与Redis中的key-value散列做区分,我们称value的散列结构的键值对为field-value(域值对)。
12.1 简介
对于图12-1中的每个key,value指针都是指向redisObject的结构体,该结构体记录了存储结构的类型以及其编码方式等信息,
12.1.1 底层存储
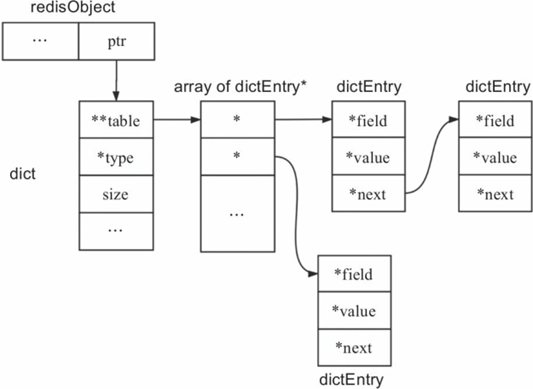
图12-1 key-value底层存储结构图
ziplist和hashtable 存储方式
散列指令对应的底层value的存储并不总是散列表,Redis提供了ziplist以及散列表(hashtable)两种方案进行存储。
当需要存储的key-value结构同时满足下面两个条件时,采用ziplist作为底层存储,否则需要转换为散列表存储。值得注意的是,ziplist的存储顺序与插入顺序一致,而散列表的存储则不一致。
1)key-value结构的所有键值对的字符串长度都小于hash-max-ziplist-value(默认值64),该值可以通过配置文件配置。
2)散列对象保存的键值对的个数(一个键值对记为1个)小于hash-max-ziplist-entries(默认值512),该值也可以通过配置文件配置。
当Redis采用ziplist底层存储时,结构图如图12-2所示。图中的f1、v1等字符串只是用于说明ziplist存储的基本结构,具体的存储方式是按照ziplist entry的方式存储,具体详情请见ziplist数据结构。
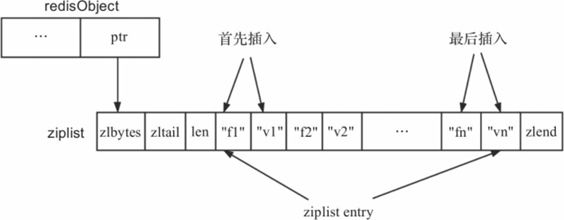
图12-2 ziplist作为散列命令底层存储结构图
当Redis采用散列表底层存储时,其结构如图12-3所示。此时就是一般的散列表。
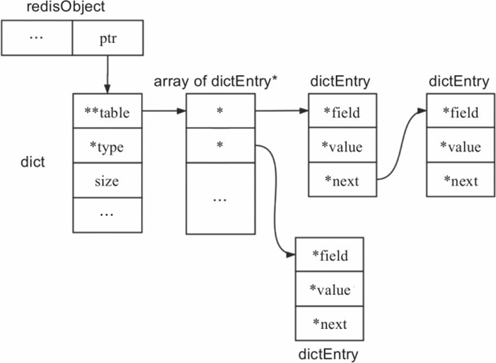
图12-3 散列表作为散列命令底层存储
12.1.2 底层存储转换
Redis散列存储有ziplist和散列表2种,有时需要从ziplist编码转换为散列表编码。
但是,后期不会从散列表编码转换为ziplist编码。
具体转换过程如下所示,核心思想是依次迭代原有数据,将其加入到新建的散列表中。
void hashTypeConvertZiplist(robj *o, int enc) {
serverAssert(o->encoding == OBJ_ENCODING_ZIPLIST);
if (enc == OBJ_ENCODING_ZIPLIST) {
/* Nothing to do... */
} else if (enc == OBJ_ENCODING_HT) {
hashTypeIterator *hi;
dict *dict;
int ret;
hi = hashTypeInitIterator(o); //初始化迭代器
dict = dictCreate(&hashDictType, NULL); //创建散列表
while (hashTypeNext(hi) != C_ERR) { //遍历所有数据,将其加入到散列表
sds key, value;
key = hashTypeCurrentObjectNewSds(hi,OBJ_HASH_KEY);
value = hashTypeCurrentObjectNewSds(hi,OBJ_HASH_VALUE);
ret = dictAdd(dict, key, value);
}
hashTypeReleaseIterator(hi);
zfree(o->ptr);
o->encoding = OBJ_ENCODING_HT;
o->ptr = dict;
} else {
serverPanic("Unknown hash encoding");
}
}
12.1.3 接口说明
为了使用方便,Redis提供了整合接口以供使用。例如:对于插入指令,Redis提供了hashTypeSet接口,该接口根据存储的编码方式分别调用ziplist的接口或者散列表的接口,本节对这类整合后的接口进行简单整理,具体源码实现此处就不再讲解。
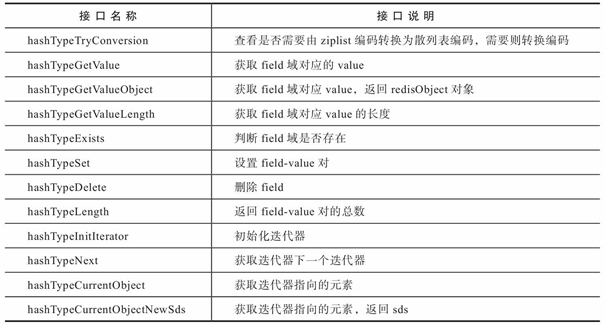
如表12-1所示,Redis提供了大量的整合接口,这类接口会根据散列存储的实际编码(ziplist和散列表)调用相关接口进行处理。后续的命令解析源码中,大量使用该类接口。这部分的源码详见src/t_hash.c文件。
表12-1 散列类型接口说明
需要先找出key对应的value。查找key的接口,如表12-2所示。
表12-2 key查找相关接口

12.2 设置命令
设置散列表中的field-value对,有3个命令:hset、hmset和hsetnx. 我们在插入新的field-value对时,需要判断是否需要编码转换,如果需要则直接转换编码。之后,我们只需调用ziplist或者散列表的上层接口实现数据插入。
格式:
hset key field value
hmset key field value [field value …]
hsetnx key field value
说明: 将key对应的散列表中的field域设置为value,如果key不存在则新建散列表。field域不存在则新建field域,将其值设置为value,并返回1。
如果field已经存在:
hset会覆盖旧值,返回0;hsetnx不进行任何操作,直接返回0;
hmset是hset的批量设置形式,成功返回ok。
设置类命令的源码实现:
