在对业务预测时,我们需要建立合适的模型,把历史数据输入模型中,进行顶测,然后与真实数据对比,不断参数调优改进模型。这时候,数据的准确性和完整性等因素确实很重要。如果数据质量出现问题,就会导致结果偏差很大,甚至是错误的。如果得出的数据是一个企业对于未来市场的判断,那么这种后果将是极其严重的。在大数据时代,我们有分析大数据的各种方法,在存储上也得到了很好的解决方案,而极少部分的不准确数据在巨大的数据量面前的影响甚微。
无论影响数据质量的因素发生什么样的变化,保证数据质量永远都是业务使用必须解决的问题。因此,对数据产品来说,建立一个数据管理系统(DMS) ,对公司的业务发展显得很重要。

数据管理系统侧重于从时效性和数据一致性两大质量方向保证数据的可读性。
2.1数据仓库的数据时效性检查
明确每天的每一个层级、每一个数据表的最早和最晚生成时间,发现影响当天数据生成延误的数据表,并能够通过数据管理系统回答以下问题:
1.当天 MYSQL表和Hive表中的核心指标是何时生成的?
2.有哪些表的产出时间比预期时间延迟了?
3.任务延迟的原因是由哪几张表造成的?
4.瓶颈在哪里?优化哪几层?哪几张表可以提高核心指标等的生成时间?
2.2数据仓库的数据一致性检查
通过数据一致性检查,在数据质量视图的展现下,我们可以快速了解存在依赖关系的数据表的分维度数据变化情况。为了对数据一致性进行检査,首先需要监测数据库中每一张表的维度和指标数据。例如,计算指标A的 MYSQL语句如下:
SELECT Platform,app id,count(user id) A
FROM etl_user_event
WHERE action method=' CLICK DOC'
GROUP BY platform, app id
然后,建立逻辑比较关系,把每个数据表的每一个指标之间建立联系。例如:
关系1:T1.指标A==T2.指标A
关系2:T1.指标A*0.95<T2.指标A
2.3因此,数据管理系统项目需要做的事情主要分为以下几步:
第一步,建立数据依赖引擎,实现依赖图谱。依赖图谱用于构建数据仓库表之间的分层级依赖关系,然后存入 MYSQL表并能支持可视化展现。
第二步,计算数据准备情况。各个表、各个分区的数据准备就绪时间按天,小时级进行汇总。根据Hive仓库的Meta信息可以获取Hive表各个分区的创建时间,根据创建时间确定数据的实效性,用来分析展现每天、每小时的状态和瓶颈。如果需要对 MYSQL进行验证则通过SOL语句査询的方式获取对应时间在MYSQL中是否存在。
第四步,建立数据比较引。根据表和表之间核心指标的关系、表和表之间的规则进行比较验证。例如,A==B,A+B==C,B/A<0.95 等逻辑判断。
3.数据管理系统功能
数据管理系统的功能主要分为数据流管理、任务管理、数据管理三大功能。
3.1数据流管理,也可以叫血缘分析。
单从字面上来看,它属于一种数据关系的分析,用来解释数据之间相互影响的一种描述。数据流管理,对于当前大数据背景下的数据治理具有十分重要的意义,它能让你快速了解数据组成结构,并制定有效的管理方式。
例如,有一天,我们发现大数据分析平台某个业务指标的数据没有产出,就要去查看到底哪里出了向题,是数据集市里的表、主题层的表还是基础层的表出了问题。而在更多的时候,数据集市的表会依赖多张表,那么这个排査问题的过程就会变得很麻烦,而且很浪费时间。有一个简单的思路就是,通过业务场景,在数据管理系统中设计解析每一个计算过程的链路关系,自动绘制出图表,动态获取执行情况,并做出预警。对于日常的监控,可以将每一个元数据的引用情况做出明暗度显示,绘制出数据连接图。
数据血缘关系会首先通过指标对应的库表关系,找出它所属的表,再根据计算关系找到计算过程中与它有关联的表,最终把整个链路上的相关表展现出来。这样就清晰地展现出了它从数据源头开始,一层一层的链路关系,并且可以用颜色区分正常、延迟、未处理等各种状况,清楚地知道任务异常情况,并在任务延退情况下触发报警机制,以短信方式提醒负责人排査问题,确保数据正常产出。
血缘分析可以清晰地帮助我们了解所维护的数据的使用与被使用情况,犹如资产一般,便于维护定位与统一管理。一个管理者如果掌握了数据资产的使用与被使用情况,就可以更加清晰地了解管理与维护的重点,并做出合理的风险预警,基于业务重点做一些资源的调整与再分配。
3.1.1血缘管理如下图所示: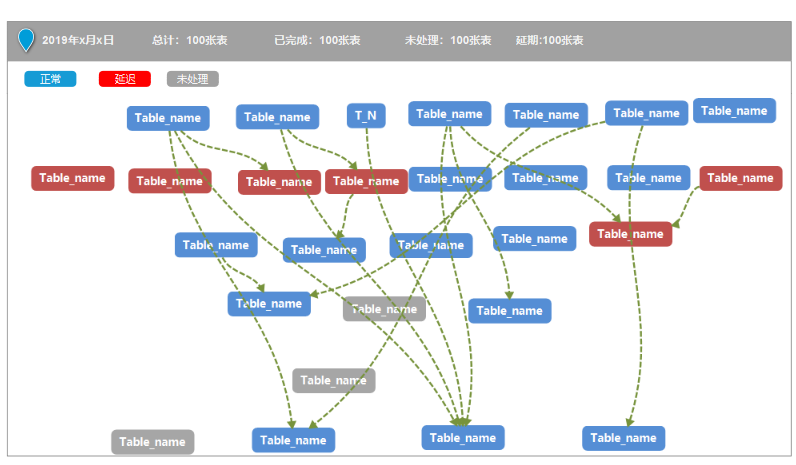
3.2任务管理
任务管理会对每天的任务执行情况进行管理,展现每张表的任务完成时间任务延时情况以及延时的原因等,一且任务出现问题,可以快速联系到数据表的负责人。同时,能够方便查看每张表的依赖关系、完成时长的历史情况以及表的字段信息,让数据分析平台变得清晰。如下图:

