- 如何编写并行程序?
- 任务并行:将待解决问题所需要执行的各个任务分配到各个核上执行
- 数据并行:将待解决的问题所需要处理的数据分配给各个核,每个核在分配到的数据集上执行大致相似的操作。
- 协调过程
- 通信
- 负载平衡:每个核被分配到大致相同数目的数据来计算
- 同步
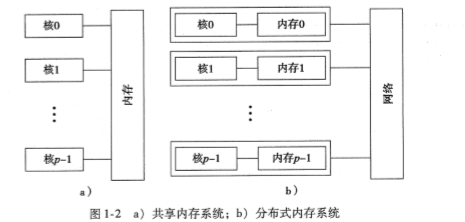
- 并行系统的种类
- 共享内存系统:各个核能够共享访问计算机的内存,理论上每个核能够读、写内存的所有区域。-----Pthreads、OpenMP
- 分布式内存系统:每个核拥有自己的私有内存,核之间的通信是显式的,需要使用类似于网络中发送消息的机制。-----MPI
- 并发计算、分布式计算
- 并发计算:一个程序的多个任务在同一时段内可以同时执行
- 并行计算:一个程序通过多个任务紧密协作来解决某个问题
- 分布式计算:一个程序需要与其他程序协作来解决某个问题
因此,并行程序和分布式程序都是并发的
- MPI(消息传递接口)
MPI是可以被C,C++和Fortran程序调用的函数库
第一个Hello World程序
设置一个进程负责输出,其他进程向他发送要打印的消息
编译:$ mpicc -g -Wall -o mpi_hello mpi_hello.c
- -g:允许使用调试器
- -Wall 显示警告
- -o<outfile> 编译出的可执行文件名为outfile
#include<stdio.h>
#include<string.h>
#include<mpi.h>
const int MAX_STRING = 100
int main(void){
char greeting[MAX_STRING];
int comm_sz; /*number of process*/
int my_rank; /*my process rank*/
MPI_Init(NULL,NULL);/*初始化*/
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);/*获取通信子的进程数,存放在comm_sz中*/
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);/*获取正在调用进程在通信子中的进程号*/
if(my_rank != 0){/*非0号进程 向0号进程发送消息*/
sprintf(greeting, "Greetings from process %d of %d! ",my_rank, comm_sz);
MPI_Send(greeting, strlen(greeting)+1, MPI_CHAR, 0, 0,MPI_COMM_WORLD);
}else{/*0号进程 负责接收其他进程发过来的消息,并打印出来*/
printf("Greetings from process %d of %d!
",my_rank,comm_sz);
for( int q = 1; q < comm_sz; q++){
MPI_Recv(greeting, MAX_STRING, MPI_CHAR, q, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
printf("%s
", greeting);
}
}
MPI_Finalize();/*结束*/
return 0;
}
1.首先要包含C语言头文件stdio.h和string.h ,加上一个mpi.h头文件
2.命名:MPI定义的标识符都由字符串MPI_开始。
下划线后的第一个字母大写,表示函数名和MPI定义的类型
MPI定义的宏和常量的所有字母都大写,这样可以区分什么是MPI定义的什么是用户程序定义的
- MPI_Init和MPI_Finalize
- MPI_Comm_size和MPI_Comm_rank
MPI_Comm_size函数在第二个参数处返回通信子的进程数
MPI_Comm_rank函数返回正在调用进程在通信子中的进程号
- MPI_Send
消息组装完毕后,发送进程可以缓冲消息或阻塞消息
- 缓冲:消息将会被放在内存中
- 阻塞:系统将会阻塞,一直等待
实现方法:如果一条消息的大小小于“截止”大小,它将会被缓冲;如果大于截止大小,那么将会被阻塞
int MPI_Send(
void* msg_buf_p,/*in*/
int msg_size,/*in*/
MPI_Datatype msg_type, /*--消息的内容*/
int dest,
int tag,
MPI_Comm communicator/*消息的目的地*/
);
- MPI_Recv
总是阻塞的,直到等待到一条匹配的消息。
int MPI_Recv(
void* msg_buf_p,/*out*/
int buf_size,
MPI_Datatype buf_type,
int source,
int tag,
MPI_Comm communicator,
MPI_Status* status_p /*out*/
);
- 消息匹配问题

如果0号进程只是简单的按照进程号顺序的接收结果,即先接收1号进程的结果,在接收2号进程的结果,以此类推,但如果comm_sz-1号进程是第一个完成工作的,那么有可能comm_sz-1号进程必须等待其他进程的完成。
为避免这个问题,MPI提供了一个特殊的常量MPI_ANY_SOURCE,可以传递给MPI_Recv了。如果0号进程执行下列代码,那么他可以按照进程完成工作的顺序来接收结果了
for (i = 1; i < comm_sz;i++){
MPI_Recv(result, result_sz, result_type, MPI_ANY_SOURCE, result_tag, comm, MPI_STATUS_IGNORE);
Process_result(result);
}
- status_p参数
接收者通过检查一下两个成员来确定发送者和标签:
status.MPI_SOURCE
status.MPI_TAG
- MPI_Get_count函数
MPI_Get_count(&status, recv_type, &count)
int MPI_Get_count(
MPI_Status* status_p,
MPI_Datatype type,
int* count_p
)
注:count值不能简单的作为MPI_Status变量的成员直接访问
- MPI消息的不可超越性
- 同一进程发送两条消息给进程t:第一条消息必须在第二条消息之前可用
- 不同进程发送消息给进程t:信息达到顺序没有限制