1 模型聚合的几种方式
分别有:(1)选择最好的模型;(2)每个模型均匀的投票;(3)每个模型按不同的权重投票;(4)每个模型的权重跟输入有关。

2 Uniform Blending
也就是均匀投票的聚合方式。对于二分类来说,就是:

对于多分类来说,就是:
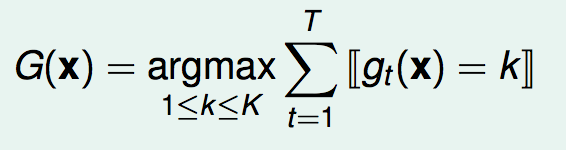
对于回归来说,就是:

简单推导一下为什么这种聚合方式可以做的好:

也就是blending之后的模型G的Eout一定是比所有g的Eout的平均值好的。(不一定比单个g的Eout好)。
3 Linear Blending
也就是每个模型按照不同的权值投票。
那么我们如何来求得这些权值呢?事实上,Linear Blending可以看作是一个两层学习的形式。第一层学出一堆的小g,第二层相当于用这些小g对原始资料作一个非线性变换,然后把这些新的变换后的资料用一个线性模型来学习:

这里的α>0的约束条件其实可以丢掉,事实上我们可以接受α<0。
这里需要注意,我们在第二层学习的时候,不能再使用之前训练小g的训练集来做非线性变换。这是因为,我们之前学到过在做模型选择时,如果用Ein来选择,就会付出相当大的VC维代价(即所有备选模型并集的VC维):

而这里的Linear Blending,包含了模型选择的这种情况(其中一个α为1,其他为0),因此它的VC维代价更大:

因此,正确的做法是:在训练集上训练出一堆的小g,然后对验证集的资料用这些小g作非线性变换得到新的资料,对这些新的资料来学出权值α。


扩展到any blending,我们第二层的学习不一定是线性模型,也可以是任意模型:

不过要注意,any Blending过拟合的风险比较高。
4 Bagging
有一笔资料,通过Bootstrap(有放回抽样),可以生成一笔新的资料,它与原来的资料大体上来源于一个概率分布。
使用这种Bootstrap来产生新样本,进而产生不一样的小g,称为bagging。