3.2.1完成时长趋势
在数仓中每张表的完成时长每天都是不一样的,因此在数据关系系统中,有必要把表的每天完成时长记录下来,然后展示在系统中,方便查询近况时间内的完成趋势,如下图:

还可以针对数据流程进行优化,减少任务延迟时间情况,需要分负责人和表名称两个维度去对数据延迟情况进行统计,可以查看每个负责人的延迟次数,延迟时间等情况。
3.2数据管理
数据管理功能会展示数仓表的信息,包括所属数据库,存储类型,负责人,产出状态,数据库地址,标签,备注等,并可以进行编辑和操作。点击表名,业务组可以跳转到血缘关系页面,对应表所在的血缘图进行查看。数据管理功能的作用还能根据表名,标签,产品状态,业务组快速查找相关表。如下图:
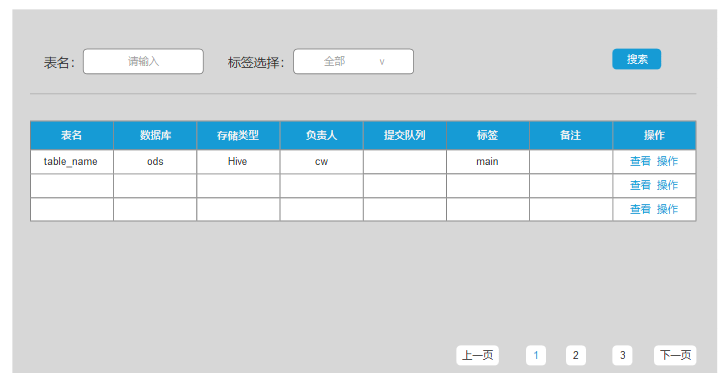
PS:通常数据质量监控的话,表级别和字段级别的监控比较常见且易实现。如果有足够的开发资源可以进行全链路数据监控的开发,全链路会涉及到源数据—数据通—数据ETL—数据展示全过程