hset、hsetnx对应的源码实现的入口函数分别是hsetCommand、hsetnxCommand。hmset的源码实现的入口也是hsetCommand。
三者实现的基本流程大致相同,首先判断key是否存在,不存在则直接创建;之后,根据field域是否存在,选择覆盖旧的数据或者直接返回。
hsetCommand的源码如下所示:
①查找key是否存在,不存在则直接新建;
②尝试是否需要将ziplist编码改为散列表编码;
③将需要写入的field、value依次写入;
④向客户端发送处理结果。
//查找key,不存在则新建
if ((o = hashTypeLookupWriteOrCreate(c,c->argv[1])) == NULL) return;
// 尝试转换底层编码
hashTypeTryConversion(o,c->argv,2,c->argc-1);
//依次写入field-value对
for (i = 2; i < c->argc; i += 2)
created += !hashTypeSet(o,c->argv[i]->ptr,c->argv[i+1]->ptr,HASH_SET_COPY);
hsetnxCommand的实现不同点在于hsetnxCommand会判断field是否已经存在,如果不存在则插入,存在则不进行任何操作,直接返回。
12.3 读取命令
获取field-value的信息。具体而言,命令有如下5类。
① hexists:判断field域是否存在。
② hget/hmget:获取单个field对应的value以及获取批量field对应的value。
③ hkeys/hvals/hgetall:获取全部的field、value或者field-value对。
④hlen:获取field的总个数。
⑤hscan:遍历hscan。
12.3.1 hexists命令
查看某个field是否存在,可以用于标识某个操作之前是否已经执行过。
格式:hexists key field
说明: 查看field是否存在,存在返回1,key不存在或者field不存在返回0。
示例:
> hset tom name tom1
1
> hexists tom name
1
源码解析:
hexists的源码处理函数为hexitsCommand,基本流程就是先获取key对应的散列表,之后判断field是否存在:
void hexistsCommand(client *c) {
robj *o;
if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.czero)) == NULL ||
checkType(c,o,OBJ_HASH)) return;
addReply(c, hashTypeExists(o,c->argv[2]->ptr) ? shared.cone : shared.czero);
}
12.3.2 hget/hmget命令
获取单个field或者多个field对应的value值。
格式:
hget key field
hmget key field [field …]
说明: 获取单个或者多个field域对应的value值,如果key不存在则返回nil,如果某个field不存在,则该field对应的位置返回nil。示例:
> hget tom name
tom1
> hmget tom name id
tom1
null
源码解析:
hget、hmget对应的处理函数分别为hgetCommand、hmgetCommand。二者相似,此处仅给出hmgetCommand的源码分析。
首先读取key对应的散列表,之后遍历所有field,返回对应的value或者nil。
void hmgetCommand(client *c) {
robj *o;
int i;
/* key不存在不要中断,返回nil. */
o = lookupKeyRead(c->db, c->argv[1]); //读取key对应的散列表
if (o != NULL && o->type != OBJ_HASH) {
addReply(c, shared.wrongtypeerr);
return;
}
addReplyArrayLen(c, c->argc-2);
//遍历所有field, 返回对应的value或者nil
for (i = 2; i < c->argc; i++) {
addHashFieldToReply(c, o, c->argv[i]->ptr);
}
}
12.3.3 hkeys/hvals/hgetall命
获取某个key下的所有field-value对的信息;
hkeys可以获取某个key下的所有field信息;
hvals可以获取每个field对应的value信息;
hgetall则可以获取所有的field-value对。
格式:
hkeys key
hvals key
hgetall key
提示 返回顺序没有固定顺序,取决于具体的底层编码
源码分析:
底层实现都是genericHgetallCommand函数,通过flags决定输出key或value还是二者都输出,具体源码如下,通过迭代器遍历散列表将所有field-value输出:
void genericHgetallCommand(client *c, int flags) {
robj *o;
hashTypeIterator *hi;
int length, count = 0;
//获取初始化迭代器
hi = hashTypeInitIterator(o);
//遍历散列表
while (hashTypeNext(hi) != C_ERR) {
