1 LeNet-5 (1998)
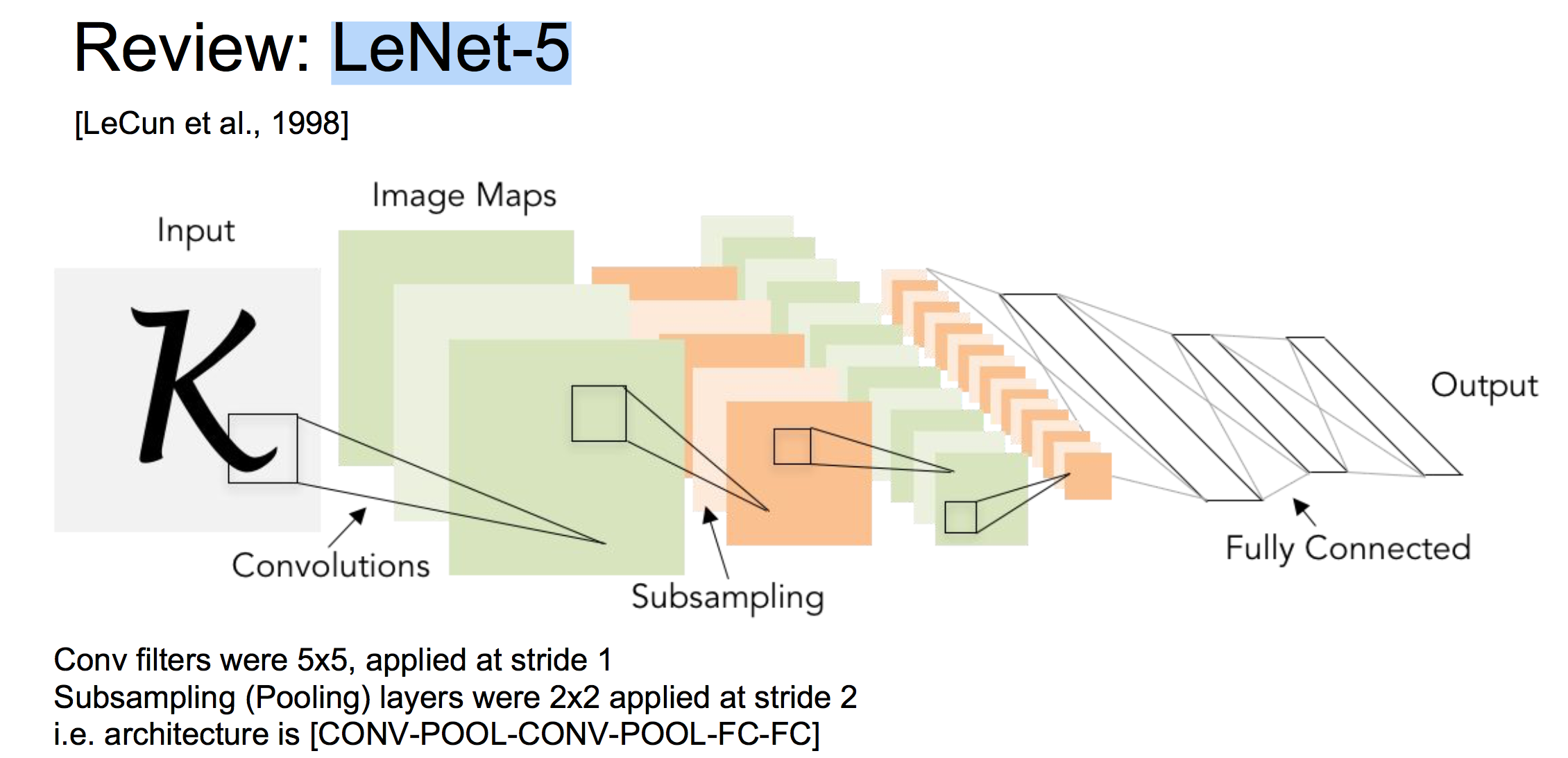
第一个被提出的卷积网络架构,深度较浅,用于手写数字识别。
2 AlexNet (2012)
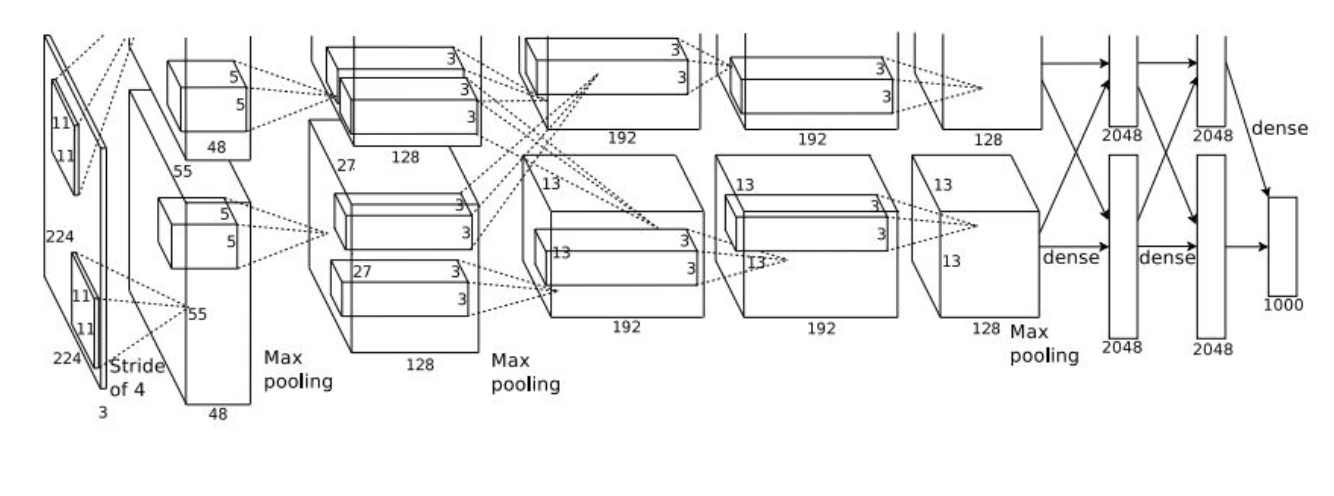
架构为:
CONV1 ->MAX POOL1 ->NORM1 ->CONV2 ->MAX POOL2 ->NORM2 ->CONV3->CONV4->CONV5->Max POOL3->FC6 ->FC7->FC8
相比于LeNet-5,AlexNet除了使用了更深的结构,还用到了:

观察架构图可以看到,AlexNet实际上被分成了两部分,这是由于当时的GPU内存限制。因此AlexNet被分别存储在两个GPU上,其中CONV3,FC6,FC7,FC8涉及到了GPU间的通信。
