1 RNN介绍
(1)一对多,多对一,多对多的任务
传统的神经网络只能处理一对一的任务,而RNN可以处理一对多,多对一,多对多的任务:

其中,一些典型的应用如下:
Image Captioning:image -> sequence of words (one to many)
Sentiment Classification:sequence of words -> sentiment (many to one)
Machine Translation:seq of words -> seq of words (many to many)
Video classification on frame level : many to many
(注意上图中两种many2many是不同的,左图是一个seg2seg的模型,即输出是不定长的,右图则表示在每次输入后都对应产生一个输出,输出是定长的)
(2)RNN
在时间t处,RNN模型可以表示如下:

每个时刻函数f接收上一时刻的隐藏态ht-1和当前时刻的输入xt,产生当前时刻的隐藏态ht。其中函数f是关于参数w的函数,在每个时刻参数w和函数f都应该是相同的。输出y可以由当前的隐藏态产生。
一个RNN模型的简单例子如下:
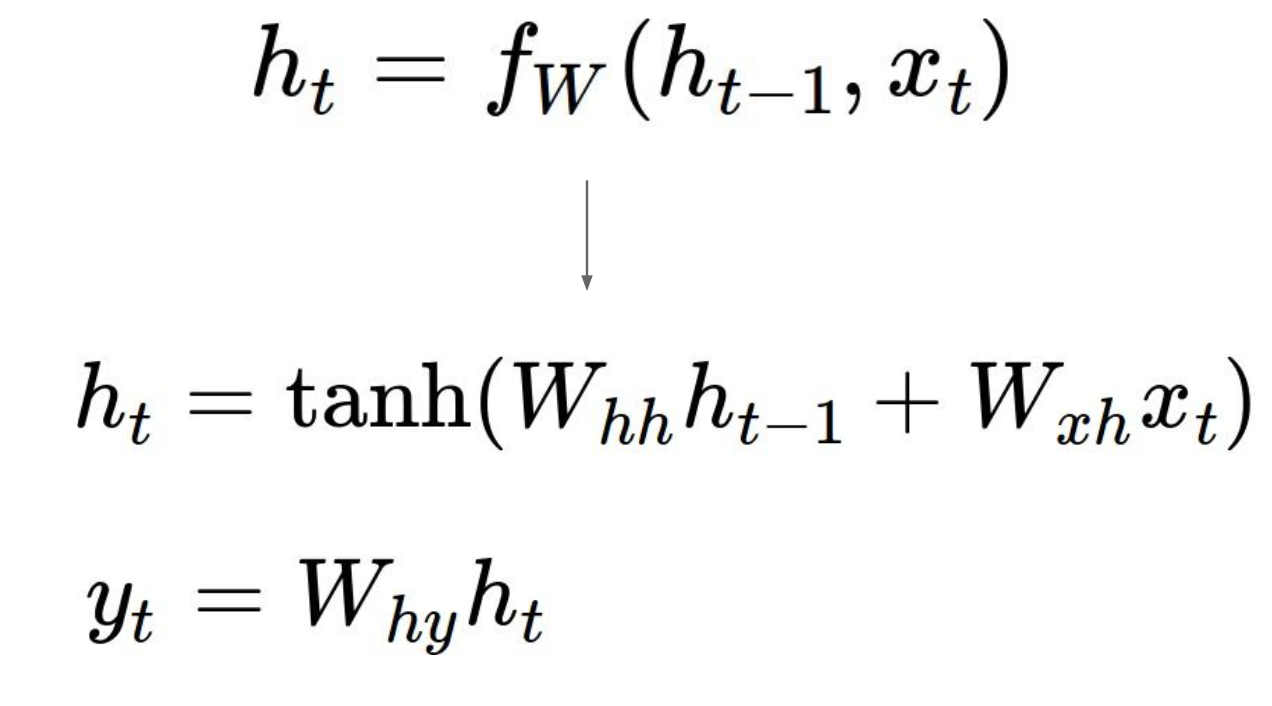
(3)几种RNN计算图
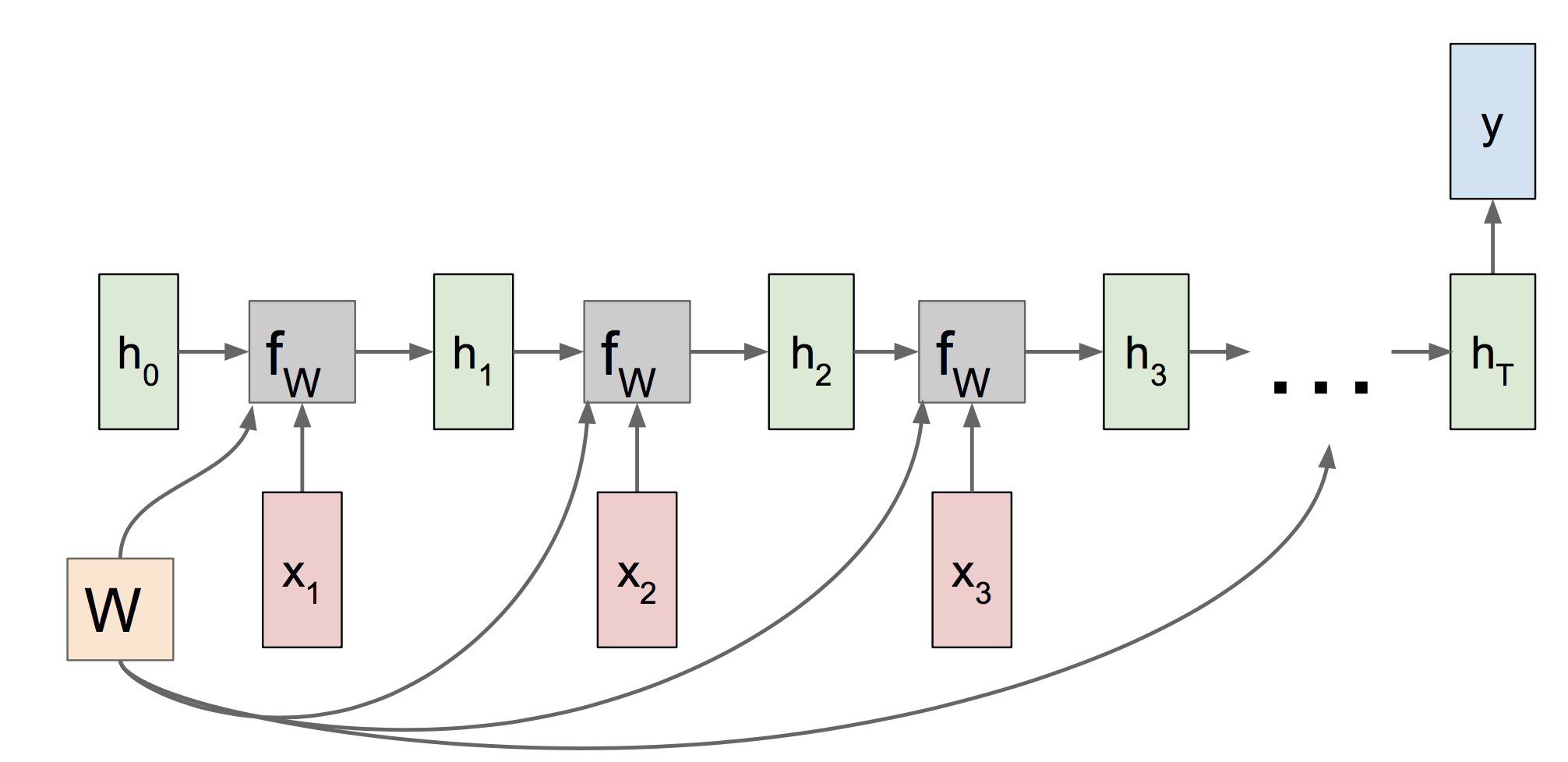
首先是输出定长的many2many计算图:

其中我们可以看到参数W在各个时刻是共享的,因此当反向传播时,W的梯度应该是各个时刻传过来的梯度之和。
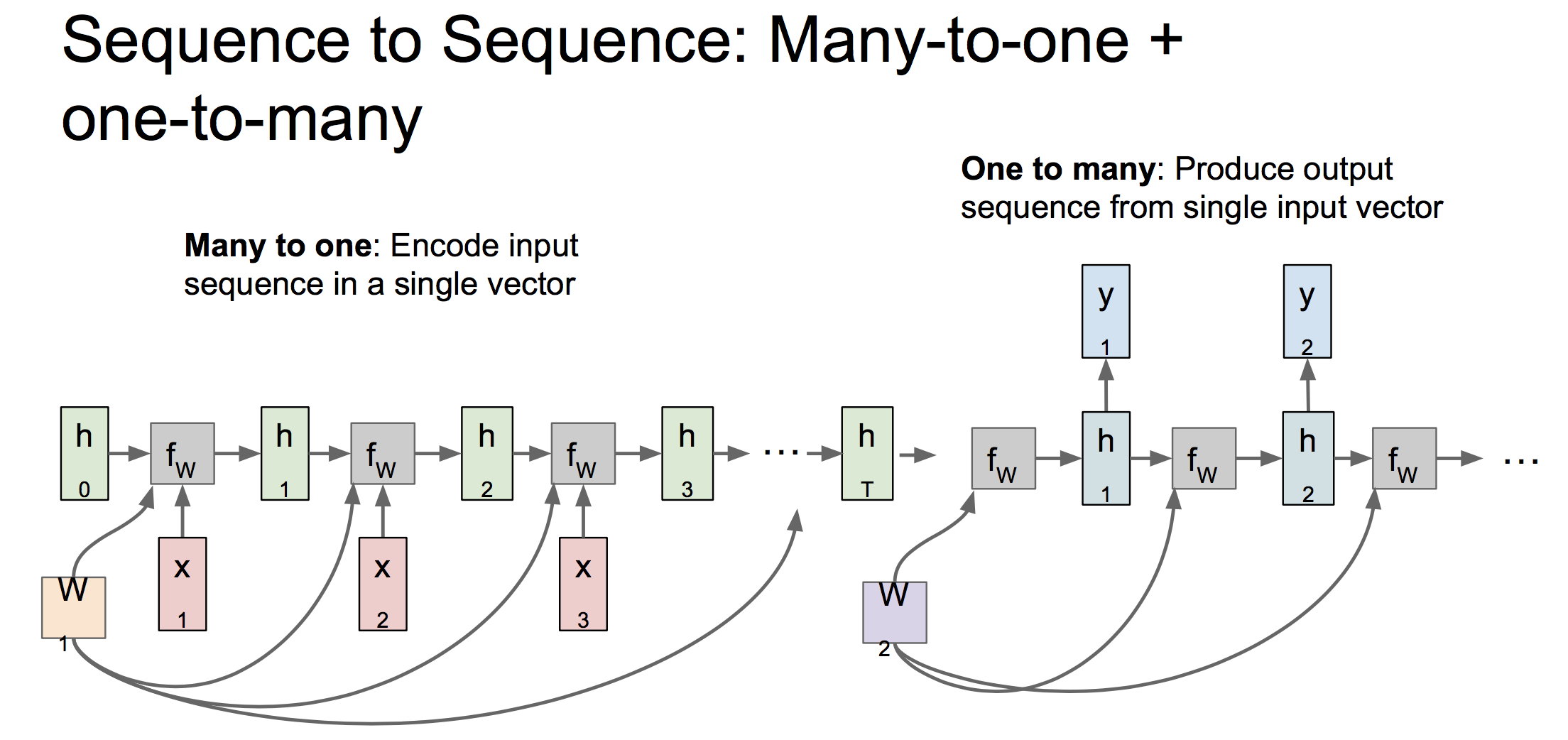
