当掌握了大量数据时候,我们往往希望在数据中挖掘更多的信息,一般可以应用成熟模型进行比较深入的分析。
举几个例子:
②上线了某个活动,预估活动效果,用户参与度情况。
③上线某个注册送现金活动,判断哪些账号是真是账号,哪些是虚假账号(为了领取现金注册的)
我们可以根据以往活动的数据,分析活动的各个影响因素在满足什么情况时才会产生我们想要的效果,并可以把有上线活动时和没有上线活动时的各项数据输入系统中,分类函数就会判断活动效果与哪些因素有关,目前比较常用的分类分析方法有决策树,朴素贝叶斯,KNN算法等等......
1.开始分析
根据上面举的工作中的例子我们本次使用朴素贝叶斯来进行相关的分析。
针对第二种分析情况,首先我们模拟一组数据如下,来说明贝叶斯分类的作用。如下:其中特征属性是优惠券金额和用户类型,类别是用户参与度情况如下表:
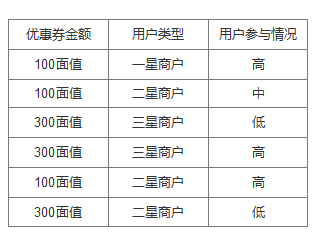
那么现在又来了第类型的人,是一个使用100面值的三星用户。请问他参与情况高的情概率有多大?
P(高 | 100面值 x 三星商户)
= P(100面值 x 三星商户 | 高) x P(高) / P(100面值 x 三星商户)
假定"100面值"和"三星用户"这两个特征是独立的,因此,上面的等式就变成了:
P(高 | 100面值 x 三星商户) = P(100面值 | 高) x P(三星商户 | 高) x P(高) / P(100面值) x P(三星商户)
这情况下是可以计算的:
P(高 | 100面值 x 三星商户) =0.66 x 0.33 x 0.5 / 0.5 x 0.33=0.66
=======================================================================================分割
针对第二种分析情况,首先我们模拟一组数据如下,
假设我们app上有10000个账号中有89%为真实账号(设为C0),11%为虚假账号(设为C1)。
C0=0.89 C1=0.11
接下来,就要用统计数据判断一个账号的真实性。假定某一个账号有以下三个特征:
F1: 日志数量/注册天数 = 0.1
F2: 购买数量/注册天数 = 0.2
F3: 是否使用真实头像(真实头像为1,非真实头像为0) =0
那么计算该账号是真实账号还是虚假账号?方法是使用朴素贝叶斯分类器,计算下面这个计算式的值:
P(F1|C)P(F2|C)P(F3|C)P(C)
我们拟定给出以下数值情况:
P(F1|C0) = 0.5,P(F2|C0) = 0.7,P(F3|C0) = 0.2
P(F1|C1) = 0.1,P(F2|C1) = 0.2 ,P(F3|C1) = 0.9
因此:
P(F1|C0) P(F2|C0) P(F3|C0) P(C0)
= 0.5 x 0.7 x 0.2 x 0.89
= 0.0623
P(F1|C1) P(F2|C1) P(F3|C1) P(C1)
= 0.1 x 0.2 x 0.9 x 0.11
= 0.00198
可以看到,虽然这个用户没有使用真实头像,但是他是真实账号的概率,比虚假账号高出30倍左右,因此判断这个账号为真。