if (flags & OBJ_HASH_KEY) {
addHashIteratorCursorToReply(c, hi, OBJ_HASH_KEY);
count++;
}
if (flags & OBJ_HASH_VALUE) {
addHashIteratorCursorToReply(c, hi, OBJ_HASH_VALUE);
count++;
}
}
}
12.3.4 hlen命令
hlen命令可以用于获取散列表中field的个数,主要用于数据统计。
格式:
hlen key
说明: 查key对应的散列表中field的个数,key不存在则返回0。
源码分析:
函数为hlenCommand,基本流程就是先获取key对应的散列表,之后通过hashTypeLength接口获取field个数,此处源码就不再展示。
/* Return the number of elements in a hash. */
unsigned long hashTypeLength(const robj *o) {
unsigned long length = ULONG_MAX;
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
length = ziplistLen(o->ptr) / 2;
} else if (o->encoding == OBJ_ENCODING_HT) {
length = dictSize((const dict*)o->ptr);
} else {
serverPanic("Unknown hash encoding");
}
return length;
}
12.3.5 hscan命令
遍历散列表中所有的field-value对,hscan命令是渐进式遍历(当底层存储为散列表时)。
格式:
hscan key cursor [MATCH pattern] [COUNT count]
说明:
用于遍历key指向的散列表。
cursor指向当前的位置,0代表新一轮的迭代,返回0代表本轮迭代结束;count是需要返回的field个数,默认值是10,当底层编码为ziplist时,该值无效,Redis会将
ziplist中所有field-value返回,当编码为散列表时,返回的元素个数不一定,可能大于,也可能小于或等于此值;
pattern是需要匹配的模式,这一步是读取完数据之后,发送数据之前执行的。
示例:
源码分析:
处理函数为hscanCommand,其功能是通过调用scanGeneric-Command实现的。函数的处理流程为:
1)当编码为散列表时,逐个遍历散列表的桶,得到其中的元素,当遍历到散列表末尾、达到count个元素或者达到最大迭代次数后终止;
2)当编码为ziplist时,输出所有元素;
3)对上一步的元素进行过滤,将结果发送给客户端。
void scanGenericCommand(client *c, robj *o, unsigned long cursor) {
/* Step 1: Parse options. */
....
/* Step 2: Iterate the collection.
/* Handle the case of a hash table. */
if (ht) { //编码为散列表的情况
void *privdata[2];
/* 如果对象是用ziplist,intset或不是哈希表的任何其他表示形式编码的,可以确定它也是由少量元素组成的。因此,为了避免进入状态,我们只需在一次调用中返回对象内部的所有内容,并将光标设置为零以表示迭代结束 */
long maxiterations = count*10;
/*将两个指针传递给回调:将向其添加新元素的列表,以及包含字典的对象,以与类型有关的方式获取更多数据。 */
privdata[0] = keys;
privdata[1] = o;
do {
cursor = dictScan(ht, cursor, scanCallback, NULL, privdata);
} while (cursor &&
maxiterations-- &&
listLength(keys) < (unsigned long)count);
} else if (o->type == OBJ_SET) {
int pos = 0;
int64_t ll;
while(intsetGet(o->ptr,pos++,&ll))
listAddNodeTail(keys,createStringObjectFromLongLong(ll));
cursor = 0;
} else if (o->type == OBJ_HASH || o->type == OBJ_ZSET) {
//编码为ziplist的情况
unsigned char *p = ziplistIndex(o->ptr,0);
unsigned char *vstr;
unsigned int vlen;
long long vll;
//遍历ziplist所有元素
while(p) {
ziplistGet(p,&vstr,&vlen,&vll);
listAddNodeTail(keys,
(vstr != NULL) ? createStringObject((char*)vstr,vlen) :
createStringObjectFromLongLong(vll));
p = ziplistNext(o->ptr,p);
}
cursor = 0;
}
/* Step 3: Filter elements. */
...