many2one和one2many的计算图:

seg2seg的计算图,可以被拆解为many2one和one2many两部分。其中many2one部分被称为编码器,将输入x编码成一个定长的向量。one2many被称为解码器,负责将该向量转化成输出序列。如下:
2 例子:字符级的语言生成模型
训练阶段:
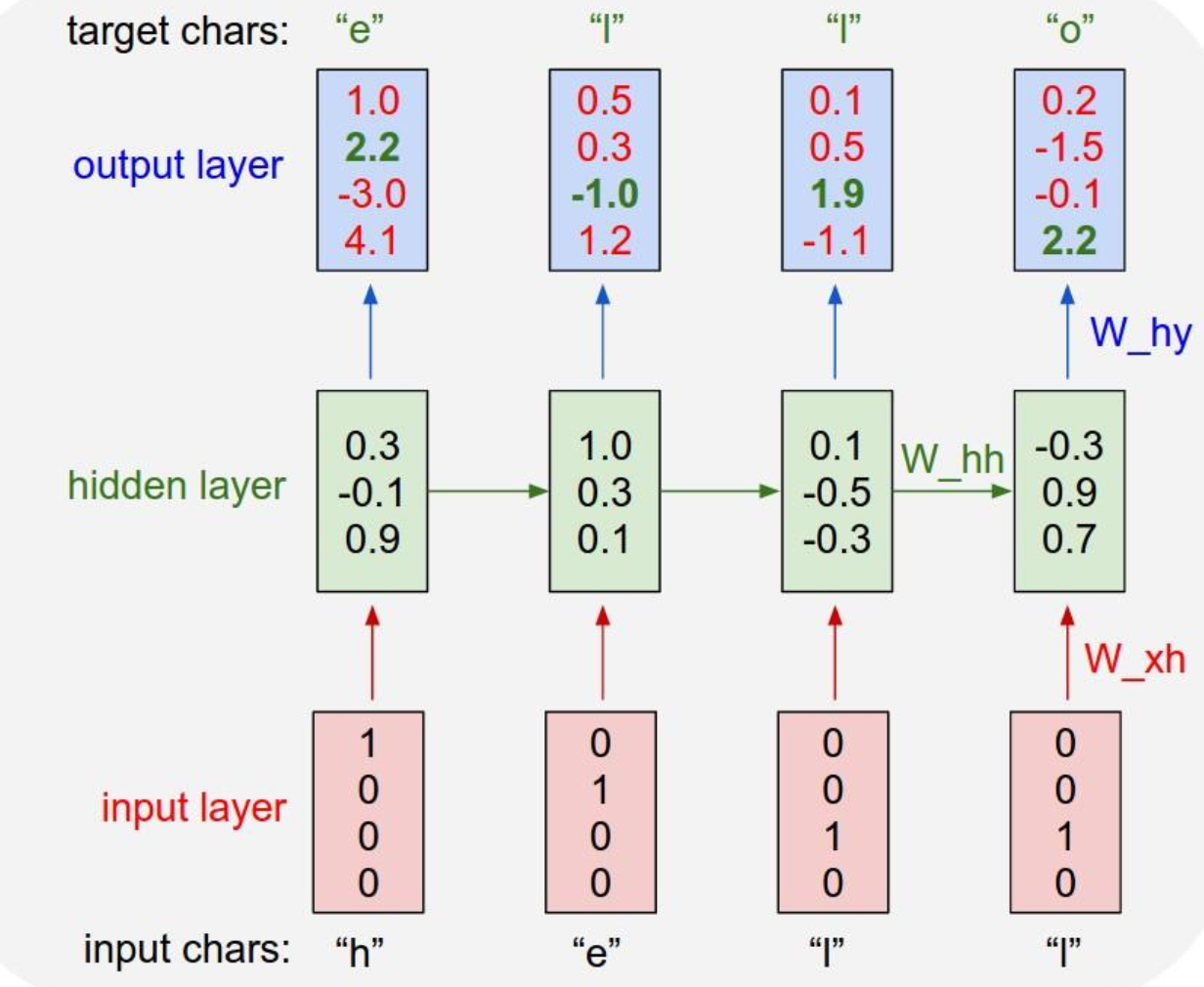
训练阶段,输入一个样本“hello”,我们经过一次前向传播产生输出。而我们的目标输出应该是输入序列向左平移一格,据此计算出损失,进而反向传播计算梯度,更新参数值,完成一轮迭代,进入下一次迭代。
测试阶段:
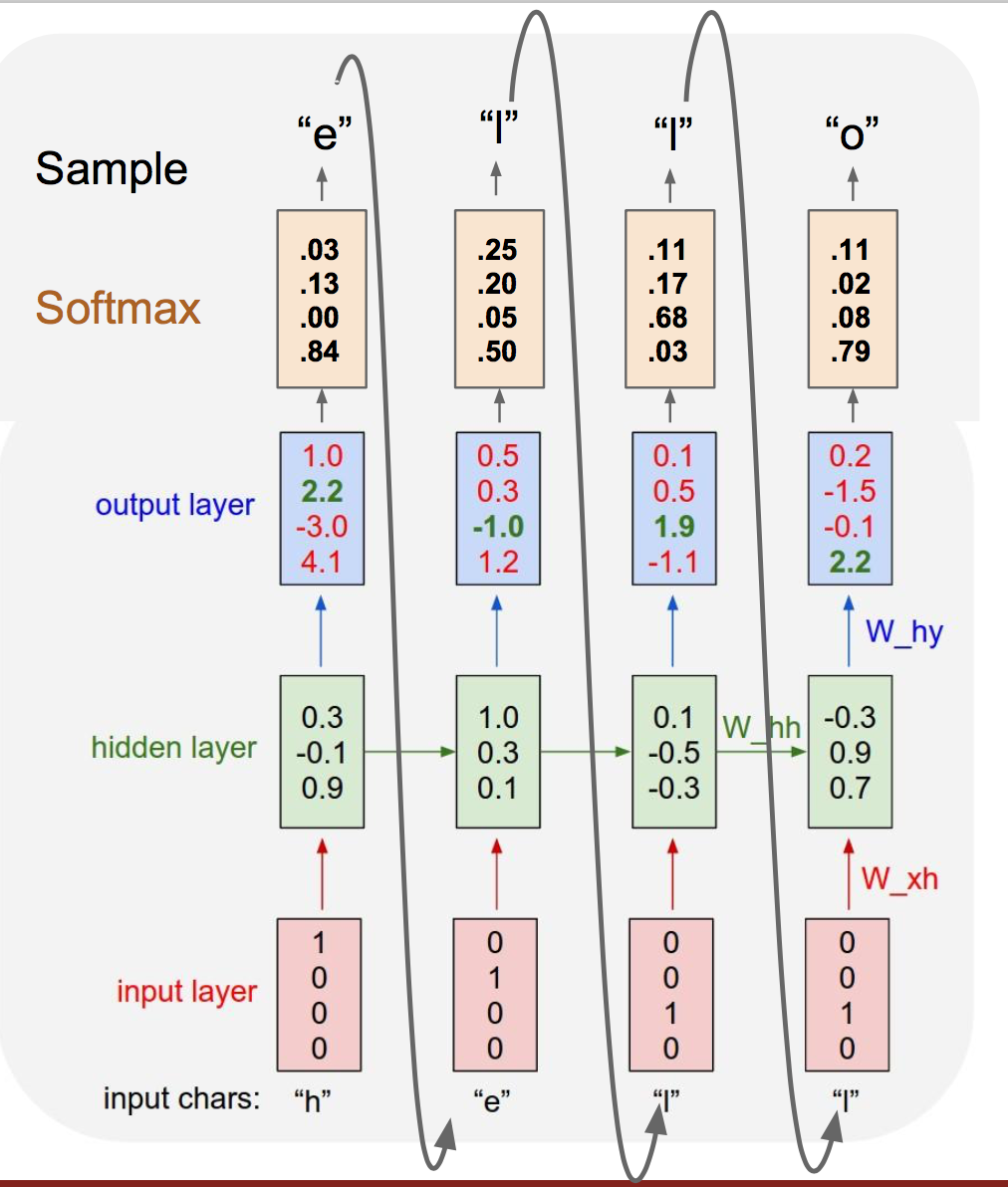
