1、首先要进行特征的选择,特征的选择需要基于一定的背景知识
X = titanic[['age','pclass','sex']]
y=titanic['survived']
选择结束可以使用info()进行探查
2、有些特征缺失,我们需要将其补充完整
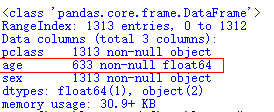
如果该特征是数值型 eg:age特征 可使用平均值或中位值,该策略是对模型造成影响最小的
X['age'] .fillna( X['age'].mean() , inplace=True )
X.info() #再次查看
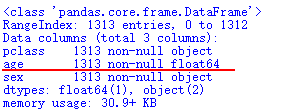
3、有一些数据列的值都是类别型的,需要转化为数值特征,用0/1代替
from sklearn.feature_extraction import DictVectorizer
#使用scikit-sklearn.feature_extraction 中的特征转换器
vec = DictVectorizer(sparse=False) #sparse稀疏
X_train = vec.fit_transform( X_train.to_dict(orient='record') )
print(vec.feature_names_) #通过查看转换特征后的结果我们发现凡是类别型的特征都单独剥离出来,独成一列特征,数值型不变
如下图:
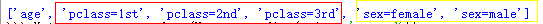
完成了特征的处理,可以继续下一步啦!