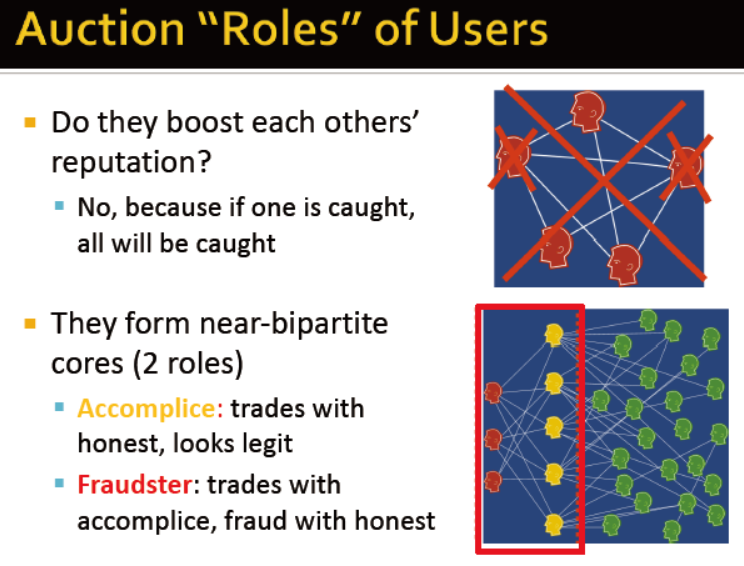
使用置信传播构建近似二分图