测试阶段,我们输入一个字母前缀,产生输出概率分布后,在这个分布上采样得到输出,并使用该输出作为下一时刻输入。(使用采样是为了得到多样化的输出)
可以看出,我们在训练阶段,一次前向传播或者一次反向传播,是要遍历一次整个序列的,也叫做Backpropagation through time 。有时候当我们的序列很长,这样前向传播和反向传播一次耗时会很长。这时有一种近似计算梯度的方法,就是截断的Backpropagation through time。我们每经过一定小步数的输入后,就前向传播计算一次损失,然后反向传播计算梯度:

3 图像标注
(1)典型的图像标注
一个典型的图像标注框架如下:

如上图,前向传播时,图像首先经过CNN网络处理,成为一个向量V,然后该向量V作为RNN的输入(注意此时有三个输入x,h,v)。
训练该网络时,梯度会从RNN一直回流到CNN,同时训练两个网络。
这个模型的结果很好,对于训练集中出现过的内容,模型可以很好的把他们标注出来;对于没有在训练集中出现的,模型会犯错。
(2)基于注意力的图像标注
另外还有一种基于注意力的图像标注方法,其模型结构如下:
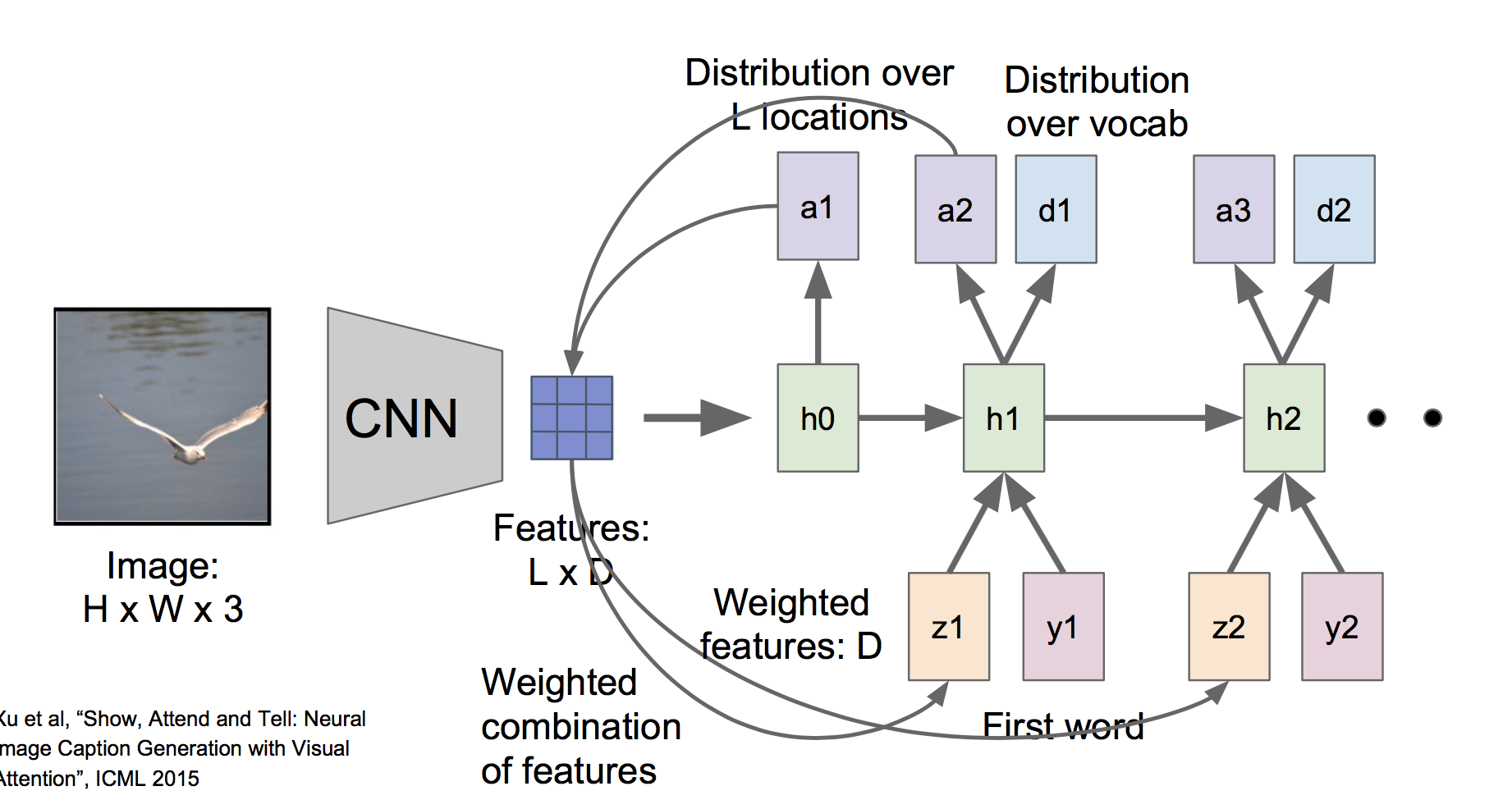
其中,CNN部分不是产生了一个单一的向量,而是产生对应L个不同位置的特征向量(通过使用窗口在图像上不同位置滑动得到)。并且,在RNN中,每个时间步的输出除了词分布dt之外,还有一个位置分布at,表示模型将注意力集中到各个位置的概率分布,然后将此概率分布与特征矩阵相乘,得到加权的特征向量z:

然后将z和序列的下一个单词y一起作为下一个时间步的输入。
对于这样一个模型,可以发现它自动学到了在每个时间步去注意图像的不同区域:

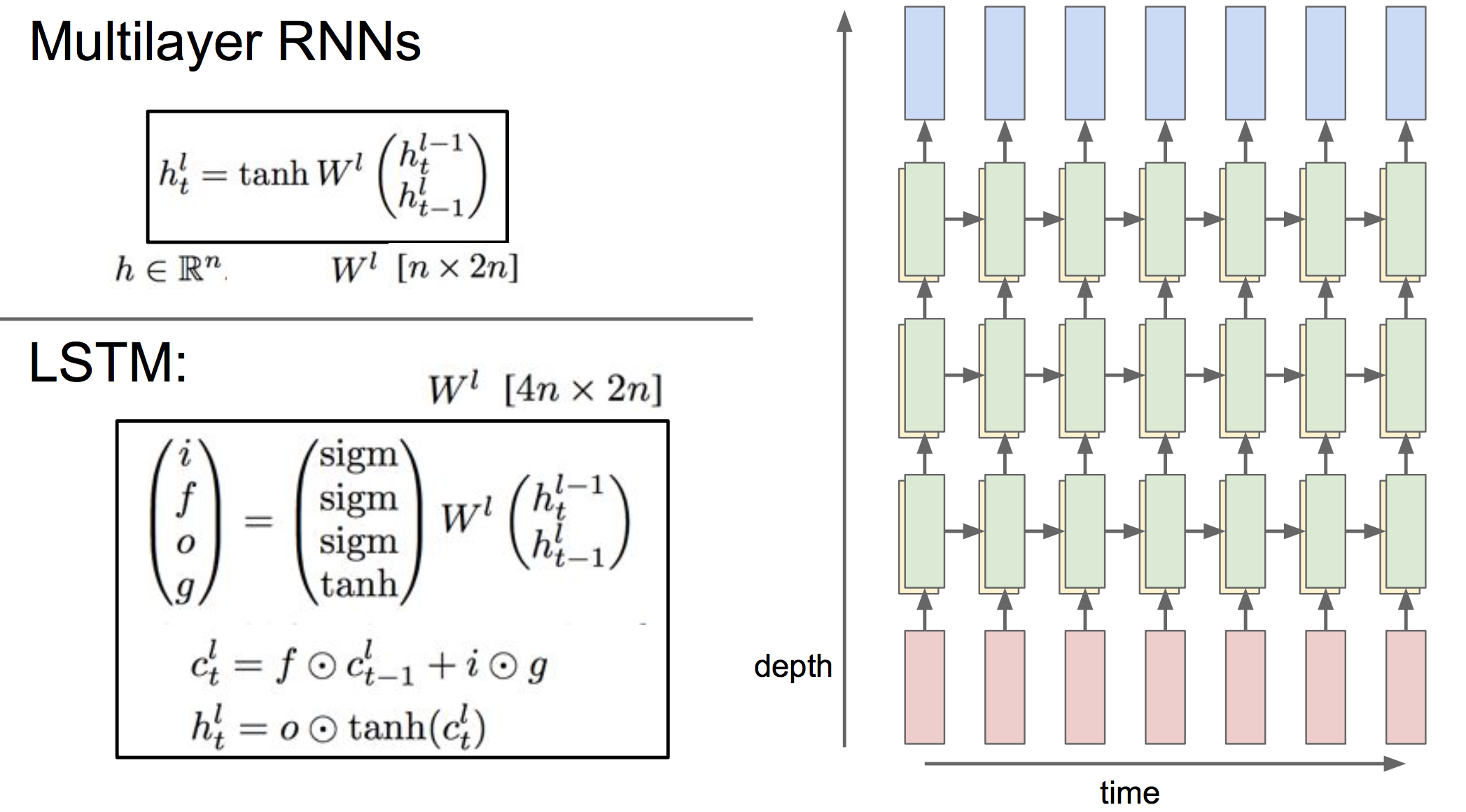
4 深层RNN
RNN的隐藏状态可以是多层的,不过通常3~4层已经足够了,如下所示L:
5 LSTM
(1)传统RNN中的梯度流
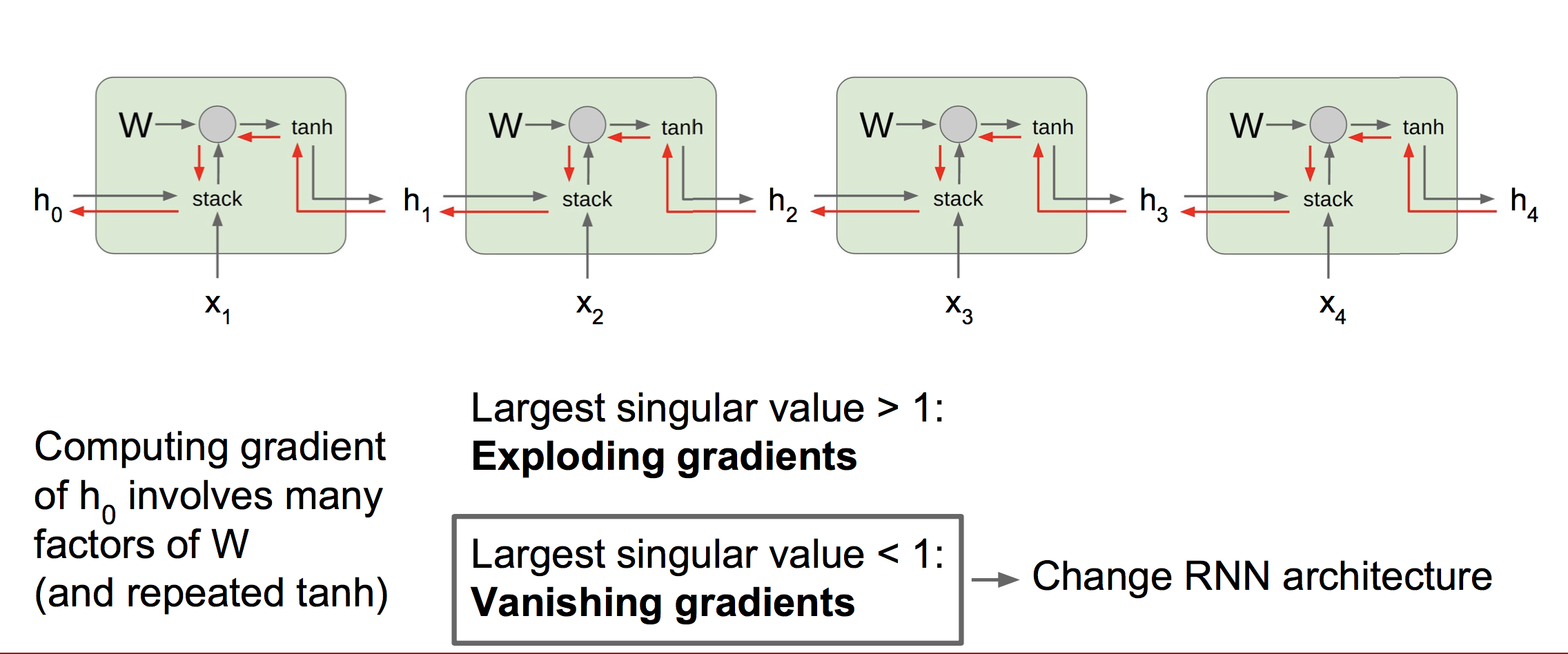
可以看到,传统RNN的梯度需要流经若干乘法门,导致梯度需要连乘相同的W因子。
当W的最大奇异值大于1时,会发生梯度爆炸,梯度爆炸不是很严重的问题,通常使用梯度截断就能解决;
当W的最大奇异值小于1时,会发生梯度消失。我们都知道RNN是通过隐藏态h来表示上文信息,而梯度消失导致低时间步单元的输入值x对高时间步的隐藏态h影响非常小,也就是高时间步的h几乎不含有低时间步输入x的信息。这样模型在训练时就无法捕获到时间间隔较长的依赖关系,也就无法学习出一个能反映长期依赖关系的参数W。