AlexNet是第一个成功运用的深度神经网络。
3 VGGNet (2014)
(1)改进
相比AlexNet,VGGNet有更深的网络,更小的滤波器:

(2)为什么更小的滤波器更好
假设有连续3层卷积层,它们都使用3*3的滤波器,那么最后一层激活图中,每个神经元的感受野是7*7的。可以看到,3个3*3的滤波器堆叠能达到一个7*7滤波器的感受野大小,但是却使用了更少的参数,更深的网络,引入了更多的非线性。
(3)整体架构
下面这张图显示了VGGNet的结构和内存参数情况:

其中红色的内存指的是存储激活值所占的内存,可以看到,一张图片的一次前向传播需要大约100M的内存,而且参数有一亿多个。而且我们发现,内存消耗主要集中在卷积层中,而参数主要集中在全连接层中。
VGG论文中一些其他的细节:

4 GoogLeNet (2014)
(1)改进
相比之前的网络,GoogleNet更深。由于放弃了全连接层,因此参数更少。并且使用了Inception模块,计算效率更高。

(2)Inception模块
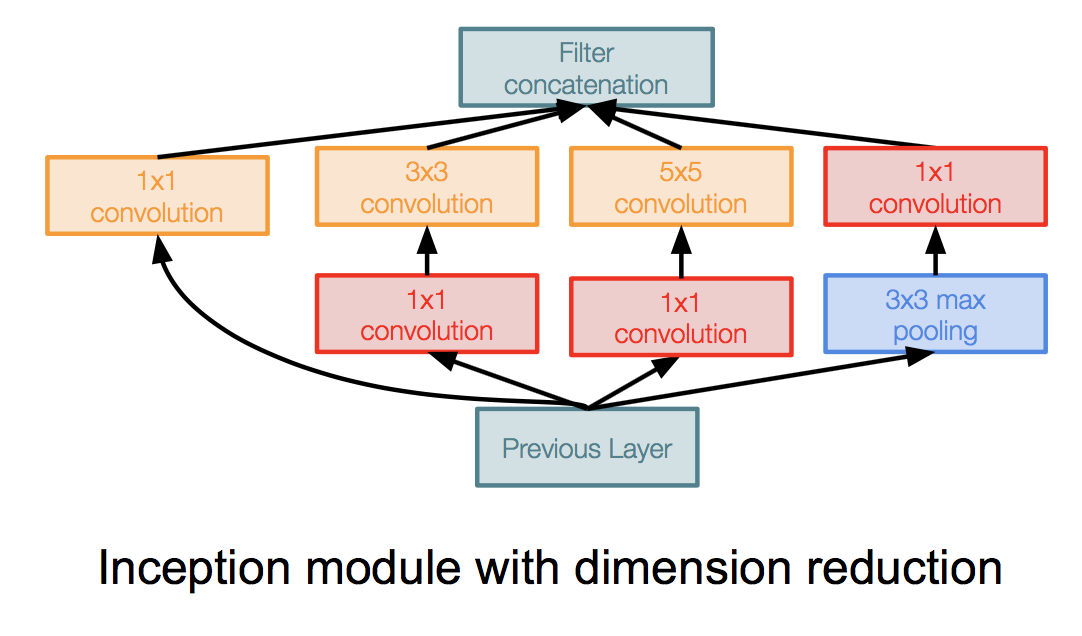
其中模块的输入是之前层的输出,在上面并行的使用各种大小的滤波器处理,最后各个滤波器的结果在深度上串联起来,得到模块的输出。
其中红色部分都是1*1的滤波器,被称为bottleneck层,其作用是减少输入的深度,然后再送给后面的滤波器处理,使得整体的运算量降低。下面两张图对比了使用和不使用bottleneck层的运算量。
不使用bottleneck层:

使用bottleneck层:

(3)整体架构
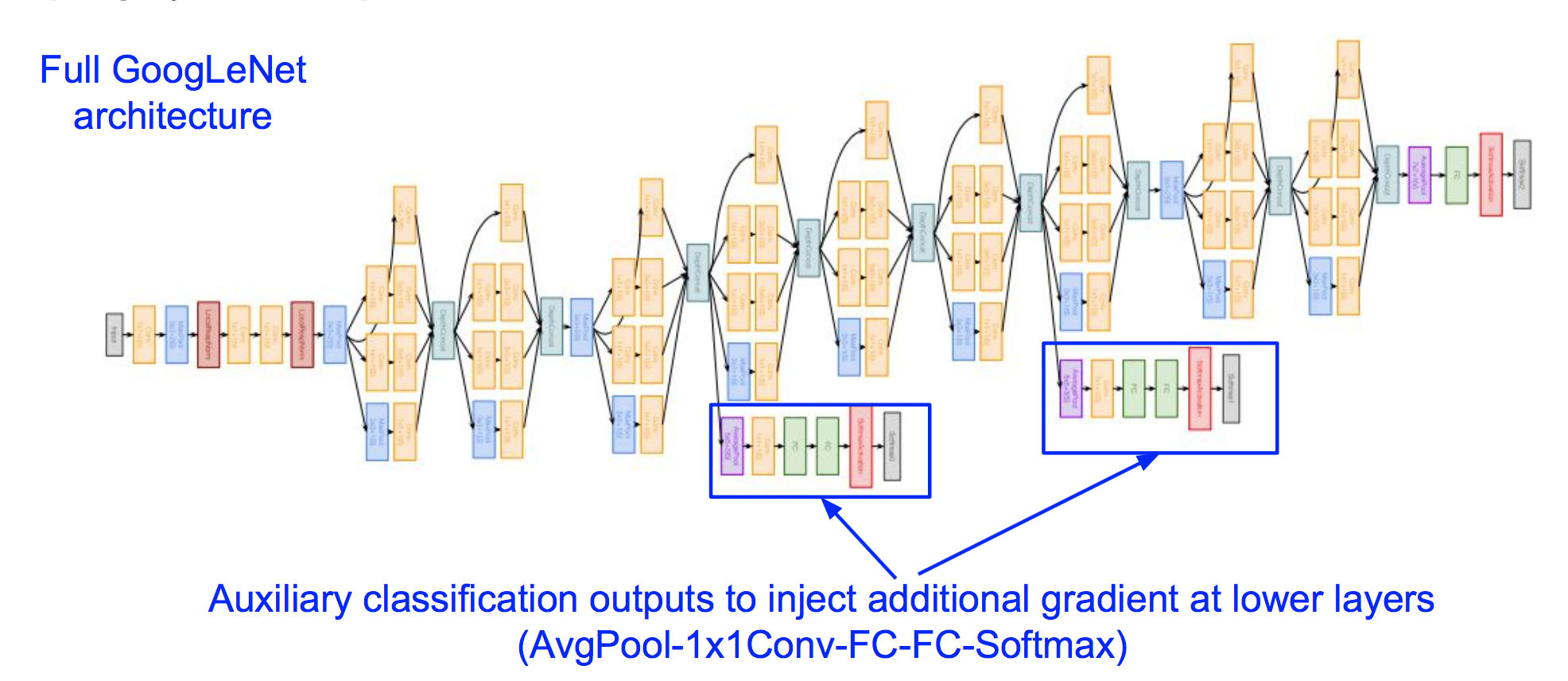
我们可以把GoogleNet的架构分为四部分:
a 输入一开始的部分,是传统的conv->pooling结构
b 中间部分是inception模块的堆叠
