K-Means算法是一种聚类算法。聚类是一种无监督的学习,是将相似的对象归于同一簇中。无监督是指不提供类别信息和给定目标值,并且无需训练数据。而聚(clustering)与分类(Classification)不同,分类是已经有类别,比如电影的类别,喜剧片、爱情片,已经有类别,是将提供的数据划分到已有的类别中,而聚类是没有定义好的类别,聚类方法几乎可以应用于所有对象,簇中的对象越相似,聚类的效果越好。而之所以叫K-Means算法是因为它可以发现k个不同的簇。
总而言之,K-Means算法是一种聚类分析的算法,其主要是来计算数据聚集的算法。
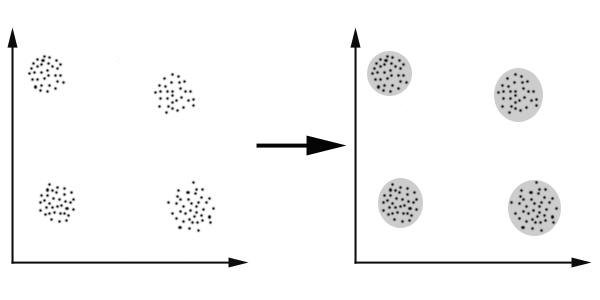
一、算法原理
1)创建k个点作为起始点,通常是随机选取。
2)计算其他点到k个种子点的距离,将这些点分配到距离最近的簇。
3)根据聚类结果,重新计算k个簇的中心,通常是计算簇中所有点的均值并将均值作为中心。
4)重复2、3步,直至聚类结果无改变
5)输出结果
二、算法实现(Python)
1、计算两个数据点之间的距离,这里使用最常用的欧式距离
def distEclud(vecA, vecB):
""" 计算两个向量的欧式距离
Args:
vecA: 向量A
vecB: 向量B
Returns:
向量之间的欧式距离
"""
return sqrt(sum(power(vecA - vecB, 2)))
2、随机选取中心点
def randCent(dataSet, k):
""" 随机选择k个中心
Args:
dataSet: 数据矩阵
k: 中心个数
Returns:
centroids 中心矩阵
"""
n = shape(dataSet)[1]
centroids = mat(zeros((k, n)))
for j in range(n):
minJ = min(dataSet[:, j])
rangeJ = float(max(dataSet[:, j]) - minJ)
centroids[:, j] = minJ + rangeJ * random.rand(k, 1)
return centroids
3、K-means具体算法
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
""" 随机选择k个中心
Args:
dataSet: 数据矩阵
k: 中心个数
distMeas: 向量距离函数
createCent: 选择簇中心函数
Returns:
centroids 中心矩阵
clusterAssment 簇分配结果矩阵,一列分配簇索引值,一列存储误差
"""
m = shape(dataSet)[0] #数据行数
clusterAssment = mat(zeros((m, 2)))
centroids = createCent(dataSet, k)
cluterChanged = True
while cluterChanged:
cluterChanged = False
for i in range(m):
# 寻找最近的中心
minDist = inf; minIndex = -1
for j in range(k):
distJI = distMeas(centroids[j,:], dataSet[i,:])
if distJI < minDist:
minDist = distJI; minIndex = j
if clusterAssment[i,0] != minIndex:
cluterChanged = True
clusterAssment[i,:] = minIndex, minDist**2
#print(centroids)
# 更改中心的位置
for cent in range(k):
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A == cent)[0]]
centroids[cent,:] = mean(ptsInClust, axis=0)
return centroids, clusterAssment
4、载入数据集
def loadDataSet(filename):
""" 载入数据集
Args:
filename: 输入文档
Returns:
mat(dataList) 数据矩阵
"""
dataList = []
fr = open(filename)
for line in fr.readlines():
curLine = line.strip().split(' ')
fltLine = [float(i) for i in curLine]
dataList.append(fltLine)
return mat(dataList)