这种梯度消失导致的长期依赖问题要通过修改网络的结构解决,代表性的就是LSTM。
(2)LSTM
一个LSTM单元的内部结构如下:

其中i,f,o,g分别称为输入门,遗忘门,输出门,“门之门”,下面会介绍它们各自的作用。
我们可以看到,f,i,o的值是0~1,g的值是-1~1
其中Ct表示细胞状态,每次Ct更新时,都要经过遗忘和写入两个阶段。遗忘阶段ct-1会与f逐元素相乘,选择性的丢弃一些信息,f中为1的元素对应的ct-1信息得以完全保留,为0的元素对应的ct-1信息会被完全丢弃。然后,i与g逐元素相乘,表示有多少新的信息要写入到细胞状态中。之后更新ct。
更新后的Ct对下一时刻隐藏态ht的影响是通过o来控制的。
我们查看LSTM反向传播时梯度流的情况:

可以看到,虽然流经h的梯度流仍然会很大程度衰减,但由于细胞状态C的引入,形成了一条流经C的额外的梯度高速公路。在流经C的路线上,梯度经过加法门是无损的,经过乘法门时,需要逐元素乘以一个f。相比于传统RNN,这里的情况好了很多,因为f在不同的单元中都是不同的,一般不会出现都小于1的情况,此外,逐元素相乘也比矩阵相乘好得多。这样就使得梯度传播到低时间步单元时仍然不衰减,模型能够联系时间上相隔很远的序列信息来进行学习,克服上面提到的长期依赖的问题。
这种添加额外连接来改善梯度流的方法很常见,如ResNet。
6 总结

RNN有很多种灵活的结构;
传统的RNN结构在实际中工作的并不好;
实际中通常使用LSTM或GRU,它们能很好地克服梯度消失;
RNN的反向传播会有梯度爆炸或消失的问题,使用梯度截断及控制梯度爆炸,使用其他结构来克服梯度消失(LSTM);
探寻RNN最好的结构是当前的热门研究方向。