c Classifier output部分,移除了复杂的全连接层,使得参数量大大减少
d 额外的Classifier output部分,是为了解决网络过深导致较低层接受不到有效的梯度信号,额外的Classifier output部分可以为较低层提供额外的梯度信号。
5 ResNet (2015)
(1)深度网络训练困难问题
ResNet提出者指出,当网络很深时,训练集和测试集上的误差都表现得不好,显然这不是过拟合,而是深度网络难以训练(并不是梯度消失导致的,因为BN已经很好的解决了梯度消失)。

(2)残差层
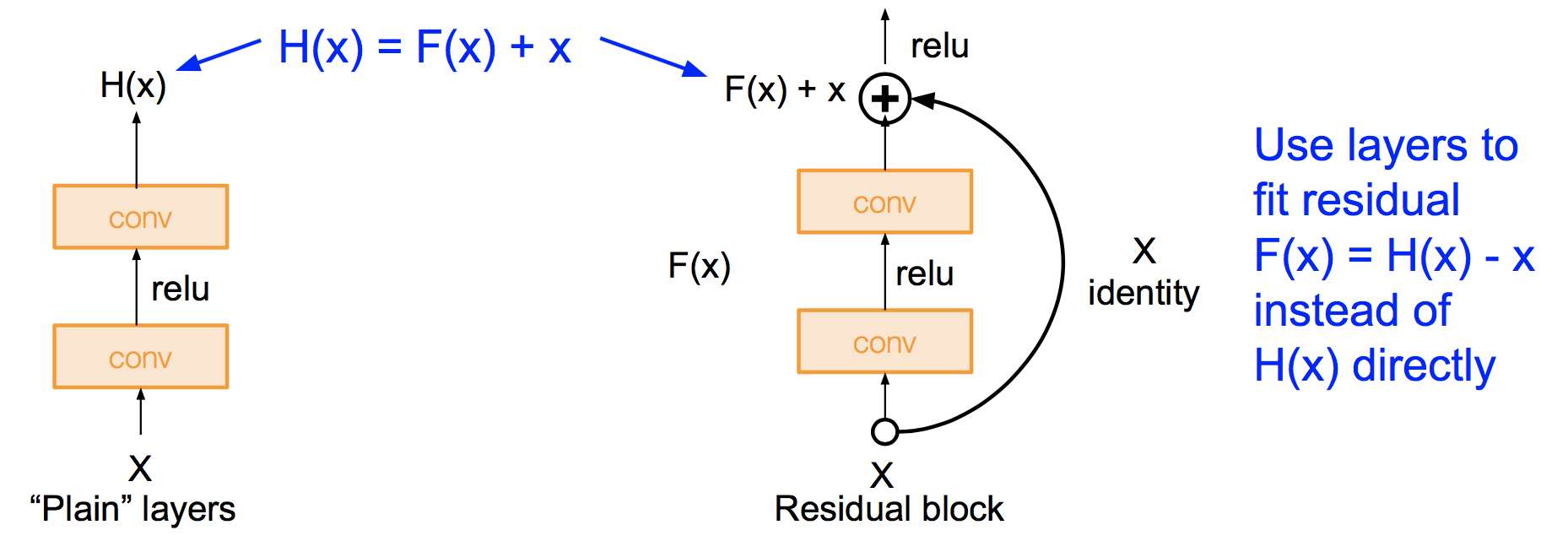
如上图,左边是普通层,右边是残差层,H(x)是我们期望学习的函数。普通层会直接学习这个函数,而残差层会学习其与x的差。
为什么残差层会有效,它解决了深度网络训练中的什么问题?