/* Step 4: Reply to the client. */
...
cleanup:
listSetFreeMethod(keys,decrRefCountVoid);
listRelease(keys);
}
12.4 删除命令
hdel直接调用ziplist或者散列表的接口将数据删除。
格式:
hdel key field [field …]
说明: 将key对应的散列表中的field删除,key为空时返回0,key不为空时返回成功删除的field个数。
提示 当散列表中field全部被删除时,key也会被删除。
源码分析:
hdel命令对应的处理函数为hdelCommand,基本的处理逻辑直接调用底层提供的接口进行数据删除,源码实现如下:
void hdelCommand(client *c) {
robj *o;
int j, deleted = 0, keyremoved = 0;
//查找key并检查其类型
if ((o = lookupKeyWriteOrReply(c,c->argv[1],shared.czero)) == NULL ||
checkType(c,o,OBJ_HASH)) return;
for (j = 2; j < c->argc; j++) { //依次删除field-value对
if (hashTypeDelete(o,c->argv[j]->ptr)) {
deleted++;
if (hashTypeLength(o) == 0) { //散列表已经为空,删除key
dbDelete(c->db,c->argv[1]);
keyremoved = 1;
break;
}
}
}
}
12.5 自增命令
当散列表field-value中的field为整数或者浮点型的数据时,对其中的value进行加法操作(减法可以视为加上一个负数),Redis提供了hincrby、hincrbyfloat两个命令。
格式:
hincrby key field increment
hincrbyfloat key field increment
说明:
将field对应的value增加increment,当为浮点型数据时使用hincrbyfloat。如果key不存在则直接新建key,field不存在则直接新建field,设置其值为0。如果hincrby增加后数值越界,则返回错误,不进行操作。hincrbyfloat不进行越界判断。如果field对应的value类型不是数值,则直接返回错误。命令返回增加后的新值。
提示 整数使用long long,浮点型使用long double。原来的值和增加的值都是整型时,才可以使用hincrby。
源码分析:
hincybyCommand源码如下:首先获取key对应的散列表,之后从散列表中读取原有的field对应的值,然后判断增加之后是否越界,最后将增加后的值写入field域。
void hincrbyCommand(client *c) {
long long value, incr, oldvalue; robj *o; sds new;
unsigned char *vstr; unsigned int vlen;
if (getLongLongFromObjectOrReply(c,c->argv[3],&incr,NULL) != C_OK) return;
//读取key对应的value
if ((o = hashTypeLookupWriteOrCreate(c,c->argv[1])) == NULL) return;
//获取field域中原来的值
if (hashTypeGetValue(o,c->argv[2]->ptr,&vstr,&vlen,&value) == C_OK) {
//判断value类型
} /* Else hashTypeGetValue() already stored it into &value */
} else {
value = 0;
}
oldvalue = value;
//判断是否越界
if ((incr < 0 && oldvalue < 0 && incr < (LLONG_MIN-oldvalue)) ||
(incr > 0 && oldvalue > 0 && incr > (LLONG_MAX-oldvalue))) {
addReplyError(c,"increment or decrement would overflow");
return;
}
value += incr;
new = sdsfromlonglong(value);
//设置新值
hashTypeSet(o,c->argv[2]->ptr,new,HASH_SET_TAKE_VALUE);
}
hincrbyfloat对应的源码基本与hincrby相似,不同点在于,hincryfloat是对浮点型数据进行操作,也没有对数值越界进行处理。
12.6 本章小结
Redis对外提供的散列相关命令的底层实现。
Redis对散列结构的存储方式,即ziplist或者散列表,当field-value长度较短并且field-value的个数较少时,Redis采用ziplist用于存储,否则使用散列表。
Redis为使用方便,整合这两种结构后对外提供的统一接口。
Redis是如何利用上述整合接口实现散列相关命令的。