ResNet并不是解决了梯度消失的问题,梯度消失可以通过BN来解决,但是我们发现,使用BN的plainNet仍然比不上ResNet。事实上ResNet解决的是反传回来的梯度之间的相关性问题,具体可以参考文章The Shattered Gradients Problem: If resnets are the answer, then what is the question?
通俗来说,ResNet的结构很好的管理了梯度流,残差层的结构提供了一条使梯度直接向后流动的畅通无阻的通路,使得我们能够轻易的训练几百层的深层结构!
(3)架构
完整的ResNet是残差块的堆叠,并且不使用全连接层,更多细节:
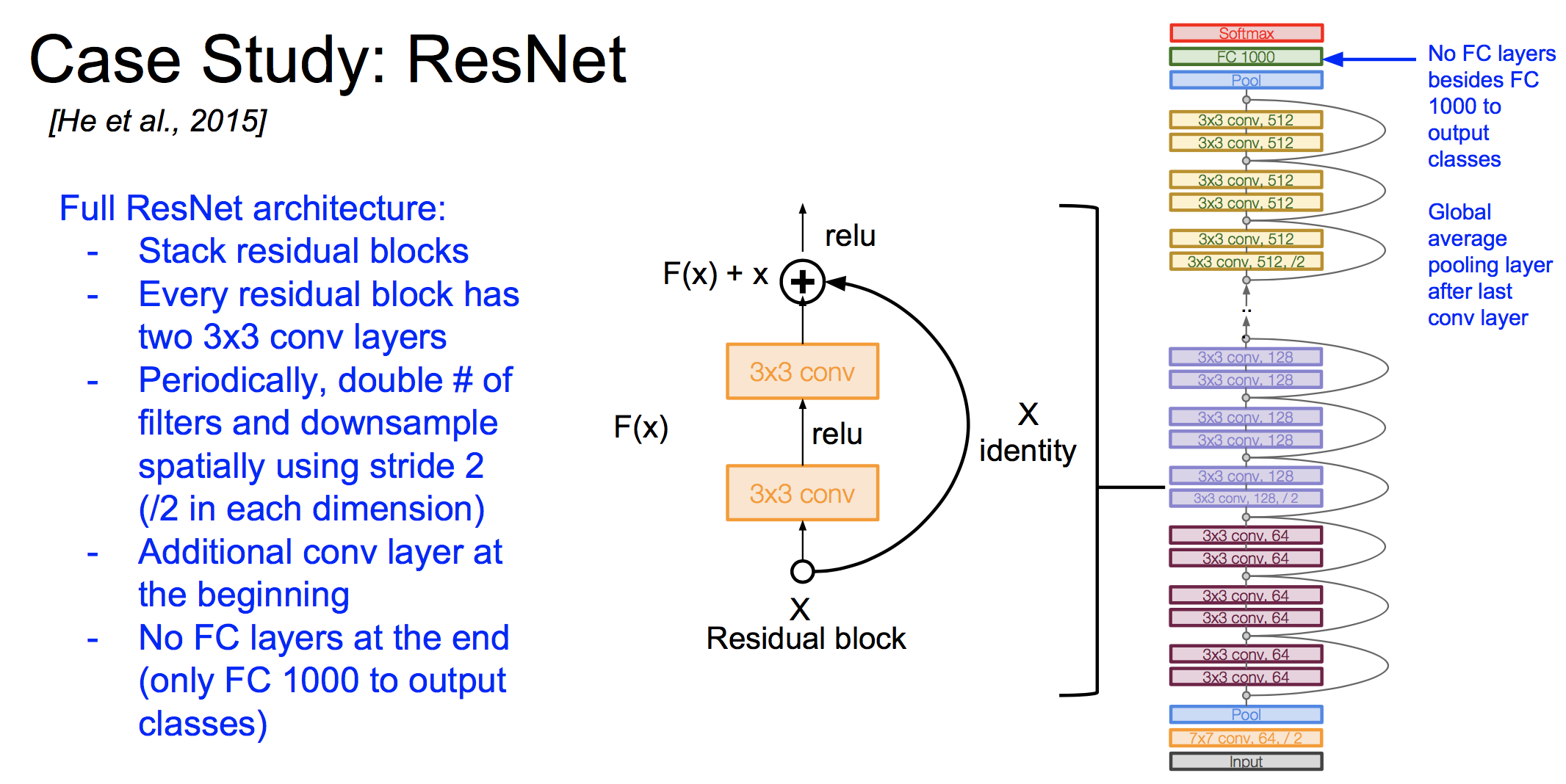
ResNet中也使用了bottleneck来提高计算效率:

6 各种架构的性能对比
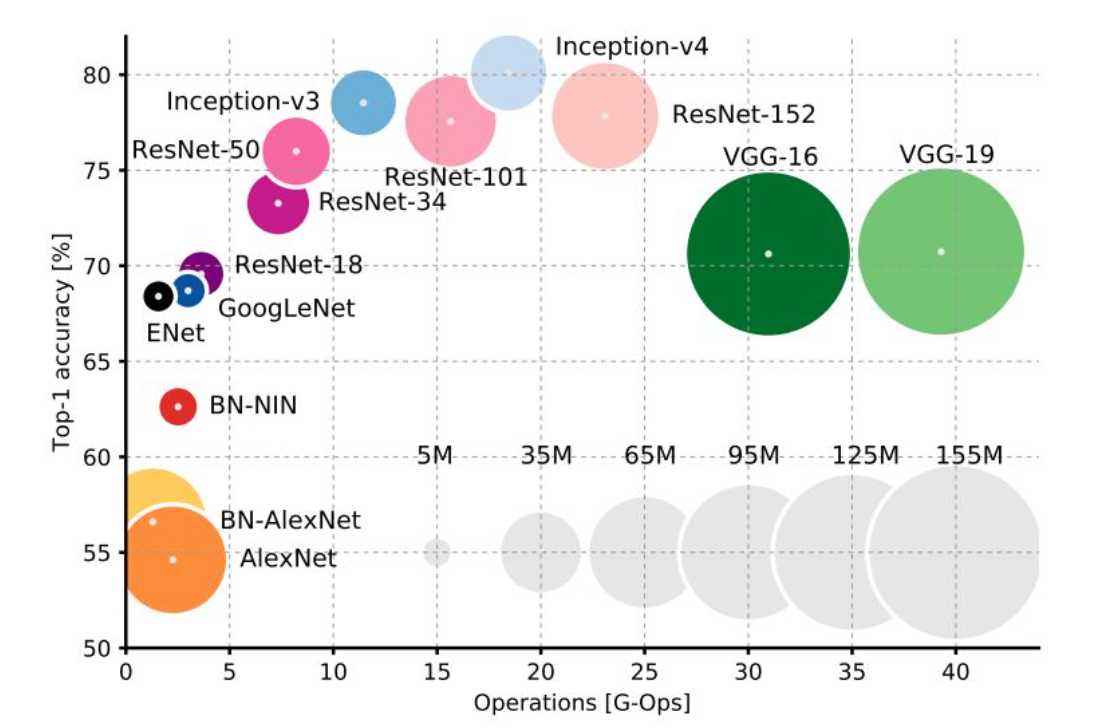
其中横坐标是运算量,纵坐标是精度,圆的大小表示占用的内存大小。
7 其他架构

8 CNN架构研究现状
(1)VGG, GoogLeNet, ResNet 被广泛投入使用,其中ResNet性能最佳
(2)加深网络是一个趋势,但是也有研究表明深度并不是最重要的,宽的ResNet仍然表现很好
(3)有很多关于层之间如何连接,跳连接的研究
